Это приложение содержит более краткое описание различных команд SQL. Цель состоит в том, чтобы дать вам быструю и точную ссылку и определение SQL. Первый раздел этого приложения определяет элементы, используемые для создания команд SQL; второй, подробности синтаксиса и предложения с кратким описанием самих команд. Далее показаны стандартные условные обозначения (они называются BNF условиями):
Кроме того, мы будем использовать следующую последовательность (.,..) чтобы указывать, что предшествующее этому может повторяться любое число раз с индивидуальными событиями отделяемыми запятыми. Атрибуты которые не являются частью официального стандарта будут отмечены как (*нестандартные*) в описании.
ОБРАТИТЕ ВНИМАНИЕ: Терминология которую мы используем здесь, не официальна терминология ANSI. Официальная терминология может вас сильно запутать, поэтому мы несколько ее упростили.
По этой причине, мы иногда используем условия отличающиеся от ANSI, или используем те же самые условия но несколько по-другому. Например, наше определение - < predicate > отличается от используемой в ANSI комбинации стандартного определения < predicate > с < search condition >.
SQL ЭЛЕМЕНТЫ
Этот раздел определяет элементы команд SQL. Они разделены на две категории: Основные элементы языка , и Функциональные элементы языка .
Основные элементы - это создаваемые блоки языка; когда SQL исследует команду, то он сначала оценивает каждый символ в тексте команды в тер- минах этих элементов. Разделители< separator > отделяют одну часть команды от другой; все что находится между разделителями < separator > обрабатывается как модуль. Основываясь на этом разделении, SQL и интерпретирует команду.
Функциональные элементы - это разнообразные вещи отличающиеся от ключевых слов, которые могут интерпретироваться как модули. Это - части команды, отделяемые с помощью разделителей < separator >, имеющих специальное значение в SQL. Некоторые из них являются специальными для определенных команд и будут описаны вместе с этими командами по- зже, в этом приложении. Перечисленное здесь, является общими элементы для всех описываемых команд. Функциональные элементы могут определяться в терминах друг друга или даже в собственных терминах. Например, предикат < predicate >, наш последний и наиболее сложный случай, содержит предикат внутри собственного определения. Это потому, что предикат < predicate > использующий AND или OR может содержать любое число предикатов < predicate > которые могут работать автономно. Мы представляли вам предикат < predicate > в отдельной секции в этом приложении, из-за разнообразия и сложности этого функционального элемента языка. Он будет постоянно присутствовать при обсуждении других функциональных частей команд.
ЭЛЕМЕНТЫ ЯЗЫКА БЕЙСИКА
ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < separator > < comment > | < space > | < newline > < comment > --< string > < newline > < space > пробел < newline > реализационно-определяемый конец символьной строки < identifier > < letter >[{< letter or digit > | < underscore}... ] < ИМЕЙТЕ ВВИДУ: Следу строгому стандарту ANSI, символы должны быть набраны в верхнем регистра, а идентификатор < identifier > не должен быть длиннее 18-ти символов. ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < underscore > - < percent sign > % < delimiter > любое из следующих: , () < > . : = + " - | <> > = < = или < string > < string > [любой печатаемый текст в одиночных кавычках] Примечание: В < string >, две последовательных одиночных кавычки (" ") интерпретируются как одна ("). < SQL term > окончание, зависящее от главного языка. (*только вложенный*)
ФУНКЦИОНАЛЬНЫЕ ЭЛЕМЕНТЫ
Следующая таблица показывает функциональные элементы команд SQL и их определения: ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < query > Предложение SELECT < subquery > Заключенное в круглых скобках предложение SELECT внутри другого условия, которое, фактически, оценивается отдельно для каждой строки-кандидата другого предложения. < value expression > < primary > | < primary > < operator > < primary > | < primary > < operator > < value expression > < operator > любое из следующих: + - / * < primary > < column name > | < literal > | < aggregate function > | < built-in constant > | < nonstandard function > < literal > < string > | < mathematical expressio ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < built-in constant > USER | < implementation-dehned constant > < table name > < identifier > < column spec > [< table name > | < alias >.]