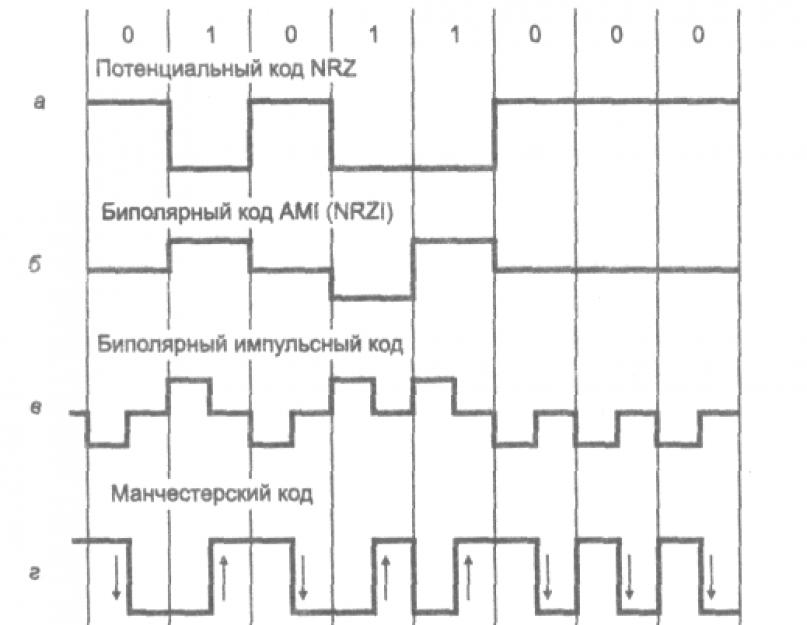
При цифровом кодировании дискретной информации применяют потенциальные и импульсные коды.
В потенциальных кодах для представления логических единиц и нулей используется только значение потенциала сигнала, а его перепады, формирующие законченные импульсы, во внимание не принимаются. Импульсные коды позволяют представить двоичные данные либо импульсами определенной полярности, либо частью импульса - перепадом потенциала определенного направления.
Требования к методам цифрового кодирования
При использовании прямоугольных импульсов для передачи дискретной информации необходимо выбрать такой способ кодирования, который одновременно достигал бы нескольких целей:
Имел при одной и той же битовой скорости наименьшую ширину спектра результирующего сигнала;
Обеспечивал синхронизацию между передатчиком и приемником;
Обладал способностью распознавать ошибки;
Обладал низкой стоимостью реализации.
Более узкий спектр сигналов позволяет на одной и той же линии (с одной и той же полосой пропускания) добиваться более высокой скорости передачи данных. Кроме того, часто к спектру сигнала предъявляется требование отсутствия постоянной составляющей, то есть наличия постоянного тока между передатчиком и приемником. В частности, применение различных трансформаторных схем гальванической развязки препятствует прохождению постоянного тока.
Синхронизация передатчика и приемника нужна для того, чтобы приемник точно знал, в какой момент времени необходимо считывать новую информацию с линии связи. Эта проблема в сетях решается сложнее, чем при обмене данными между близко расположенными устройствами, например между блоками внутри компьютера или же между компьютером и принтером. На небольших расстояниях хорошо работает схема, основанная на отдельной тактирующей линии связи (рис), так что информация снимается с линии данных только в момент прихода тактового импульса. В сетях использование этой схемы вызывает трудности из-за неоднородности характеристик проводников в кабелях. На больших расстояниях неравномерность скорости распространения сигнала может привести к тому, что тактовый импульс придет настолько позже или раньше соответствующего сигнала данных, что бит данных будет пропущен или считан повторно. Другой причиной, по которой в сетях отказываются от использования тактирующих импульсов, является экономия проводников в дорогостоящих кабелях.
Поэтому в сетях применяются так называемые самосинхронизирующиеся коды, сигналы которых несут для передатчика указания о том, в какой момент времени нужно осуществлять распознавание очередного бита (или нескольких бит, если код ориентирован более чем на два состояния сигнала). Любой резкий перепад сигнала - так называемый фронт - может служить хорошим указанием для синхронизации приемника с передатчиком.
При использовании синусоид в качестве несущего сигнала результирующий код обладает свойством самосинхронизации, так как изменение амплитуды несущей частоты дает возможность приемнику определить момент появления входного кода.
Распознавание и коррекцию искаженных данных сложно осуществить средствами физического уровня, поэтому чаще всего эту работу берут на себя протоколы, лежащие выше: канальный, сетевой, транспортный или прикладной. С другой стороны, распознавание ошибок на физическом уровне экономит время, так как приемник не ждет полного помещения кадра в буфер, а отбраковывает его сразу при распознавании ошибочных бит внутри кадра.
Требования, предъявляемые к методам кодирования, являются взаимно противоречивыми, поэтому каждый из рассматриваемых ниже популярных методов цифрового кодирования обладает своими преимуществами и своими недостатками по сравнению с другими.
Потенциальный код без возвращения к нулю
На рис. 2.16, а показан уже упомянутый ранее метод потенциального кодирования, называемый также кодированием без возвращения к нулю (NonReturntoZero,NRZ). Последнее название отражает то обстоятельство, что при передаче последовательности единиц сигнал не возвращается к нулю в течение такта (как мы увидим ниже, в других методах кодирования возврат к нулю в этом случае происходит). МетодNRZпрост в реализации, обладает хорошей распознаваемостью ошибок (из-за двух резко отличающихся потенциалов), но не обладает свойством самосинхронизации. При передаче длинной последовательности единиц или нулей сигнал на линии не изменяется, поэтому приемник лишен возможности определять по входному сигналу моменты времени, когда нужно в очередной раз считывать данные. Даже при наличии высокоточного тактового генератора приемник может ошибиться с моментом съема данных, так как частоты двух генераторов никогда не бывают полностью идентичными. Поэтому при высоких скоростях обмена данными и длинных последовательностях единиц или нулей небольшое рассогласование тактовых частот может привести к ошибке в целый такт и, соответственно, считыванию некорректного значения бита.

Другим серьезным недостатком метода NRZявляется наличие низкочастотной составляющей, которая приближается к нулю при передаче длинных последовательностей единиц или нулей. Из-за этого многие каналы связи, не обеспечивающие прямого гальванического соединения между приемником и источником, этот вид кодирования не поддерживают. В результате в чистом виде кодNRZв сетях не используется. Тем не менее используются его различные модификации, в которых устраняют как плохую самосинхронизацию кодаNRZ, так и наличие постоянной составляющей. Привлекательность кодаNRZ, из-за которой имеет смысл заняться его улучшением, состоит в достаточно низкой частоте основной гармоникиfo, которая равнаN/2 Гц, как это было показано в предыдущем разделе. У других методов кодирования, например манчестерского, основная гармоника имеет более высокую частоту.
Метод биполярного кодирования с альтернативной инверсией
Одной из модификаций метода NRZявляется метод биполярного кодирования с альтернативной инверсией (BipolarAlternateMarkInversion,AMI). В этом методе (рис. 2.16, б) используются три уровня потенциала - отрицательный, нулевой и положительный. Для кодирования логического нуля используется нулевой потенциал, а логическая единица кодируется либо положительным потенциалом, либо отрицательным, при этом потенциал каждой новой единицы противоположен потенциалу предыдущей.
Код AMIчастично ликвидирует проблемы постоянной составляющей и отсутствия самосинхронизации, присущие кодуNRZ. Это происходит при передаче длинных последовательностей единиц. В этих случаях сигнал на линии представляет собой последовательность разнополярных импульсов с тем же спектром, что и у кодаNRZ, передающего чередующиеся нули и единицы, то есть без постоянной составляющей и с основной гармоникойN/2 Гц (где N - битовая скорость передачи данных). Длинные же последовательности нулей также опасны для кодаAMI, как и для кодаNRZ- сигнал вырождается в постоянный потенциал нулевой амплитуды. Поэтому кодAMIтребует дальнейшего улучшения, хотя задача упрощается - осталось справиться только с последовательностями нулей.
В целом, для различных комбинаций бит на линии использование кода AMIприводит к более узкому спектру сигнала, чем для кодаNRZ, а значит, и к более высокой пропускной способности линии. Например, при передаче чередующихся единиц и нулей основная гармоникаfoимеет частотуN/4 Гц. КодAMIпредоставляет также некоторые возможности по распознаванию ошибочных сигналов. Так, нарушение строгого чередования полярности сигналов говорит о ложном импульсе или исчезновении с линии корректного импульса. Сигнал с некорректной полярностью называется запрещенным сигналом (signalviolation).
