Обектом внешней сортировки является файл. Размеры файла принципиально не ограничены, то есть он может не помещаться в оперативной памяти. Для этого вида сортировки дополнительные расходы внешней памяти жестко не нормируются, поэтому активно используются вспомогательные файлы. Доступ к файлам строго последовательный. Это требование обусловлено двумя обстоятельствами. Во-первых, методы внешней сортировки должны быть работоспособными при хранении файлов на устройствах последовательного доступа типа магнитных лент. Во-вторых, при использовании прямого доступа основные затраты времени связаны с позиционированием файлов, что желательно исключить.
В основе методов внешней сортировки лежит процедура слияния, заключающаяся в объединении двух или более отсортированных последовательностей. Рассмотрим эту процедуру на примере слияния двух последовательностей A и B в последовательность C. Пусть элементы A и B отсортированы по возрастанию, то есть a 1 £ a 2 £ …£ a m и b 1 £ b 2 £ …£ b n . Требуется, чтобы последовательность C также располагалась по возрастанию, то есть выполнялось c 1 £ c 2 £ …£ c m + n .
Сначала в качестве текущих выбираются первые элементы последовательностей. Меньший из них записывается в C, и вместо него текущим становится следующий элемент этой же последовательности. Эта операция повторяется до исчерпания одной из последовательностей, после чего в C дописывается остаток другой последовательности.
Можно заметить, что доступ к элементам A, B и C выполнялся строго последовательно. В методах внешней сортировки в качестве последовательностей A, B и C фигурируют отсортированные участки файлов.
Базовым методом внешней сортировки является метод простого слияния. Рассмотрим его на следующем примере. Пусть имеется файл A, включающий элементы 27, 16, 13, 11, 18, 25, 7. Этот файл разделяется на два файла B и C путем поочередной записи элементов в эти файлы. Покажем это схемой
B: 27, 13, 18, 7
A: 27, 16, 13, 11, 18, 25, 7
Затем файлы B и C снова соединяются путем поочередного включения в C элементов из A и B. При этом первым располагается меньший элемент каждой пары. Получится следующий результат
B: 27, 13, 18, 7
Пары отделяются друг от друга апострофами. На следующем этапе снова происходит разделение файла A на B и C, но в каждый файл пишутся поочередно уже не отдельные элементы, а выделенные пары. Получаем
B: 16, 27,’ 18, 25
A: 16, 27,’ 11, 13,’ 18, 25, ‘ 7
B: 16, 27,’ 18, 25
A: 11, 13, 16, 27,’ 7, 18, 25
Затем файл A распределяется по четверкам элементов и при новом соединении будет состоять из упорядоченных восьмерок элементов. В нашем примере сортировка закончится на этом этапе. В общем случае длина отсортированных серий будет увеличиваться по степеням 2, пока величина серии не превзойдет количество элементов в файле.
На этом примере определим основные термины внешней сортировки. В методе участвовали 3 файла, поэтому он называется трехленточным. Для выполнения сортировки потребовалось 3 прохода. Отдельный проход состоял из процедур разделения и слияния, каждая из которых обрабатывала все элементы. Такие процедуры называют фазами. Следовательно, метод простого слияния является двухфазным и трехленточным.
Есть очевидное усовершенствование метода. Результат слияния сразу распределяется на две ленты, то есть в процессе участвуют уже 4 ленты. За счет дополнительной памяти число операций перезаписи уменьшается вдвое. Это однофазный четырехленточный метод, называемый также сбалансированным слиянием.
Как видно из приведенных выше данных, метод может конкурировать по скорости с самыми быстрыми методами внутренней сортировки, но не применяется в таком качестве, так как требует значительных затрат памяти. Число проходов оценивается величиной log 2 n, а общее число пересылок M пропорцинально n log 2 n.
Метод простого слияния не дает какого-либо выигрыша в тех случаях, когда файл A полностью либо частично отсортирован. Этот недостаток отсутствует в методе естественного слияния.
Назовем серией последовательность элементов a i , a i +1 , …, a j , удовлетворяющих соотношениям a i -1 > a i £ a i +1 £ …£ a j > a j +1 . В частных случаях серия может находиться в начале или конце последовательности.
Исходный файл A разбивается на серии. Распределение на B и C ведется по сериям. При соединении сливаются пары серий. Снова возможен как трехленточный, так и четырехленточный вариант метода. Ниже показан пример сортировки методом естественного слияния c 4 лентами.
B: 17, 25, 41, ‘6
A: 17, 25, 41, ‘ 9, 11, ‘ 6, ‘ 3, 5, 8, 44
C: 9, 11, ‘ 3, 5, 8, 44
A: 9, 11, 17, 25, 41 B: 3, 5, 6, 8, 9, 11, 17, 25, 41, 44
D: 3, 5, 6, 8, 44 C:
При последнем разделении лента C оказывается пустой, и отсортированный файл остается на ленте B.
Метод естественного слияния в целом быстрее, но требует большего числа сравнений, так как требуется определять конец каждой серии. Ниже приведена программа сортировки файла двухфазным трехленточным методом естественного слияния.
Program SortSlian;
{ 3-ленточная, 2-фазная сортировка естественным слиянием }
{ ключи целые и положительные }
Type elem=record
{ другие поля }
tape=file of elem;
Name: string; { имя исходного файла }
Procedure Vvod(var F: tape);
While K <> -1 do
Write("Введите очередной ключ (конец -1): ");
if K<>-1 then Write(F, S)
Procedure Pech(var F: tape);
While not eof(F) do
Write(S. Key," ")
Procedure CopyElem(var X, Y: tape;
var Buf: elem; var E: boolean);
{ копирование элемента и считывание следующего
{ в Buf с проверкой конца серии (E=True) }
if not Eof(X) then Read(X, Buf)
else Buf.Key:=-1; { барьер: достигнут конец файла }
E:=(Buf.Key Procedure CopySer(var X, Y: tape; var Buf: elem); { копирование серии из X в Y } {в начале Buf-первый элемент текущей серии на X } {в конце Buf-первый элемент следующей или –1 (конец X) } if Buf.Key>0 then { файл X не считан } CopyElem(X, Y, Buf, E) Until E { E=True в конце серии } Procedure Raspred; { распределение A ---> B и C } Read(A, S); { первый элемент из A } Rewrite(B); Rewrite(C); CopySer(A, B, S); {S-первый элемент следующей серии } if S.Key>0 then { файл A скопирован не весь } CopySer(A, C, S) Until S.Key<0 Procedure Slian; { слияние B и C--->A } E1, E2: boolean; Procedure SlianSer; { слияние серий из B и C ---> A } { S и T - первые элементы серий } { S.Key<0-весь файл B считан, T.Key<0-файл C считан } E1:=False; E2:=False; if (S.Key>0) and ((S.Key { файл B не считан и текущий элемент B меньше, чем в C либо файл C полностью считан } CopyElem(B, A, S, E1); if E1 then { достигнут конец серии на B } CopySer(C, A, T) CopyElem(C, A, T, E2); if E2 then { достигнут конец серии на C } CopySer(B, A, S) Begin { начало Slian } if not (Eof(B) or Eof(C)) then begin { оба файла не пусты } L:=0; { счетчик числа серий } While (S.Key>0) or (T.Key>0) do Begin { начало основной программы } Write("Введите имя файла для записи элементов: "); Assign(A, Name); Assign(B, "Rab1"); Assign(C, "Rab2"); L:=0; { L - число серий после слияния - параметр } WriteLn("Файл A: "); Pech(A); Raspred; { фаза распределения } WriteLn("Файл B: "); Pech(B); WriteLn("Файл C: "); Pech(C); ReadLn; { пауза } Slian { фаза слияния } Until L<=1; { L=0, если исходный файл отсортирован } WriteLn("Файл A в конце: "); Close(B); Erase(B); { удаление рабочих файлов } Close(C); Erase(C); Стоит обратить внимание на процедуру копирования элемента с ленты на ленту CopyElem. Реально в файл записывается элемент из оперативной памяти, оставшийся от предыдущего копирования, а в память читается следующий элемент данного файла. Это связано с необходимостью постоянной проверки конца серии. Приходится особо учитывать случай, когда конец серии совпадает с концом файла. При слиянии считается количество получившихся серий. Сортировка заканчивается, когда остается единственная серия. Эффективность сортировки можно повысить, используя многопутевое слияние, в котором распределение выполняется на k лент. Поскольку число серий на каждом проходе уменьшается в k раз, количество