< column name > < grouping column > < column spec > | < integer > < ordering column > < column spec > | < integer > < colconstraint > NOT NULL | UNIQUE | CHECK (< predicate >) | PRIMARY KEY | REFERENCES < table name >[(< column name >)] < tabconstraint > UNIQUE (< column list >) | CHECK (< predicate >) | PRIMARY KEY (< column list >) | FOREIGN KEY (< column list >) REFERENCES < table name >[(< column list >)] < defvalue > ЗНАЧЕНИЕ ПО УМОЛЧАНИЮ = < value expression > < data type > Допустимый тип данных (См. Приложение B для описания типов обеспечиваемых ANSI или Приложение C для других общих типов.) < size > Значение зависит от < data type >(См. Приложение B .) < cursor name > < identifier > < index name > < identifier > < synonym > < identifier >(*nonstandard*) < owner > < Authorization ID > < column list > < column spec > .,.. < value list > < value expression > .,.. < table reference > { < table name > [< alias >] } .,..ПРЕДИКАТЫ
Следующее определяет список различных типов предиката < predicate > описанных на следующих страницах:
< predicate > ::=
{ < comparison predicate > | < in predicate > | < null predicate > | < between predicate > | < like predicate > | < quantified predicate > | < exists predicate > } < predicate > - это выражение, которое может быть верным, неверным, или неизвестным, за исключением < exists predicate > и < null predicate >, которые могут быть только верными или неверными.
Будет получено неизвестно если NULL значения предотвращают вывод полученного ответа. Это будет случаться всякий раз, когда NULL значение сравнивается с любым значением. Стандартные операторы Буля - AND, OR, и NOT - могут использоваться с предикатом. NOT верно = неверно, NOT неверно = верно, а NOT неизвестно = неизвестно. Результаты AND и OR в комбинации с предикатами, показаны в следующих таблицах:
AND AND Верно Неверно Неизвестно Верно верно неверно неизвестно Неверно неверно неверно неверно Неизвестно неизвестно неверно неизвестно OR OR Верно Неверно Неизвестно Верно верно верно верно Неверно верно неверно неизвестно Неизвестно верно неизвестно неизвестно
Эти таблицы читаются способом наподобие таблицы умножения: вы объединяете верные, неверные, или неизвестные значения из строк с их столбцами чтобы на перекрестье получить результат. В таблице AND, например, третий столбец (Неизвестно) и первая строка (Верно) на пересечении в верхнем правом углу дают результат - неизвестно, другими словами: Верно AND Неизвестно = неизвестно. Порядок вычислений определяется круглыми скобками. Они не представляются каждый раз. NOT оценивается первым, далее AND и OR. Различные типы предикатов < predicate > рассматриваются отдельно в следующем разделе.
< comparison predicate > (предикат сравнения)
Синтаксис
< value expresslon > < relational op > < value expresslon >
|
< subquery >
< relatlonal op > :: =
=
| <
|
>
| <
| >=
| < >
Если либо < value expression > = NULL, либо < comparison predicate
> = неизвестно; другими словами, это верно если сравнение верно или неверно
если сравнение неверно.
< relational op > имеет стандартные
математические значения для числовых значений; для других типов значений, эти
значения определяются конкретной реализацией.
Оба < value expression >
должны иметь сравнимые типы данных. Если подзапрос < subquery >
используется, он должен содержать одно выражение < value expression > в
предложении SELECT, чье значение будет заменять второе выражение < value
expression > в предикате сравнения < comparision predicate >, каждый
раз когда < subquery > действительно выполняется.
< between predicate >
Синтаксис
< value expression > BETWEEN < value expression >
AND
< value expression >
< between predicate > - A BETWEEN B AND C , имеет такое же значение что и < predicate > - (A >= B AND < = C). < between predicate > для которого A NOT BETWEEN B AND C, имеет такое же значение что и NOT (BETWEEN B AND C). < value expression > может быть выведено с помощью нестандартного запроса < subquery > (*nonstandard*).
< in prediicate >
Синтаксис
< value expression > IN < value list > | < subquery
>
Список значений < value list > будет состоять из одного или более перечисленных значений в круглых скобках и отделяемых запятыми, которые имеют сравнимый с < value expression > тип данных. Если используется подзапрос < subquery >, он должен содержать только одно выражение < value expression > в предложении SELECT (возможно и больше, но это уже будет вне стандарта ANSI). Подзапрос < subquery > фактически, выполняется отдельно для каждой строки-кандидата основного запроса, и значения которые он выведет, будут составлять список значений < value list > для этой строки. В любом случае, предикат < in predicate > будет верен если выражение < value expression > представленное в списке значений < value list >, если не указан NOT. Фраза A NOT IN (B, C) является эквивалентом фразы NOT (A IN (B, C)).