В коде AMIиспользуются не два, а три уровня сигнала на линии. Дополнительный уровень требует увеличение мощности передатчика примерно на 3 дБ для обеспечения той же достоверности приема бит на линии, что является общим недостатком кодов с несколькими состояниями сигнала по сравнению с кодами, которые различают только два состояния.
Потенциальный код с инверсией при единице
Существует код, похожий на AMI, но только с двумя уровнями сигнала. При передаче нуля он передает потенциал, который был установлен в предыдущем такте (то есть не меняет его), а при передаче единицы потенциал инвертируется на противоположный. Этот код называется потенциальным кодом с инверсией при единице
(NonReturntoZerowithonesInverted,NRZI). Этот код удобен в тех случаях, когда использование третьего уровня сигнала весьма нежелательно, например в оптических кабелях, где устойчиво распознаются два состояния сигнала - свет и темнота. Для улучшения потенциальных кодов, подобныхAMIиNRZI, используются два метода. Первый метод основан на добавлении в исходный код избыточных бит, содержащих логические единицы. Очевидно, что в этом случае длинные последовательности нулей прерываются и код становится самосинхронизирующимся для любых передаваемых данных. Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии, так как избыточные единицы пользовательской информации не несут. Другой метод основан на предварительном «перемешивании» исходной информации таким образом, чтобы вероятность появления единиц и нулей на линии становилась близкой. Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble- свалка, беспорядочная сборка). При скремблировании используется известный алгоритм, поэтому приемник, получив двоичные данные, передает их на дескрэмблер, который восстанавливает исходную последовательность бит. Избыточные биты при этом по линии не передаются. Оба метода относятся к логическому, а не физическому кодированию, так как форму сигналов на линии они не определяют. Более детально они изучаются в следующем разделе.
Биполярный импульсный код
Кроме потенциальных кодов в сетях используются и импульсные коды, когда данные представлены полным импульсом или же его частью - фронтом. Наиболее простым случаем такого подхода является биполярный импульсный код, в котором единица представлена импульсом одной полярности, а ноль - другой (рис. 2.16, в). Каждый импульс длится половину такта. Такой код обладает отличными самосинхронизирующими свойствами, но постоянная составляющая может присутствовать, например, при передаче длинной последовательности единиц или нулей. Кроме того, спектр у него шире, чем у потенциальных кодов. Так, при передаче всех нулей или единиц частота основной гармоники кода будет равна N Гц, что в два раза выше основной гармоники кода NRZи в четыре раза выше основной гармоники кодаAMIпри передаче чередующихся единиц и нулей. Из-за слишком широкого спектра биполярный импульсный код используется редко.
Манчестерский код
В локальных сетях до недавнего времени самым распространенным методом кодирования был так называемый манчестерский код (рис. 2.16, г). Он применяется в технологиях EthernetиTokenRing.
В манчестерском коде для кодирования единиц и нулей используется перепад потенциала, то есть фронт импульса. При манчестерском кодировании каждый такт делится на две части. Информация кодируется перепадами потенциала, происходящими в середине каждого такта. Единица кодируется перепадом от низкого уровня сигнала к высокому, а ноль - обратным перепадом. В начале каждого такта может происходить служебный перепад сигнала, если нужно представить несколько единиц или нулей подряд. Так как сигнал изменяется по крайней мере один раз за такт передачи одного бита данных, т.о. манчестерский код обладает хорошими самосинхронизирующими свойствами. Полоса пропускания манчестерского кода уже, чем у биполярного импульсного. У него также нет постоянной составляющей, а основная гармоника в худшем случае (при передаче последовательности единиц или нулей) имеет частоту N Гц, а в лучшем (при передаче чередующихся единиц и нулей) она равна N/2 Гц, как и у кодовAMIилиNRZ. В среднем ширина полосы манчестерского кода в полтора раза уже, чем у биполярного импульсного кода, а основная гармоника колеблется вблизи значения 3N/4. Манчестерский код имеет еще одно преимущество перед биполярным импульсным кодом. В последнем для передачи данных используются три уровня сигнала, а в манчестерском - два.
Потенциальный код 2В1 Q
На рис. 2.16, д показан потенциальный код с четырьмя уровнями сигнала для кодирования данных. Это код 2В1Q, название которого отражает его суть - каждые два бита (2В) передаются за один такт сигналом, имеющим четыре состояния (1Q). Паре бит 00 соответствует потенциал -2,5 В, паре бит 01 соответствует потенциал -0,833 В, паре 11 - потенциал +0,833 В, а паре 10 - потенциал +2,5 В. При этом способе кодирования требуются дополнительные меры по борьбе с длинными последовательностями одинаковых пар бит, так как при этом сигнал превращается в постоянную составляющую. При случайном чередовании бит спектр сигнала в два раза уже, чем у кодаNRZ, так как при той же битовой скорости длительность такта увеличивается в два раза. Таким образом, с помощью кода 2В1Qможно по одной и той же линии передавать данные в два раза быстрее, чем с помощью кодаAMIилиNRZI. Однако для его реализации мощность передатчика должна быть выше, чтобы четыре уровня четко различались приемником на фоне помех.
Кодирование на двух нижних каналах характеризует метод представления информации сигналами, которые распространяются по среде транспортировки. Кодирование можно рассматривать как двухступенчатое. И ясно, что на принимающей стороне реализуется симметричное декодирование.
Логическое кодирование данных изменяет поток бит созданного кадра МАС-уровня в последовательность символов, которые подлежат физическому кодированию для транспортировки по каналу связи. Для логического кодирования используют разные схемы:
- 4B/5B — каждые 4 бита входного потока кодируются 5-битным символом (табл 1.1). Получается двукратная избыточность, так как 2 4 = 16 входных комбинаций показываются символами из 2 5 = 32. Расходы по количеству битовых интервалов составляют: (5-4)/4 = 1/4 (25%). Такая избыточность разрешает определить ряд служебных символов, которые служат для синхронизации. Применяется в 100BaseFX/TX, FDDI
- 8B/10B — аналогичная схема (8 бит кодируются 10-битным символом) но уже избыточность равна 4 раза (256 входных в 1024 выходных).
- 5B/6B — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN
- 8B/6T — 8 бит входного потока кодируются шестью троичными (T = ternary) цифрами (-,0,+). К примеру: 00h: +-00+-; 01h: 0+-+=0; Код имеет избыточность 3 6 /2 8 = 729/256 = 2,85. Скорость транспортировки символов в линию является ниже битовой скорости и их поступления на кодирования. Применяется в 100BaseT4.
- Вставка бит — такая схема работает на исключение недопустимых последовательностей бит. Ее работу объясним на реализации в протоколе HDLC. Тут входной поток смотрится как непрерывная последовательность бит, для которой цепочка из более чем пяти смежных 1 анализируется как служебный сигнал (пример: 01111110 является флагом-разделителем кадра). Если в транслируемом потоке встречается непрерывная последовательность из 1 , то после каждой пятой в выходной поток передатчик вставляет 0 . Приемник анализирует входящую цепочку, и если после цепочки 011111 он видит 0 , то он его отбрасывает и последовательность 011111 присоединяет к остальному выходному потоку данных. Если принят бит 1 , то последовательность 011111 смотрится как служебный символ. Такая техника решает две задачи — исключать длинные монотонные последовательности, которые неудобные для самосинхронизации физического кодирования и разрешает опознание границ кадра и особых состояний в непрерывном битовом потоке.
