/ Просм: 21952
Здравствуйте уважаемые друзья ! Проверка robots.txt также важна, как и его правильное составление.
Проверка файла robots.txt в панели Yandex и Google Webmasters.
Проверка robots.txt, почему важно проверить?
Рано или поздно каждый уважающий себя автор сайта вспоминает про файл robots . Про этот файл, размещаемый в корне сайта, написано в интернете предостаточно. Почти у каждого вебмастера есть на сайте про актуальность и правильность составления его. Я же в этой статье напомню начинающим блоггерам как проверить его с помощью инструментов в панели вебмастера, предоставляемые Yandex и Google.
Для начала немного о нем. Файл Robots.txt (иногда ошибочно называемый robot.txt, в единственном числе, внимание английская буква s в конце обязательна) создается веб-мастерам, чтобы отметить или запретить те или иные файлы и папки веб-сайта, для поисковых пауков (а также других типов роботов). Т. е. те файлы, к которым робот поисковика не должен иметь доступ.
Проверка robots.txt является для автора сайта обязательным атрибутом при создании блога на WordPress и его дальнейшем продвижении. Многие вебмастера также обязательно просматривают страниц проекта. Анализ дает понять роботам правильный синтаксис, чтобы убедиться, в его действительном формате. Дело в том, что существует установленный Стандарт исключений для роботов. Будет не лишним узнать мнение самих поисковиков, читайте документацию, в ней поисковые системы подробно излагают свое видение насчет этого файла.
Все это будет не лишним, дабы впредь обезопасить свой сайт от ошибок при индексировании. Знаю примеры, когда из-за неправильного составленного файла, был дан сигнал запретить его видимость в сети. При дальнейшем его исправлении можно долго ждать изменения ситуации вокруг сайта.
Останавливаться на правильном составлении самого файла в этой статье не буду. Примеров в сети множество, можете зайти на блог любого популярного блоггера и приписать в конце его домена для проверки /robots.txt. Браузер покажет его вариант, который вы можете взять за основу. Однако у каждого бывают свои исключения, поэтому необходимо проверить именно для своего сайта на соответствие. Также описание и пример правильного текста для блога на WordPress находиться по адресу:
Sitemap: http: // ваш сайт/sitemap.xml
User-agent: Googlebot-Image
# Google AdSense
User-agent: Mediapartners-Google*
User-agent: duggmirror
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/cache/
Disallow: /wp-content/themes/
Disallow: /trackback/
Disallow: /feed/
Disallow: /comments/
Disallow: /category/*/*
Disallow: */trackback/
Disallow: */feed/
Disallow: */comments/
Allow: /wp-content/uploads/
Существуют некоторые различия в составлении и дальнейшей проверки файла robots.txt для основных поисковых систем Рунета. Ниже приведу примеры, как проверить в панели Яндекс Вебмастер и Google.
После того как вы составили файл и закинули его в корень своего сайта по FTP необходимо провести проверку его на соответствие к примеру поисковой системе Яндекс. Тем самым мы узнаем, не закрыли ли мы случайно те страницы, благодаря которым к вам придут посетители.
Проверка robots.txt в панели Yandex Webmaster
У вас должен быть аккаунт в панели Яндекс Вебмастер. Зайдя в инструменты и указав свой сайт, справа будет перечень доступных возможностей. Переходим на вкладку «Проверить robots.txt»
Указываем свой домен и жмем «Загрузить robots.txt с сайта». Если у вас составлен файл, в котором указано отдельно для каждой поисковой системы, то необходимо выбрать строки для Яндекс и скопировать их в поле ниже. Напоминаю, директива Host: актуальна для Янд., поэтому не забудьте внести в поле для проверки. Осталось сделать проверку robots.txt. Кнопка справа.

Буквально сразу увидите анализ от Яндекс на соответствие вашего robots.txt. Ниже будет указаны строки, которые Янд. принял к рассмотрению. И смотрим результаты проверки. Слева Url указаны директивы. Справа напротив сам результат. Как видно на скриншоте, правильно будет увидеть красным цветом надпись – запрещен правилом и указано само правило. Если вы указали директиву для индексации, то увидим зеленым – разрешен.
После проверки robots.txt, вы сможете подкорректировать свой файл. Также рекомендую проверить страницы сайта. Вставляем url адрес отдельной записи в поле /Список URL/. И на выходе получаем результат – разрешен. Так мы сможет отдельно проверить запреты на архивы, рубрики и далее.
Не забываем подписываться, в следующей статье планирую показать, как бесплатно пройти регистрацию в каталог Mail.ru. Не пропустите, .