пересылок M пропорционально величине n log k n. Если общее число лент четное, то можно использовать однофазный метод слияния, распределяя серии с одной половины лент на другую. Платой за повышение эффективности многопутевого слияния являются, как всегда, увеличение сложности реализации и дополнительные затраты внешней памяти. На сколько может отличаться количество серий после разделения? На первый взгляд кажется, что не более, чем на одну, но это не так. Например, при распределении серий 17, 25, 41, ’ 9, 60, ‘ 50, 52, ‘ 7 первая и третья серии сливаются в общую серию, что не происходит со второй и четвертой сериями. В результате при последующем слиянии серии на одной из лент могут закончиться раньше, и придется впустую переписывать остаток другой ленты, теряя эффективность. Подобные ситуации учитываются в методе многофазной сортировки. Рассмотрим его на примере трех лент. Пусть при соединении лент B и C на ленту A серии на B заканчиваются раньше. Тогда лента B объявляется выходной, а лента A становится входной. Процесс продолжается до нового повторения ситуации, когда серии на одной из входных лент заканчиваются. Многофазная сортировка возможна и при многопутевом слиянии. Например, при использовании в сортировке k лент можно постоянно иметь одну выходную ленту. При исчерпании серий на одной из k-1 входных лент эта лента становится выходной вместо предыдущей выходной ленты. Методы внутренней и внешней сортировок могут использоваться совместно. Пусть сортируется большой по объему файл. В оперативной памяти выделяется буфер максимально возможного размера. Файл делится на блоки, соответствующие величине буфера. Блоки читаются в буфер, сортируются одним из методов внутренней сортировки и переписываются в другой файл. Сейчас каждый блок нового файла является серией достаточно большой длины, определяемой размером буфера. Остается применить один из методов внешней сортировки, использующий данные серии. Существует три общих метода сортировки массивов:
Чтобы понять, как работают эти методы, представьте себе колоду игральных карт. Чтобы отсортировать карты методом обмена
, разложите их на столе лицом вверх и меняйте местами карты, расположенные не по порядку, пока вся колода не будет упорядочена. В методе выбора
разложите карты на столе, выберите карту наименьшей значимости и положите ее в руку. Затем из оставшихся карт снова выберите карту наименьшей значимости и положите ее на ту, которая уже находится у вас в руке. Процесс повторяется до тех пор, пока в руке не окажутся все карты; по окончании процесса колода будет отсортирована. Чтобы отсортировать колоду методом вставки
, возьмите все карты в руку. Выкладывайте их по одной на стол, вставляя каждую следующую карту в соответствующую позицию. Когда все карты окажутся на столе, колода будет отсортирована. Сортировка вставками
Сортировка вставками
- простой алгоритм сортировки. Хотя этот алгоритм уступает в эффективности более сложным (таким как быстрая сортировка), у него есть ряд преимуществ: · эффективен на небольших наборах данных, на наборах данных до десятков элементов может оказаться лучшим; · эффективен на наборах данных, которые уже частично отсортированы; · это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы); · может сортировать список по мере его получения; Минусом -высокая сложность алгоритма: O(n
²) Вообще говоря, в худших случаях сортировка вставками настолько же плоха, как и пузырьковая сортировка и сортировка посредством выбора, а в среднем она лишь немного лучше. Описание
На каждом шаге алгоритма мы выбираем один из элементов входных данных и вставляем его на нужную позицию в уже отсортированном списке, до тех пор, пока набор входных данных не будет исчерпан. Метод выбора очередного элемента из исходного массива произволен; может использоваться практически любой алгоритм выбора. Обычно (и с целью получения устойчивого алгоритма сортировки), элементы вставляются по порядку их появления во входном массиве. Анализ Алгоритма
Время выполнения алгоритма зависит от входных данных: чем большее множество нужно отсортировать, тем большее время выполняется сортировка. Также на время выполнения влияет исходная упорядоченность массива. Так, лучшим случаем является отсортированный массив, а худшим - массив, отсортированный в порядке, обратном нужному. Временная сложность алгоритма при худшем варианте входных данных - θ(n²). Реализация на java
public void
addingSort() { for
(Node cur = first.next; cur != null
; cur = cur.next) { Node n = cur.prev; Object val = cur.value; for
(; n != null
; n = n.prev) { if
(((Comparable) n.value).compareTo(val)
> 0) { n.next.value = n.value; } else
{ if
(n != null
) { n.next.value = val; } else
{ first.value = val; Сначала он сортирует два первых элемента. Затем алгоритм вставляет третий элемент в соответствующую порядку позицию по отношению к первым двум элементам. После этого он вставляет четвертый элемент в список из трех элементов. Этот процесс повторяется до тех пор, пока не будут вставлены все элементы. Например
, при сортировке массива dcab
каждый проход алгоритма будет выглядеть следующим образом: Начало d c a b
Проход 1 c d a b
Проход 2 a c d b
Проход 3 a b c d
Сортировка выбором
Описание
При сортировке из массива выбирается элемент с наименьшим значением и обменивается с первым элементом. Затем из оставшихся n
- 1 элементов снова выбирается элемент с наименьшим ключом и обменивается со вторым элементом, и т.д. Эти обмены продолжаются до двух последних элементов. Например
, если применить метод выбора к массиву dcab
, каждый проход будет выглядеть так: Анализ
К сожалению, как и в пузырьковой сортировке, внешний цикл выполняется n
- 1 раз, а внутренний - в среднем n
/2 раз. Следовательно, сортировка посредством выбора требует 1/2(n
2 -n
)
сравнений. Таким образом, это алгоритм порядка n
2 , из-за чего он считается слишком медленным для сортировки большого количества элементов. Несмотря на то, что количество сравнений в пузырьковой сортировке и сортировке посредством выбора одинаковое, в последней количество обменов в среднем случае намного меньше, чем в пузырьковой сортировке. Реализация на java
public void
SelectSort() { for
(Node a = first; a != last; a = a.next) { Node min = last; for
(Node b = a; b != last; b = b.next) { if
(((Comparable) b.val).compareTo(min.val)
< 0) { a.val = min.val; Сортировка Обменом
Самый известный алгоритм - пузырьковая сортировка
. Его популярность объясняется интересным названием и простотой самого алгоритма. Тем не менее, в общем случае это один из самых худших алгоритмов сортировки. Пузырьковая сортировка относится к классу обменных сортировок, т.е. к классу сортировок методом обмена. Ее алгоритм содержит повторяющиеся сравнения (т.е. многократные сравнения одних и тех же элементов) и, при необходимости, обмен соседних элементов. Элементы ведут себя подобно пузырькам воздуха в воде - каждый из них поднимается на свой уровень. Чтобы наглядно показать, как работает пузырьковая сортировка, допустим, что исходный массив содержит элементы dcab
. Ниже показано состояние массива после каждого прохода: Начало d c a b
Проход 1 a d c b
Проход 2 a b d c
Проход 3 a b c d
При анализе любого алгоритма сортировки полезно знать, сколько операций сравнения и обмена будет выполнено в лучшем, среднем и худшем случаях. Поскольку характеристики выполняемого кода зависят от таких факторов, как оптимизация, производимая компилятором, различия между процессорами и особенности реализации, мы не будем пытаться получить точные значения этих параметров. Вместо этого сконцентрируем свое внимание на общей эффективности каждого алгоритма. В пузырьковой сортировке количество сравнений всегда одно и то же, поскольку два цикла for повторяются указанное количество раз независимо от того, был список изначально упорядочен или нет. Это значит, что алгоритм пузырьковой сортировки всегда выполняет (n
2 -n
)/2 сравнений, где n