Таблица 1 — Кодирование 4В/5В
| Входной символ | Выходной символ |
|---|---|
| 0000 (0) | 11110 |
| 0001 (1) | 01001 |
| 0010 (2) | 10100 |
| 0011 (3) | 10101 |
| 0100 (4) | 01010 |
| 0101 (5) | 01011 |
| 0110 (6) | 01110 |
| 0111 (7) | 01111 |
| 1000 (8) | 10010 |
| 1001 (9) | 10011 |
| 1010 (A) | 10110 |
| 1011 (B) | 10111 |
| 1100 (C) | 11010 |
| 1101 (D) | 11011 |
| 1110 (E) | 11100 |
| 1111 (F) | 11101 |
Избыточность логического кодирования разрешает облегчить задачи физического кодирования — исключить неудобные битовые последовательности, улучшить спектральные характеристики физического сигнала и др. Физическое/сигнальное кодирование пишет правила представления дискретных символов, результат логического кодирования в результат физические сигналы линии. Физические сигналы могут иметь непрерывную (аналоговую) форму — бесконечное число значений, из которого выбирают допустимое распознаваемое множество. На уровне физических сигналов вместо битовой скорости (бит/с) используют понятие скорость изменения сигнала в линии которая измеряется в бодах (baud). Под таким определением определяют число изменений различных состояний линии за единицу времени. На физическом уровне проходит синхронизация приемника и передатчика. Внешнюю синхронизацию не используют из-за дороговизны реализации еще одного канала. Много схем физического кодирования являются самосинхронизирующимися — они разрешают выделить синхросигнал из принимаемой последовательности состояний канала.
Скремблирование на физическом уровне разрешает подавить очень сильные спектральные характеристики сигнала, размазывая их по некоторой полосе спектра. Очень сильные помеха искажают соседние каналы передачи. При разговоре о физическом кодирировании, возможное использование следующие термины:
- Транзитное кодирование — информативным есть переход из одного состояния в другое
- Потенциальное кодирование — информативным есть уровень сигнала в конкретные моменты времени
- Полярное — сигнал одной полярности реализуется для представления одного значения, сигнал другой полярности для — другого. При оптоволоконное транспортировке вместо полярности используют амплитуды импульса
- Униполярное — сигнал одной полярности реализуется для представления одного значения, нулевой сигнал — для другого
- Биполярное — используется отрицательное, положительное и нулевое значения для представления трех состояний
- Двухфазное — в каждом битовом интервале присутствует переход из одного состояния в другое, что используется для выделения синхросигнала.
Популярные схемы кодирования, которые применяются в локальных сетях
AMI/ABP
AMI — Alternate Mark Inversion или же ABP — Alternate bipolare, биполярная схема, которая использует значения +V, 0V и -V. Все нулевые биты имеют значения 0V, единичные — чередующимися значениями +V, -V (рис.1). Применяется в DSx (DS1 — DS4), ISDN. Такая схема не есть полностью самосинхронизирующейся — длинная цепочка нулей приведет к потере синхронизации.
Рисунок — 1
MAMI — Modified Alternate Mark Inversion, или же ASI — модифицированная схема AMI, импульсами чередующейся полярности кодируется 0, а 1 — нулевым потенциалом. Применяется в ISDN (S/T — интерфейсы).
B8ZS — Bipolar with 8 Zero Substitution, схема аналогичная AMI, но для синхронизации исключает цепочки 8 и более нулей (за счет вставки бит).
HDB3 — High Density Bipolar 3, схема аналогичная AMI, но не допускает передачи цепочки более трех нулей. Вместо последовательности из четырех нулей вставляется один из четырех биполярных кодов. (Рис.2)
 Рисунок — 2
Рисунок — 2
Манчестерское кодирование
Manchester encoding — двухфазное полярное/униполярное самосинхронизирующееся кодирование. Текущий бит узнается по направлению смены состояния в середине битового интервала: от -V к +V: 1. От +V к -V: 0. Переход в начале интервала может и не быть. Применяется в Ethernet. (В начальных версиях — униполярное). (рис.3)
 Рисунок — 3
Рисунок — 3
Differential manchester encoding — двухфазное полярное/униполярное самосинхронизирующиеся код. Текущий бит узнается по наличию перехода в начале битового интервала (рис. 4.1), например 0 — есть переход (Вертикальный фрагмент), 1 — нет перехода (горизонтальный фрагмент). Можно и наоборот определять 0 и 1.В середине битового интервала переход есть всегда. Он нужен для синхронизации. В Token Ring применяется измененная версия такой схемы, где кроме бит 0 и 1 определенны также два бита j и k (Рис. 4.2). Здесь нет переходов в середине интервала. Бит К имеет переход в начале интервала, а j — нет.
 Рисунок — 4.1 и 4.2
Рисунок — 4.1 и 4.2
Трехуровневое кодирование со скремблированием который не самосинхронизуется. Используются уровни (+V, 0, -V) постоянные в линии каждого битового интервала. При передаче 0 значения не меняются, при передаче 1 — меняются на соседние по цепочке +V, 0, -V, 0, +V и тд. (рис. 5). Такая схема является усложнонным вариантом NRZI. Применяется в FDDI и 100BaseTX.
 Рисунок — 5
Рисунок — 5
NRZ и NRZI
NRZ — Non-return to zero (без возврата к нулю), биполярная нетранзиктивная схема (состояния меняются на границе), которая имеет 2 варианта. Первый вариант это недифференциальное NRZ (используется в RS-232) состояние напрямую отражает значение бита (рис. 6.а). В другом варианте — дифференциальном, NRZ состояние меняется в начале битового интервала для 1 и не меняется для 0. (рис.6.Б). Привязки 1 и 0 к определенному состоянию нету.
NRZI — Non-return to zero Inverted, измененная схема NRZ (рис. 6.в). Тут состояния изменяются на противоположные в начале битового интервала 0, и не меняются при передаче 1. Возможна и обратная схема представления. Используются в FDDI, 100BaseFX.
 Рисунок — 6-а,б,в
Рисунок — 6-а,б,в
RZ — Return to zero (с возвратом к нулю), биполярная транзитивная самосинхронизирующаяся схема. Состояние в определенный момент битового интервала всегда возвращается к нулю. Имеет дифференциальный/недифференциальный варианты. В дифференциальном привязки 1 и 0 к состоянию нету. (рис. 7.а).
 Рисунок — 7-а,б
Рисунок — 7-а,б
FM 0 — Frequency Modulation 0 (частотная модуляция), самосинхронизирующийся полярный код. Меняется на противоположное на границе каждого битового интервала. При передаче 1 в течение битового интервала состояние неизменное. При передаче 0, в середине битового интервала состояние меняется на противоположное. (рис. 8). Используется в LocalTalk.
 Рисунок — 8
Рисунок — 8
PAM 5 — Pulse Amplitude Modulation, пятиуровневое биполярное кодирование, где пара бит в зависимости от предыстории оказывается одним из 5 уровней потенциала. Нужен неширокая полоса частот (вдвое ниже битовой скорости). Используется в 1000BaseT.
Здесь пара бит оказывается одним четверичным символом (Quater-nary symbol), где каждому соответствует один из 4 уровней сигнала. В табллице показано представление символов в сети ISDN.
4B3T — блок из 4 бит (16 состояний) кодируется тремя троичными символами (27 символов). Из множества возможных методов изменений рассмотрим MMS43, который используется в интерфейсе BRI сетей ISDN (таблица). Тут применяются специальные методы для исключения постоянной составляющей напряжения в линии, в следствии чего кодирования ряда комбинаций зависит от предыстории — состояния, где находится кодер. Пример: последовательность бит 1100 1101 будет представлена как: + + + — 0 -.
| Двоичный код | S1 | Переход | S2 | Переход | S3 | Переход | S4 | Переход |
|---|---|---|---|---|---|---|---|---|
| 0001 | 0 — + | S1 | 0 — + | S2 | 0 — + | S3 | 0 — + | S4 |
| 0111 | — 0 + | S1 | — 0 + | S2 | — 0 + | S3 | — 0 + | S4 |
| 0100 | — + 0 | S1 | — + 0 | S2 | — + 0 | S3 | — + 0 | S4 |
| 0010 | + — 0 | S1 | + — 0 | S2 | + — 0 | S3 | + — 0 | S4 |
| 1011 | + 0 — | S1 | + 0 — | S2 | + 0 — | S3 | + 0 — | S4 |
| 1110 | 0 + — | S1 | 0 + — | S2 | 0 + — | S3 | 0 + — | S4 |
| 1001 | + — + | S2 | + — + | S3 | + — + | S4 | — — — | S1 |
| 0011 | 0 0 + | S2 | 0 0 + | S3 | 0 0 + | S4 | — — 0 | S2 |
| 1101 | 0 + 0 | S2 | 0 + 0 | S3 | 0 + 0 | S4 | — 0 — | S2 |
| 1000 | + 0 0 | S2 | + 0 0 | S3 | + 0 0 | S4 | 0 — — | S2 |
| 0110 | — + + | S2 | — + + | S3 | — — + | S2 | — — + | S3 |
| 1010 | + + — | S2 | + + — | S3 | + — — | S2 | + — — | S3 |
| 1111 | + + 0 | S3 | 0 0 — | S1 | 0 0 — | S1 | 0 0 — | S3 |
| 0000 | + 0 + | S3 | 0 — 0 | S1 | 0 — 0 | S2 | 0 — 0 | S3 |
| 0101 | 0 + + | S3 | — 0 0 | S1 | — 0 0 | S2 | — 0 0 | S3 |
| 1100 | + + + | S4 | — + — | S1 | — + — | S2 | — + — | S3 |
Итог
Схемы, которые не являются самосинхронизирующими, вместе с логическим кодированием и определением фиксированной длительности битовых интервалов разрешают достигать синхронизации. Старт-бит и стоп-бит служат для синхронизации, а контрольный бит вводит избыточность для повышения достоверности приема.