< like predicate >
Синтаксис
< charvalue > LIKE < pattern >
< charvalue > - это любое *нестандартное* выражение < value expression > алфавитно-цифрового типа. < charvalue > может быть, в соответствии со стандартом, только определенным столбцом < column spec >. Образец < pattern > состоит из строки которая будет проверена на совпадение с < charvalue >. Символ окончания < escapechar > - это одиночный алфавитно-цифровой символ. Совпадение произойдет, если верны следующие условия:
Если совпадение произошло, < like predicate > - верен, если не был указан NOT. Фраза NOT LIKE "текст" - эквивалентна NOT (A LIKE "текст").
< null predicate >
Синтаксис
< column spec > IS NULL
< column spec > = IS NULL, если NULL значение представлено в этом столбце. Это сделает < null predicate > верным если не указан NULL. Фраза < column spec > IS NOT NULL, имеет тот же результат что и NOT (< column spec > IS NULL).
< quantified predicate >
Синтаксис
< value expression > < relational op >
< quantifier >
< subquery >
< quantifier > :: = ANY | ALL | SOME
Предложение SELECT подзапроса < subquery > должно содержать одно и только одно выражение значения < value expression >. Все значения выведенные подзапросом < subquery > составляют набор результатов < result set >. < value expression > сравнивается, используя оператор связи < relational operator >, с каждым членом набора результатов < result set >. Это сравнение оценивается следующим образом:
< exists predicate >
Синтаксис:
EXISTS (< subquery >)
Если подзапрос < subquery > выводит одну или более строк вывода, < exists predicate > - верен; и неверен если иначе.
SQL КОМАНДЫ
Этот раздел подробно описывает синтаксис различных команд SQL. Это даст вам возможность быстро отыскивать команду, находить ее синтаксис и краткое описание ее работы.
ИМЕЙТЕ ВВИДУ Команды которые начинаются словами - EXEC SQL, а также команды или предложения заканчивающиеся словом - могут использоваться только во вложенном SQL.
BEGIN DECLARE SECTION (НАЧАЛО РАЗДЕЛА ОБЪЯВЛЕНИЙ)
Синтаксис
EXEC SQL BEGIN DECLARE SECTION < SQL term > < host-language variable declarations > EXEC SQL END DECLARE SECTION < SQL term >
Эта команда создает раздел программы главного языка для объявления в ней главных переменных, которые будут использоваться во вкладываемых операторах SQL. Переменна SQLCODE должна быть включена как одна из объявляемых переменных главного языка.
CLOSE CURSOR (ЗАКРЫТЬ КУРСОР)
Синтаксис
EXEC SQL CLOSE CURSOR < cursor name > < SQL term >;
Эта команда указывает курсору закрыться, после чего ни одно значение не сможет быть выбрано из него до тех пор пока он не будет снова открыт.
COMMIT (WORK) (ФИКСАЦИЯ (ТРАНЗАКЦИИ))
Синтаксис
Эта команда оставляет неизменными все изменения сделанных в базе данных, до тех пор пока начавшаяся транзакция не закончится, и не начнется новая транзакция.
CREATE INDEX (СОЗДАТЬ ИНДЕКС)
(*NONSTANDARD*) (НЕСТАНДАРТНО)
Синтаксис
CREATE INDEX < Index name >
ON < table name > (<
column list >);
Эта команда создает эффективный маршрут с быстрым доступом для поиска строк содержащих обозначенные столбцы. Если UNIQUE - указана, таблица не сможет содержать дубликатов(двойников) значений в этих столбцах.
CREATE SYNONYM (*NONSTANDARD*)
(СОЗДАТЬ СИНОНИМ) (*НЕСТАНДАРТНО*)
Синтаксис
CREATE IPUBLICl SYNONYM < synonym > FOR
< owner >.< table
name >;
Эта команда создает альтернативное(синоним) им для таблицы. Синоним принадлежит его создателю, а сама таблица, обычно другому пользователю. Используя синоним, его владелец может не ссылаться к таблице ее полным (включая им владельца) именем. Если PUBLIC - указан, синоним принадлежит каталогу SYSTEM и следовательно доступен всем пользователям.
