В теоретических трудах по многопоточности вы можете встретить описание трех задач, которые по словам авторов, покрывают все возможные задачи многопоточности — задача производитель-потребитель, задача читатели-писатели, задача обедающие философы. Аллегория красивая и по своему достаточно неплохая, но на мой взгляд, для неокрепшего молодого программиста, совершенно ничего не говорящая. Посему опишу проблемы со своей колокольни. Проблем всего две.
Проблема первая — доступ к одному ресурсу из нескольких потоков. Мы уже описывали проблему с одной лопатой. Можете расширить вариант — есть один бак с водой (с одним краником), 25 жаждущих пить рудокопов и 5 кружек на всех. Придется договариваться, иначе смертоубийство может начаться. Причем надо не только сохранить кружки в целостности — надо еще организовать все так, чтобы всем удалось попить. Это частично переходит на проблему номер два.
Проблема вторая — синхронизация взаимодействия. Как-то мне предложили задачу — написать простую программу, чтобы два потока играли в пинг-понг. Один пишет «Пинг», а второй — «Понг». Но они это должны делать по очереди. А теперь представим, что надо сделать такую же задачу, но на 4 потока — играем пара на пару.
Т.е. постановка проблем весьма несложная. Раз — надо организовать упорядоченный и безопасный доступ к разделяемому ресурсу. Два — надо выполнять потоки в какой-то очередности.
Дело за реализацией. И вот тут нас подстерегает много сложностей, про которые с предыханием и говорят (и может не зря). Начнем с разделяемого ресурса.
Совместный ресурс для нескольких потоков
Предлагаю сразу продемонстрировать проблему на несложном примере. Его задача — запустить 200 потоков класса CounterThread . Каждый поток получает ссылку на один единственный объект Counter . В процессе выполнения поток вызывает у этого объекта метод increaseCounter одну тысячу раз. Метод увеличивает переменную counter на 1. Запустив 200 потоков мы ожидаем их окончания (просто засыпаем на 1 секунду — этого вполне достаточно). И в конце печатаем результат. Посмотрите код — по-моему, там все достаточно прозрачно:
<200; i++) { CounterThread ct = new CounterThread(counter); ct.start(); } Thread.sleep(1000); System.out.println("Counter:" + counter.getCounter()); } } class Counter { private long counter = 0L; public void increaseCounter() { counter++; } public long getCounter() { return counter; } } class CounterThread extends Thread { private Counter counter; public CounterThread(Counter counter) { this.counter = counter; } @Override public void run() { for(int i=0; i<1000; i++) { counter.increaseCounter(); } } }
public class CounterTester for (int i = 0 ; i < 200 ; i ++ ) { ct . start () ; Thread . sleep (1000 ) ; class Counter private long counter = 0L ; public void increaseCounter () { counter ++ ; public long getCounter () { return counter ; private Counter counter ; this . counter = counter ; @ Override public void run () { for (int i = 0 ; i < 1000 ; i ++ ) { |
По логике мы должны получить следующий результат — 200 потоков по 1000 прибавлений = 200000. Но, о ужас, это совсем не так. У меня результаты бывают разные, но явно не 200000. В чем же проблема? Проблема в том, что мы из 200 потоков одновременно пытаемся вызвать метод increaseCounter
. На первый взгляд в нем ничего страшного не происходит — мы просто прибавляем к переменной counter
единицу. Что же тут такого ужасного?
Ужасно то, что безобидный на первый взгляд код прибавления единицы, на самом деле выполняется не за один шаг. Сначала мы считываем значение переменной в регистр, потом прибавляем к нему единицу, потом записываем результат обратно в переменную. Как видите, шагов больше, чем один (по секрету — их даже больше чем три, которые я описал). И вот теперь представим, что два потока (или даже больше) одновременно считали значение переменной — например там было значение 99. Теперь оба потока прибавляют к 99 по единице, получают оба 100 и оба записывают это значение в переменную. Что там получается? Нетрудно видеть, что будет 100. А должно быть 101. Может быть даже хуже, если какой-то поток «умудрился» считать 98 и «застрял» в очереди потоков на исполнение. Мы тогда даже 100 не получим. Неувязочка 🙂
Доступ к разделяемому ресурсу — это одна из самых больших проблем многопоточности. Потому что она весьма коварна. Можно сделать все очень надежно, но тогда производительность упадет. А как только даешь «слабину» (сознательно, для производительности), обязательно возникнет ситуация, что «слабина» вылезет во всей своей красе.
Волшебное слово — synchronized
Что можно сделать для того, чтобы избавиться от ситуации, в которую мы попали с нашими замечательными потоками. Давайте для начала немного порассуждаем. Когда мы приходим в магазин, то для оплаты мы подходим к кассе. Кассир одновременно обслуживает только одного человека. Мы все выстраиваемся к ней в очередь. По сути касса становится эксклюзивным ресурсом, которым может воспользоваться одновременно только один покупатель. В многопоточности предлагается точно такой же способ — вы можете определить некоторый ресурс как экслюзивно предоставляемый одновременно только одному потоку. Такой ресурс называется «монитором». Это самый обычный объект, который поток должен «захватить». Все потоки, которые хотят получить доступ к этому монитору (объекту) выстраиваются в очередь. Причем для этого не надо писать специальный код — достаточно просто попробовать «захватить» монитор. Но как же обозначить это? Давайте разбираться.
Предлагаю запустить наш пример, но с одним дополнительным словом в описании метода increaseCounter
— это слово synchronized
.
package edu.javacourse.counter; public class CounterTester { public static void main(String args) throws InterruptedException { Counter counter = new Counter(); for(int i=0; i<200; i++) { CounterThread ct = new CounterThread(counter); ct.start(); } Thread.sleep(1000); System.out.println("Counter:" + counter.getCounter()); } } class Counter { private long counter = 0L; public synchronized void increaseCounter() { counter++; } public long getCounter() { return counter; } } class CounterThread extends Thread { private Counter counter; public CounterThread(Counter counter) { this.counter = counter; } @Override public void run() { for(int i=0; i<1000; i++) { counter.increaseCounter(); } } }
package edu . javacourse . counter ; public class CounterTester public static void main (String args ) throws InterruptedException { Counter counter = new Counter () ; for (int i = 0 ; i < 200 ; i ++ ) { CounterThread ct = new CounterThread (counter ) ; ct . start () ; Thread . sleep (1000 ) ; System . out . println ("Counter:" + counter . getCounter () ) ; class Counter private long counter = 0L ; public synchronized void increaseCounter () { counter ++ ; public long getCounter () { return counter ; class CounterThread extends Thread private Counter counter ; public CounterThread (Counter counter ) { this . counter = counter ; @ Override public void run () { for (int i = 0 ; i < 1000 ; i ++ ) { counter . increaseCounter () ; |
И … о чудо. Все заработало. Мы получаем ожидаемый результат — 200000. Что же делает это волшебное слово — synchronized
?