- количество сортируемых элементов. Данная формула выведена на том основании, что внешний цикл выполняется n
- 1 раз, а внутренний выполняется в среднем n
/2 раз. Произведение этих величин и дает предыдущее выражение. Обратите внимание на член n
2 в формуле. Говорят, что пузырьковая сортировка является алгоритмом порядка n
2 , поскольку время ее выполнения пропорционально квадрату количества сортируемых элементов. Необходимо признать, что алгоритм порядка n
2 не эффективен при большом количестве элементов, поскольку время выполнения растет экспоненциально в зависимости от количества сортируемых элементов. В алгоритме пузырьковой сортировки количество обменов в лучшем случае равно нулю, если массив уже отсортирован. Однако в среднем и худшем случаях количество обменов также является величиной порядка n
2 . Похожая информация. Если вы программируете и ваш код уходит дальше написания калькулятора, ты вы не раз столкнётесь или сталкивались с необходимостью отсортировать тот или иной массив данных. Существует множество способов сортировки. В этой статье мы разберём основные из них и сделаем акцент на быстрой сортировке. Быстрая сортировка - Quick Sort или qsort. По названию становится понятно, что это и для чего. Но если не понятно, то это алгоритм по быстрой сортировке массива, алгоритм имеет эффективность O(n log n) в среднем. Что это значит? Это значит, что среднее время работы алгоритма повышается по той же траектории, что и график данной функции. В некоторых популярных языках имеются встроенные библиотеки с этим алгоритмом, а это уже говорит о том, что он крайне эффективен. Это такие языки, как Java, C++, C#. Метод быстрой сортировки использует рекурсию и стратегию "Разделяй и властвуй". 1. В массиве ищется некий опорный элемент, для простоты лучше взять центральный, но если вы хотите поработать над оптимизацией, то придётся попробовать разные варианты. 2. Слева от опоры ищется элемент больший, чем опорный, справа - меньший, чем опорный, затем меняем их местами. Делаем это, пока максимальный справа не будет меньше, чем минимальный слева. Таким образом, все маленькие элементы кидаем в начало, большие - в конец. 3. Рекурсивно применяем данный алгоритм к левой и правой части нашего алгоритма отдельно, затем ещё и ещё, до достижения одного элемента или определённого количества элементов. Что же это за количество элементов? Есть ещё один способ оптимизировать данный алгоритм. Когда сортируемая часть становится примерно равной 8 или 16, то можно обработать её обычной сортировкой, например пузырьковой. Так мы повысим эффективность нашего алгоритма, т.к. маленькие массивы он обрабатывает не так быстро, как хотелось бы. Таким образом, будет обработан и отсортирован весь массив. А теперь наглядно изучим данный алгоритм Является ли быстрая сортировка самым быстрым алгоритмом сортировки? Однозначно нет. Сейчас появляется всё больше и больше сортировок, на данный момент самая быстрая сортировка - это Timsort, она работает крайне быстро для массивов, изначально отсортированных по-разному. Но не стоит забывать, что метод быстрой сортировки является одним из самых простых в написании, это очень важно, ведь, как правило, для рядового проекта нужно именно простое написание, а не громадный алгоритм, который сам ты и не напишешь. Timsort - тоже не самый сложный алгоритм, но звание самого простого ему точно не светит. Ну вот мы и дошли до самого "вкусного". Теперь разберём, как реализовывается данный алгоритм. Как говорилось ранее, он не слишком сложен в реализации, скорее, даже прост. Но мы всё равно полностью разберём каждое действие нашего кода, чтобы вы поняли, как работает быстрая сортировка. Наш метод называется quickSort. В нём запускается основной алгоритм, в который мы передаём массив, первый и последний его элементы. Запоминаем в переменные i и k первый и последний элемент сортируемого отрезка, чтобы не изменять эти переменные, так как они нам нужны. Затем проверяем расстояние между первым и последним проверяемым: оно больше или равно единице? Если нет, значит, мы пришли к центру и нужно выйти из сортировки этого отрезка, а если да, то продолжаем сортировку. Затем за опорный элемент берём первый элемент в сортируемом отрезке. Следующий цикл делаем до того момента, пока не дойдём до центра. В нём делаем ещё два цикла: первый - для левой части, а второй - для правой. Их мы выполняем, пока есть элементы, подходящие под условие, или пока не дойдём до опорного элемента. Затем, если минимальный элемент всё же справа, а максимальный - слева, меняем их местами. Когда цикл заканчивается, меняем первый элемент и опорный, если опорный меньше. Затем мы рекурсивно делаем наш алгоритм для правого и левого участка массива и так продолжаем, пока не дойдём до отрезка длиной в 1 элемент. Тогда все наши рекурсивные алгоритмы будут return, и мы полностью выйдем из сортировки. Также внизу имеется метод swap - вполне стандартный метод при сортировке массива заменами. Чтобы несколько раз не писать замену элементов, пишем один раз и меняем элементы в данном массиве. В заключение можно сказать, что по соотношению "качество-сложность" быстрая сортировка находится на лидирующей позиции среди всех алгоритмов, поэтому вам стоит однозначно взять метод на заметку и использовать при необходимости в своих проектах. Введение
.
Около трех с половиной десятилетий минуло с тех пор, как в педвузах введено в качестве учебной дисциплины программирование для ЭВМ. При колоссальной скорости изменений в самом предмете, всегда существенно превышавшей скорость центральных издательских механизмов, специально ориентированные на программы педвузов книги выходили не чаще, чем раз в десятилетие – едва ли не соразмерно скорости смены поколений ЭВМ. Сегодня полки книжных магазинов ломятся от изданий по информатике. Однако преподавателю (а более всего студенту) специальные учебные книги, содержание и направленность которых отвечают заданному учебному плану и программе все-таки очень нужны. Сейчас помимо программирования на некоторых специальностях в педвузах введены и другие более сложные спецкурсы, находящиеся на стыке прикладной (дискретной) математики и информатики.
В данной курсовой работе можно познакомится с массивами и узнать о простых и сложных методах их сортировки, а также о том, какие из них наиболее эффективны и в каких случаях.
Основная задача – продемонстрировать различные методы сортировки и выделить наиболее эффективные из них. Сортировка – достаточно хороший пример задачи, которую можно решать с помощью многих различных алгоритмов. Каждый из них имеет и свои достоинства, и свои недостатки, и выбирать алгоритм нужно, исходя из конкретной постановки задачи.
В общем сортировку следует понимать как процесс перегруппировки заданного множества объектов в некотором определенном порядке. Цель сортировки – облегчить последующий поиск элементов в таком отсортированном множестве. Это почти универсальная, фундаментальная деятельность. Мы встречаемся с отсортированными объектами в телефонных книгах, в списках подоходных налогов, в оглавлениях книг, в библиотеках, в словарях, на складах – почти везде, где нужно искать хранимые объекты.
Таким образом, разговор о сортировке вполне уместен и важен, если речь идет об обработке данных. Первоначальный интерес к сортировке основывается на том, что при построении алгоритмов мы сталкиваемся со многими весьма фундаментальными приемами. Почти не существует методов, с которыми не приходится встречаться при обсуждении этой задачи. В частности, сортировка – это идеальный объект для демонстрации огромного разнообразия алгоритмов, все они изобретены для одной и той же задачи, многие в некотором смысле оптимальны, большинство имеет свои достоинства. Поэтому это еще и идеальный объект, демонстрирующий необходимость анализа производительности алгоритмов. К тому же на примерах сортировок можно показать, как путем усложнения алгоритма, хотя под рукой и есть уже очевидные методы, можно добиться значительного выигрыша в эффективности.