CREATE TABLE (СОЗДАТЬ ТАБЛИЦУ)
Синтаксис
CREATE TABLE < table name >
({< column name > < data type
>[< size >]
[< colconstralnt > . . .]
[< defvalue
>]} . , . . < tabconstraint > . , . .);
Команда создает таблицу в базе данных. Эта таблица будет принадлежать ее
создателю. Столбцы будут рассматриваться в поименном порядке. < data type
> - определяет тип данных который будет содержать столбец. Стандарт < data
type > описывается в Приложении
B ; все прочие используемые типы данных < data type >, обсуждались в Приложении
C . Значение размера < size > зависит от типа данных < data type
>.
< colconstraint > и < tabconstraint > налагают ограничения
на значения ко торые могут быть введены в столбцу.
< defvalue >
определяет значение(по умолчанию) которое будет вставлено автоматически, если
никакого другого значения не указано для этой строки. (См. Главу
17 для подробностей о самой команде CREATE TABLE иГлавы
18 И для
подробностей об ограничениях и о < defvalue >).
CREATE VIEW (СОЗДАТЬ ПРОСМОТР)
Синтаксис
CREATE VIEW < table name >
AS < query >
;
Просмотр обрабатывается как люба таблица в командах SQL. Когда команда
ссылается на имя таблицы < table name >, запрос < query >
выполняется, и его вывод соответствует содержанию таблицы указанной в этой
команде.
Некоторые просмотры могут модифицироваться, что означает, что
команды модификации могут выполняться в этих просмотрах и передаваться в
таблицу, на которую была ссылка в запросе < query >. Если указано
предложение WITH CHECK OPTION, эта модификация должны также удовлетворять
условию предиката < predicate > в запросе < query >.
DECLARE CURSOR (ОБЪЯВИТЬ КУРСОР)
Синтаксис
EXEC SQL DECLARE < cursor name > CURSOR FOR
< query >< SQL
term >
Эта команда связывает им курсора < cursor name >, с запросом < query >. Когда курсор открыт (см. OPEN CURSOR), запрос < query > выполняет ся, и его результат может быть выбран(командой FETCH) для вывода. Если курсор модифицируемый, таблица на которую ссылается запрос < query >, может получить изменение содержания с помощью операции модификации в курсоре (См. Главу 25 о модифицируемых курсорах).
DELETE (УДАЛИТЬ)
Синтаксис
DELETE FROM < table name >
{ ; }
|
WHERE CURRENT OF < cursorname >< SQL term >
Если предложение WHERE отсутствует, ВСЕ строки таблицы удаляются. Если предложение WHERE использует предикат < predicate >, строки, ко торые удовлетворяют условию этого предиката < predicate > удаляются. Если предложение WHERE имеет аргумент CURRENT OF(ТЕКУЩИЙ) в имени курсора < cursor name >, строка из таблицы < table name > на ко торую в данный момент имеется ссылка с помощью имени курсора < cursor name > будет удалена. Форма WHERE CURRENT может использоваться только во вложенном SQL, и только с модифицируемыми курсорами.
EXEC SQL (ВЫПОЛНИТЬ SQL)
Синтаксис
EXEC SQL < embedded SQL command > < SQL term >
EXEC SQL используется чтобы указывать начало всех команд SQL, вложенных в другой язык.
FETCH (ВЫБОРКА)
Синтаксис
EXEC SQL FETCH < cursorname >
INTO < host-varlable llst ><
SQL term >
FETCH принимает вывод из текущей строки запроса < query >, вставляет ее в список главных переменных < host-variable list >, и перемещает кур сор на следующую строку. Список < host-variable list > может включать переменную indicator в качестве целевой переменной (См. Главу 25 .)
GRANT (ПЕРЕДАТЬ ПРАВА)
Синтаксис (стандартный)
GRANT ALL
| {SELECT
| INSERT
| DELETE
| UPDATE
[(< column llst >)]
| REFERENCES [(< column llst >)l } . , . .