1.5 Кодирование сигналов
1.5.1 Основные виды и способы обработки
и кодирования данных
Этап подготовки информации связан с процессом формирования структуры информационного потока. Такая структура должна обеспечивать возможность передачи информации от объекта к субъекту (от источника к потребителю) по каналам коммуникаций посредством определенных сигналов или знаков, а также возможность однозначного понимания этих сигналов и обеспечения их записи на соответствующие носители информации. Для этого осуществляется кодирование сигналов.
Кодирование информации – одна из базовых тем курса теоретических основ информатики, отражающая фундаментальную необходимость представления информации в какой-либо форме. При этом слово "кодирование" понимается не в узком смысле – как способ сделать сообщение непонятным для всех, кто не владеет ключом кода, а в широком – как представление информации в виде сообщения на любом языке. В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразоваться в сообщение из символов (букв) другого алфавита.
Код – правило (алгоритм), сопоставляющее каждое конкретное сообщение (информацию) со строго определенной комбинацией различных символов (или соответствующих им сигналов).
Кодирование – процесс преобразования сообщения (информации) в комбинацию различных символов или соответствующих им сигналов, осуществляющийся в момент поступления сообщения от источника в канал связи.
Кодовое слово – последовательность символов, которая в процессе кодирования присваивается каждому из множеств передаваемых сообщений.
Декодирование – процесс восстановления содержания сообщения по данному коду.
Необходимым условием декодирования является взаимно однозначное соответствие кодовых слов во вторичном алфавите кодируемым символам первичного алфавита.
Устройство, обеспечивающее кодирование, называют кодировщиком.
Система кодирования – совокупность правил кодового обозначения объектов – применяется для замены названия объекта на условное обозначение (код) в целях обеспечения удобной и более эффективной обработки информации, т. е. кодирование – это отображение информации с помощью некоторого языка. Любой язык состоит из алфавита, включающего в себя буквы, цифры и другие символы, и правил составления слов и фраз (синтаксических правил).
Первичный алфавит – символы, при помощи которых записано передаваемое сообщении; вторичный – символы, при помощи которых сообщение трансформируется в код.
Код характеризуется длиной (числом позиций в коде) и структурой (порядком расположения символов, используемых для обозначения классификационного признака).
Неравномерные (некомплектные) коды – это коды, с помощью которых сообщения кодируются комбинациями с неравномерным количеством символов; равномерные (комплектные) – коды, с помощью которых сообщения представлены комбинациями с равным количеством символов.
5) Для хранения в ЭВМ информация кодируется. При выборе языка создатели руководствовались следующими соображениями:
Буквы алфавита должны надежно распознаваться (нельзя допустить, чтобы одна буква была принята за другую);
Алфавит должен быть как можно проще, т. е. содержать поменьше букв;
Синтаксис языка (правила построения слов и фраз) должен быть строгим, однозначным, не допускающим неопределенности.
6) Таким свойством обладают математические теории, в них все строго определено.
7) 1.5.2 Кодирование текста
Не возникает никаких проблем при кодировании информации, представимой с помощью ограниченного набора символов – алфавита. Достаточно пронумеровать все знаки этого алфавита и затем записывать в память компьютера и обрабатывать соответствующие номера. Самым простым алфавитом является тот, в котором всего две буквы, два символа.
При кодировании текста для каждого его символа отводится обычно 1 байт. Именно по этой причине ячейка памяти в компьютере сделана так, что может хранить сразу восемь бит (1 байт), т. е. целый символ. Это позволяет использовать 2 8 = 256 различных символов, так как в ЭВМ надо кодировать все буквы: английские – 52 буквы (прописные и строчные), русские – 66 букв, 10 цифр, знаки препинания, арифметических операций и т. п.:
9) Хорошо видно, что если у числа разрядность равна n, то количество n-разрядных чисел равно 2 n:
13) Чтобы закодировать порядка 256 букв и символов, требуется использовать 8-разрядные числа.
Соответствие между символом и его кодом может быть выбрано совершенно произвольно. Однако на практике необходимо иметь возможность прочесть на одном компьютере текст, созданный на другом, поэтому таблицы кодировок стараются стандартизовать. Практически все использующиеся сейчас таблицы основаны на "американском стандартном коде обмена информацией" ASCII. Он определяет значения для нижней половины кодовой таблицы – первых 127 кодов (32 управляющих кода, основные знаки препинания и арифметические символы, цифры и латинские буквы). В результате, эти символы отображаются верно, какая бы кодировка не использовалась на конкретном компьютере. Хуже обстоит дело с национальными символами и типографскими знаками препинания. А особенно не повезло языкам, использующим кириллицу (русскому, украинскому, белорусскому, болгарскому и т. д.).
Например, для русского языка сейчас широко используются пять таблиц кодировок:
CP866 (альтернативная DOS) – на PC-совместимых компьютерах при работе с операционными системами DOS и OS/2, а также в любительской международной сети Фидо (Fidonet);
CP1251 (Windows-кодировка) – на PC-совместимых компью-терах при работе под Windows 3.1 и Windows 95;
KOI-8r – самая старая из использующихся до сих пор кодировок. Применяется на компьютерах, работающих под UNIX, является фактическим стандартом для русских текстов в сети Internet;
Macintosh Cyrillic – предназначена для работы со всеми кириллическими языками на Макинтошах.
ISO-8859. Эта кодировка задумывалась как международный стандарт для кириллицы, однако на территории России практически не применяется.
14) Сейчас, когда объем памяти компьютеров чрезвычайно вырос, уже нет необходимости очень сильно "экономить" при кодировании текста. Можно позволить себе роскошь "тратить" для хранения текста вдвое больше памяти (выделяя для каждого символа не 1, а 2 байт). При этом появляется возможность разместить в кодовой таблице – каждый на своем месте – не только буквы европейских алфавитов (латинского, кириллицы, греческого), но и буквы арабского, грузинского и многих других языков и даже большую часть японских и китайских иероглифов, поскольку два байта могут хранить число от 0 до 65 535. Двухбайтная международная кодировка Unicode, разработанная несколько лет назад, теперь начинает внедряться на практике. В компьютере все составные части соединяются между собой с помощью шины (магистрали), т. е. пучка проводов.
15) Теперь нам должно стать понятно, почему шина содержит 8, 16 или 32 провода. Если в шине 8 проводов, то по ней можно передать одновременно 8 бит, т. е. 1 байт (1 символ) информации. Такой компьютер называется восьмиразрядным, (первые персональные компьютеры IBM).
16) Если в шине 16 проводов, то по ней можно передать одновременно 2 байт информации; если 32 провода – 4 байт, если 64 провода – 8 байт.
18) 1.5.3. Два способа кодирования изображения
Изображение на экране компьютера (или при печати с по-мощью принтера) составляется из маленьких точек – пикселов. Их так много, и они настолько малы, что человеческий глаз воспринимает картинку как непрерывную. Следовательно, качество изображения будет тем выше, чем плотнее расположены пиксели (т. е. чем больше разрешение устройства вывода) и точнее закодирован цвет каждого из них.
В простейшем случае каждый пиксел может быть или черным, или белым. Значит, для его кодирования достаточно одного бита. Однако при этом полутона приходится имитировать, чередуя черные и белые пиксели (заметим, что примерно так формируют полутоновое изображение на принтерах и при типографской печати). Чтобы получить реальные полутона, для хранения каждого пикселя нужно отводить большее количество разрядов. В этом случае черный цвет по-прежнему будет представлен нулем, а белый – максимально возможным числом. Например, при восьмибитном кодировании получится 256 разных значений яркости – 256 полутонов.