Выбор алгоритма зависит от структуры обрабатываемых данных – это почти закон, но в случае сортировки такая зависимость столь глубока, что соответствующие методы разбили на два класса – сортировку массивов и сортировку файлов (последовательностей). Иногда их называют внутренней и внешней сортировкой, поскольку массивы хранятся в быстрой, оперативной, внутренней памяти машины со случайным доступом, а файлы обычно размещаются в более медленной, но и более емкой внешней памяти, на устройствах, основанных на механических перемещениях (дисках или лентах).
Прежде чем идти дальше, введем некоторые понятия и обозначения. Если у нас есть элементы а
,
a, …… , а
то сортировка есть перестановка этих элементов в массив а
k,
ak, …… ,
ak где
ak ak
ak
.
Считаем, что тип элемента определен как
INTEGER .
Constn=???; //здесь указывается нужная длина массива
Var A: array of integer; Выбор
INTEGER до некоторой степени произволен. Можно было взять и
другой тип, на котором определяется общее отношение порядка.
Метод сортировки называют устойчивым, если в процессе сортировки относительное расположение элементов с равными ключами не изменяется. Устойчивость сортировки часто бывает желательной, если речь идет об элементах, уже упорядоченных (отсортированных) по некотором вторичным ключам (т.е. свойствам), не влияющим на основной ключ.
Основное условие: выбранный метод сортировки массивов должен экономно использовать доступную память. Это предполагает, что перестановки, приводящие элементы в порядок, должны выполняться на том же месте т. е. методы, в которых элементы из массива а передаются в результирующий массив
b, представляют существенно меньший интерес. Мы будем сначала классифицировать методы по их экономичности, т. е. по времени их работы. Хорошей мерой эффективности может быть
C – число необходимых сравнений ключей и
M – число пересылок (перестановок) элементов. Эти числа суть функции от
n – числа сортируемых элементов. Хотя хорошие алгоритмы сортировки требуют порядка
n*
logn сравнений, мы сначала разберем несколько простых и очевидных методов, их называют прямыми, где требуется порядка
n2 сравнений ключей. Начинать разбор с прямых методов, не трогая быстрых алгоритмов, нас заставляют такие причины:
Прямые методы особенно удобны для объяснения характерных черт основных принципов большинства сортировок.
Программы этих методов легко понимать, и они коротки.
Усложненные методы требуют большого числа операций, и поэтому для достаточно малых
n прямые методы оказываются быстрее, хотя при больших
n их использовать, конечно, не следует.
Методы сортировки “ на том же месте “ можно разбить в соответствии с определяющими их принципами на три основные категории:
Сортировки с помощью включения (byinsertion).
Сортировки с помощью выделения (byselection).
Сортировка с помощью обменов (byexchange).
Теперь мы исследуем эти принципы и сравним их. Все программы оперируют массивом а.
Constn=
a:
array
ofinteger;
Такой метод широко используется при игре в карты. Элементы мысленно делятся на уже “готовую” последовательность а
, … , а
и исходную последовательность. При каждом шаге, начиная с
I = 2 и увеличивая
i каждый раз на единицу, из исходной последовательности извлекается
i- й элементы и перекладывается в готовую последовательность, при этом он вставляется на нужное место.
ПРОГРАММА 2.1. ССОРТИРОВКА С ПОМОЩЬЮ ПРЯМОГО ВКЛЮЧЕНИЯ.
I,J,N,X:INTEGER; A:ARRAY OF INTEGER; WRITELN(‘Введите длину массива’);
READ(N);
WRITELN(‘Введите
массив
’); FOR I:=1 TO N DO READ(A[I]); FOR I:=2 TO N DO WRITELN("Результат:"); END.
Такой типичный случай повторяющегося процесса с двумя условиями
окончания позволяет нам воспользоваться хорошо известным приемом
“барьера” (sentinel).
Анализ метода прямого включения. Число сравнений ключей (Ci) при
i- м просеивании самое большее равно
i-1, самое меньшее – 1; если предположить, что все перестановки из
n ключей равновероятны, то среднее число сравнений –
I/2. Число же пересылок
Mi равно
Ci + 2 (включая барьер). Поэтому общее число сравнений и число пересылок таковы:
Cmin = n-1 (2.1.) Mmin = 3*(n-1) (2.4.) Cave = (n2+n-2)/4 (2.2.) Mave = (n2+9*n-10)/4 (2.5.) Cmax = (n2+n-4)/4 (2.3.) Mmax = (n2+3*
n-4)/2 (2.6.)
Алгоритм с прямыми включениями можно легко улучшить, если обратить внимание на то, что готовая последовательность, в которую надо вставить новый элемент, сама уже упорядочена. Естественно остановиться на двоичном поиске, при котором делается попытка сравнения с серединой готовой последовательности, а затем процесс деления пополам идет до тех пор, пока не будет найдена точка включения. Такой модифицированный алгоритм сортировки называется методом с двоичным включением (binaryinsertion).
ПРОГРАММА 2.2. СОРТИРОВКА МЕТОДОМ ДЕЛЕНИЯ ПОПОЛАМ.
I,J,M,L,R,X,N:INTEGER; A:ARRAY OF INTEGER; WRITELN("Введи массив"); FOR I:=1 TO N DO READ(A[I]); FOR I:=2 TO N DO X:=A[I];L:=1;R:=I; FOR J:=I DOWNTO R+1 DO A[J]:=A; WRITELN("Результат:"); FOR I:=1 TO N DO WRITE(A[I]," ") END.
Анализ двоичного включения. Место включения обнаружено, если
L=
R. Таким образом, в конце поиска интервал должен быть единичной длины; значит, деление его пополам происходит
I*
logI раз. Таким образом:
C =
Si: 1i
n
: [
logI ] (2.7.)
Аппроксимируем эту сумму интегралом
Integral (1:n) log x dx = n*(log n – C) + C (2.8.) Где
C =
loge = 1/
ln 2 = 1.4426… . (2.9.)
Этот прием основан на следующих принципах:
Выбирается элемент с наименьшим ключом
Он меняется местами с первым элементом а1.
Затем этот процесс повторяется с оставшимися
n-1 элементами,
n-2 элементами и т.д. до тех пор, пока не останется один, самый большой элемент.
ПРОГРАММА 2.3. СОРТИРВКА С ПОМОЩЬЮ ПРЯМОГО ВЫБОРА.
I,J,R,X,N:INTEGER; A:ARRAY OF INTEGER; WRITELN("Введи длину массива"); WRITELN("Введи массив"); FOR I:=1 TO N DO READ(A[I]); FOR I:=1 TO N-1 DO FOR J:=I+1 TO N DO IF A[J] WRITELN("Результат:"); FOR I:=1 TO N DO WRITE(A[I]," ") END.
Анализ прямого выбора. Число сравнений ключей (С), очевидно не зависит от начального порядка ключей. Для С мы имеем
C = (n2 –
n)/2 (2.10.).
Число перестановок минимально:
Mmin = 3*(n-1) (2.11.).
В случае изначально упорядоченных ключей и максимально
Mmax =
n2/4 + 3*(n-1) (2.12.)
Определим М
avg . Для достаточно больших
n мы можем игнорировать дробные составляющие и поэтому аппроксимировать среднее число присваиваний на
i-м просмотре выражением
Fi =
lni +
g + 1 (2.13.), где
g = 0.577216… - константа Эйлера.