ON < table name > . , . .
TO PUBLIC | < Authorization ID > .
, . .
;
Аргумент ALL(ВСЕ), с или без PRIVILEGES(ПРИВИЛЕГИИ), включает каждую привилегию в список привилегий. PUBLIC(ОБЩИЙ) включает всех существующих пользователей и всех созданных в будущем. Эта команда дает возможность передать права для выполнения действий в таблице с указанным именем. REFERENCES позволяет дать права чтобы использовать столбцы в списке столбцов < column list > как родительский ключ для внешнего ключа. Другие привилегии состоят из права выполнять команды для которых привилегии указаны их именами в таблице. UPDATE, подобен REFERENCES, и может накладывать ограничения на определенные столбцы. GRANT OPTION дает возможность передавать эти привилегии другим пользователям.
Синтаксис (нестандартный)
GRANT DBA
| RESOURCE
| CONNECT ... .
TO < Authorization ID
> . , . .
| < privilege > . , . . }
FROM { PUBLIC
| < Authorization ID > . , . . };
Привилегия < privelege > может быть любой из указанных в команде GRANT. Пользователь дающий REVOKE должен иметь те же привилегии, что и пользователь который давал GRANT. Предложение ON может быть использовано, если используется привилегия специального типа для особого объекта.
ROLLBACK (WORK)
(ОТКАТ) (ТРАНЗАКЦИИ)
Синтаксис
Команда отменяет все изменения в базе данных, сделанные в течение те- кущей транзакции. Она кроме того заканчивается текущую, и начинает новую транзакцию.
SELECT (ВЫБОР)
Синтаксис
SELECT { IDISTINCT | ALL] < value expression > . , . . } / *
FROM < table reference
> . , . .
. , . . ];
Это предложение организует запрос и выводит значения из базы данных (см. Глава 3 - Глава 14). Применяются следующие правила:
Предложение SELECT оценивает каждую строку-кандидат таблицы в которой строки показаны независимо. Строка-кандидат определяется следующим образом:
Каждая строка-кандидат производит значения, которые делают предикат <
predicate > в предложении WHERE верным, неверным, или неизвестным. Если GROUP
BY не используется, каждое < value expression > применяется в свою очередь
для каждой строки-кандидата чье значение делает предикат верным, и результатом
этой операции является вывод.
Если GROUP BY используется, строки-кандидаты
комбинируются, используя агрегатные функции. Если никакого предиката <
predicate > не установлено, каждое выражение< value expression >
применяется к каждой строке-кандидату или к каждой группе. Если указан DISTINCT,
дубликаты(двойники) строк будут удалены из вывода.
UNION (ОБЪЕДИНЕНИЕ)
Синтаксис
< query > {UNION < query > } . . . ;
Вывод двух или более запросов < query > будет объединен. Каждый запрос < query > должен содержать один и тот же номер < value expression > в предложение SELECT и в таком порядке что 1.. n каждого, совместим по типу данных < data type > и размеру < size > с 1.. n всех других.
UPDATE (МОДИФИКАЦИЯ)
Синтаксис
UPDATE < table name >
SET { < column name > = < value
expression > } . , . .
{[ WHERE < predlcate >]; }
| {
< SQL term >]}
UPDATE изменяет значения в каждом столбце с именем < column name > на соответствующее значение < value expression >. Если предложение WHERE использует предикат < predicate >, то только строки таблиц чьи текущие значения делают тот предикат < predicate > верным, могут быть изменены. Если WHERE использует предложение CURRENT OF, то значения в строке таблицы с именем < table name > находящиеся в курсоре с именем < cursor name > меняются. WHERE CURRENT OF пригодно для использования только во вложенном SQL, и только с модифицируемыми курсорами. При отсутствии предложения WHERE - все строки меняются.
WHENEVER (ВСЯКИЙ РАЗ КАК)
Синтаксис
EXEC SQL WHENEVER < SQLcond > < actlon > < SQL term
>
< SQLcond > :: = SQLERROR | NOT FOUND | SQLWARNING
(последнее
- нестандартное)
< action > :: = CONTINUE | GOTO < target > |
GOTO < target >
< target > :: = зависит от главного языка
Табличными выражениями называются подзапросы, которые используются там, где ожидается наличие таблицы. Существует два типа табличных выражений:
производные таблицы;
обобщенные табличные выражения.