Слово synchronized
говорит о том, что прежде чем поток сможет вызвать этот метод у нашего объекта, он должен «захватить» наш объект и потом выполнить нужный метод. Еще раз и внимательно (иногда предлагается несколько иной подход, который на мой взгляд, крайне опасен и ошибочен — чуть позже опишу) — сначала поток «захватывает» (лочит — от слова lock — замок, блокировать) объект-монитор (в нашем случае это объект класса Counter
) и только после этого поток сможет выполнить метод increaseCounter
. Эксклюзивно, в полном одиночестве без конкурентов.
Существует иная трактовка synchronized
, которая может ввести в заблуждение — она звучит как-то так: в synchronized метод не может зайти несколько потоков одновременно. Это НЕВЕРНО. Потому как тогда получается, что если у класса несколько методов synchronized
, то одновременно можно выполнять два разных метода одного объекта, помеченные как synchronized
. Это НЕВЕРНО. Если у класса 2, 3 и более методов synchronized
, то при выполнении хотя бы одного, блокируется весь объект. Это значит, что все методы, обозначенные как synchronized
недоступны для других потоков. Если метод не обзозначен так. то не проблема — выполняйте на здоровье.
И еще раз — сначала «захватили», потом выполнили метод, потом «отпустили». Теперь объект свободен и кто первый успел из потоков его захватить — тот и прав.
В случае если метод объявлен как static
, то объектом-монитором становится класс целиком и доступ к нему блокируется на уровне всех объектов этого класса.
При обсуждении статьи мне указали на некорректность, которую я сознательно допустил (для простоты), но наверно есть смысл о ней упомянуть. Речь идет о методе getCounter
. Строго говоря, он тоже должен быть обозначен как synchronized
, потому что в момент изменения нашей переменной какой-то другой поток захочет ее прочитать. И чтобы не было проблем, доступ к этой переменной надо делать синхронизированным во всех метода.
Хотя что касается getCounter
, то здесь можно использовать еще более интересную особенность — атомарность операций. О ней можно прочитать в статье Atomic access . Основная мысль — чтение и запись некоторых элементарных типов и ссылок производится за один шаг и в принципе безопасна. Если бы поле counter
было например int
, то читать можно было бы и не в синхронном методе. Для типа long
и double
мы должны объявить переменную counter
как volatile
. Почему это может быть любопытно — надо учесть, что int
состоит из 4 байт и можно представить ситуацию, что число будет записано не за один шаг. Но это исключительно теоретически — JVM нам гарантирует, что чтение и запись элементарного типа int делает за один шаг и ни один поток не сможет вклиниться в эту операцию и что-то испортить.
Есть и другой способ использования слова synchronized — не в описании метода, а внутри кода. Давайте еще раз изменим наш пример в части метода increaseCounter .
package edu.javacourse.counter; public class CounterTester { public static void main(String args) throws InterruptedException { Counter counter = new Counter(); for(int i=0; i<200; i++) { CounterThread ct = new CounterThread(counter); ct.start(); } Thread.sleep(1000); System.out.println("Counter:" + counter.getCounter()); } } class Counter { private long counter = 0L; public void increaseCounter() { synchronized(this) { counter++; } } public long getCounter() { return counter; } } class CounterThread extends Thread { private Counter counter; public CounterThread(Counter counter) { this.counter = counter; } @Override public void run() { for(int i=0; i<1000; i++) { counter.increaseCounter(); } } }
package edu . javacourse . counter ; public class CounterTester public static void main (String args ) throws InterruptedException { Counter counter = new Counter () ; for (int i = 0 ; i < 200 ; i ++ ) { |
Написание параллельного кода – непростая задача, а проверка его корректности – задача еще сложнее. Несмотря на то, что Java предоставляет обширную поддержку многопоточности и синхронизации на уровне языка и API, на деле же оказывается, что написание корректного многопоточного Java-кода зависит от опыта и усердности конкретного программиста. Ниже изложен набор советов, которые помогут вам качественно повысить уровень вашего многопоточного кода на Java. Некоторые из вас, возможно, уже знакомы с этими советами, но никогда не помешает освежать их в памяти раз в пару лет.
Многие из этих советов появились в процессе обучения и практического программирования, а также после прочтения книг «Java concurrency in practice» и «Effective Java» . Я советую прочитать первую каждому Java-программисту два раза; да, всё правильно, ДВА раза. Параллелизм – запутанная и сложная для понимания тема (как, например, для некоторых – рекурсия), и после однократного прочтения вы можете не до конца всё понять.
Единственная цель использования параллелизма – создание масштабируемых и быстрых приложений, но при этом всегда следует помнить, что скорость не должна становиться помехой корректности. Ваша Java-програма должна удовлетворять своему инварианту независимо от того, запущена ли она в однопоточном или многотопочном виде. Если вы новичок в параллельном программировании, для начала ознакомьтесь с различными проблемами, возникающими при параллельном запуске программ (например: взаимная блокировка, состояние гонки, ресурсный голод и т.д.).