Как проверить в Yandex Webmasters.
Проверить robots.txt в панели Google Webmasters
Заходим в свой аккаунт и ищем слева /Состояние/ – /Заблокированные URL/Здесь увидим его наличие и возможность отредактировать. При необходимости проверки всего сайта на соответствие указываем в поле ниже адрес главной страницы. Имеется возможность проверить, как видят разные роботы Google ваш сайт с учетом проверки файла robots.txt

Кроме основного бота Google выбираем и робота специализирующегося на разных видах контента (2). Скриншот ниже.
- Googlebot
- Googlebot-Image
- Googlebot-Mobile
- Mediapartners-Google – показатели для AdSense
- AdsBot-Google – проверка качества целевой стр.
Показатели для других роботов Гугл я не нашел:
- Googlebot Video
- Googlebot-News

По аналогии с проверкой файла роботс.тхт в панели Яндекс, здесь также есть возможность проанализировать отдельную страницу сайта. После проверки вы увидите результат отдельно для каждого поискового бота.
При условии, что результаты проверки вас не устроили, вам остается дальше продолжить редактировать. И в дальнейшем проверка.
Анализ robots.txt онлайн
Кроме этих возможностей, вы также можете сделать анализ файла robots.txt с помощью онлайн сервисов. Те которые я находил в основном англоязычные. Мне понравился этот сервис. После анализа будут даны рекомендации по его исправлению.
tool.motoricerca.info/robots-checker.phtml
На этом все. Надеюсь, проверка файла robots.txt глазами Яндекс и Google вас не расстроила? Если же увидели не соответствие вашим желаниям, то всегда можно отредактировать и затем сделать повторный анализ. Спасибо за ваш твит в Twitter и лайк в Facebook!
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Robots.txt — директива user-agent и боты поисковых систем
Роботс.тхт имеет совсем не сложный синтаксис, который очень подробно описан, например, в хелпе яндекса и хелпе Гугла . Обычно в нем указывается, для какого поискового бота предназначены описанные ниже директивы: имя бота ("User-agent "), разрешающие ("Allow ") и запрещающие ("Disallow "), а также еще активно используется "Sitemap" для указания поисковикам, где именно находится файл карты.
Стандарт создавался довольно давно и что-то было добавлено уже позже. Есть директивы и правила оформления, которые будут понятны только роботами определенных поисковых систем. В рунете интерес представляют в основном только Яндекс и Гугл, а значит именно с их хелпами по составлению robots.txt следует ознакомиться особо детально (ссылки я привел в предыдущем абзаце).
Например, раньше для поисковой системы Яндекс было полезным указать, вашего вебпроекта является главным в специальной директиве "Host", которую понимает только этот поисковик (ну, еще и Майл.ру, ибо у них поиск от Яндекса). Правда, в начале 2018 Яндекс все же отменил Host и теперь ее функции как и у других поисковиков выполняет 301-редирект.
Если даже у вашего ресурса нет зеркал, то полезно будет указать, какой из вариантов написания является главным - .
Теперь поговорим немного о синтаксисе этого файла. Директивы в robots.txt имеют следующий вид:
<поле>:<пробел><значение><пробел> <поле>:<пробел><значение><пробел>
Правильный код должен содержать хотя бы одну директиву «Disallow» после каждой записи «User-agent». Пустой файл предполагает разрешение на индексирование всего сайта.
User-agent
Директива «User-agent» должна содержать название поискового бота. При помощи нее можно настроить правила поведения для каждого конкретного поисковика (например, создать запрет индексации отдельной папки только для Яндекса). Пример написания «User-agent», адресованной всем ботам зашедшим на ваш ресурс, выглядит так:
User-agent: *
Если вы хотите в «User-agent» задать определенные условия только для какого-то одного бота, например, Яндекса, то нужно написать так:
User-agent: Yandex
Название роботов поисковых систем и их роль в файле robots.txt
Бот каждой поисковой системы имеет своё название (например, для рамблера это StackRambler). Здесь я приведу список самых известных из них:
Google http://www.google.com Googlebot Яндекс http://www.ya.ru Yandex Бинг http://www.bing.com/ bingbot
У крупных поисковых систем иногда, кроме основных ботов , имеются также отдельные экземпляры для индексации блогов, новостей, изображений и т.д. Много информации по разновидностям ботов вы можете почерпнуть (для Яндекса) и (для Google).