Эти две формы табличных выражений рассматриваются в следующих подразделах.
Производные таблицы
Производная таблица (derived table) - это табличное выражение, входящее в предложение FROM запроса. Производные таблицы можно применять в тех случаях, когда использование псевдонимов столбцов не представляется возможным, поскольку транслятор SQL обрабатывает другое предложение до того, как псевдоним станет известным. В примере ниже показана попытка использовать псевдоним столбца в ситуации, когда другое предложение обрабатывается до того, как станет известным псевдоним:
USE SampleDb; SELECT MONTH(EnterDate) as enter_month FROM Works_on GROUP BY enter_month;
Попытка выполнить этот запрос выдаст следующее сообщение об ошибке:
Msg 207, Level 16, State 1, Line 5 Invalid column name "enter_month". (Сообщение 207: уровень 16, состояние 1, строка 5 Недопустимое имя столбца enter_month)
Причиной ошибки является то обстоятельство, что предложение GROUP BY обрабатывается до обработки соответствующего списка инструкции SELECT, и при обработке этой группы псевдоним столбца enter_month неизвестен.
Эту проблему можно решить, используя производную таблицу, содержащую предшествующий запрос (без предложения GROUP BY), поскольку предложение FROM исполняется перед предложением GROUP BY:
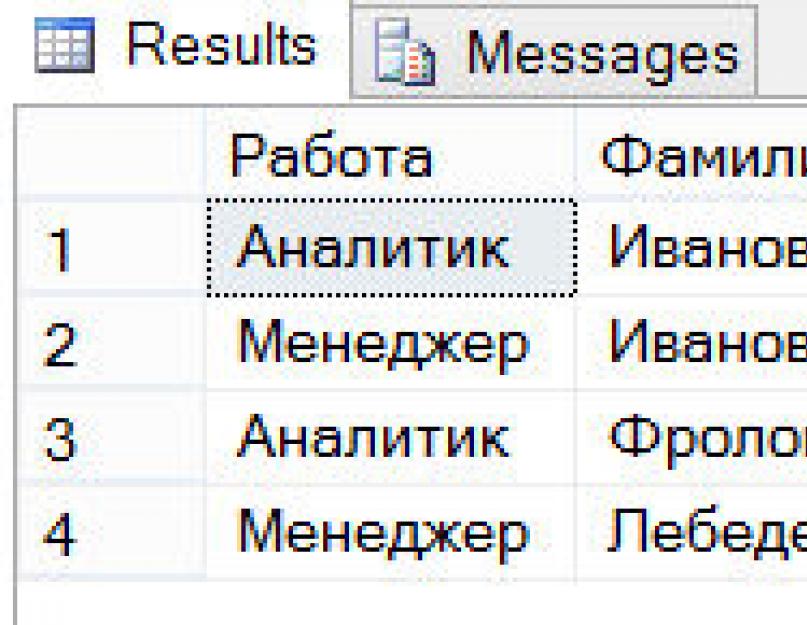
USE SampleDb; SELECT enter_month FROM (SELECT MONTH(EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
Результат выполнения этого запроса будет таким:
Обычно табличное выражение можно разместить в любом месте инструкции SELECT, где может появиться имя таблицы. (Результатом табличного выражения всегда является таблица или, в особых случаях, выражение.) В примере ниже показывается использование табличного выражения в списке выбора инструкции SELECT:
Результат выполнения этого запроса:

Обобщенные табличные выражения
Обобщенным табличным выражением (OTB) (Common Table Expression - сокращенно CTE) называется именованное табличное выражение, поддерживаемое языком Transact-SQL. Обобщенные табличные выражения используются в следующих двух типах запросов:
нерекурсивных;
рекурсивных.
Эти два типа запросов рассматриваются в следующих далее разделах.
OTB и нерекурсивные запросы
Нерекурсивную форму OTB можно использовать в качестве альтернативы производным таблицам и представлениям. Обычно OTB определяется посредством предложения WITH и дополнительного запроса, который ссылается на имя, используемое в предложении WITH. В языке Transact-SQL значение ключевого слова WITH неоднозначно. Чтобы избежать неопределенности, инструкцию, предшествующую оператору WITH, следует завершать точкой с запятой.