1. Используйте локальные переменные
Всегда старайтесь использовать локальные переменные вместо полей класса или статических полей. Иногда разработчики используют поля класса, чтобы сэкономить память и переиспользовать переменные, полагая, что создание локальной переменной при каждом вызове метода может потребовать большого количества дополнительной памяти. Одним из примеров такого использования может послужить коллекция (Collection), объявленная как статическое поле и переиспользуемая с помощью метода clear(). Это переводит класс в общее состояние, которого он иметь не должен, т.к. изначально создавался для параллельного использования в нескольких потоках. В коде ниже метод execute() вызывается из разных потоков, а для реализации нового функционала потребовалась временная коллекция. В оригинальном коде была использована статическая коллекция (List), и намерение разработчика были ясны - очищать коллекцию в конце метода execute() , чтобы потом можно было её заново использовать. Разработчик полагал, что его код потокобезопасен, потому что CopyOnWriteArrayList потокобезопасен. Но это не так - метод execute() вызывается из разных потоков, и один из потоков может получить доступ к данным, записанным другим потоком в общий список. Синхронизация, предоставляемая CopyOnWriteArrayList в данном случае недостаточна для обеспечения инвариантности метода execute() .
Public static class ConcurrentTask { private static List temp = Collections.synchronizedList(new ArrayList()); @Override public void execute(Message message) { // Используем локальный временный список // List temp = new ArrayList(); // Добавим в список что-нибудь из сообщения temp.add("message.getId()"); temp.add("message.getCode()"); temp.clear(); // теперь можно переиспользовать } }
Проблема: Данные одного сообщения попадут в другое, если два вызова execute() «пересекаются», т.е. первый поток добавит id из первого сообщения, затем второй поток добавит id из второго сообщения (это произойдёт ещё до очистки списка), таким образом данные одного из сообщений будут повреждены.
Варианты решений:
- Добавить блок синхронизации в ту часть кода, где поток добавляет что-то во временный список и очищает его. Таким образом, другой поток не сможет получить доступ к списку, пока первый не закончит работу с ним. В таком случае эта часть кода будет однопоточной, что уменьшит производительность приложения в целом.
- Использовать локальный список в место поля класса. Да, это увеличит затраты памяти, но избавит от блока синхронизации и сделает код более читаемым. Также вам не придётся беспокоиться о временных объектах – о них позаботится сборщик мусора.
Здесь представлен только один из случаев, но при написании параллельного кода лично я предпочитаю локальные переменные полям класса, если последних не требует архитектура приложения.
2. Предпочитайте неизменяемые классы изменяемым
Самая широко известная практика в многопоточном программировании на Java – использование неизменяемых (immutable) классов. Неизменяемые классы, такие как String, Integer и другие упрощают написание параллельного кода в Java, т.к. вам не придётся беспокоиться о состоянии объектов данных классов. Неизменяемые классы уменьшают количество элементов синхронизации в коде . Объект неизменяемого класса, будучи однажды созданным, не может быть изменён. Самый лучший пример такого класса – строка (java.lang.String). Любая операция изменения строки в Java (перевод в верхний регистр, взятие подстроки и пр.) приведёт к созданию нового объекта String для результата операции, оставив исходную строку нетронутой.
3. Сокращайте области синхронизации
Любой код внутри области синхронизации не может быть исполнен параллельно, и если в вашей программе 5% кода находится в блоках синхронизации, то, согласно закону Амдала, производительность всего приложения не может быть улучшена более, чем в 20 раз. Главная причина этого в том, что 5% кода всегда выполняется последовательно. Вы можете уменьшить это количество, сокращая области синхронизации – попробуйте использовать их только для критических секций. Лучший пример сокращения областей синхронизации – блокировка с двойной проверкой, которую можно реализовать в Java 1.5 и выше с помощью volatile переменных.
4. Используйте пул потоков
Создание потока (Thread) - дорогая операция. Если вы хотите создать масштабируемое Java-приложение, вам нужно использовать пул потоков. Помимо тяжеловесности операции создания, управление потокам вручную порождает много повторяющегося кода, который, перемешиваясь с бизнес-логикой, уменьшает читаемость кода в целом. Управление потоками – задача фреймворка, будь то инструмент Java или любой другой, который вы захотите использовать. В JDK есть хорошо организованный, богатый и полностью протестированный фреймворк, известный как Executor framework , который можно использовать везде, где потребуется пул потоков.
5. Используйте утилиты синхронизации вместо wait() и notify()
В Java 1.5 появилось множество утилит синхронизации, таких как CyclicBarrier, CountDownLatch и Semaphore. Вам всегда следует сначала изучить, что есть в JDK для синхронизации, прежде чем использовать wait() и notify() . Будет намного проще реализовать шаблон читатель-писатель с помощью BlockingQueue, чем через wait() и notify() . Также намного проще будет подождать 5 потоков для завершения вычислений, используя CountDownLatch, чем реализовывать то же самое через wait() и notify() . Изучите пакет java.util.concurrent , чтобы писать параллельный код на Java лучшим образом.
6. Используйте BlockingQueue для реализации Producer-Consumer
Этот совет следует из предыдущего, но я выделил его отдельно ввиду его важности для параллельных приложений, используемых в реальном мире. Решение многих проблем многопоточности основано на шаблоне Producer-Consumer, и BlockingQueue – лучший способ реализации его в Java. В отличие от Exchanger, который может быть использовать в случае одного писателя и читателя, BlockingQueue может быть использована для правильной обработки нескольких писателей и читателей.
7. Используйте потокобезопасные коллекции вместо коллекций с блокированием доступа
Потокобезопасные коллекции предоставляют большую масштабируемость и производительность, чем их аналоги с блокированием доступа (Collections.synchronizedCollection и пр.). СoncurrentHashMap, которая, по моему мнению, является самой популярной потокобезопасной коллекцией, демострирует лучшую производителность, чем блокировочные HashMap или Hashtable, в случае, когда количество читателей превосходит количество писателей. Другое преимущество потокобезопасных коллекций состоит в том, что они реализованы с помощью нового механизма блокировки (java.util.concurrent.locks.Lock) и используют нативные механизмы сихнронизации, предоставленные низлежащим аппаратным обеспечением и JVM. Вдобавок используйте CopyOnWriteArrayList вместо Collections.synchronizedList , если чтение из списка происходит чаще, чем его изменение.
8. Используйте семафоры для создания ограничений
Чтобы создать надёжную и стабильную систему, у вас должны быть ограничения на ресурсы (базы данных, файловую систему, сокеты и т.д.). Ваш код ни в коем случае не должен создавать и/или использовать бесконечное количество ресурсов. Семафоры (java.util.concurrent.Semaphore) - хороший выбор для создания ограничений на использование дорогих ресурсов, таких как подключения к базе данных (кстати, в этом случае можно использовать пул подключений). Семафоры помогут создать ограничения и заблокируют потоки в случае недоступности ресурса.