Сложнее обстоит дело с цветными изображениями, так как здесь нужно закодировать не только яркость, но и оттенок пикселя. Изображение на мониторе формируется путем сложения в различных пропорциях трех основных цветов: красного, зеленого и синего. Значит просто нам нужно хранить информацию о яркости каждой из этих составляющих.
Для получения наивысшей точности цветопередачи достаточно иметь по 256 значений для каждого из основных цветов (вместе это дает 256 3 – более 16 млн. оттенков). Во многих случаях можно обойтись несколько меньшей точностью цветопередачи. Если использовать для представления каждой составляющей по 5 бит (тогда для хранения данных пикселя будет нужно не 3, а 2 байт), удастся закодировать 32 768 оттенков.
На практике встречаются (и нередко) ситуации, когда гораздо важнее не идеальная точность, а минимальный размер файла: бывают изображения, где изначально используется небольшое количество цветов. В этих случаях поступают так: собирают все нужные оттенки в таблицу и нумеруют, после чего хранят уже не полный код цвета каждого пикселя, а номера (индексы) цветов в таблице. Чаще всего используют 256-цветные таблицы. В разных компьютерах могут быть приняты разные стандартные таблицы цветов, поэтому не исключено, что открыв полученный от кого-нибудь графический файл, можно увидеть совершенно немыслимую картинку.
При печати на бумаге используется несколько иная цветовая модель: если монитор испускает свет, то оттенок получается в результате сложения цветов, а краски поглощают свет – цвета вычитаются. Поэтому в качестве основных используют голубую, сиреневую и желтую краски. Кроме того, из-за неидеальности красителей к ним обычно добавляют четвертую краску – черную. Для хранения информации о каждой краске чаще всего используют 1 байт.
Растровые изображения очень хорошо передают реальные образы. Они замечательно подходят для фотографий, картин и в случаях, когда требуется максимальная "естественность". Такие изображения легко выводить на монитор или принтер, поскольку эти устройства тоже основаны на растровом принципе. Однако есть у них и ряд недостатков. Растровое изображение высокого качества (с высоким разрешением и большой глубиной цвета) может занимать десятки, и даже сотни мегабайт памяти. Для их обработки нужны мощные компьютеры, но и они нередко "задумываются" на десятки минут. Любое изменение размеров неизбежно приводит к ухудшению качества: при увеличении пикселы не могут появиться "из ничего", при уменьшении – часть пикселов будет просто выброшена.
Есть другой способ представления изображений – объектная (векторная) графика. В этом случае в памяти хранится не сам рисунок, а правила его построения, т. е., например, не все пикселы круга, а команда "построить круг радиусом 30 с центром в точке с координатами (50, 135) и закрасить его красным цветом". Быстродействия современных компьютеров вполне достаточно, чтобы перерисовка происходила почти мгновенно.
На первый взгляд, все становится гораздо более сложным. Зачем же это нужно? Во-первых, и это самое главное, векторное изображение можно как угодно масштабировать, выводить на устройства, имеющие любое разрешение, – и всегда будет получаться результат с наивысшим для данного устройства качеством, ведь картинка каждый раз "рисуется" заново, используя столько пикселов, сколько возможно.
Во-вторых, в векторном изображении все части (так называемые "примитивы") могут быть изменены независимо друг от друга: любой из них можно увеличить, повернуть, деформировать, перекрасить, даже стереть, но остальных объектов это никоим образом не коснется.
В-третьих, даже очень сложные векторные рисунки, содержащие тысячи объектов, редко занимают более нескольких сотен килобайт, т. е. в десятки, сотни, а то и тысячи раз меньше аналогичного растрового.
Но почему, если все так хорошо, векторная графика не вытеснила растровую? Сам принцип ее формирования предполагает использование объектов с исключительно ровными четкими границами, а это сразу выдает их искусственность, поэтому область применения векторной графики довольно ограничена – это чертежи, схемы, стилизованные рисунки, эмблемы и другие подобные изображения.
Вычислительной техники, а также принципы функционирования этих средств и методы управления ими. Из этого определения видно, что информатика очень близка к технологии, поэтому ее предмет нередко называют информационной технологией. Предмет информатики составляют следующие понятия: а) аппаратное обеспечение средств вычислительной техники; б) программное обеспечение средств вычислительной техники...




... » (Zero Administration Initiative), которая будет реализована во всех следующих версиях Windows. SMS- сервер управления системами У SMS две задачи - централизовать управление сетью и упростить распространение программного обеспечения и его модернизацию на клиентских системах. SMS подойдет и малой, и большой сети - это инструмент управления сетью на базе Windows NT, эффективно использующий...
Простейшими кодерами/декодерами речи, вообще не использующими информацию о том, как был сформирован кодируемый сигнал, а просто старающимися максимально приблизить восстанавливаемый сигнал по форме к оригиналу, являются кодеры/декодеры формы сигнала . Теоретически они инвариантны к характеру сигнала, подаваемого на их вход, и могут использоваться для кодирования любых, в том числе и неречевых, сигналов. Эти кодеры - самые простые по принципу действия и устройству, но больших степеней сжатия (низких скоростей кода) обеспечить не могут.
Простейшим способом кодирования формы сигнала является так называемая импульсно-кодовая модуляция – ИКМ (или PCM – Pulse Code Modulation), при использовании которой производятся просто дискретизация и равномерное квантование входного сигнала, а также преобразование полученного результата в равномерный двоичный код.
Для речевых сигналов со стандартной для передачи речи полосой 0,3 – 3,5 кГц обычно используют частоту дискретизации F дискр ³2F max = 8 кГц. Экспериментально показано, что при равномерном квантовании для получения практически идеального качества речи нужно квантовать сигнал не менее чем на ± 2000 уровней, иными словами, для представления каждого отсчета понадобится 12 бит, а результирующая скорость кода будет составлять
R = 8000 отсчетов/с * 12 бит/отсчет = 96000 бит/с = 96 кбит/с.
Используя неравномерное квантование (более точное для малых уровней сигнала и более грубое для больших его уровней, таким образом, чтобы относительная ошибка квантования была постоянной для всех уровней сигнала ), можно достичь того же самого субъективного качества восстановления речевого сигнала, но при гораздо меньшем числе уровней квантования – порядка ± 128 . В этом случае для двоичного представления отсчетов сигнала понадобится уже 8 бит и результирующая скорость кода составит 64 кбит/с.
С учетом статистических свойств речевого сигнала (вида распределения вероятностей мгновенных значений), а также нелинейных свойств слуха, гораздо лучше различающего слабые звуки, оптимальной является логарифмическая шкала квантования, которая и была принята в качестве стандарта еще в середине 60-х годов и сегодня повсеместно используется. Правда, в США и Европе стандарты нелинейного квантования несколько различаются (m-law companding и A-law compression), что приводит к необходимости перекодирования сигналов.
Таким образом, исходной для любого сравнения эффективности и качества кодирования речевых сигналов может служить скорость кода, равная 64 кбит/с.
Следующим приемом, позволяющим уменьшить результирующую скорость кода, может быть попытка предсказать значение текущего отсчета сигнала по нескольким предыдущим его значениям, и далее, кодирование уже не самого отсчета, а ошибки его предсказания – разницы между истинным значением текущего отсчета и его предсказанным значением . Если точность предсказания достаточно высока, то ошибка предсказания очередного отсчета будет значительно меньше величины самого отсчета и для ее кодирования понадобится гораздо меньшее число бит. Таким образом, чем более предсказуемым будет поведение кодируемого сигнала, тем более эффективным будет его сжатие.
Описанная идея лежит в основе так называемой дифференциальной импульсно-кодовой модуляции - ДИКМ (DPCM ) – способа кодирования, при котором кодируются не сами значения сигнала, а их отличия от некоторым образом предсказанных значений. Простейшим способом предсказания является использование предыдущего отсчета сигнала в качестве предсказания его текущего значения :
x* i = x i –1 , e i = x i - x* I . (8.10)
Это так называемое предсказание нулевого порядка , самое простое, но и наименее точное. Более точным, очевидно, будет предсказание текущего отсчета на основе линейной комбинации двух предшествующих и т.д.:
x* i = å a k x i – k , e i = x i - x* I . (8.11)
К сожалению, точность предсказания не всегда растет с ростом порядка предсказания, поскольку свойства сигнала между отсчетами начинают уже изменяться, поэтому обычно ограничиваются предсказанием не выше 2 – 3-го порядка.