Как быть в этом случае? Если нужно написать правило запрета индексации, которое должны выполнить все типы роботов Гугла, то используйте название Googlebot и все остальные пауки этого поисковика тоже послушаются. Однако, можно запрет давать только, например, на индексацию картинок, указав в качестве User-agent бота Googlebot-Image. Сейчас это не очень понятно, но на примерах, я думаю, будет проще.
Примеры использования директив Disallow и Allow в роботс.тхт
Приведу несколько простых примеров использования директив с объяснением его действий.
- Приведенный ниже код разрешает всем ботам (на это указывает звездочка в User-agent) проводить индексацию всего содержимого без каких-либо исключений. Это задается пустой директивой Disallow . User-agent: * Disallow:
- Следующий код, напротив, полностью запрещает всем поисковикам добавлять в индекс страницы этого ресурса. Устанавливает это Disallow с «/» в поле значения. User-agent: * Disallow: /
- В этом случае будет запрещаться всем ботам просматривать содержимое каталога /image/ (http://mysite.ru/image/ — абсолютный путь к этому каталогу) User-agent: * Disallow: /image/
- Чтобы заблокировать один файл, достаточно будет прописать его абсолютный путь до него (читайте ):
User-agent: *
Disallow: /katalog1//katalog2/private_file.html
Забегая чуть вперед скажу, что проще использовать символ звездочки (*), чтобы не писать полный путь:
Disallow: /*private_file.html
- В приведенном ниже примере будут запрещены директория «image», а также все файлы и директории, начинающиеся с символов «image», т. е. файлы: «image.htm», «images.htm», каталоги: «image», «images1», «image34» и т. д.): User-agent: * Disallow: /image Дело в том, что по умолчанию в конце записи подразумевается звездочка, которая заменяет любые символы, в том числе и их отсутствие. Читайте об этом ниже.
- С помощью директивы Allow
мы разрешаем доступ. Хорошо дополняет Disallow. Например, таким вот условием поисковому роботу Яндекса мы запрещаем выкачивать (индексировать) все, кроме вебстраниц, адрес которых начинается с /cgi-bin:
User-agent: Yandex
Allow: /cgi-bin
Disallow: /
Ну, или такой вот очевидный пример использования связки Allow и Disallow:
User-agent: * Disallow: /catalog Allow: /catalog/auto
- При описании путей для директив Allow-Disallow можно использовать символы "*" и "$"
, задавая, таким образом, определенные логические выражения.
- Символ "*"(звездочка) означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов с расширение «.php»: User-agent: * Disallow: *.php$
- Зачем нужен на конце знак $ (доллара)
? Дело в том, что по логике составления файла robots.txt, в конце каждой директивы как бы дописывается умолчательная звездочка (ее нет, но она как бы есть). Например мы пишем:
Disallow: /images
Подразумевая, что это то же самое, что:
Disallow: /images*
Т.е. это правило запрещает индексацию всех файлов (вебстраниц, картинок и других типов файлов) адрес которых начинается с /images, а дальше следует все что угодно (см. пример выше). Так вот, символ $ просто отменяет эту умолчательную (непроставляемую) звездочку на конце. Например:
Disallow: /images$
Запрещает только индексацию файла /images, но не /images.html или /images/primer.html. Ну, а в первом примере мы запретили индексацию только файлов оканчивающихся на.php (имеющих такое расширение), чтобы ничего лишнего не зацепить:
Disallow: *.php$
Звездочка после вопросительного знака напрашивается, но она, как мы с вами выяснили чуть выше, уже подразумевается на конце. Таким образом мы запретим индексацию страниц поиска и прочих служебных страниц создаваемых движком, до которых может дотянуться поисковый робот. Лишним не будет, ибо знак вопроса чаще всего CMS используют как идентификатор сеанса, что может приводить к попаданию в индекс дублей страниц.
Директивы Sitemap и Host (для Яндекса) в Robots.txt
Во избежании возникновения неприятных проблем с зеркалами сайта, раньше рекомендовалось добавлять в robots.txt директиву Host, которая указывал боту Yandex на главное зеркало.
Директива Host — указывает главное зеркало сайта для Яндекса
Например, раньше, если вы еще не перешли на защищенный протокол , указывать в Host нужно было не полный Урл, а доменное имя (без http://, т.е..ru). Если же уже перешли на https, то указывать нужно будет полный Урл (типа https://myhost.ru).
Замечательный инструмент для борьбы с дублями контента — поисковик просто не будет индексировать страницу, если в Canonical прописан другой урл. Например, для такой страницы моего блога (страницы с пагинацией) Canonical указывает на https://сайт и никаких проблем с дублированием тайтлов возникнуть не должно.
Но это я отвлекся...