Среднее число пересылок
Mavg в сортировке с выбором есть сумма
Fi с
i от 1 до
n Mavg = n*(g + 1) + (Si: 1 Вновь аппроксимируя эту сумму дискретных членов интегралом
Integral (1:n) ln x dx = x*(ln x – 1) = n*ln (n) – n + 1 (2.15.) Получаем приблизительное значение
Mavg =
n*(ln (n) +
g) . (2.16.)
2.1.3. Сортировка с помощью прямого обмена
.
Как и в методе прямого выбора, мы повторяем проходы по массиву, сдвигая каждый раз наименьший элемент оставшейся последовательности к левому концу массива. Если мы будем рассматривать как вертикальные, а не горизонтальные построения, то элементы можно интерпретировать как пузырьки в чане с водой, причем вес каждого соответствует его ключу.
ПРОГРАММА 2.4. ПУЗЫРЬКОВАЯ СОРТИРОВКА.
PROGRAMBS;
I,J,X,N:INTEGER; A:ARRAY OF INTEGER; WRITELN("Введи длину массива"); WRITELN("Введи массив"); FOR I:=1 TO N DO READ(A[I]); FOR I:=2 TO N DO FOR J:=N DOWNTO I DO IF A>A[J] THEN WRITELN("Результат:"); FOR I:=1 TO N DO END.
Улучшения этого алгоритма напрашиваются сами собой:
Запоминать, были или не были перестановки в процессе
некоторого прохода.
Запоминать не только сам факт, что обмен имел место, но и
положение (индекс) последнего обмена.
Чередовать направление последовательных просмотров.
Получающийся при этом алгоритм мы назовем “шейкерной” сортировкой (ShakerSoft).
Анализ пузырьковой и шейкерной сортировок. Число сравнений в строго обменном алгоритме
C = (n2 –
n)/2, (2.17.), а минимальное, среднее и максимальное число перемещений элементов (присваиваний) равно соответственно
M = 0,
Mavg = 3*(n2 –
n)/2,
Mmax = 3*(n2 –
n)/4 (2.18.)
Анализ же улучшенных методов, особенно шейкерной сортировки довольно сложен. Минимальное число сравнений
Cmin =
n – 1. Кнут считает, что улучшенной пузырьковой сортировки среднее число проходов пропорционально
n –
k1
n1/2, а среднее число сравнений пропорционально ½(n2 –
n(k2 +
lnn)).
ПРОГРАММА 2.5. ШЕЙКЕРНАЯ СОРТИРОВКА.
PROGRAMSS;
J,L,K,R,X,N,I:INTEGER; A:ARRAY OF INTEGER; WRITELN("Введи длину массива’); WRITELN("Введи массив"); FOR I:=1 TO N DO FOR J:=R DOWNTO L DO IF A>A[J] THEN FOR J:=L TO R DO IF A>A[J] THEN WRITELN("Результат:"); FOR I:=1 TO N DO END.
Фактически в пузырьковой сортировке нет ничего ценного, кроме ее привлекательного названия. Шейкерная же сортировка широко используется в тех случаях, когда известно, что элементы почти упорядочены – на практике это бывает весьма редко.
В 1959 году Д. Шеллом было предложено усовершенствование сортировки с помощью прямого включения. Сначала отдельно сортируются и группируются элементы, отстоящие друг от друга на расстояние 4. Такой процесс называется четверной сортировкой. В нашем примере восемь элементов и каждая группа состоит из двух элементов. После первого прохода элементы перегруппировываются – теперь каждый элемент группы отстоит от другого на две позиции – и вновь сортируются. Это называется двойной сортировкой. На третьем подходе идет обычная или одинарная сортировка. На каждом этапе либо сортируется относительно мало элементов, либо элементы уже довольно хорошо упорядочены и требуют сравнительно немного перестановок.
ПРОГРАММА 2.6. СОРТИРОВКА ШЕЛЛА..
PROGRAMSHELLS;
H: ARRAY OF INTEGER = (15,7,3,1); I,J,K,S,X,N,M:INTEGER; A:ARRAY[-16..50] OF INTEGER; WRITELN("Введи длину массива"); WRITELN("Введи массив"); FOR I:=1 TO N DO FOR M:=1 TO T DO FOR I:=K+1 TO N DO IF S=0 THEN S:=-K; WRITELN("Результат:"); FOR I:=1 TO N DO Анализ сортировки Шелла. Нам не известно, какие расстояния дают наилучший результат. Но они не должны быть множителями один другого. Справедлива такая теорема: если
k-отсортированную последовательность
i-отсортировать, то она остается
k-отсортированной. Кнут показывает, что имеет смысл использовать такую последовательность, в которой
hk-1 = 3
hk + 1,
ht = 1 и
t = [
log2
n] – 1. (2.19.)
2.2.2.Сортировка с помощью дерева
.
Метод сортировки с помощью прямого выбора основан на повторяющихся поисках наименьшего ключа среди
n элементов, среди
n-1 оставшихся элементов и т. д. Как же усовершенствовать упомянутый метод сортировки? Этого можно добиться, действуя согласно следующим этапам сортировки:
1. Оставлять после каждого прохода больше информации, чем просто идентификация единственного минимального элемента. Проделав
n-1 сравнений, мы можем построить дерево выбора вроде представленного на рисунке 2.1.
44 12 18 06
44 55 12 42 94 18 06 67
РИСУНОК 2.1. ПОВТОРЯЮЩИЙСЯ ВЫБОР СРЕДИ ДВУХ КЛЮЧЕЙ.
2. Спуск вдоль пути, отмеченного наименьшим элементом, и исключение его из дерева путем замены либо на пустой элемент в самом низу, либо на элемент из соседний ветви в промежуточных вершинах (см. рисунки 2.2 и 2.3.).
Д. Уилльямсом был изобретен метод
Heapsort, в котором было получено существенное улучшение традиционных сортировок с помощью деревьев. Пирамида определяется как последовательность ключей
a[
L],
a[
L+1], … ,
a[
R], такая, что
a[
i] a
и
a[
i] a
для
i=
L…
R/2.
Р. Флойдом был предложен некий “лаконичный” способ построения пирамиды на ”том же месте”. Здесь
a …
a[
n] – некий массив, причем
a[
m]…
a[
n] (m = [
nDIV 2] + 1) уже образуют пирамиду, поскольку индексов
i и
j, удовлетворяющих соотношению
j = 2
i (или
j = 2
i + 1), просто не существует.
44 12 18
44 55 12 42 94 18 67
РИСУНОК 2.2.ВЫБОР НАИМЕНЬШЕГО КЛЮЧА.
12 18
44 12 18 67
44 55 12 42 94 18 67
РИСУНОК 2.3. ЗАПОЛНЕНИЕ ДЫРОК.
Эти элементы образуют как бы нижний слой соответствующего двоичного дерева (см. рисунок 2.4.), для них никакой упорядоченности не требуется. Теперь пирамида расширяется влево; каждый раз добавляется и сдвигами ставится в надлежащую позицию новый элемент. Получающаяся пирамида показана на рисунке 2.4.
РИСУНОК
2.4.МАССИВ
, ПРЕДСТАВЛЕННЫЙ
В
ВИДЕ
ДВОИЧНОГО
ДЕРЕВА
. ПРОГРАММА 2.7. HEARSORT. I,X,L,N,R:INTEGER; A:ARRAY OF INTEGER; PROCEDURE SIFT(L,R: INTEGER); WRITELN("Введи длину массива"); WRITELN("Введи массив"); FOR I:=1 TO N DO WRITELN(‘Результат:"); FOR I:=1 TO N DO END.
Анализ
Heapsort.
Heapsort очень эффективна для большого числа элементов
n; чем больше
n, тем лучше она работает.