9. Используйте блоки синхронизации вместо блокированных методов
Данный совет расширяет совет по сокращению областей синхрониации. Использование блоков синхронизации – один из методов сокращения области синхронизации, что также позволяет выполнить блокировку на объекте, отличном от текущего, представленного указателем this . Первым кандитатом должна быть атомарная переменная, затем volatile переменная, если они удовлетворяют ваши требования к синхронизации. Если вам требуется взаимное исключение, используйте в первую очередь ReentrantLock, либо блок synchronized . Если вы новичок в параллельном программировании, и не разрабатываете какое-либо жизненно важное приложение, можете просто использовать блок synchronized - так будет безопаснее и проще.
10. Избегайте использования статических переменных
Как показано в первом совете, статические переменные, будучи использованными в параллельном коде, могут привести к возникновению множества проблем. Если вы всё-таки используете статическую переменную, убедитесь, что это константа либо неизменяемая коллекция. Если вы думаете о том, чтобы переиспользовать коллекцию с целью экономии памяти, вернитесь ещё раз к первому совету.
11. Используйте Lock вместо synchronized
Последний, бонусный совет, следует использовать с осторожностью. Интерфейс Lock - мощный инструмент, но его сила влечёт и большую ответственность. Различные объекты Lock на операции чтения и записи позволяют реализовывать масштабируемые структуры данных, такие как ConcurrentHashMap, но при этом требуют большой осторожности при своём программировании. В отличие от блока synchronized, поток не освобождает блокировку автоматически. Вам придётся явно вызывать unlock() , чтобы снять блокировку. Хорошей практикой является вызов этого метода в блоке finally, чтобы блокировка завершалась при любых условиях:
Lock.lock(); try { //do something ... } finally { lock.unlock(); }
Заключение
Вам были представлены советы по написанию многопоточного кода на Java. Ещё раз повторюсь, никогда не помешает перечитывать «Java concurrency in practice» и «Effective Java» время от времени. Также можно вырабатывать нужный для параллельного програмирования способ мышления, просто читая чужой код и пытаясь визуализировать проблемы во время разработки. В завершение спросите себя, каких правил вы придерживаетесь, когда разрабатываете многопоточные приложения на Java?
Any application can have multiple processes (instances). Each of this process can be assigned either as a single thread or multiple threads.
We will see in this tutorial how to perform multiple tasks at the same time and also learn more about threads and synchronization between threads.
In this tutorial, we will learn-
What is Single Thread?
A single thread is basically a lightweight and the smallest unit of processing. Java uses threads by using a "Thread Class".
There are two types of thread – user thread and daemon thread (daemon threads are used when we want to clean the application and are used in the background).
When an application first begins, user thread is created. Post that, we can create many user threads and daemon threads.
Single Thread Example:
Package demotest; public class GuruThread { public static void main(String args) { System.out.println("Single Thread"); } }
Advantages of single thread:
- Reduces overhead in the application as single thread execute in the system
- Also, it reduces the maintenance cost of the application.
What is Multithreading?
Multithreading in java is a process of executing two or more threads simultaneously to maximum utilization of CPU.
Multithreaded applications are where two or more threads run concurrently; hence it is also known as Concurrency in Java. This multitasking is done, when multiple processes share common resources like CPU, memory, etc.
Each thread runs parallel to each other. Threads don"t allocate separate memory area; hence it saves memory. Also, context switching between threads takes less time.
Example of Multi thread:
Package demotest; public class GuruThread1 implements Runnable { public static void main(String args) { Thread guruThread1 = new Thread("Guru1"); Thread guruThread2 = new Thread("Guru2"); guruThread1.start(); guruThread2.start(); System.out.println("Thread names are following:"); System.out.println(guruThread1.getName()); System.out.println(guruThread2.getName()); } @Override public void run() { } }
Advantages of multithread:
- The users are not blocked because threads are independent, and we can perform multiple operations at times
- As such the threads are independent, the other threads won"t get affected if one thread meets an exception.
Thread Life Cycle in Java
The Lifecycle of a thread:
There are various stages of life cycle of thread as shown in above diagram:
- Runnable
- Running
- Waiting
- New: In this phase, the thread is created using class "Thread class".It remains in this state till the program starts the thread. It is also known as born thread.
- Runnable: In this page, the instance of the thread is invoked with a start method. The thread control is given to scheduler to finish the execution. It depends on the scheduler, whether to run the thread.
- Running: When the thread starts executing, then the state is changed to "running" state. The scheduler selects one thread from the thread pool, and it starts executing in the application.
- Waiting: This is the state when a thread has to wait. As there multiple threads are running in the application, there is a need for synchronization between threads. Hence, one thread has to wait, till the other thread gets executed. Therefore, this state is referred as waiting state.
- Dead: This is the state when the thread is terminated. The thread is in running state and as soon as it completed processing it is in "dead state".
Some of the commonly used methods for threads are:
| Method | Description |
|---|---|
| start() | This method starts the execution of the thread and JVM calls the run() method on the thread. |
| Sleep(int milliseconds) | This method makes the thread sleep hence the thread"s execution will pause for milliseconds provided and after that, again the thread starts executing. This help in synchronization of the threads. |
| getName() | It returns the name of the thread. |
| setPriority(int newpriority) | It changes the priority of the thread. |
| yield () | It causes current thread on halt and other threads to execute. |
Example: In this example we are going to create a thread and explore built-in methods available for threads.