Если ваш проект создан на основе какого-либо движка, то дублирование контента будет иметь место с высокой вероятностью, а значит нужно с ним бороться, в том числе и с помощью запрета в robots.txt, а особенно в мета-теге, ибо в первом случае Google запрет может и проигнорировать, а вот на метатег наплевать он уже не сможет (так воспитан).
Например, в WordPress страницы с очень похожим содержимым могут попасть в индекс поисковиков, если разрешена индексация и содержимого рубрик, и содержимого архива тегов, и содержимого временных архивов. Но если с помощью описанного выше мета-тега Robots создать запрет для архива тегов и временного архива (можно теги оставить, а запретить индексацию содержимого рубрик), то дублирования контента не возникнет. Как это сделать описано по ссылке приведенной чуть выше (на плагин ОлИнСеоПак)
Подводя итог скажу, что файл Роботс предназначен для задания глобальных правил запрета доступа в целые директории сайта, либо в файлы и папки, в названии которых присутствуют заданные символы (по маске). Примеры задания таких запретов вы можете посмотреть чуть выше.
Теперь давайте рассмотрим конкретные примеры роботса, предназначенного для разных движков — Joomla, WordPress и SMF. Естественно, что все три варианта, созданные для разных CMS, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, у всех у них будет один общий момент, и момент этот связан с поисковой системой Яндекс.
Т.к. в рунете Яндекс имеет достаточно большой вес, то нужно учитывать все нюансы его работы, и тут нам поможет директива Host . Она в явной форме укажет этому поисковику главное зеркало вашего сайта.
Для нее советуют использовать отдельный блог User-agent, предназначенный только для Яндекса (User-agent: Yandex). Это связано с тем, что остальные поисковые системы могут не понимать Host и, соответственно, ее включение в запись User-agent, предназначенную для всех поисковиков (User-agent: *), может привести к негативным последствиям и неправильной индексации.
Как обстоит дело на самом деле — сказать трудно, ибо алгоритмы работы поиска — это вещь в себе, поэтому лучше сделать так, как советуют. Но в этом случае придется продублировать в директиве User-agent: Yandex все те правила, что мы задали User-agent: * . Если вы оставите User-agent: Yandex с пустым Disallow: , то таким образом вы разрешите Яндексу заходить куда угодно и тащить все подряд в индекс.
Robots для WordPress
Не буду приводить пример файла, который рекомендуют разработчики. Вы и сами можете его посмотреть. Многие блогеры вообще не ограничивают ботов Яндекса и Гугла в их прогулках по содержимому движка WordPress. Чаще всего в блогах можно встретить роботс, автоматически заполненный плагином .
Но, по-моему, все-таки следует помочь поиску в нелегком деле отсеивания зерен от плевел. Во-первых, на индексацию этого мусора уйдет много времени у ботов Яндекса и Гугла, и может совсем не остаться времени для добавления в индекс вебстраниц с вашими новыми статьями. Во-вторых, боты, лазящие по мусорным файлам движка, будут создавать дополнительную нагрузку на сервер вашего хоста, что не есть хорошо.
Мой вариант этого файла вы можете сами посмотреть. Он старый, давно не менялся, но я стараюсь следовать принципу «не чини то, что не ломалось», а вам уже решать: использовать его, сделать свой или еще у кого-то подсмотреть. У меня там еще запрет индексации страниц с пагинацией был прописан до недавнего времени (Disallow: */page/), но недавно я его убрал, понадеясь на Canonical, о котором писал выше.
А вообще, единственно правильного файла для WordPress, наверное, не существует. Можно, кончено же, реализовать в нем любые предпосылки, но кто сказал, что они будут правильными. Вариантов идеальных robots.txt в сети много.
Приведу две крайности :
- можно найти мегафайлище с подробными пояснениями (символом # отделяются комментарии, которые в реальном файле лучше будет удалить): User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команду Host понимает # Яндекс и Mail.RU, Google не учитывает. Host: www.site.ru
- А вот можно взять на вооружение пример минимализма: User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Host: https://site.ru Sitemap: https://site.ru/sitemap.xml
Истина, наверное, лежит где-то посредине. Еще не забудьте прописать мета-тег Robots для «лишних» страниц, например, с помощью чудесного плагина — . Он же поможет и Canonical настроить.
Правильный robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/
В принципе, здесь практически все учтено и работает он хорошо. Единственное, в него следует добавить отдельное правило User-agent: Yandex для вставки директивы Host, определяющей главное зеркало для Яндекса, а так же указать путь к файлу Sitemap.