На рис. 8.16 и 8.17 приведены схемы ДИКМ кодера и декодера.
При кодировании речевых сигналов с учетом степени их кратковременной (на несколько очередных отсчетов) предсказуемости результирующая скорость кода для ДИКМ (DPCM ) обычно составляет 5 – 6 бит на отсчет или 40 – 48 кбит/с.
Эффективность ДИКМ может быть несколько повышена, если предсказание и квантование сигнала будет выполняться не на основе некоторых усредненных его характеристик, а с учетом их текущего значения и изменения во времени, то есть адаптивно. Так, если скорость изменения сигнала стала большей, можно увеличить шаг квантования, и, наоборот, если сигнал стал изменяться гораздо медленнее, величину шага квантования можно уменьшить. При этом ошибка предсказания уменьшится и, следовательно, будет кодироваться меньшим числом бит на отсчет. Такой способ кодирования называется адаптивной ДИКМ , или АДИКМ (ADPCM ). Сегодня такой способ кодирования стандартизован и широко используется при сжатии речи в междугородных цифровых системах связи, в системе микросотовой связи DECT , в цифровых бесшнуровых телефонах и т.д. Использование АДИКМ со скоростью кода 4 бита/отсчет или 32 кбит/с обеспечивает такое же субъективное качество речи, что и 64 кбит/с - ИКМ , но при вдвое меньшей скорости кода.
На сегодня стандартизованы также АДИКМ – кодеки для скоростей 40, 24 и 16 кбит/с (в последнем случае с несколько худшим, чем для 32 кбит/с – АДИКМ, качеством сигнала). Таким образом, видно, что сжатие речевых сигналов на основе кодирования их формы обеспечивает в лучшем случае двух - трехкратное уменьшение скорости кода. Дальнейшее снижение скорости ведет к резкому ухудшению качества кодируемого сигнала.
Описанные выше кодеры формы сигнала использовали чисто временной подход к описанию этого сигнала. Однако возможны и другие подходы. Примером может служить так называемое кодирование поддиапазонов (Sub-Band Coding - SBC ), при котором входной сигнал разбивается (или расфильтровывается) на несколько частотных диапазонов (поддиапазонов - sub-bands) и сигнал в каждом из этих поддиапазонов кодируется по отдельности, например, с использованием техники АДИКМ .
Поскольку каждый из частотных поддиапазонов имеет более узкую полосу (все поддиапазоны в сумме дают полосу исходного сигнала), то и частота дискретизации в каждом поддиапазоне также будет меньше. В результате суммарная скорость всех кодов будет по крайней мере не больше, чем скорость кода для исходного сигнала. Однако у такой техники есть определенные преимущества. Дело в том, что субъективная чувствительность слуха к сигналам и их искажениям различна на разных частотах. Она максимальна на частотах 1 - 1,5 кГц и уменьшается на более низких и более высоких частотах. Таким образом, если в диапазоне более высокой чувствительности слуха квантовать сигнал более точно, а в диапазонах низкой чувствительности более грубо, то можно получить выигрыш в результирующей скорости кода. Действительно, при использовании технологии кодирования поддиапазонов получено хорошее качество кодируемой речи при скорости кода 16 – 32 кбит/с. Кодер получается несколько более сложным, чем при простой АДИКМ, однако гораздо проще, нежели для других эффективных способов сжатия речи.
Упрощенная схема подобного кодера (с разбиением на 2 поддиапазона) приведена на рис. 8.18.
Близким к кодированию поддиапазонов является метод сжатия, основанный на применении к сигналу линейных преобразований, к примеру, дискретного косинусного или синусного преобразования. Для кодирования речи используется так называемая технология ATC (Adaptive Transform Coding), при которой сигнал разбивается на блоки, к каждому блоку применяется дискретное косинусное преобразование и полученные коэффициенты адаптивно, в соответствии с характером спектра сигнала, квантуются.
Чем более значимыми являются коэффициенты преобразования, тем большим числом бит они кодируются. Техника очень похожа на JPEG , но применяется к речевым сигналам. Достигаемые при таком кодировании скорости кодов составляют 12 – 16 кбит/с при вполне удовлетворительном качестве сигнала. Широкого распространения для сжатия речи этот метод не получил, поскольку известны гораздо более эффективные и простые в исполнении методы кодирования.
Рис. 8.18. Схема, поясняющая кодирование поддиапазонов
Следующим большим классом кодеров речевых сигналов являются кодеры источника.
Кодирование источника
В отличие от кодеров формы сигнала , вообще не использующих информацию о том, как был сформирован кодируемый сигнал, кодеры источника основываются именно на модели источника и из кодируемого сигнала извлекают информацию о параметрах этой модели. При этом результатом кодирования являются не коды сигналов, а коды параметров источника этих сигналов. Кодеры источника для кодирования речи называются вокодерами (VOice CODERS) и работают примерно следующим образом. Голосообразующий тракт представляется как линейный фильтр с переменными во времени параметрами, возбуждаемый либо источником белого шума (при формировании согласных звуков), либо последовательностями импульсов с периодом основного тона (при формировании гласных звуков) – рис. 8.19 .
Линейная модель системы речеобразования и ее параметры могут быть найдены различными способами. И от того, каким способом они определяются, зависит тип вокодера.
Информация, которую получает вокодер в результате анализа речевого сигнала и передает декодеру, это параметры речеобразующего фильтра, указатель гласный/негласный звук, мощность сигнала возбуждения и период основного тона для гласных звуков . Эти параметры должны обновляться каждые 10 – 20 мс, чтобы отслеживать нестационарность речевого сигнала.
Вокодер, в отличие от кодера формы сигнала, пытается сформировать сигнал, звучащий как оригинальная речь, и не обращает внимания на отличие формы этого сигнала от исходного. При этом результирующая скорость кода на его выходе обычно составляет не более 2,4 кбит/с, то есть в пятнадцать раз меньше, чем при АДИКМ ! К сожалению, качество речи, обеспечиваемой вокодерами, очень далеко от идеального, ее звучание хотя и достаточно разборчиво, но абсолютно ненатурально. При этом даже существенное увеличение скорости кода практически не улучшает качества речи, поскольку для кодирования была выбрана слишком простая модель системы речеобразования. Особенно грубым является предположение о том, что речь состоит лишь из гласных и согласных звуков, не допускающее каких либо промежуточных состояний.
Основное применение вокодеры нашли в военной области, где главное – это не натуральность речи, а большая степень ее сжатия и очень низкая скорость кода, позволяющая эффективно защищать от перехвата и засекречивать передаваемую речь. Кратко рассмотрим основные из известных типов вокодеров.
Канальные вокодеры. Это наиболее древний тип вокодера, предложенный еще в 1939 году. Этот вокодер использует слабую чувствительность слуха человека к незначительным фазовым (временным) сдвигам сигнала.
Для сегментов речи длиной примерно в 20 - 30 мс с помощью набора узкополосных фильтров определяется амплитудный спектр. Чем больше фильтров, тем лучше оценивается спектр, но тем больше нужно бит для его кодирования и тем больше результирующая скорость кода. Сигналы с выходов фильтров детектируются, пропускаются через ФНЧ, дискретизуются и подвергаются двоичному кодированию (рис. 8.20).
Таким образом, определяются медленно изменяющиеся параметры голосообразующего тракта и, кроме того, с помощью детекторов основного тона и гласных звуков, – период основного тона возбуждения и признак - гласный/негласный звук.
Канальный вокодер может быть реализован как в цифровой, так и в аналоговой форме и обеспечивает достаточно разборчивую речь при скорости кода на его выходе порядка 2,4 кбит/с.
Рис. 8.20. Схема начального вокодера
Декодер (рис. 8.21), получив информацию, вырабатываемую кодером, обрабатывает ее в обратном порядке, синтезируя на своем выходе речевой сигнал, в какой-то мере похожий на исходный.
Учитывая простоту модели, трудно ожидать от вокодерного сжатия хорошего качества восстановленной речи. Действительно, канальные вокодеры используются в основном только там, где главным образом необходимы разборчивость и высокая степень сжатия: в военной связи, авиации, космической связи и т.д.
|
Гомоморфный вокодер. Гомоморфная обработка сигналов представляет собой один из нелинейных методов обработки, который может эффективно применяться к сложным сигналам, например к речевым.
