Контент (англ. content — содержимое) - информация, а именно, текст, изображения, видео, файлы, которые расположены на сайте.Он должен быть:
- Дающим наиболее полный и понятный ответ, решающим проблему человека: будь то поднять настроение, покончить со сложной дилеммой или приобрести качественный товар.
- Без использования скрытых фрагментов, таких как:
- текст одного цвета с фоном,
- текст скрыт изображением, располагаясь позади него,
- размер шрифта равен значению 0.
- главные мысли выделены цветом или жирностью, чтобы пользователь сфокусировал на них внимание. Не забывайте, что веб-страницы не читаются, а мельком просматриваются.
- через реализована структура статьи,
- предложения объединены в абзацы, между которыми присутствует пустая строка,
- использованы списки, цитаты, таблицы,
- применены картинки, инфогра́фика, видеоролики, аудиозаписи. Изображения играют большую роль. Так, один читатель данного блога попросил перевести символы на скриншоте, на котором был изображён редактор Blogger.
Дублирование контента можно наблюдать не только при размещении данных на разных сайтах, но и при повторении информации на двух и более одного веб-проекта. Вот эксперимент на devvver.ru о негативе внутренних дубликатов и как этим могут воспользоваться конкуренты.
Рассмотрим какие инструменты у нас есть в борьбе с этим недугом.
Ссылки на страницу
Единственный стопроцентный способ не дать проиндексироваться странице - не размещать на неё ссылки, и не добавлять её в аддурилки Яндекса , Google и т.п.
Файл robots.txt
Текстовый файл robots.txt (например, ) прекрасный инструмент для управления индексацией. Справка Yandex , Google . Но если Гугл найдёт ссылку на закрытый в robots.txt URL, то он добавит его в выдачу.
Из-за этого здесь нужно вписывать только те веб-документы, до которых нельзя добраться иным путём , например, . И, конечно, sitemap для более качественной и быстрой индексации востребованных страниц.
HTTP заголовок
URL не будет проиндексирован, если показывает 404 или 301. А для Google, ещё и когда присутствует строка
X-Robots-Tag: noindex
Мета-теги robots
Это главный инструмент , потому что работает он и для Яндекса и для Гугла одинаково. На странице, доступ к содержимому которой должен быть запрещён, указывается:
Атрибут rel="canonical"
Обязательный атрибут rel="canonical" подсказывает предпочитаемый из нескольких web-документов с очень похожим содержанием, например, http://сайт/2010/07/kontent..html?showComment. Второй поисковая система проигнорирует, поскольку подчинится строке:
Яндекс.Вебмастер

media="print"
Не нужно создавать отдельную версию для печати. Стили можно скорректировать с помощью .
Удаление дубликатов, находящихся в индексе по ошибке
Несмотря на предпринятые меры, поисковые роботы могут проиндексировать нежелательную страницу. Задав запрос
Просмотрите всю выдачу, особенно с опущенными результатами в Гугле. В идеале этой надписи не должно быть:

Опущенные результаты надо убирать вручную. Для Yandex воспользуемся формой удаления страницы , а для Google нужно зайти в "Инструменты для веб-мастеров"-"Оптимизация"-"Удалить URL-адреса"-"Создать новый запрос на удаление".
Многие владельцы сайтов уделяют внимание главным образом тому, чтобы контент был уникален по сравнению с другими ресурсами. Однако не стоит упускать из виду наличие дублированного контента в пределах одного сайта. Это тоже оказывает сильное влияние на ранжирование.
Что такое дублированный контент
Повторяющийся, или дублированный, контент – это совпадающие в рамках сайта объемные блоки текста на разных страницах. Не обязательно такое делается со злым умыслом – чаще возникает по техническим причинам, подробно разобранные ниже.
Опасность состоит в том, что часто дублированный контент невозможно увидеть невооруженным глазом, однако поисковик его прекрасно видит и реагирует соответствующим образом.