Поэтому в окончательном виде правильный robots для Joomla, по-моему мнению, должен выглядеть так:
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /component/tags* Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Host: vash_sait.ru (или www.vash_sait.ru) User-agent: * Allow: /*.css?*$ Allow: /*.js?*$ Allow: /*.jpg?*$ Allow: /*.png?*$ Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /layouts/ Disallow: /cli/ Disallow: /bin/ Disallow: /logs/ Disallow: /components/ Disallow: /component/ Disallow: /*mailto/ Disallow: /*.pdf Disallow: /*% Disallow: /index.php Sitemap: http://путь к вашей карте XML формата
Да, еще обратите внимание, что во втором варианте есть директивы Allow, разрешающие индексацию стилей, скриптов и картинок . Написано это специально для Гугла, ибо его Googlebot иногда ругается, что в роботсе запрещена индексация этих файлов, например, из папки с используемой темой оформления. Даже грозится за это понижать в ранжировании.
Поэтому заранее все это дело разрешаем индексировать с помощью Allow. То же самое, кстати, и в примере файла для Вордпресс было.
Удачи вам! До скорых встреч на страницах блога сайт
посмотреть еще ролики можно перейдя на");">Вам может быть интересно
Домены с www и без него - история появления, использование 301 редиректа для их склеивания
Зеркала, дубли страниц и Url адреса - аудит вашего сайта или что может быть причиной краха при его SEO продвижении

В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.
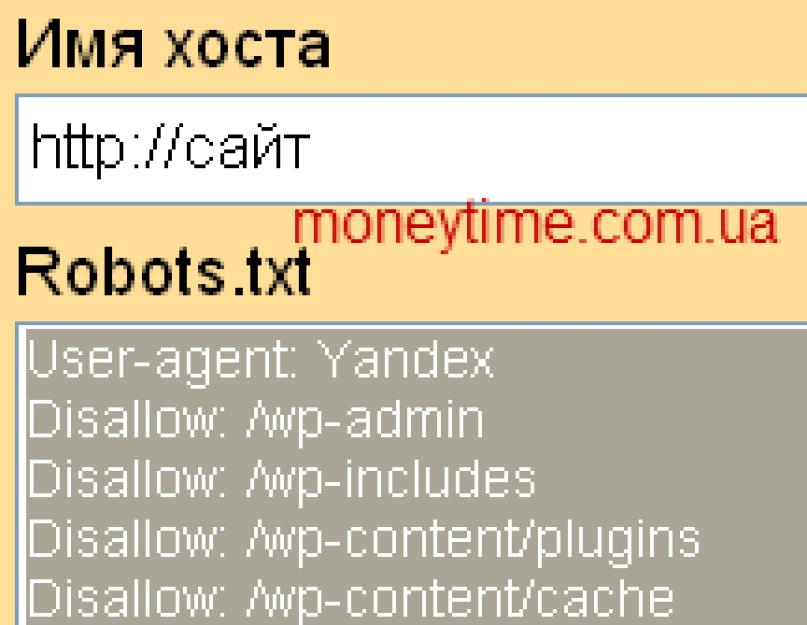
Итак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:

В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Allow: /wp-content/uploads/
User - agent : * Disallow : / wp - admin Disallow : / wp - includes Disallow : / wp - content Allow : / wp - content / uploads / |
Все вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
Disallow: /wp-feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/
Disallow : / wp - feed Тут уже нужно бороться по-другому. Например, с помощью редиректов или плагинов, которые будут уничтожать дубли. Впрочем, это уже тема для отдельной статьи. Где находится robots.txt?Этот файл всегда находится в корне сайта, поэтому мы и можем обратиться к нему, прописав адрес сайта и название файла через слэш. По-моему, тут все максимально просто. В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. О настройке я также напишу еще 1-2 статьи в ближайшее время, потому что в этой статье мы рассмотрели не все. Кстати, также много информации по продвижению сайтов-блогов вы можете найти в нашем . А я на этом пока прощаюсь с вами. |
Правильная индексация страниц сайта в поисковых системах одна из важных задач, которая стоит перед владельцем ресурса. Попадание в индекс ненужных страниц может привести к понижению документов в выдаче. Для решения таких проблем и был принят стандарт исключений для роботов консорциумом W3C 30 января 1994 года - robots.txt.
Что такое Robots.txt?
Robots.txt - текстовый файл на сайте, содержащий инструкции для роботов какие страницы разрешены для индексации, а какие нет. Но это не является прямыми указаниями для поисковых машин, скорее инструкции несут рекомендательный характер, например, как пишет Google, если на сайт есть внешние ссылки, то страница будет проиндексирована.