USE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") AND Freight > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005")/2.5;
Запрос в этом примере выбирает заказы, чьи общие суммы налогов (TotalDue) большие, чем среднее значение по всем налогам, и плата за перевозку (Freight) которых больше чем 40% среднего значения налогов. Основным свойством этого запроса является его объемистость, поскольку вложенный запрос требуется писать дважды. Одним из возможных способов уменьшить объем конструкции запроса будет создать представление, содержащее вложенный запрос. Но это решение несколько сложно, поскольку требует создания представления, а потом его удаления после окончания выполнения запроса. Лучшим подходом будет создать OTB. В примере ниже показывается использование нерекурсивного OTB, которое сокращает определение запроса, приведенного выше:
USE AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT year_2005 FROM price_calc) AND Freight > (SELECT year_2005 FROM price_calc)/2.5;
Синтаксис предложения WITH в нерекурсивных запросах имеет следующий вид:
Параметр cte_name представляет имя OTB, которое определяет результирующую таблицу, а параметр column_list - список столбцов табличного выражения. (В примере выше OTB называется price_calc и имеет один столбец - year_2005.) Параметр inner_query представляет инструкцию SELECT, которая определяет результирующий набор соответствующего табличного выражения. После этого определенное табличное выражение можно использовать во внешнем запросе outer_query. (Внешний запрос в примере выше использует OTB price_calc и ее столбец year_2005, чтобы упростить употребляющийся дважды вложенный запрос.)
OTB и рекурсивные запросы
В этом разделе представляется материал повышенной сложности. Поэтому при первом его чтении рекомендуется его пропустить и вернуться к нему позже. Посредством OTB можно реализовывать рекурсии, поскольку OTB могут содержать ссылки на самих себя. Основной синтаксис OTB для рекурсивного запроса выглядит таким образом:
Параметры cte_name и column_list имеют такое же значение, как и в OTB для нерекурсивных запросов. Тело предложения WITH состоит из двух запросов, объединенных оператором UNION ALL . Первый запрос вызывается только один раз, и он начинает накапливать результат рекурсии. Первый операнд оператора UNION ALL не ссылается на OTB. Этот запрос называется опорным запросом или источником.
Второй запрос содержит ссылку на OTB и представляет ее рекурсивную часть. Вследствие этого он называется рекурсивным членом. В первом вызове рекурсивной части ссылка на OTB представляет результат опорного запроса. Рекурсивный член использует результат первого вызова запроса. После этого система снова вызывает рекурсивную часть. Вызов рекурсивного члена прекращается, когда предыдущий его вызов возвращает пустой результирующий набор.
Оператор UNION ALL соединяет накопившиеся на данный момент строки, а также дополнительные строки, добавленные текущим вызовом рекурсивного члена. (Наличие оператора UNION ALL означает, что повторяющиеся строки не будут удалены из результата.)
Наконец, параметр outer_query определяет внешний запрос, который использует OTB для получения всех вызовов объединения обеих членов.
Для демонстрации рекурсивной формы OTB мы используем таблицу Airplane, определенную и заполненную кодом, показанным в примере ниже:
USE SampleDb; CREATE TABLE Airplane (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), QuantityContained INT, UnitCost DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Самолет", "Фюзеляж",1, 10); INSERT INTO Airplane VALUES ("Самолет", "Крылья", 1, 11); INSERT INTO Airplane VALUES ("Самолет", "Хвост",1, 12); INSERT INTO Airplane VALUES ("Фюзеляж", "Салон", 1, 13); INSERT INTO Airplane VALUES ("Фюзеляж", "Кабина", 1, 14); INSERT INTO Airplane VALUES ("Фюзеляж", "Нос",1, 15); INSERT INTO Airplane VALUES ("Салон", NULL, 1,13); INSERT INTO Airplane VALUES ("Кабина", NULL, 1, 14); INSERT INTO Airplane VALUES ("Нос", NULL, 1, 15); INSERT INTO Airplane VALUES ("Крылья", NULL,2, 11); INSERT INTO Airplane VALUES ("Хвост", NULL, 1, 12);
Таблица Airplane состоит из четырех столбцов. Столбец ContainingAssembly определяет сборку, а столбец ContainedAssembly - части (одна за другой), которые составляют соответствующую сборку. На рисунке ниже приведена графическая иллюстрация возможного вида самолета и его составляющих частей:

Таблица Airplane состоит из следующих 11 строк:

В примере ниже показано применение предложения WITH для определения запроса, который вычисляет общую стоимость каждой сборки:
USE SampleDb; WITH list_of_parts(assembly1, quantity, cost) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAssembly IS NULL UNION ALL SELECT a.ContainingAssembly, a.QuantityContained, CAST(l.quantity * l.cost AS DECIMAL(6,2)) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECT assembly1 "Деталь", quantity "Кол-во", cost "Цена" FROM list_of_parts;
Предложение WITH определяет список OTB с именем list_of_parts, состоящий из трех столбцов: assembly1, quantity и cost. Первая инструкция SELECT в примере вызывается только один раз, чтобы сохранить результаты первого шага процесса рекурсии. Инструкция SELECT в последней строке примера отображает следующий результат.