Откуда берется дублированный контент и где он чаще встречается
Основные причины возникновения такого явления:
- Изменение структуры сайта;
- Намеренное использование в конкретных целях (скажем, версии для печати);
- Ошибочные действия программистов и веб-мастеров;
- Неувязки с CMS.
Например, часто встречается ситуация: replytocom (ответ на комментарий) в WordPress автоматически формирует и новые страницы с разными URL-адресами, но не содержимым.
Обычно дублированный контент замечается при создании анонсов статьи на других страницах сайта, размещении отзывов, а также при одинаковых описаниях товаров, категорий, рубрик.

Почему дублированный контент – это плохо
У повторяющегося содержимого есть аналог из области экономики – банковский овердрафт. Только здесь расходуется так называемый краулинговый бюджет. Это число страниц ресурса, которое за конкретный промежуток времени сможет просканировать поисковая машина. Ресурс очень ценный, и лучше потратить его на действительно важные и актуальные страницы, чем на десятки дублей идентичного текста.
Таким образом, дублированный контент ухудшает поисковое продвижение. Кроме того, теряются естественные ссылки и неверно распределяется ссылочный вес внутри сайта. А также подменяются по-настоящему релевантные страницы.
Как найти дублированный контент на сайте (вручную, программы и сервисы)
Существуют специальные программы для анализа ресурсов. Из них пользователи особенно выделяют Netpeak Spider. Она ищет полные копии страниц, совпадения по тайтлу или дескрипшену, заголовкам. Другой вариант — Screaming Frog, которая обладает схожим функционалом и по сути отличается только интерфейсом. Еще есть приложение Xenu`s Link Sleuth, работающее схожим с поисковиком образом и способное довольно качественно прочесать сайт на наличие дубликатов.

К сожалению, нет инструментов, способных полноценно отслеживать все дубли текста. Поэтому, скорее всего, придется производить ручную проверку. Вот список возможных факторов, повлекших за собой проблему:

Разобрались, как найти дублированный контент. А лучшие помощники в борьбе с ним – это переадресация 301, теги Canonical URL, указания в robots.txt и параметры Nofollow и Noindex в составе мета-тега «robots».
Одним из способов на скорую руку проверить, если ли на сайте дублированный контент, является расширенный поиск в Яндексе или Гугле. Необходимо ввести адрес сайта и кусок текста со страницы, которую решили проверить. Также можно использовать многочисленные программы для проверки уникальности текста:
- Text.Ru;
- eTXT Антиплагиат;
- Advego Plagiatus;
- Content-Watch.

Как бороться и чистить дублированный контент
Всё та же справочная система Гугл дает ряд советов по предотвращению появления данной проблемы.
- 301. При структурных изменениях ресурса необходимо указывать редирект 301 в файле htaccess.
- Используйте единый стандарт ссылок.
- Контент для конкретного региона лучше размещать на доменах верхнего уровня, чем на поддоменах или в поддиректориях.
- Устанавливайте предпочтительный способ индексирования с помощью Search Console.
- Не используйте шаблоны. Вместо того, чтобы на каждой странице размещать текст о защите авторского права, лучше сделать ссылку, которая будет вести на отдельную страницу с этим текстом.
- Разрабатывая новые страницы, следите, чтобы до полной готовности они были закрыты от индексации.
- Разберитесь, как именно отображается ваш контент – могут быть отличия отображения в блогах и форумах.
- Если на сайте много схожих статей, лучше или объединить их содержимое в одно целое, или уникализировать каждую.
Поисковиками не предусмотрено никаких санкций по отношению к сайтам, имеющим дублированный контент по техническим причинам (в отличие от тех, кто делает это намеренно с целью манипулировать результатами поиска или вводить в заблуждение посетителей).