На иллюстрации можно увидеть индексацию ресурса без файла Robots.txt и с ним.
Что следует закрывать от индексации:
- служебные страницы сайта
- дублирующие документы
- страницы с приватными данными
- результат поиска по ресурсу
- страницы сортировок
- страницы авторизации и регистрации
- сравнения товаров
Как создать и добавить Robots.txt на сайт?
Robots.txt обычный текстовый файл, который можно создать в блокноте, следуя синтаксису стандарта, который будет описан ниже. Для одного сайта нужен только один такой файл.
Файл нужно добавить в корневой каталог сайта и он должен быть доступен по адресу: http://www.site.ru/robots.txt
Синтаксис файла robots.txt
Инструкции для поисковых роботов задаются с помощью директив с различными параметрами.
Директива User-agent
С помощью данной директивы можно указать для какого робота поисковой системы будут заданы нижеследующие рекомендации. Файл роботс должен начинаться с этой директивы. Всего официально во всемирной паутине таких роботов 302. Но если не хочется их все перечислять, то можно воспользоваться следующей строчкой:
Где * является спецсимволом для обозначения любого робота.
Список популярных поисковых роботов:
- Googlebot — основной робот Google;
- YandexBot — основной индексирующий робот;
- Googlebot-Image — робот картинок;
- YandexImages — робот индексации Яндекс.Картинок;
- Yandex Metrika — робот Яндекс.Метрики;
- Yandex Market— робот Яндекс.Маркета;
- Googlebot-Mobile —индексатор мобильной версии.
Директивы Disallow и Allow
С помощью данных директив можно задавать какие разделы или файлы можно индексировать, а какие не следует.
Disallow - директива для запрета индексации документов на ресурсе. Синтаксис директивы следующий:
Disallow: /site/
В данном примере от поисковиков были закрыты от индексации все страницы из раздела site.ru/site/
Примечание: Если данная директива будет указана пустой, то это означает, что весь сайт открыт для индексации. Если же указать Disallow: / - это закроет весь сайт от индексации.
-
Для запрета папки сайта следует указать следующее:
Disallow: /folder/ -
Для запрета только одного файла нужно написать:
Disallow: /folder/img.jpg -
Если нужно запретить файлы только определенного разрешения:
Disallow: /*.css$ -
Allow напротив является разрешающей инструкцией для индексации.
User-agent: *
Allow: /site
Disallow: /Такая инструкция запрещает индексировать весь сайт, за исключением папки site.
Директива Sitemap
Если на сайте есть файл описания структуры сайта sitemap.xml, путь к нему можно указать в robots.txt с помощью директивы Sitemap. Если файлов таких несколько, то можно их перечислить в роботсе:
User-agent: *
Disallow: /site/
Allow: /
Sitemap
: http://site.com/sitemap1.xml
Sitemap
: http://site.com/sitemap2.xml
Директиву можно указать в любой из инструкций для любого робота.
Директива Host
Host является инструкцией непосредственно для робота Яндекса для указания главного зеркала сайта. Данная директива необходима в том случае, если у сайта есть несколько доменов, по которым он доступен. Указывать Host необходимо в секции для роботов Яндекса:
User-agent: Yandex
Disallow: /site/
Host
: site.ru
Примечание:
Если главным зеркалом сайта является домен с протоколом https, то его нужно указать в роботсе таким образом:
Host: https://site.ru.
В роботсе директива Host учитывается только один раз. Если в файле есть 2 директивы HOST, то роботы Яндекса будут учитывать только первую.
Директива Clean-param
Clean-param дает возможность запретить для индексации страницы сайта, которые формируются с динамическими параметрами. Такие страницы могут содержать один и тот же контент, что будет являться дублями для поисковых систем и может привести к понижению сайта в выдаче.
Директива Clean-param имеет следующий синтаксис:
Clean-param : p1[&p2&p3&p4&..&pn] [Путь к динамическим страницам]
Рассмотрим пример, на сайте есть динамические страницы:
- https://site.ru/promo-odezhda/polo.html?kol_from=&price_to=&color=7
- https://site.ru/promo-odezhda/polo.html?kol_from=100&price_to=&color=7
Для того, чтобы исключить подобные страницы из индекса следует задать директиву таким образом:
Clean-param
: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param
: kol_from1&price_to2&pcolor / # для всех страниц сайта
Директива Crawl-delay
Если роботы поисковиков слишком часто заходят на ресурс, это может повлиять на нагрузку на сервер (актуально для ресурсов с большим количеством страниц). Чтобы снизить нагрузку на сервер, можно воспользоваться директивой Crawl-delay.