- Перевод
- Tutorial
Надо “ SELECT * WHERE a=b FROM c ” или “ SELECT WHERE a=b FROM c ON * ” ?
Если вы похожи на меня, то согласитесь: SQL - это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:


У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” - имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title FROM books WHERE author="Dan Brown";
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM - откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE - какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк , которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author - это “Dan Brown”.
3.3 SELECT - как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid=books.bookid WHERE books.author="Dan Brown";
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы . Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице , которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid - это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 - откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid
Результат соединения можно увидеть по ссылке .
Шаг 2 - какие данные показываем? Нас интересуют только те данные, где автор книги - “Dan Brown”
WHERE books.author="Dan Brown"
Шаг 3 - как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown";
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну . При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count(*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown" GROUP BY members.firstname, members.lastname;
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT "ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock) FROM books GROUP BY author;
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов - использовать подзапросы:
SELECT * FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE author="Robin Sharma";
Результат:
Можно записать как: ["Robin Sharma", "Dan Brown"]
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3);
Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown");
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;
Что дает нам:
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT "ом, мы задаем знаения SET "ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books SET stock=0 WHERE author="Dan Brown";
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books WHERE author="Dan Brown";
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
INSERT INTO x (a,b,c) VALUES (x, y, z);
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
INSERT INTO books (bookid,title,author,published,stock) VALUES (1,"Scion of Ikshvaku","Amish Tripathi","06-22-2015",2), (2,"The Lost Symbol","Dan Brown","07-22-2010",3), (3,"Who Will Cry When You Die?","Robin Sharma","06-15-2006",4), (4,"Inferno","Dan Brown","05-05-2014",3), (5,"The Fault in our Stars","John Green","01-03-2015",3);
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Теги: Добавить метки
Синтаксис:
* где fields1
— поля для выборки через запятую, также можно указать все поля знаком *; table
— имя таблицы, из которой вытаскиваем данные; conditions
— условия выборки; fields2
— поле или поля через запятую, по которым выполнить сортировку; count
— количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
Простые примеры использования select
1. Обычная выборка данных:
> SELECT * FROM users
2. Выборка данных с объединением двух таблиц (JOIN):
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights . Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
а) известна точка начала и определенный временной интервал:
* будут выбраны данные за последний час (поле date ).
б) известны дата начала и дата окончания:
25.10.2017 и 25.11.2017 .
в) известны даты начала и окончания + время:
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд .
г) вытаскиваем данные за определенные месяц и год:
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
4. Выборка максимального, минимального и среднего значения:
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки:
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT):
* из таблицы users извлекаются данные по полю id , все они помещаются в одну строку, значения разделяются запятыми .
2. Группировка данных по двум и более полям:
> SELECT * FROM users GROUP BY CONCAT(title, "::", birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth . Перед группировкой мы делаем объединение полей в одну строку с разделителем :: .
3. Объединение результатов из двух таблиц (UNION):
> (SELECT id, fio, address, "Пользователи" as type FROM users)
UNION
(SELECT id, fio, address, "Покупатели" as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers .
4. Выборка средних значений, сгруппированных за каждый час:
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H") as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H")
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO
 SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released
SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released


 Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;
Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;