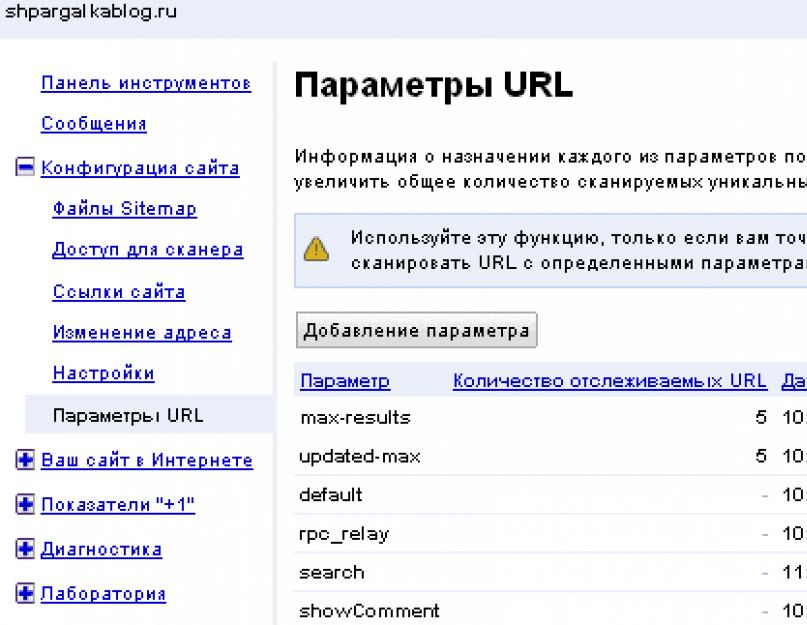
После того, как дубли удалены, осталось убрать их из поисковой выдачи. Яндекс делает это самостоятельно, при условии, что файл robots.txt настроен должным образом. Что касается Google: там придется вручную прописать правила в Вебмастере, на вкладке «Параметры URL».
Заключение
Борьба с дублированным контентом на сайте – важный аспект деятельности владельца любого сайта. Причин его возникновения довольно много, и столь же много способов устранения.
Однако главным правилом остается: размещать исключительно оригинальный контент, независимо от типа сайта. Даже если это крупный сетевой магазин с тысячами страниц.
ПОЛУЧАЙТЕ АНОНСЫ ПОДОБНЫХ ПОСТОВ СЕБЕ НА ПОЧТУ
Подпишитесь и получайте не чаще, чем раз в неделю что-нибудь интересное из мира интернет-маркетинга, SEO, продвижения сайтов, интернет-магазинов, заработка на сайтах.
Наверняка, вам не раз приходилось слышать словосочетание “дублированный контент” и вы, как опытный владелец сайта, никогда не стали бы размещать один и тот же контент дважды, не так ли?
Дублированный контент можно сравнить с банковским овердрафтом. Только в этом случае вы расходуете свой ценный краулинговый бюджет.
Краулинговый бюджет - это количество страниц на сайте, которое поисковый робот может сканировать за определенной отрезок времени. Поэтому так важно расходовать его на нужные нам страницы.
Проявляя себя в различных формах, дублированный контент может стать одной из самых неуловимых и невидимых проблем, которая может негативно влиять на ранжирование и продвижение сайта. Его появление зачастую связано с особенностями архитектуры сайта или ограничениями CMS.
К сожалению, нет такого чекера в Google Вебмастере, который бы мог легко обнаружить дубли контента. Даже самые продвинутые сторонние инструменты не всегда хорошо справляются с этой задачей, особенно, когда источник проблемы находится внутри. Ручной проверки не избежать.
Перед вами - список с 8 потенциальными причинами появления дублей страниц на сайте:
HTTP и HTTPS страницы
Одна из самых быстрых проверок того, что у вас есть две доступные к индексированию версии сайта - это попробовать зайти на него, используя как HTTP, так и HTTPS-протокол. Если обе версии открываются, очевидно, что ваш разработчик перевел сайт на HTTPS и не настроил 301 редирект с HTTP-версии.