В худшем случае нужно
n/2 сдвигающих шагов, они сдвигают элементы на
log(n/2),
log(n/2 – 1), … ,
log(n – 1) позиций (логарифм по [основанию 2] «обрубается» до следующего меньшего целого). Следовательно фаза сортировки будет
n – 1 сдвигов с самое большое
log(n-1),
log(n-2), … , 1 перемещениями. Можно сделать вывод, что даже в самом плохом из возможных случаев
Heapsort потребуется
n*
logn шагов. Великолепная производительность в таких случаях – одно из привлекательных свойств
Heapsort.
2.2.3. Сортировка с помощью разделения
.
Этот улучшенный метод сортировки основан на обмене. Это самый лучший из всех известных на данный момент методов сортировки массивов. Его производительность столь впечатляюща, что изобретатель Ч. Хоар назвал этот метод быстрой сортировкой (Quicksort) . В
Quicksort исходят из того соображения, что для достижения наилучшей эффективности сначала лучше производить перестановки на большие расстояния. Предположим, что у нас есть
n элементов, расположенных по ключам в обратном порядке. Их можно отсортировать за
n/2 обменов, сначала поменять местами самый левый с самым правым, а затем последовательно сдвигаться с двух сторон. Это возможно в том случае, когда мы знаем, что порядок действительно обратный. Однако полученный при этом алгоритм может оказаться и не удачным, что, например, происходит в случае
n идентичных ключей: для разделения нужно
n/2 обменов. Этих необязательных обменов можно избежать, если операторы просмотра заменить на такие:
В этом случае
x не работает как барьер для двух просмотров. В результате просмотры массива со всеми идентичными ключами приведут к переходу через границы массива.
Наша цель – не только провести разделение на части исходного массива элементов, но и отсортировать его. Будем применять процесс разделения к получившимся двум частям, до тех пор, пока каждая из частей не будет состоять из одного-единственного элемента. Эти действия описываются в программе 2.8.
ПРОГРАММА 2.8. QUICKSORT. A:ARRAY OF INTEGER; PROCEDURE SORT(L,R: INTEGER); I,J,X,W: INTEGER; X:=A[(L+R) DIV 2]; WRITELN("Введи длину массива"); WRITELN("Введи массив"); FOR I:=1 TO N DO READ(A[I]); WRITELN("Результат:"); FOR I:=1 TO N DO END.
Анализ
Quicksort. Процесс разделения идет следующим образом: выбрав некоторое граничное значение
x, мы затем проходим целиком по всему массиву. При этом выполняется точно
n сравнений. Ожидаемое число обменов есть среднее этих ожидаемых значений для всех возможных границ
x.
N*(n-1)/2n-(2n2-3n+1)/6n = (n-1/n)/6 (2.20.) В том случае, если бы нам всегда удавалось выбирать в качестве границы медиану, то каждый процесс разделения расщеплял бы массив на две половинки, и для сортировки требовалось бы всего
n*
logn подходов. В результате общее число сравнений было бы равно
n*
logn, а общее число обменов –
n*
log(n) /6. Но вероятность этого составляет только 1/
n.
Главный из недостатков
Quicksort – недостаточно высокая производительность при небольших
n, впрочем этим грешат все усовершенствованные методы, одним из достоинств является то, что для обработки небольших частей в него можно легко включить какой-либо из прямых методов сортировки.
Тесты
.
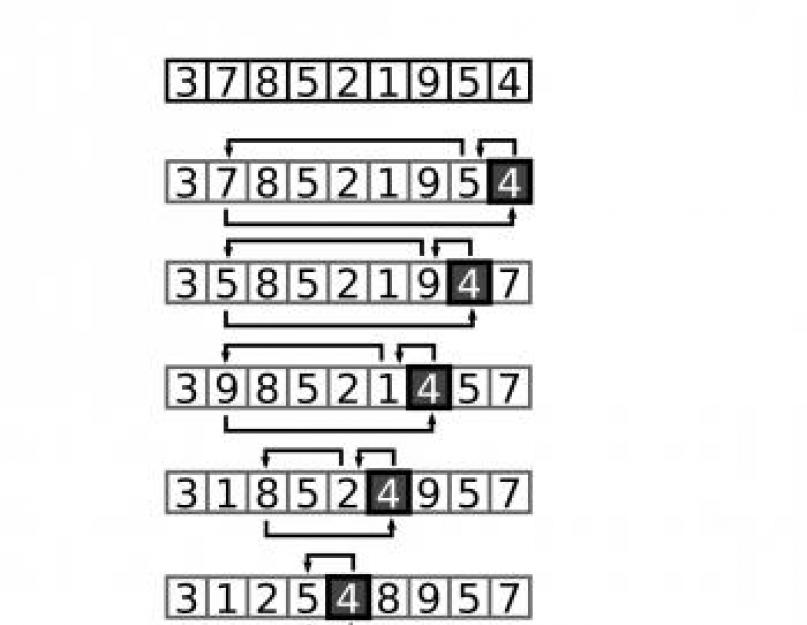
Идея сортировки массива прямым включением заключается в том, что
в сортируемой последовательности masi длиной n (i = 0..n - 1) последовательно выбираются элементы начиная со второго (i
в сортируемой последовательности masi длиной n (i=0..n-1) последовательно выбираются элементы начиная со первого (i
в сортируемой последовательности masi длиной n (i=0..n-1) последовательно выбираются элементы начиная со второго (i
в сортируемой последовательности masi длиной n-1 (i=0..n-1) последовательно выбираются элементы начиная со второго (i
При сортировке массива прямым включением поиск места включения очередного элемента х в левой части последовательности mas может закончиться двумя ситуациями:
найден элемент последовательности mas, для которого masi>x; достигнут левый конец отсортированной слева последовательности.
найден элемент последовательности mas, для которого masi
найден элемент последовательности mas, для которого masi
При сортировке массива прямым включением для отслеживания условия окончания просмотра влево отсортированной последовательности используется прием «барьера». Суть его в том, что
к исходной последовательности справа добавляется фиктивный элемент X. В начале каждого шага просмотра влево отсортированной части массива элемент X устанавливается в значение того элемента, для которого будет осуществляться поиск места вставки.
к исходной последовательности слева добавляется фиктивный элемент X. В конце каждого шага просмотра влево отсортированной части массива элемент X устанавливается в значение того элемента, для которого будет осуществляться поиск места вставки.
к исходной последовательности слева добавляется фиктивный элемент X. В начале каждого шага просмотра влево отсортированной части массива элемент X устанавливается в значение того элемента, для которого не будет осуществляться поиск места вставки.
к исходной последовательности слева добавляется фиктивный элемент X. В начале каждого шага просмотра влево отсортированной части массива элемент X устанавливается в значение того элемента, для которого будет осуществляться поиск места вставки.
Сортировка массива прямым включением требует в среднем
N^2/2 перемещений.
N^2/4 перемещений.
N^2 перемещений.
N/4 перемещений.
Выберите правильный вариант для вставки вместо знака «вопрос» во фрагмент кода сортировки массива прямым включением:
For
i:=2 to С
ount do Begin
Tmp:=Arr
[i]; j:=i
-1; Begin
Arr
:=Arr[j]; j:=j
-1; End
; Arr
:=Tmp; End
; While (j0) and (Arr[j] ) do While (j>0) and (Arr[j]>Tmp) do While
(j>
0
)
and
(Arr
[
j
]
)
do
While (j=0) and (Arr[j]=Tmp) do Алгоритм сортировки массива бинарными включениями
вставляет
i
-
й
элемент в готовую последовательность, которая пока не отсортирована, для нахождения места для
i
-
го
вставляет
i
-
й
i
-
го
элемента используется метод бинарного поиска элемента.
вставляет
i
-
й
элемент в готовую последовательность, которая уже отсортирована, для нахождения места для
i
-
го
вставляет
i
-
й
элемент в пока готовую последовательность, которая пока не отсортирована, для нахождения места для
i
-
го
элемента используется метод Шелла поиска элемента.