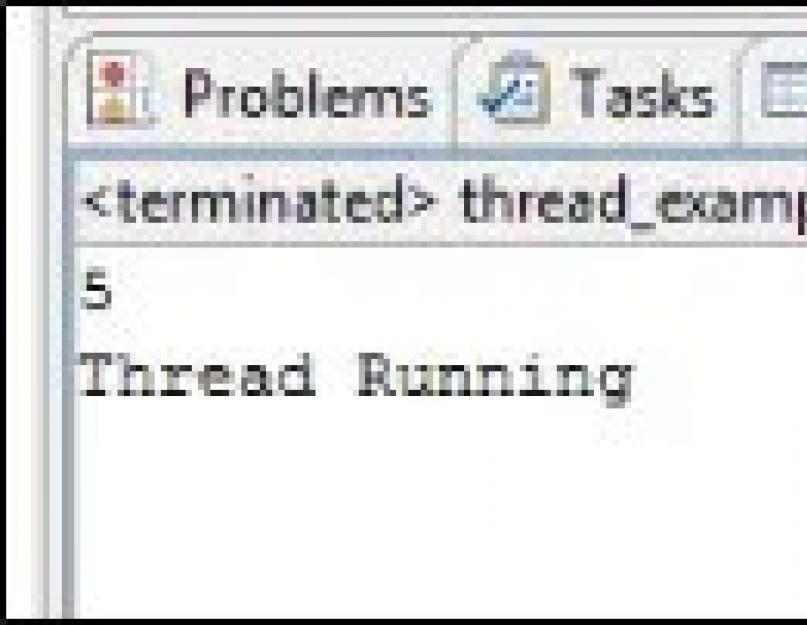
Package demotest; public class thread_example1 implements Runnable { @Override public void run() { } public static void main(String args) { Thread guruthread1 = new Thread(); guruthread1.start(); try { guruthread1.sleep(1000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } guruthread1.setPriority(1); int gurupriority = guruthread1.getPriority(); System.out.println(gurupriority); System.out.println("Thread Running"); } }
Explanation of the code:
Code Line 2: We are creating a class "thread_Example1" which is implementing the Runnable interface (it should be implemented by any class whose instances are intended to be executed by the thread.)
Code Line 4: It overrides run method of the runnable interface as it is mandatory to override that method
Code Line 6: Here we have defined the main method in which we will start the execution of the thread.
Code Line 7: Here we are creating a new thread name as "guruthread1" by instantiating a new class of thread.
Code Line 8: we will use "start" method of the thread using "guruthread1" instance. Here the thread will start executing.
Code Line 10: Here we are using the "sleep" method of the thread using "guruthread1" instance. Hence, the thread will sleep for 1000 milliseconds.
Code 9-14: Here we have put sleep method in try catch block as there is checked exception which occurs i.e. Interrupted exception.
Code Line 15: Here we are setting the priority of the thread to 1 from whichever priority it was
Code Line 16: Here we are getting the priority of the thread using getPriority()
Code Line 17: Here we are printing the value fetched from getPriority
Code Line 18: Here we are writing a text that thread is running.
5 is the Thread priority, and Thread Running is the text which is the output of our code.
Java Thread Synchronization
In multithreading, there is the asynchronous behavior of the programs. If one thread is writing some data and another thread which is reading data at the same time, might create inconsistency in the application.
When there is a need to access the shared resources by two or more threads, then synchronization approach is utilized.
Java has provided synchronized methods to implement synchronized behavior.
In this approach, once the thread reaches inside the synchronized block, then no other thread can call that method on the same object. All threads have to wait till that thread finishes the synchronized block and comes out of that.
In this way, the synchronization helps in a multithreaded application. One thread has to wait till other thread finishes its execution only then the other threads are allowed for execution.
It can be written in the following form:
Synchronized(object) { //Block of statements to be synchronized }
Java Multithreading Example
In this example, we will take two threads and fetch the names of the thread.
Example1:
GuruThread1.java package demotest; public class GuruThread1 implements Runnable{ /** * @param args */ public static void main(String args) { Thread guruThread1 = new Thread("Guru1"); Thread guruThread2 = new Thread("Guru2"); guruThread1.start(); guruThread2.start(); System.out.println("Thread names are following:"); System.out.println(guruThread1.getName()); System.out.println(guruThread2.getName()); } @Override public void run() { } }
Explanation of the code:
Code Line 3: We have taken a class "GuruThread1" which implements Runnable (it should be implemented by any class whose instances are intended to be executed by the thread.)
Code Line 8: This is the main method of the class
Code Line 9: Here we are instantiating the Thread class and creating an instance named as "guruThread1" and creating a thread.
Code Line 10: Here we are instantiating the Thread class and creating an instance named a "guruThread2" and creating a thread.
Code Line 11: We are starting the thread i.e. guruThread1.
Code Line 12: We are starting the thread i.e. guruThread2.
Code Line 13: Outputting the text as "Thread names are following:"
Code Line 14: Getting the name of thread 1 using method getName() of the thread class.
Code Line 15: Getting the name of thread 2 using method getName() of the thread class.
When you execute the above code, you get the following output:
Thread names are being outputted here as
- Guru1
- Guru2
Example 2:
In this example, we will learn about overriding methods run() and start() method of a runnable interface and create two threads of that class and run them accordingly.
Also, we are taking two classes,
- One which will implement the runnable interface and
- Another one which will have the main method and execute accordingly.
Explanation of the code:
Code Line 2: Here we are taking a class "GuruThread2" which will have the main method in it.
Code Line 4: Here we are taking a main method of the class.
Code Line 6-7: Here we are creating an instance of class GuruThread3 (which is created in below lines of the code) as "threadguru1" and we are starting the thread.
Code Line 8-9: Here we are creating another instance of class GuruThread3 (which is created in below lines of the code) as "threadguru2" and we are starting the thread.
Code Line 11: Here we are creating a class "GuruThread3" which is implementing the runnable interface (it should be implemented by any class whose instances are intended to be executed by the thread.)
Code Line 13-14: we are taking two class variables from which one is of the type thread class and other of the string class.
Code Line 15-18: we are overriding the GuruThread3 constructor, which takes one argument as string type (which is threads name) that gets assigned to class variable guruname and hence the name of the thread is stored.
Code Line 20: Here we are overriding the run() method of the runnable interface.
Code Line 21: We are outputting the thread name using println statement.
Code Line 22-31: Here we are using a for loop with counter initialized to 0, and it should not be less than 4 (we can take any number hence here loop will run 4 times) and incrementing the counter. We are printing the thread name and also making the thread sleep for 1000 milliseconds within a try-catch block as sleep method raised checked exception.
Code Line 33: Here we are overriding start method of the runnable interface.