До того как Google стал активно призывать веб-мастеров переводить свои сайты полностью на HTTPS, многие подключили HTTPS только на отдельных страницах, которые нуждались в дополнительной безопасности, например, страницы авторизации или страницы с транзакциями. Если разработчик использовал относительные ссылки, то каждый раз, когда поисковый робот посещает защищенные страницы, он вынужден добавлять HTTPS ко всем URL, что, в конечном счете, приводит к появлению дублей страниц.
Таким же образом, нужно проверить нет ли у сайта двух версий страниц как с WWW, так и без WWW. Решить эту проблему можно настроив 301 редирект и указав предпочитаемый домен (главное зеркало) в Google Вебмастере.
Cайты, ворующие ваш контент
До тех пор пока не существует законодательства, позволяющего вернуть вам украденный контент, есть только способы, которые вы можете использовать в коде, чтобы усложнить задачу ворам, пытающимся выдать ваш контент за свой собственный. Для этого всегда используйте на сайте абсолютные ссылки вместо относительных:
Абсолютные ссылки:
http://seo.artox-media.ru/wiki/dublirovannyi-kontent.html (начинается с указания протокола и содержит имя сайта).
Относительные ссылки:
/wiki/dublirovannyi-kontent.html (берет начало от корня сайта или текущего документа).
Почему это важно? При использовании относительных URL-адресов, ваш браузер предполагает, что ссылка указывает на страницу, на которой вы уже находитесь. Некоторые разработчики предпочитают относительные URL-адреса, потому что они упрощают процесс написания кода.
Если разработчик не желает переписывать весь сайт, можно использовать ссылающиеся на себя канонические теги. Когда ваш контент будет размещен на другом сайте, канонические теги могут остаться, помогая Google определить, что ваш сайт является первоисточником контента.
Чтобы узнать, что ваш контент украли, можно использовать любой из бесплатных сервисов (например, Siteliner, Copyscape. Etxt, AdvegoPlagiatus и др.)
Заброшенные поддомены
Предположим, вы отказались от какого-либо поддомена и решили использовать вместо этого субдиректорию. Или, например, вы создали совершенно новый сайт. В любом случае, ваш старый контент может быть доступен и, более того, он может плохо повлиять на ранжирование новых страниц. Для решения проблемы лучше всего использовать 301 редирект с этого субдомена на новый сайт/каталог. Это особенно важно, если ваш старый ресурс имеет большую ссылочную массу.
Скрытые страницы в стадии разработки
Решили обновить дизайн? Готовите ваш сайт к большим переменам? Если перед этим вы не закрыли свои тестовые страницы (а тем более дев-версии сайта) от индексации, то вы не застрахованы от того, что робот их не обнаружит.
Существует распространенное заблуждение, что никто никогда не догадается ввести в браузерную строку какой-то выдуманный URL на вашем сайте http://razrabotka.sait.ru/, если нигде нет ссылки на нее в коде, кажется, что это просто нереально. Но это не так! Google постоянно ищет и индексирует новые веб-страницы, в том числе и находящиеся в разработке. Все это может повлиять на результаты ранжирования, а также ввести пользователей в заблуждение.
Это не только наносит огромный урон сайту с точки зрения конфиденциальности и безопасности, но также может нанести серьезный ущерб краулинговому бюджету. Избежать этого просто: используйте мета-тег robots c noindex на всех тестовых страницах или заблокируйте их в файле robots.txt.
или
Оба варианта обозначают запрет на индексацию текста и переход по ссылкам на странице.
Помните, что, перенося страницы из дев-режима на лив, необходимо удалить эти блокирующие директивы из кода.
Динамически генерируемые параметры в URL
Чаще всего динамические URL генерируются на основе используемых на сайте фильтров. Как же именно выглядят такие URL?
URL 1: www.shop.com/chocolate/cake/vanilla
URL 2: www.shop.com/chocolate/cake/vanilla%8in
URL 3: www.shop.com/chocolate/cake/vanilla%8in=marble
Это простой пример, однако, ваша CMS может добавлять различные параметры фильтров и генерировать излишне длинные строки URL-адресов, которые могут участвовать в процессе сканирования поисковым роботом.