С учетом используемой в вокодерах модели системы голособразования речевой сигнал можно представить как временную свертку импульсной переходной характеристики голосового тракта с сигналом возбуждения. В частотной области это соответствует произведению частотной характеристики голосового тракта и спектра сигнала возбуждения. Наконец, если взять логарифм от этого произведения, то получим сумму логарифмов спектра сигнала возбуждения и частотной характеристики голосового тракта. Поскольку человеческое ухо практически не чувствительно к фазе сигнала, можно оперировать с амплитудными спектрами:
log(|S(e jw)|) = log(|P(e jw)|) + log(|V(e jw)|, (8.12)
где S(e jw) - спектр речи, P(ejw) спектр сигнала возбуждения и V(ejw) - частотная характеристика голосового тракта.
Если теперь выполнить над log(|S(e jw)|) обратное преобразование Фурье (ОПФ ), то получим так называемый кепстр сигнала. Параметры голосового тракта изменяются во времени сравнительно медленно (их спектр находится в области низких частот - НЧ), тогда как сигнал возбуждения – быстроосциллирующая функция (ее спектр сосредоточен в области высоких частот - ВЧ). Поэтому в кепстре речевого сигнала эти составляющие разделяются (рис. 8.22) и могут быть закодированы по отдельности.
Рис. 8.22. Представление речевого сигнала в виде НЧ и ВЧ составляющих
Схема гомоморфного кодера/декодера речи приведена на рис. 8.23, с его использованием можно получить скорость кода порядка 4 кбит/с.
Формантные вокодеры. Как уже отмечалось ранее, основная информация о речевом сигнале содержится в положении и ширине составляющих его формант. Если с высокой точностью определять и кодировать параметры этих формант, можно получить очень низкую результирующую скорость кода – менее 1 кбит/с. К сожалению, сделать это очень трудно, поэтому формантные кодеры речи пока не нашли широкого распространения.
Вокодеры с линейным предсказанием. Вокодеры на основе линейного предсказания используют такую же модель речеобразования, что и остальные из рассмотренных. Что их отличает – это метод определения параметров тракта. Линейные предсказывающие кодеры, или ЛПК, полагают голосовой тракт линейным фильтром с непрерывной импульсной переходной характеристикой, в котором каждое очередное значение сигнала может быть получено как линейная комбинация некоторого числа его предыдущих значений.
Рис. 8.23. Схема гомоморфного кодера/декодера
В ЛПК-вокодере речевой сигнал делится на блоки длиной около 20 мс, для каждого из которых определяются коэффициенты предсказывающего фильтра. Эти коэффициенты квантуются и передаются декодеру. Затем речевой сигнал пропускается через фильтр, частотная характеристика которого обратна частотной характеристике голосового тракта. На выходе фильтра получается ошибка предсказания. Назначение предсказателя – устранить корреляцию между соседними отсчетами сигнала. В результате гораздо отчетливее проявляется долговременная корреляция в сигнале, что позволяет точнее определить частоту основного тона и выделить признак гласный/согласный звук.
Вокодеры на основе линейного предсказания сейчас наиболее популярны, поскольку все используемые ими фильтровые модели речевого тракта работают очень хорошо. Получаемые с их помощью скорости кодов при неплохом качестве речи составляют до 2,4 кбит/с.
Нижним уровнем в иерархии кодирования является физическое кодирование, которое определяет число дискретных уровней сигнала (амплитуды напряжения, амплитуды тока, амплитуды яркости).
Физическое кодирование рассматривает кодирование только на самом низшем уровне иерархии кодирования - на физическом уровне и не рассматривает более высокие уровни в иерархии кодирования, к которым относятся логические кодирования различных уровней.
С точки зрения физического кодирования цифровой сигнал может иметь два, три, четыре, пять и т. д. уровней амплитуды напряжения, амплитуды тока, амплитуды света.
Ни в одной из версий технологии Ethernet не применяется прямое двоичное кодирование бита 0 напряжением 0 вольт и бита 1 - напряжением +5 вольт, так как такой способ приводит к неоднозначности. Если одна станция посылает битовую строку 00010000, то другая станция может интерпретировать её либо как 10000, либо как 01000, так как она не может отличить «отсутствие сигнала» от бита 0. Поэтому принимающей машине необходим способ однозначного определения начала, конца и середины каждого бита без помощи внешнего таймера. Кодирование сигнала на физическом уровне позволяет приемнику синхронизироваться с передатчиком по смене напряжения в середине периода битов.
В некоторых случаях физическое кодирование решает проблемы:
Логическое кодирование
Вторым уровнем в иерархии кодирования является самый нижний уровень логического кодирования с разными назначениями.
В совокупности физическое кодирование и логическое кодирование образуют систему кодирования низкого уровня.
Форматы кодов [ ]
Каждый бит кодового слова передается или записывается с помощью дискретных сигналов, например, импульсов. Способ представления исходного кода определенными сигналами определяется форматом кода. Известно большое количество форматов, каждый из которых имеет свои достоинства и недостатки и предназначен для использования в определенной аппаратуре.
Направление перепада при передаче сигнала единицы не имеет значения. Поэтому изменение полярности кодированного сигнала не влияет на результат декодирования. Он может передаваться по симметричным линиям без постоянной составляющей. Это также упрощает его магнитную запись. Этот формат известен также под названием «Манчестер 1». Он используется в адресно-временном коде SMPTE, широко применяющемся для синхронизации носителей звуковой и видеоинформации.
Системы с двухуровневым кодированием
NRZ (Non Return to Zero)
NRZ (Non Return to Zero, с англ. - «без возвращения к нулю») - двухуровневый код. Логическому нулю соответствует нижний уровень, логической единице - верхний уровень. Информационные переходы происходят на границе значащих интервалов (значащий момент) .
Варианты представления кода NRZ
Различают несколько вариантов представления кода:
- Униполярный код - логическая единица представлена верхним потенциалом, логический нуль представлен нулевым потенциалом;
- Биполярный код - логическая единица представлена положительным потенциалом, логический нуль представлен отрицательным потенциалом.
Достоинства NRZ кода
- Простая реализация;
- Высокая скорость передачи данных;
- Для синхронизации передачи байта используется старт-стоповый бит.
Недостатки NRZ кода
NRZI (Non Return to Zero Invertive) - потенциальный код с инверсией при единице, код формируется путем инверсного состояния при поступлении на вход кодирующего устройства логической единицы, при поступлении логического нуля состояние потенциала не меняется. Этот метод является модифицированным методом Non Return to Zero (NRZ) .
Поскольку код не защищен от долгих последовательностей логических нулей или единиц, то это может привести к проблемам синхронизации. Поэтому перед передачей, заданную последовательность битов рекомендуется предварительно закодировать кодом предусматривающим скремблирование (скремблер предназначен для придания свойств случайности передаваемой последовательности данных с целью облегчения выделения тактовой частоты приемником). Используется в Fast Ethernet 100Base-FX и 100Base-T4.
Достоинства NRZI кода
- Простота реализации;
- Метод обладает хорошей распознаваемостью ошибок (благодаря наличию двух резко отличающихся потенциалов);
- Спектр сигнала расположен в низкочастотной области относительно частоты следования значащих интервалов.
Недостатки NRZI кода
- Метод не обладает свойством самосинхронизации. Даже при наличии высокоточного тактового генератора приёмник может ошибиться с выбором момента съёма данных, так как частоты двух генераторов никогда не бывают полностью идентичными. Поэтому при высоких скоростях обмена данными и длинных последовательностях единиц или нулей небольшое рассогласование тактовых частот может привести к ошибке в целый такт и, соответственно, считыванию некорректного значения бита;
- Вторым серьёзным недостатком метода, является наличие низкочастотной составляющей, которая приближается к постоянному сигналу при передаче длинных последовательностей единиц и нулей (можно обойти сжатием передаваемых данных). Из-за этого многие линии связи, не обеспечивающие прямого гальванического соединения между приёмником и источником, этот вид кодирования не поддерживают. Поэтому в сетях код NRZ в основном используется в виде различных его модификаций, в которых устранены как плохая самосинхронизация кода, так и проблемы постоянной составляющей.