Параметром для Crawl-delay является время в секундах, которое указывает роботам, что страницы следует скачивать с сайта не чаще одного раза в указанный период.
Пример использования директивы Crawl-delay:
User-agent: *
Disallow: /site
Crawl-delay
: 4
Особенности файла Robots.txt
- Все директивы указываются с новой строки и не следует перечислять директивы в одной строке
- Перед директивой не должно быть указано каких-либо других символов (в том числе пробела )
- Параметры директив необходимо указывать в одну строку
- Правила в роботс указываются в следующей форме: [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]
- Параметры не нужно указывать в кавычках или других символах
- После директив не следует указывать “;”
- Пустая строка трактуется как конец директивы User-agent, если нет пустой строки перед следующим User-agent, то она может быть проигнорирована
- В роботс можно указывать комментарии после знака решетки # (даже если комментарий переносится на следующую строку, на след строке тоже следует поставить #)
- Robots.txt нечувствителен к регистру
- Если файл роботс имеет вес более 32 Кб или по каким-то причинам недоступен или является пустым, то он воспринимается как Disallow: (можно индексировать все)
- В директивах «Allow», «Disallow» можно указывать только 1 параметр
- В директивах «Allow», «Disallow» в параметре директории сайта указываются со слешем (например, Disallow: /site)
- Использование кириллицы в роботс не допускаются
Спецсимволы robots.txt
При указании параметров в директивах Disallow и Allow разрешается использовать специальные символы * и $, чтобы задавать регулярные выражения. Символ * означает любую последовательность символов (даже пустую).
Пример использования:
User-agent: *
Disallow: /store/*
.php # запрещает "/store/ex.php" и "/store/test/ex1.php"
Disallow: /*
tpl # запрещает не только "/tpl", но и "/tpl/user"
По умолчанию у каждой инструкции в роботсе в конце подставляется спецсимвол *. Для того, чтобы отменить * на конце, используется спецсимвол $ (но он не может отменить явно поставленный * на конце).
Пример использования $:
User-agent: *
Disallow: /site$
# запрещено для индексации "/site", но не запрещено"/ex.css"
User-agent: *
Disallow: /site # запрещено для индексации и "/site", и "/site.css"
User-agent: *
Disallow: /site$
# запрещен к индексации только "/site"
Disallow: /site*$
# так же, как "Disallow: /site" запрещает и /site.css и /site
Особенности настройки robots.txt для Яндекса
Особенностями настройки роботса для Яндекса является только наличие директории Host в инструкциях. Рассмотрим корректный роботс на примере:
User-agent: Yandex
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Disallow: */css
Host: www.site.com
В данном случаем директива Host указывает роботам Яндекса, что главным зеркалом сайта является www.site.com (но данная директива носит рекомендательный характер).
Особенности настройки robots.txt для Google
Для Google особенность лишь состоит в том, что сама компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. В таком случае, робот примет такой вид:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *.js
Host: www.site.com
С помощью директив Allow роботам Google доступны файлы стилей и скриптов, они не будут проиндексированы поисковой системой.
Проверка правильности настройки роботс
Проверить robots.txt на ошибки можно с помощью инструмента в панели Яндекс.Вебмастера :

Также при помощи данного инструмента можно проверить разрешены или запрещены к индексации страницы:

Еще одним инструментом проверки правильности роботс является “Инструмент проверки файла robots.txt” в панели Google Search Console:

Но данный инструмент доступен только в том случае, если сайт добавлен в панель Вебмастера Google.
Заключение
Robots.txt является важным инструментом управления индексацией сайта поисковыми системами. Очень важно держать его актуальным, и не забывать открывать нужные документы для индексации и закрывать те страницы, которые могут повредить хорошему ранжированию ресурса в выдаче.
Пример настройки роботс для WordPress
Правильный robots.txt для Wordpress должен быть составлен таким образом (все, что указано в комментариях не обязательно размещать):
User-agent: Yandex
Host: www.site.ru
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *.css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ru/sitemap1.xml
Пример настройки роботс для Bitrix
Если сайт работает на движке Битрикс, то могут возникнуть такие проблемы:
- попадание в выдачу большого количества служебных страниц;
- индексация дублей страниц сайта.