При сортировке массива бинарными включениями
всего будет произведено
N
log
2
N
сравнений.
log
2
N
сравнений.
log
2
(N/
2
)
сравнений.
N
/2*log
2
N
сравнений.
Изменится ли количество пересылок в сортировке массива бинарными включениями по отношению к количеству сравнений
станет больше
станет меньше
не изменится.
При сортировке массива методом бинарного включения внутренний цикл поиска с одновременным сдвигом следует разделить:
бинарным поиском находится позиция вставки, затем все элементы готовой последовательности, находящиеся левее этой позиции, сдвигаются вправо.
бинарным поиском находится позиция вставки, затем все элементы готовой последовательности, находящиеся правее этой позиции, сдвигаются влево.
бинарным поиском находится позиция вставки, затем все элементы готовой последовательности, находящиеся правее этой позиции, сдвигаются вправо.
бинарным поиском находится позиция вставки, затем все элементы готовой последовательности, находящиеся левее этой позиции, сдвигаются влево.
В чем состоит идея сортировки массива методом Шелла?
сортировке подвергаются не все подряд элементы последовательности, а только отстоящие друг от друга на определенном расстоянии большем h.
сортировке подвергаются не все подряд элементы последовательности, а только отстоящие друг от друга на определенном расстоянии меньшем h.
сортировке подвергаются не все подряд элементы последовательности, а только отстоящие друг от друга на определенном расстоянии h.
сортировке подвергаются не все подряд элементы последовательности, а только h элементов.
При сортировке массива методом Шелла на каждом шаге значение h изменяется, пока не станет (обязательно) равно
Если h=1, то алгоритм сортировки массива методом Шелла вырождается в
пирамидальную сортировку.
сортировку прямыми включениями.
сортировку слиянием.
сортировку бинарного включения.
При сортировке массива методом Шелла расстояния между сравниваемыми элементами могут изменяться по-разному. Обязательным является лишь то, что
последний шаг должен равняться единице.
последний шаг должен равняться нулю.
первый элемент равен последнему элементу.
первый элемент равен предпоследнему элементу.
Эффективность сортировки массива методом Шелла объясняется тем, что
при каждом проходе используется очень большое число элементов, упорядоченность увеличивается при каждом новом просмотре данных.
при каждом проходе элементы массива не упорядочены, а упорядоченность увеличивается при каждом новом просмотре данных.
при каждом проходе используется относительно небольшое число элементов или элементы массива уже находятся в относительном порядке, а упорядоченность увеличивается при каждом новом просмотре данных.
Идея алгоритма сортировки массива прямым выбором заключается в том, что
на каждом шаге просмотру подвергается несортированная правая часть массива. В ней ищется очередной максимальный элемент. Если он найден, то производится его перемещение на место крайнего левого элемента несортированной правой части массива.
на каждом шаге просмотру подвергается несортированная правая часть массива. В ней ищется очередной минимальный элемент. Если он не найден, то производится его перемещение на место крайнего левого элемента несортированной правой части массива.
на каждом шаге просмотру подвергается несортированная правая часть массива. В ней ищется очередной минимальный элемент. Если он найден, то производится его перемещение на место крайнего правого элемента несортированной левой части массива.
на каждом шаге просмотру подвергается несортированная правая часть массива. В ней ищется очередной минимальный элемент. Если он найден, то производится его перемещение на место крайнего левого элемента несортированной правой части массива.
Если сортировку выбором применить для массива "bdac", то будут получены следующие проходы
первый проход:
c d b
a; второй проход: a b b c; третий проход: a b c d.
d
c; третий проход: a b c d.
первый проход: a d b c; второй проход: a
cdb; третий проход: a b c d.
первый проход: a d b c; второй проход: a b
d c; третий проход:
d b c
a.
Как и в сортировке массива пузырьковым методом в сортировке массива прямым выбором внешний цикл
выполняется n раз, а внутренний цикл выполняется n/2 раз.
выполняется n-1 раз, а внутренний цикл выполняется n раз.
выполняется n-1 раз, а внутренний цикл выполняется n/2 раз.
выполняется n раз, а внутренний цикл выполняется n раз.
Вставить во фрагмент кода сортировки массива прямым выбором, вместо знака «вопроса», верное неравенство:
for i:= 1 to n - 1 do
begin
min:= i;
for j:= i + 1 to n do
if
?
then min:= j;
t:= a[i];
a[i] := a;
a := t
end;
a > a[j].
a[
min]
a[
j].
При сортировке массива методом прямого выбора в лучшем случае (когда исходный массив уже упорядочен) потребуется поменять местами только?, а каждая операция обмена требует три операции пересылки.
Вставьте вместо знака «вопрос» верный вариант.
n-элементов.
(n-1)-элементов.
n/2-элементов.
2*n-элементов.
Алгоритм сортировки массива методом пирамидального выбора предназначен для сортировки последовательности чисел, которые
являются отображением в памяти дерева специальной структуры - пирамиды.
являются отображением в памяти дерева специальной структуры - дерева.
являются отображением в памяти пирамиды специальной структуры - пирамиды.
являются отображением в памяти куста специальной структуры - дерева.
На рисунке изображено несколько деревьев, из которых лишь одно
является пирамидой.
Т4.
Пирамида, показанная на рисунке (одна из четырех), в памяти будет представлена следующим массивом:
3, 2, 7, 11, 5, 8, 14, 9, 27.
2, 3, 5, 7, 8, 9, 11, 14, 27. 27, 14, 11, 9, 8, 7, 5, 3, 2. 27, 9, 14, 8, 5, 11, 7, 2, 3.
На каждом из n шагов, требуемых для сортировки массива методом пирамидального выбора, нужно
n*log n (двоичных) сравнений.
(log n
)/2 (двоичных) сравнений.
log n (двоичных) сравнений.
2 * log n (двоичных) сравнений.
Идея алгоритма сортировки массива прямым обменом заключается в том, что
если номер позиции большего из элементов больше номера позиции меньшего элемента, то меняем их местами.
если номер позиции меньшего из элементов больше номера позиции большего элемента, то не меняем их местами.
если номер позиции меньшего из элементов больше номера позиции большего элемента, то оставляем их на месте.
если номер позиции меньшего из элементов больше номера позиции большего элемента, то меняем их местами.
При использовании метода пузырьковой сортировки массива требуется самое большее
n проходов.
(n-1) проходов.
n
/2 проходов.
2*n проходов.
При сортировке массива методом прямого обмена или методом пузырьковой сортировки после каждого прохода через таблицу может быть сделана проверка, были ли совершены перестановки в течение данного прохода. Если перестановок не было, то это означает, что
таблица не отсортирована и требует дальнейших проходов.
таблица уже отсортирована и требует дальнейших проходов.
таблица уже отсортирована и дальнейших проходов не требуется.
таблица не отсортирована и дальнейших проходов не требуется.
Сортировка массива пузырьковым методом обладает одной особенностью: расположенный не на своем месте в конце массива элемент
достигает своего места за один проход.
достигает своего места за два прохода.
достигает своего места за три прохода.
достигает своего места за
N проходов.
Сортировка массива пузырьковым методом обладает одной особенностью: элемент, расположенный в начале массива
очень быстро достигает своего места.
очень медленно достигает своего места.
не достигает своего места.
достигает середины массива.
В основе метода внутренней сортировки массива лежит процедура слияния
двух упорядоченных таблиц.
одной упорядоченной таблицы.
трех упорядоченных таблиц.
двух неупорядоченных таблиц.
Сущность сортировки массива слиянием состоит в том, что упорядочиваемая таблица разделяется на равные группы элементов. Группы упорядочиваются, а затем
попарно сливаются, образуя три новые группы, содержащие втрое больше элементов.
попарно сливаются, образуя две новые группы, содержащие вдвое больше элементов.
попарно сливаются, образуя новые группы, содержащие втрое больше элементов.