Code Line 35: We are outputting the text "Thread started".
Code Line 36-40: Here we are taking an if condition to check whether class variable guruthread has value in it or no. If its null then we are creating an instance using thread class which takes the name as a parameter (value for which was assigned in the constructor). After which the thread is started using start() method.
When you execute the above code you get the following output:
There are two threads hence, we get two times message "Thread started".
We get the names of the thread as we have outputted them.
It goes into for loop where we are printing the counter and thread name and counter starts with 0.
The loop executes three times and in between the thread is slept for 1000 milliseconds.
Hence, first, we get guru1 then guru2 then again guru2 because the thread sleeps here for 1000 milliseconds and then next guru1 and again guru1, thread sleeps for 1000 milliseconds, so we get guru2 and then guru1.
Summary :
In this tutorial, we saw multithreaded applications in Java and how to use single and multi threads.
- In multithreading, users are not blocked as threads are independent and can perform multiple operations at time
- Various stages of life cycle of the thread are,
- Runnable
- Running
- Waiting
- We also learned about synchronization between threads, which help the application to run smoothly.
- Multithreading makes many more application tasks easier.
Как пользоваться классом Thread?
Есть две возможности.
- Во-первых, вы можете создать свой дочерний класс на базе класса Thread. При этом вы должны переопределить метод run. Ваша реализация этого метода будет работать в рамках отдельного потока.
- Во-вторых, ваш класс может реализовать интерфейс Runnable. При этом в рамках вашего класса необходимо определить метод run, который будет работать как отдельный поток.
Второй способ особенно удобен в тех случаях, когда ваш класс должен быть унаследован от какого-либо другого класса (например, от класса Applet) и при этом вам нужна многопоточность. Так как в языке программирования Java нет множественного наследования, невозможно создать класс, для которого в качестве родительского будут выступать классы Applet и Thread. В этом случае реализация интерфейса Runnable является единственным способом решения задачи.
Методы класса Thread
В классе Thread определены три поля, несколько конструкторов и большое количество методов, предназначенных для работы с потоками. Ниже мы привели краткое описание полей, конструкторов и методов.
С помощью конструкторов вы можете создавать потоки различными способами, указывая при необходимости для них имя и группу. Имя предназначено для идентификации потока и является необязательным атрибутом. Что же касается групп, то они предназначены для организации защиты потоков друг от друга в рамках одного приложения.
Методы класса Thread предоставляют все необходимые возможности для управления потоками, в том числе для их синхронизации.
Поля
Три статических поля предназначены для назначения приоритетов потокам.
- NORM_PRIORITY
Нормальный
public final static int NORM_PRIORITY;- MAX_PRIORITY
Максимальный
public final static int MAX_PRIORITY;- MIN_PRIORITY
Минимальный
public final static int MIN_PRIORITY;Конструкторы
Создание нового объекта Thread
public Thread();Создвание нового объекта Thread с указанием объекта, для которого будет вызываться метод run
public Thread(Runnable target); public Thread(Runnable target, String name);Создание объекта Thread с указанием его имени
public Thread(String name);Создание нового объекта Thread с указанием группы потока и объекта, для которого вызывается метод run
public Thread(ThreadGroup group, Runnable target);Аналогично предыдущему, но дополнительно задается имя нового объекта Thread
public Thread(ThreadGroup group, Runnable target, String name);Создание нового объекта Thread с указанием группы потока и имени объекта
public Thread(ThreadGroup group, String name);Методы
- activeCount
Текущее количество активных потоков в группе, к которой принадлежит поток
public static int activeCount();- checkAccess
Текущему потоку разрешается изменять объект Thread
public void checkAccesss();- countStackFrames
Определение количества фреймов в стеке
public int countStackFrames();- currentThread
Определение текущего работающего потока
public static Thread currentThread();- destroy
Принудительное завершение работы потока
public void destroy();- dumpStack
Вывод текущего содержимого стека для отладки
public static void dumpStack();- enumerate
Получение всех объектов Tread данной группы
public static int enumerate(Thread tarray);- getName
Определение имени потока
public final String getName();- getPriority
Определение текущего приоритета потока
public final int getPriority();- getThreadGroup
Определение группы, к которой принадлежит поток
public final ThreadGroup getThreadGroup();- interrupt
Прерывание потока
public void interrupt();- interrupted
- isAlive
Определение, выполняется поток или нет
public final boolean isAlive();- isDaemon
Определение, является ли поток демоном
public final boolean isDaemon();- isInterrupted
Определение, является ли поток прерванным
public boolean isInterrupted();- join
Ожидание завершения потока
public final void join();Ожидание завершения потока в течение заданного времени. Время задается в миллисекундах
public final void join(long millis);Ожидание завершения потока в течение заданного времени. Время задается в миллисекундах и наносекундах
public final void join(long millis, int nanos);- resume
Запуск временно приостановленного потока
public final void resume();Метод вызывается в том случае, если поток был создан как объект с интерфейсом Runnable
public void run();- setDaemon
Установка для потока режима демона
public final void setDaemon(boolean on);- setName
Устаовка имени потока
public final void setName(String name);- setPriority
Установка приоритета потока
public final void setPriority(int newPriority);- sleep
Задержка потока на заднное время. Время задается в миллисекундах и наносекундах
public static void sleep(long millis, int nanos);- start
Запуск потока на выполнение
public void start();- stop
Остановка выполнения потока
public final void stop();Аварийная остановка выполнения потока с заданным исключением
public final void stop(Throwable obj);- suspend
Приостановка потока
public final void suspend();- toString
Строка, представляющая объект-поток
public String toString();- yield
Приостановка текущего потока для того чтобы управление было передано другому потоку
public static void yield();Создание дочернего класса на базе класса Thread
Рассмотрим первый способ реализации многопоточности, основанный на наследовании от класса Thread. При использовании этого способа вы определяете для потока отдельный класс, например, так:
class DrawRectangles extends Thread { . . . public void run() { . . . } }Здесь определен класс DrawRectangles, который является дочерним по отношению к классу Thread.
Обратите внимание на метод run. Создавая свой класс на базе класса Thread, вы должны всегда определять этот метод, который и будет выполняться в рамках отдельного потока.