Чтобы избежать подобных проблем, которые могут повлиять на позицию сайта в выдаче, следует правильно настроить файл robots.txt. Ниже приведен пример robots.txt для CMS 1C-Bitrix:
User-Agent: Yandex
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
HOST: https://site.ru
User-Agent: *
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /personal/cart/
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter.php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ru/sitemap.xml
Пример настройки роботс для OpenCart
Правильный robots.txt для OpenCart должен быть составлен таким образом:
User-agent: Yandex
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Host: site.ru
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Umi.CMS
Правильный robots.txt для Umi CMS должен быть составлен таким образом (проблемы с дублями страниц в таком случае не должно быть):
User-Agent: Yandex
Disallow: /?
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Host: site.ru
User-Agent: Googlebot
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Allow: *.css
Allow: *.js
User-Agent: *
Disallow: /?
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /go_out.php
Disallow: /images
Disallow: /files
Disallow: /users
Disallow: /admin
Disallow: /search
Disallow: /install-temp
Disallow: /install-static
Disallow: /install-libs
Sitemap: http://site.ru/sitemap.xml
Пример настройки роботс для Joomla
Правильный robots.txt для Джумлы должен быть составлен таким образом:
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Host: www.site.ru
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www.site.ru/sitemap.xml
У меня подготовлены отмазки от "день рождения был 21-го" и до "магнитных бурь" :)
Но действительно, я накосячил, когда писал.
Disallow без указания значения = разрешение к индексации сайта.
Валерия Очереднюк
Исправили.
Пані Яновська
Когда Вы уже начнете понимать разницу между сканированием и индексированием? Уже и справку Гугла по robots.txt исправили, а все пишут запрещает индексирование. Директивы файла robots.txt носят рекомендационный характер и только на сканирование.
Справедливо, но не в контексте robots.txt и людей, которым она нужна.
Т.е. конечная цель - не допустить попадания в индекс, соответственно людям будет понятнее "запрет к индексированию" и это будет верно (если краулер не может просканировать страницу, соответственно он не может ее проиндексировать). Отталкиваемся исходя из аудитории, которой нужна данная информация.
Пані Яновська
Странный ответ, я так считал, что тут публикуются материалы, которые соответствуют справочным материалам поисковых систем.
В случае с Гугл, такие страницы закрытые в robots.txt от сканирования, могут быть в индексе, правда в скрытых результатах.
При внедрении новой консоли гугл, многие вебмастера были приятно удивлены сообщением "Проиндексировано, несмотря на блокировку в файле robots.txt".
https://yandex.ru/support/w... - справка Яндекса. В видео говорить "запрет на индексацию всего сайта". Логично, страницы, которые краулер не может просканировать, индексатор соответственно не может проиндексировать. Но конечное действие в случае с Яндексом - страница с запретом в robots.txt не попадет в индекс.
В случае Google - всё иначе, о чем указано в статье.
Насчет новой консоли это вы про ребрендинг из GWT в Google Search Console в 2015 (или около того)? Если да, то Google мог игнорировать robots.txt еще и раньше.
Читатель
Дякую, мріяв про таку статтю
Подскажите плизз вот что, не могу разобраться.
1. Чем отличаются команды
Disallow: /wp-admin/ от Disallow: /wp-admin или Disallow: /wp-
2. Кажется в инструкции Гугл написано что нельзя от ботов скрывать файлы css и js но какая команда подойдет т.к. все рекомендуют по разному:
Allow: /*/*.js или Allow: /*.js или Allow: *.js или /wp-content/*.js
3. Также и картинки чтобы индексировались нужно открыть для индексации. Дело в том что при публикации картинок Вордпресс автоматически создает свою страницу для каждой картинки (URL) такая страница если на нее зайти по прямой ссылке пустая только с фотографией. Так вот что делать? Плагин Yoast рекомендует: если вы никогда не используете эти URL, лучше деактивировать их и перенаправить их на сам медиа-объект. Т.е. они рекомендуют перенаправить URL вложений на файл вложения. Они делают это если включить перенаправление. Я сейчас отключил это перенаправление и у меня появилась дополнительная карта сайта со страницами фотографий, но интересно что почему то не все фотографии. Вот страница: https://www.nsdancing.com/a...
Что посоветуете делать?
4. Кажется что в файле robots также нужно открыть длоя индексации все файлы изображений, но какой командой? В инете предлагают кучу вариантов:
Allow: /wp-content/uploads/ или Allow: /wp-content/*.jpg или Allow: /wp-*.jpg или Allow: /*.jpg или Allow: *.jpg
5. Как рекомендуют спецы по настройке файла для robots.txt всякий раз когда я вставляю команду Allow: /wp-admin/admin-ajax.php то позже в Гугл сорч консоли появляется ошибка с ответом сервера 400 именно на эту команду. Что мне делать?
Пожалуйста подскажите как лучше. Спасибо!