Таким образом, Google может создавать и индексировать бесконечные комбинации URL, которые пользователь даже не запрашивает.
В данном случае, примените канонический тег с указанием предпочитаемого URL и настройте параметры сканирования URL в Google Вебмастере.
.jpg)
Вы можете пропустить этот шаг и заблокировать определенные URL-адреса в файле robots.txt с использованием символа (*), чтобы запретить индексацию всего, что входит в указанный каталог. Например: Disallow:/chocolate/cake/*
Зеркальные подкаталоги
Ваш бизнес работает в нескольких регионах? Некоторые компании предпочитают создать основную целевую страницу, которая позволяет пользователям выбрать наиболее подходящий для них регион, а затем перенаправляет их в соответствующий подкаталог. Например:
URL 1: www.wonderfullywhisked.com/fr
URL 2: www.wonderfullywhisked.com/de
Хоть это и может казаться логичным, подумайте, действительно ли существует необходимость в этой настройке. Ведь, в то время как вы нацелены на разную аудиторию, есть вероятность, что оба подкаталога будут полностью дублировать друг друга по содержанию. Чтобы решить эту проблему, используйте Google Вебмастер для настройки геотаргетинга.
.jpg)
Синдицикация контента
Синдицикация контента - повторное использование одного и того же контента на разных ресурсах с целью продвижения вашего сайта/бренда/контента и привлечения дополнительного трафика.
Синдикация является отличным способом ознакомить новую аудиторию с вашим сайтом, однако, стоит определить правила для тех, кто будет перепубликовать ваш контент.
В идеале, необходимо попросить издателей использовать атрибут “rel=canonical” на странице материала, чтобы указать поисковым системам, что ваш веб-сайт является первоисточником контента. Кроме этого, они также могут закрыть контент от индексации, что позволит решить потенциальные проблемы с дублированием в результатах поиска.
В конце концов, издатели могут ссылаться на первоначальную статью с указанием вас как первоисточника.
Схожий контент
Схожий контент может причинить не меньше вреда, чем дублированный. В определении Google про дублированный контент даже фигурирует фраза «существенно похожий». И пусть части материала могут быть разными по синтаксису, общее правило заключается в том, что, если вы можете почерпнуть из них одну и ту же информацию, то нет никакой причины для существования на веб-сайте их обеих. Здесь, отличным вариантом решения проблемы является использование канонического тега или рассмотрение вопроса об объединении этих частей контента в один.
Выводы
Очень важно следить за появлением дублей контента на сайте, чтобы избежать израсходования вашего краулингового бюджета, ведь это препятствует поиску и индексированию роботом новых и нужных вам страниц. В данном случае, лучшими инструментами в вашем арсенале могут послужить канонические теги, 301 редирект, атрибуты nofollow/noindex в мета-теге "robots" и директивы в файле robots.txt. Работайте над выявлением и удалением дублированного контента, добавив эти пункты проверки в свой seo-аудит.
Многие владельцы сайтов уделяют внимание главным образом тому, чтобы контент был уникален по сравнению с другими ресурсами. Однако не стоит упускать из виду наличие дублированного контента в пределах одного сайта. Это тоже оказывает сильное влияние на ранжирование.
Что такое дублированный контент
Повторяющийся, или дублированный, контент – это совпадающие в рамках сайта объемные блоки текста на разных страницах. Не обязательно такое делается со злым умыслом – чаще возникает по техническим причинам, подробно разобранные ниже.
Опасность состоит в том, что часто дублированный контент невозможно увидеть невооруженным глазом, однако поисковик его прекрасно видит и реагирует соответствующим образом.
Откуда берется дублированный контент и где он чаще встречается
Основные причины возникновения такого явления:
- Изменение структуры сайта;
- Намеренное использование в конкретных целях (скажем, версии для печати);
- Ошибочные действия программистов и веб-мастеров;
- Неувязки с CMS.