Заметим, что метод run не вызывается напрямую никакими другими методами. Он получает управление при запуске потока методом start.
Как это происходит?
Рассмотрим процедуру запуска потока на примере некоторого класса DrawRectangles.
Вначале ваше приложение должно создать объект класса Thread:
public class MultiTask2 extends Applet { Thread m_DrawRectThread = null; . . . public void start() { if (m_DrawRectThread == null) { m_DrawRectThread = new DrawRectangles(this); m_DrawRectThread.start(); } } }Создание объекта выполняется оператором new в методе start, который получает управление, когда пользователь открывает документ HTML с аплетом. Сразу после создания поток запускается на выполнение, для чего вызывается метод start.
Что касается метода run, то если поток используется для выполнения какой либо периодической работы, то этот метод содержит внутри себя бесконечный цикл. Когда цикл завершается и метод run возвращает управление, поток прекращает свою работу нормальным, не аварийным образом. Для аварийного завершения потока можно использовать метод interrupt.
Остановка работающего потока выполняется методом stop. Обычно остановка всех работающих потоков, созданных аплетом, выполняется методом stop класса аплета:
public void stop() { if (m_DrawRectThread != null) { m_DrawRectThread.stop(); m_DrawRectThread = null; } }Напомним, что этот метод вызывается, когда пользователь покидает страницу сервера Web, содержащую аплет.
Реализация интерфейса Runnable
Описанный выше способ создания потоков как объектов класса Thread или унаследованных от него классов кажется достаточнао естественным. Однако этот способ не единственный. Если вам нужно создать только один поток, работающую одновременно с кодом аплета, проще выбрать второй способ с использованием интерфейса Runnable.
Идея заключается в том, что основной класс аплета, который является дочерним по отношению к классу Applet, дополнительно реализует интерфейс Runnable, как это показано ниже:
public class MultiTask extends Applet implements Runnable { Thread m_MultiTask = null; . . . public void run() { . . . } public void start() { if (m_MultiTask == null) { m_MultiTask = new Thread(this); m_MultiTask.start(); } } public void stop() { if (m_MultiTask != null) { m_MultiTask.stop(); m_MultiTask = null; } } }Внутри класса необходимо определить метод run, который будет выполняться в рамках отдельного потока. При этом можно считать, что код аплета и код метода run работают одновременно как разные потоки.
Для создания потока используется оператор new. Поток создается как объект класса Thread, причем конструктору передается ссылка на класс аплета:
m_MultiTask = new Thread(this);При этом, когда поток запустится, управление получит метод run, определенный в классе аплета.
Как запустить поток?
Запуск выполняется, как и раньше, методом start. Обычно поток запускается из метода start аплета, когда пользователь отображает страницу сервера Web, содержащую аплет. Остановка потока выполняется методом stop.
В этом руководстве мы рассмотрим, как выполняется многопоточность Java , более подробно узнаем о потоках и синхронизации между ними.
Пример одного потока :
package demotest; public class GuruThread1 implements Runnable { /** * @param args */ public static void main(String args) { Thread guruThread1 = new Thread("Guru1"); Thread guruThread2 = new Thread("Guru2"); guruThread1.start(); guruThread2.start(); System.out.println("Thread names are following:"); System.out.println(guruThread1.getName()); System.out.println(guruThread2.getName()); } @Override public void run() { } }
Преимущества одного потока :
- При выполнении одного потока снижается нагрузка на приложение;
- Уменьшается стоимость обслуживания приложения.
Что такое многопоточность?
Многопоточность в Java - это выполнение двух или более потоков одновременно для максимального использования центрального процесса.
Многопоточные приложения - это приложения, где параллельно выполняются два или более потоков. Данное понятие известно в Java как многопотоковое выполнение. При этом несколько процессов используют общие ресурсы, такие как центральный процессор, память и т. д.
Все потоки выполняются параллельно друг другу. Для каждого отдельного потока не выделяется память, что приводит к ее экономии. Кроме этого переключение между потоками занимает меньше времени.
Пример многопоточности :
package demotest; public class GuruMultithread implements Runnable{ /** * @param args */ public static void main(String args) { Thread guruthread1 = new Thread(); guruThread1.start(); Thread guruthread2 = new Thread(); guruThread2.start(); } @Override public void run() { // TODO Автоматически сгенерированный метод stub } }
Преимущества многопоточности :
- В задачах на многопоточность Java потоки выполняются независимо друг от друга, поэтому отсутствует блокирование пользователей, и можно выполнять несколько операций одновременно;
- Одни потоки не влияют на другие, когда они наталкиваются на исключения.
Жизненный цикл потока в Java
Жизненный цикл потока :
Стадии жизни потока :
- Новый;
- Готовый к выполнению;
- Выполняемый;
- Ожидающий;
- Остановленный.
- Новый : в этой фазе поток создается с помощью класса Thread . Он остается в этом состоянии, пока программа его не запустит;
- Готовый к выполнению : экземпляр потока вызывается с помощью метода Start . Управление потоком предоставляется планировщику для завершения выполнения. От планировщика зависит то, следует ли запускать поток;
- Выполняемый : с началом выполнения потока его состояние изменяется на «выполняемый ». Планировщик выбирает один поток из пула потоков и начинает его выполнение в приложении;
- Ожидающий : поток ожидает своего выполнения. Поскольку в приложении выполняется сразу несколько потоков, необходимо синхронизировать их. Следовательно, один поток должен ожидать, пока другой поток не будет выполнен. Таким образом, это состояние называется состоянием ожидания;
- Остановленный : выполняемый поток после завершения процесса переходит в состояние «остановленный », известное также как «мертвый ».
Часто используемые методы для управления многопоточностью Java :
Например : В этом примере создается поток, и применяются перечисленные выше методы.
package demotest; public class thread_example1 implements Runnable { @Override public void run() { } public static void main(String args) { Thread guruthread1 = new Thread(); guruThread1.start(); try { guruthread1.sleep(1000); } catch (InterruptedException e) { // TODO Автоматически сгенерированный блок catch e.printStackTrace(); } guruthread1.setPriority(1); int gurupriority = guruthread1.getPriority(); System.out.println(gurupriority); System.out.println("Thread Running"); } }
Объяснение кода
Строка кода 2
: создаем класс «thread_Example1
Runnable
» (готовый к выполнению
). Он должен быть реализован любым классом, экземпляры которого предназначены для выполнения потоком.