Манчестерское кодирование
|
Манчестерское кодирование |
При манчестерском кодировании каждый такт делится на две части. Информация кодируется перепадами потенциала в середине каждого такта. Различают два варианта манчестерского кодирования:
В начале каждого такта может происходить служебный перепад сигнала, если нужно представить несколько единиц или нулей подряд. Так как сигнал изменяется по крайней мере один раз за такт передачи одного бита данных, то манчестерский код обладает самосинхронизирующими свойствами. Обязательное наличие перехода в центре бита позволяет легко выделить синхросигнал. Допустимое расхождение частот передачи - до 25 % (это означает, что код Манчестер-2 - самый устойчивый к рассинхронизации, он самосинхронизуется в каждом бите передаваемой информации).
Плотность кода 1 бит/герц. В спектре сигнала, закодированного Манчестером-2, присутствует 2 частоты - частота передачи и половинная частота передачи (она образуется когда рядом стоят 0 и 1 или 1 и 0. При передаче гипотетической последовательности одних 0 или 1 в спектре будет присутствовать только частота передачи).
Достоинства манчестерского кодирования
- Нет постоянной составляющей (смена сигнала происходит на каждом такте передачи данных)
- Полоса частот в сравнении с NRZ кодированием - основная гармоника в при передаче последовательности единиц или нулей имеет частоту N Гц, а при постоянной последовательности (при передаче чередования единиц и нулей) - N/2 Гц.
- Является самосинхронизирующимся , то есть не требует специальной кодировки синхроимпульса, который бы занимал полосу данных и поэтому является самым плотным кодом на единицу частоты.
- Возможность обеспечить гальваническую развязку с помощью трансформатора, так как у него отсутствует постоянная составляющая
- Вторым важным преимуществом является отсутствие необходимости в синхронизующих битах (как в NRZ-коде) и, вследствие этого, данные могут передаваться подряд сколь угодно долго, из-за чего плотность данных в общем потоке кода приближается к 100 % (например для кода NRZ 1-8-0 она равна 80 %).
Код Миллера
Код Миллера (иногда называют трехчастотным) - является двуполярным двухуровневым кодом, в котором каждый информационный бит кодируется комбинацией из двух битов {00, 01,10,11}, а переходы из одного состояния в другое описываются графом . При непрерывном поступлении логических нулей или единиц на кодирующее устройство переключение полярности происходит с интервалом T, а переход от передачи единиц к передаче нулей с интервалом 1,5T. При поступлении на кодирующее устройство последовательности 101 возникает интервал 2Т, по этой причине данный метод кодирования называют трехчастотным .
Преимущества
- Нет избыточности в коде (нет специальных комбинаций для синхронизации);
- Способность к самосинхронизации (в самом коде заложен принцип по которому гарантированно можно синхронизироваться);
- Полоса пропускания кода Миллера вдвое меньше полосы пропускания в сравнении с манчестерским кодированием.
Недостатки
- Присутствие постоянной составляющей, при этом достаточно велик и низкочастотный компонент, что преодолено в модифицированном коде Миллера в квадрате.
Системы с трёхуровневым кодированием
RZ (return to zero)
AMI -код использует следующие представления битов:
- биты 0 представляются нулевым напряжением (0 В)
- биты 1 представляются поочерёдно значениями -U или +U (В)
HDB3 (биполярный код с высокой плотностью третьего порядка)
Код HDB3 (биполярный код с высокой плотностью третьего порядка ) исправляет любые 4 подряд идущих нуля в исходной последовательности. Правило формирования кода следующее: каждые 4 нуля заменяются 4 символами в которых имеется хотя бы один сигнал V. Для подавления постоянной составляющей полярность сигнала V чередуется при последовательных заменах. Для замены используются два способа:
- Если перед заменой исходный код содержал нечётное число единиц то используется последовательность 000V
- Если перед заменой исходный код содержал чётное число единиц то используется последовательность 100V
V-сигнал единицы запрещённого для данного сигнала полярности
Тоже что и AMI , только кодирование последовательностей из четырех нулей заменяется на код -V/0, 0, 0, -V или +V/0, 0, 0, +V - в зависимости от предыдущей фазы сигнала и количества единиц в сигнале, предшествующем данной последовательности нулей.
MLT-3
|
Кодирование MLT-3 |
MLT-3 (Multi Level Transmission - 3) (англ. многоуровневая передача) - метод кодирования, использующий три уровня сигнала. Метод основывается на циклическом переключении уровней -U, 0, +U. Единице соответствует переход с одного уровня сигнала на следующий. Так же как и в методе NRZI при передаче логического нуля сигнал не меняется. Метод разработан Cisco Systems для использования в сетях FDDI на основе медных проводов, известных как CDDI. Также используется в Fast Ethernet 100BASE-TX . Единице соответствует переход с одного уровня сигнала на другой, причем изменение уровня сигнала происходит последовательно с учетом предыдущего перехода. При передаче нуля сигнал не меняется.
Преимущества MLT-3 кода
- В случае наиболее частого переключения уровней (длинная последовательность единиц) для завершения цикла необходимо четыре перехода. Это позволяет вчетверо снизить частоту несущей относительно тактовой частоты, что делает MLT-3 удобным методом при использовании медных проводов в качестве среды передачи.
- Этот код, так же как и NRZI нуждается в предварительном кодировании. Используется в Fast Ethernet 100Base-TX .
Гибридный троичный код (англ.) русск.
| Входной бит | Предыдущее состояние на выходе |
Выходной бит |
|---|---|---|
| 0 | + | − |
| 0 | ||
| − | 0 | |
| 1 | + | |
| 0 | + | |
| − |
4B3T
4B3T (4 Binary 3 Ternary, когда 4 двоичных символа передаются с помощью 3 троичных символов) - cигнал на выходе кодирующего устройства, согласно коду 4B3T, является трехуровневым, то есть на выходе кодирующего устройства формируется сигнал с тремя потенциальными уровнями. Код формируется, например, согласно таблице кодирования MMS43 . Таблица кодирования:
| Input | Accumulated DC offset | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| 0000 | + 0 + (+2) | 0−0 (−1) | ||
| 0001 | 0 − + (+0) | |||
| 0010 | + − 0 (+0) | |||
| 0011 | 0 0 + (+1) | − − 0 (−2) | ||
| 0100 | − + 0 (+0) | |||
| 0101 | 0 + + (+2) | − 0 0 (−1) | ||
| 0110 | − + + (+1) | − − + (−1) | ||
| 0111 | − 0 + (+0) | |||
| 1000 | + 0 0 (+1) | 0 − − (−2) | ||
| 1001 | + − + (+1) | − − − (−3) | ||
| 1010 | + + − (+1) | + − − (−1) | ||
| 1011 | + 0 − (+0) | |||
| 1100 | + + + (+3) | − + − (−1) | ||
| 1101 | 0 + 0 (+1) | − 0 − (−2) | ||
| 1110 | 0 + − (+0) | |||
| 1111 | + + 0 (+2) | 0 0 − (−1) | ||
Таблица декодирования:
| Ternary | Binary | Ternary | Binary | Ternary | Binary | ||
|---|---|---|---|---|---|---|---|
| 0 0 0 | н/д | − 0 0 | 0101 | + − − | 1010 | ||
| + 0 + | 0000 | − + + | 0110 | + 0 − | 1011 | ||
| 0 − 0 | 0000 | − − + | 0110 | + + + | 1100 | ||
| 0 − + | 0001 | − 0 + | 0111 | − + − | 1100 | ||
| + − 0 | 0010 | + 0 0 | 1000 | 0 + 0 | 1101 | ||
| 0 0 + | 0011 | 0 − − | 1000 | − 0 − | 1101 | ||
| − − 0 | 0011 | + − + | 1001 | 0 + − | 1110 | ||
| − + 0 | 0100 | − − − | 1001 | + + 0 | 1111 | ||
| 0 + + | 0101 | + + − | 1010 | 0 0 − | 1111 |
Системы с четырёхуровневым кодированием
2B1Q (Потенциальный код 2B1Q)
Достоинство метода 2B1Q
- Сигнальная скорость у этого метода в два раза ниже, чем у кодов NRZ и AMI, а спектр сигнала в два раза уже. Следовательно с помощью 2B1Q-кода можно по одной и той же линии передавать данные в два раза быстрее.
Недостатки метода 2B1Q
- Реализация этого метода требует более мощного передатчика и более сложного приемника, который должен различать четыре уровня.