Например, часто встречается ситуация: replytocom (ответ на комментарий) в WordPress автоматически формирует и новые страницы с разными URL-адресами, но не содержимым.
Обычно дублированный контент замечается при создании анонсов статьи на других страницах сайта, размещении отзывов, а также при одинаковых описаниях товаров, категорий, рубрик.
Почему дублированный контент – это плохо
У повторяющегося содержимого есть аналог из области экономики – банковский овердрафт. Только здесь расходуется так называемый краулинговый бюджет. Это число страниц ресурса, которое за конкретный промежуток времени сможет просканировать поисковая машина. Ресурс очень ценный, и лучше потратить его на действительно важные и актуальные страницы, чем на десятки дублей идентичного текста.
Таким образом, дублированный контент ухудшает поисковое продвижение. Кроме того, теряются естественные ссылки и неверно распределяется ссылочный вес внутри сайта. А также подменяются по-настоящему релевантные страницы.
Как найти дублированный контент на сайте (вручную, программы и сервисы)
Существуют специальные программы для анализа ресурсов. Из них пользователи особенно выделяют Netpeak Spider. Она ищет полные копии страниц, совпадения по тайтлу или дескрипшену, заголовкам. Другой вариант — Screaming Frog, которая обладает схожим функционалом и по сути отличается только интерфейсом. Еще есть приложение Xenu`s Link Sleuth, работающее схожим с поисковиком образом и способное довольно качественно прочесать сайт на наличие дубликатов.
К сожалению, нет инструментов, способных полноценно отслеживать все дубли текста. Поэтому, скорее всего, придется производить ручную проверку. Вот список возможных факторов, повлекших за собой проблему:
Разобрались, как найти дублированный контент. А лучшие помощники в борьбе с ним – это переадресация 301, теги Canonical URL, указания в robots.txt и параметры Nofollow и Noindex в составе мета-тега «robots».
Одним из способов на скорую руку проверить, если ли на сайте дублированный контент, является расширенный поиск в Яндексе или Гугле. Необходимо ввести адрес сайта и кусок текста со страницы, которую решили проверить. Также можно использовать многочисленные программы для проверки уникальности текста:
- Text.Ru;
- eTXT Антиплагиат;
- Advego Plagiatus;
- Content-Watch.
Как бороться и чистить дублированный контент
Всё та же справочная система Гугл дает ряд советов по предотвращению появления данной проблемы.
- 301. При структурных изменениях ресурса необходимо указывать редирект 301 в файле htaccess.
- Используйте единый стандарт ссылок.
- Контент для конкретного региона лучше размещать на доменах верхнего уровня, чем на поддоменах или в поддиректориях.
- Устанавливайте предпочтительный способ индексирования с помощью Search Console.
- Не используйте шаблоны. Вместо того, чтобы на каждой странице размещать текст о защите авторского права, лучше сделать ссылку, которая будет вести на отдельную страницу с этим текстом.
- Разрабатывая новые страницы, следите, чтобы до полной готовности они были закрыты от индексации.
- Разберитесь, как именно отображается ваш контент – могут быть отличия отображения в блогах и форумах.
- Если на сайте много схожих статей, лучше или объединить их содержимое в одно целое, или уникализировать каждую.
Поисковиками не предусмотрено никаких санкций по отношению к сайтам, имеющим дублированный контент по техническим причинам (в отличие от тех, кто делает это намеренно с целью манипулировать результатами поиска или вводить в заблуждение посетителей).
После того, как дубли удалены, осталось убрать их из поисковой выдачи. Яндекс делает это самостоятельно, при условии, что файл robots.txt настроен должным образом. Что касается Google: там придется вручную прописать правила в Вебмастере, на вкладке «Параметры URL».
Заключение
Борьба с дублированным контентом на сайте – важный аспект деятельности владельца любого сайта. Причин его возникновения довольно много, и столь же много способов устранения.
Однако главным правилом остается: размещать исключительно оригинальный контент, независимо от типа сайта. Даже если это крупный сетевой магазин с тысячами страниц.