Строка 4
: переопределяется метод run
для готового к запуску интерфейса, так как он является обязательным при переопределении этого метода.
Строка кода 6
: определяется основной метод, в котором начнется выполнение потока.
Строка кода 7
: создается новое имя потока «guruthread1
«, инициализируя новый класс потока.
Код строка 8
: используется метод «Start
» в экземпляре «guruthread1
«. Здесь поток начнет выполняться.
Строка 10
: используется метод «sleep
» в экземпляре «guruthread1
«. Поток приостановит свое выполнение на 1000 миллисекунд.
Строки 9-14
: применяется метод «sleep
» в блоке «try catch
», так как есть проверяемое исключение «Interrupted exception
».
Строка кода 15
: для потока назначается приоритет «1
», независимо от того, каким приоритет был до этого.
Строка кода 16
: получаем приоритет потока с помощью getPriority()
.
Строка кода 17
: значение, извлеченное из getPriority
.
Строка кода 18
: пишем текст, что поток выполняется.

Вывод
5 - это приоритет потока, а «Thread Running » - текст, который является выводом нашего кода.
Синхронизация потоков Java
В многопоточности Java присутствует асинхронное поведение. Если один поток записывает некоторые данные, а другой в это время их считывает, в приложении может возникнуть ошибка. Поэтому при необходимости доступа к общим ресурсам двум и более потоками используется синхронизация.
В Java есть свои методы для обеспечения синхронизации. Как только поток достигает синхронизированного блока, другой поток не может вызвать этот метод для того же объекта. Все другие потоки должны ожидать, пока текущий не выйдет из синхронизированного блока.
Таким образом, решается проблема в многопоточных приложениях. Один поток ожидает, пока другой не закончит свое выполнение, и только тогда другим потокам будет разрешено их выполнение.
Это можно написать следующим образом:
Synchronized(object) { //Блок команд для синхронизации }
Пример многопоточности Java
В этом Java многопоточности примере мы задействуем два потока и извлекаем имена потоков.
Пример 1
GuruThread1.java package demotest; public class GuruThread1 implements Runnable{ /** * @param args */ public static void main(String args) { Thread guruThread1 = new Thread("Guru1"); Thread guruThread2 = new Thread("Guru2"); guruThread1.start(); guruThread2.start(); System.out.println("Thread names are following:"); System.out.println(guruThread1.getName()); System.out.println(guruThread2.getName()); } @Override public void run() { } }
Объяснение кода
Строка кода 3
: задействуем класс «GuruThread1
«, который реализует интерфейс «Runnable
» (он должен быть реализован любым классом, экземпляры которого предназначены для выполнения потоком
).
Строка 8
: основной метод класса.
Строка 9
: создаем класс Thread
, экземпляр с именем «guruThread1
» и поток.
Строка 10
: создаем класс Thread
, экземпляр с именем «guruThread2
» и поток.
Строка 11
: запускаем поток guruThread1
.
Строка 12
: запускаем поток guruThread2
.
Строка 13
: выводим текст «Thread names are following:
«.
Строка 14
: получаем имя потока 1, используя метод getName()
класса thread
.
Строка кода 15
: получаем имя потока 2, используя метод getName()
класса thread
.
Вывод
Имена потоков выводятся как:
- Guru1
- Guru2
Пример 2
Из этого Java многопоточности урока мы узнаем о переопределяющих методах Run () и методе Start () интерфейса runnable . Создадим два потока этого класса и выполним их.
Также мы задействуем два класса:
- Один будет реализовывать интерфейс runnable ;
- Другой — с методом main и будет выполняться.
package demotest; public class GuruThread2 { public static void main(String args) { // TODO Автоматически сгенерированный метод stub GuruThread3 threadguru1 = new GuruThread3("guru1"); threadguru1.start(); GuruThread3 threadguru2 = new GuruThread3("guru2"); threadguru2.start(); } } class GuruThread3 implements Runnable { Thread guruthread; private String guruname; GuruThread3(String name) { guruname = name; } @Override public void run() { System.out.println("Thread running" + guruname); for (int i = 0; i < 4; i++) { System.out.println(i); System.out.println(guruname); try { Thread.sleep(1000); } catch (InterruptedException e) { System.out.println("Thread has been interrupted"); } } } public void start() { System.out.println("Thread started"); if (guruthread == null) { guruthread = new Thread(this, guruname); guruthread.start(); } } }
Объяснение кода
Строка кода 2
: принимаем класс «GuruThread2
«, содержащий метод main
.
Строка 4
: принимаем основной метод класса.
Строки 6-7
: создаем экземпляр класса GuruThread3
(создается в строках внизу
) как «threadguru1
» и запускаем поток.
Строки 8-9
: создаем еще один экземпляр класса GuruThread3
(создается в строках внизу
) как «threadguru2
» и запускаем поток.
Строка 11
: для многопоточности Java
создаем класс «GuruThread3
«, который реализует интерфейс «Runnable
». Он должен быть реализован любым классом, экземпляры которого предназначены для выполнения потоком.
Строки 13-14
: принимаем две переменные класса, из которых одна - потоковый класс, другая - строковый класс.
Строки 15-18
: переопределение конструктора GuruThread3
, который принимает один аргумент как тип String
(являющийся именем потока
). Имя будет присвоено переменной класса guruname
и сохраняется имя потока.
Строка 20
: переопределяется метод run()
интерфейса runnable
.
Строка 21
: выводится имя потока с использованием набора команд println
.
Строки 22-31
: используется цикл «for
» со счетчиком, инициализированным на «0
», который не должен быть меньше 4
. Выводится имя потока, а также выполняется приостановка потока на 1000 миллисекунд в блоке try-catch
, поскольку метод sleep
вызвал проверяемое исключение.
Строка 33
: переопределяется метод start
интерфейса runnable
.
Строка 35
: выводится текст «Thread started
«.
Строки 36-40
: проверяем, содержит ли переменная класса guruthread
значение. Если оно равно NULL
, создается экземпляр класса thread
. После этого запускается поток с использованием класса start()
.