ПОЛУЧАЙТЕ АНОНСЫ ПОДОБНЫХ ПОСТОВ СЕБЕ НА ПОЧТУ
Подпишитесь и получайте не чаще, чем раз в неделю что-нибудь интересное из мира интернет-маркетинга, SEO, продвижения сайтов, интернет-магазинов, заработка на сайтах.
Дублированный контент или просто дубли - это страницы на вашем сайте, которые полностью (четкие дубли) или частично (нечеткие дубли) совпадают друг с другом, но каждая из них имеет свой URL. Одна страница может иметь как один, так и несколько дублей.
Как появляется дублированный контент на сайте?
Как для четких, так и для нечетких дублей есть несколько причин возникновения. Четкие дубли могут возникнуть по следующим причинам:
- Они появляются из-за CMS сайта. Например, с помощью replytocom в WordPress, когда добавление новых комментариев создает автоматом и новые страницы, отличающиеся только URL.
- В результате ошибок веб-мастера.
- Из-за изменения структуры сайта. Например, при внедрении обновленного шаблона с новыми URL.
- Делаются владельцем сайта для определенных функций. Например, страницы с версиями текста для печати.
Нечеткие дубли на вашем сайте могут появиться по следующим причинам:
Почему дублированный контент вредит сайту?
- Негативно влияет на продвижение в поисковой выдаче. Поисковые роботы отрицательно относятся к дублированному контенту и могут понизить позиции в выдаче из-за отсутствия уникальности, а следовательно, и полезности для клиента. Нет смысла читать одно и то же на разных страницах сайта.
- Может подменить истинно-релевантные страницы. Робот может выбрать для выдачи дублированную страницу, если посчитает ее содержание более релевантным запросу. При этом у дубля, как правило, показатели поведенческих факторов и/или ссылочной массы ниже, чем у той страницы, которую вы целенаправленно продвигаете. А это значит, что дубль будет показан на худших позициях.
- Ведет к потере естественных ссылок. Когда пользователь делает ссылку не на прототип, а на дубль.
- Способствует неправильному распределению внутреннего ссылочного веса. Дубли перетягивают на себя часть веса с продвигаемых страниц, что также препятствует продвижению в поисковиках.
Как проверить, есть у вас дубли или нет?
Чтобы узнать, есть у страниц сайта дубли или нет, существует несколько способов.

Нашли дубли? Читаем, как их обезвредить:
- 301-й редирект Этот способ считается самым надежным при избавлении от лишних дублей на вашем сайте. Суть метода заключается в переадресации поискового робота со страницы-дубля на основную. Таким образом, робот проскакивает дубль и работает только с нужной страницей сайта. Со временем, после настройки 301-ого редиректа, страницы дублей склеиваются и выпадают из индекса.
- Тег . Здесь мы указываем поисковой системе, какая страница у нас основная, предназначенная для индексации. Для этого на каждом дубле надо вписать специальный код для поискового робота , который будет содержать адрес основной страницы. Чтобы не делать подобные работы вручную, существуют специальные плагины.
- Disallow в robots.txt . Файл robots.txt - своеобразная инструкция для поискового робота, в которой указано, какие страницы нужно индексировать, а какие нет. Для запрета индексации и борьбы с дублями используется директива Disallow. Здесь, как и при настройке 301-го редиректа, важно правильно прописать запрет.
Как убрать дубли из индекса поисковых систем?
Что касается Яндекса, то он самостоятельно убирает дубли из индекса при правильной настройке файла robots.txt. А вот для Google надо прописывать правила во вкладке «Параметры URL» через Google Вебмастер.
Если у вас возникнут трудности с проверкой и устранением дублированного контента, вы всегда можете обратиться к нашим специалистам. Мы найдем все подозрительные элементы, настроим 301-й редирект, robots.txt, rel= "canonical", сделаем настройки в Google . В общем, проведем все работы, чтобы ваш сайт эффективно работал.