попарно сливаются, образуя новые группы, содержащие вдвое больше элементов.
В предложенных тестах правильные ответы выделены курсивом.
Заключение
.
В данной курсовой работе рассматриваются задачи сортировки, постановка задачи сортировки массивов. А также основная часть отведена рассмотрению методов: а именно, простые методы сортировки (сортировка с помощью прямого включения, сортировка с помощью прямого выбора, сортировка с помощью прямого обмена) и улученные методы сортировки массивов (метод Шелла, сортировка с помощью дерева, сортировка с помощью разделения). Предложен анализ к каждому из методов сортировки массивов. Разработаны тестовые задания по сортировкам массивов (30 заданий).
http://ru.wikipedia.org
В статье рассмотрены одни из самых популярных алгоритмов сортировки для массивов, применяемых как практически, так и в учебных целях. Сразу хочу оговориться, что все рассмотренные алгоритмы медленнее, чем метод классической сортировки массива через список значений, но тем не менее, заслуживают внимания. Текста получается много, поэтому по каждому алгоритму описываю самое основное.
1.Алгоритм "Сортировка выбором".
Является одним из самых простых алгоритмов сортировки массива. Смысл в том, чтобы идти по массиву и каждый раз искать минимальный элемент массива, обменивая его с начальным элементом неотсортированной части массива. На небольших массивах может оказаться даже эффективнее, чем более сложные алгоритмы сортировки, но в любом случае проигрывает на больших массивах. Число обменов элементов по сравнению с "пузырьковым" алгоритмом N/2, где N - число элементов массива. Алгоритм:
//Сортировка выбором {---
Функция СортировкаВыбором(Знач Массив)
Мин = 0;
Для i = 0 По Массив.ВГраница() Цикл
Мин = i;
Для j = i + 1 ПО Массив.ВГраница() Цикл //Ищем минимальный элемент в массиве
Если Массив[j] < Массив[Мин] Тогда
Мин = j;
КонецЕсли;
КонецЦикла;
Если Массив [Мин] = Массив [i] Тогда //Если мин. элемент массива = первому элементу неотс. части массива, то пропускаем.
Продолжить;
КонецЕсли;
Смена = Массив[i]; //Производим замену элементов массива.
Массив[i] = Массив[Мин];
Массив[Мин] = Смена;
КонецЦикла;
Возврат Массив;
КонецФункции
2.Алгоритм "Сортировка пузырьком".
Пожалуй самый известный алгоритм, применяемый в учебных целях, для практического же применения является слишком медленным. Алгоритм лежит в основе более сложных алгоритмов: "Шейкерная сортировка", "Пирамидальная сортировка", "Быстрая сортировка". Примечательно то, что один из самых быстрых алгоритмов "Быстрый алгоритм" был разработан путем модернизации одного из самых худших алгоритмов "Сортировки пузырьком"."Быстрая" и "Шейкерная" сортировки будут рассмотрены далее. Смысл алгоритма заключается в том, что самые "легкие" элементы массива как бы "всплывают" , а самые "тяжелые" "тонут". Отсюда и название "Сортировка пузырьком" Алгоритм:
//Сортировка пузырьком {---
Функция СортировкаПузырьком(Знач Массив)
Для i = 0 По Массив.ВГраница() Цикл
Для j = 0 ПО Массив.Вграница() - i - 1 Цикл
Если Массив[j] > Массив Тогда
Замена = Массив[j];
Массив[j] = Массив;
Массив = Замена;
КонецЕсли;
КонецЦикла;
КонецЦикла;
Возврат Массив;
КонецФункции
//---}
3.Алгоритм "Шейкерная сортировка"(Сортировка перемешиванием,Двунаправленная пузырьковая сортировка).
Алгоритм представляет собой одну из версий предыдущей сортировки - "сортировки пузырьком". Главное отличие в том, что в классической сортировке пузырьком происходит однонаправленное движение элементов снизу - вверх, то в шейкерной сортировке сначало происходит движение снизу-вверху, а затем сверху-вниз. Алгоритм такой же, что и у пузырьковой сортировки + добавляется цикл пробега сверху-вниз. В приведенном ниже примере, есть усовершенствование в шейкерной сортировке. В отличие от классической, используется в 2 раза меньше итераций.
//Сортировка перемешивание (Шейкер-Сортировка) {---
Функция СортировкаПеремешиванием(Знач Массив)
Для i = 0 ПО Массив.ВГраница()/2 Цикл
нИтер = 0;
конИтер = Массив.ВГраница();
Пока нИтер Массив[нИтер+1] Тогда
Замена = Массив[нИтер];
Массив[нИтер] = Массив[нИтер + 1];
Массив[нИтер + 1] = Замена;
КонецЕсли;
нИтер = нИтер + 1;//Двигаем позицию на шаг вперед
//Проходим с конца
Если Массив[конИтер - 1] > Массив[конИтер] Тогда
Замена = Массив[конИтер - 1];
Массив[конИтер-1] = Массив[конИтер];
Массив[конИтер] = Замена;
КонецЕсли;
конИтер = конИтер - 1;//Двигаем позицию на шаг назад
КонецЦикла;
КонецЦикла;
Возврат Массив;
КонецФункции
//---}
4. Алгоритм "Гномья сортировка".
Алгоритм так странно назван благодаря голландскому ученому Дику Груну. Гномья сортировка основана на технике, используемой обычным голландским садовым гномом (нидерл. tuinkabouter). Это метод, которым садовый гном сортирует линию цветочных горшков. По существу он смотрит на следующий и предыдущий садовые горшки: если они в правильном порядке, он шагает на один горшок вперёд, иначе он меняет их местами и шагает на один горшок назад. Граничные условия: если нет предыдущего горшка, он шагает вперёд; если нет следующего горшка, он закончил.
Вот собственно и все описание алгоритма "Гномья сортировка". Что интересно, алгоритм не содержит вложенных циклов, а сортирует весь массив за один проход.
//Гномья сортировка {---
Функция ГномьяСортировка(Знач Массив)
i = 1;
j = 2;
Пока i < Массив.Количество() Цикл // Сравнение < - Сортировка по возрастанию, > - по убыванию
Если Массив
i = j;
j = j + 1;
Иначе
Замена = Массив[i];
Массив[i] = Массив;
Массив = Замена;
i = i - 1;
Если i = 0 Тогда
i = j;
j = j + 1;
КонецЕсли;
КонецЕсли;
КонецЦикла;
Возврат Массив;
КонецФункции
//---}
5. Алгоритм "Сортировка вставками".
Представляет собой простой алгоритм сортировки. Смысл заключается в том, что на каждом шаге мы берем элемент, ищем для него позицию и вставляем в нужное место. 6. Алгортим "Сортировка слиянием".
Интересный в плане реализации и идеи алгоритм. Смысл его в том, чтобы разбивать массив на подмассивы, пока длина каждого подмассива не будет равна 1. Тогда мы утверждаем, что такой подмассив отсортирован. Затем сливаем получившиеся подмассивы воедино, одновременно сравнивая и сортируя
поэлементно значения подмассивов. p/s не смог вставить сюда рисунок с более наглядной схемой, постоянно размазывается. Зато хорошо видна в блоке скриншотов внизу. Можно посмотреть как работает алгоритм. //Сортировка слиянием {---
Функция СортировкаСлиянием(Знач Массив)
Если Массив.Количество() = 1 Тогда
Возврат Массив;
КонецЕсли;
ТочкаРазрыв = Массив.Количество() / 2;
лМассив = Новый Массив;
прМассив = Новый Массив;
Для Сч = 0 ПО Массив.ВГраница() Цикл
Если Сч < ТочкаРазрыв Тогда
лМассив.Добавить(Массив[Сч]);
Иначе
прМассив.Добавить(Массив[Сч]);
КонецЕсли;
КонецЦикла;
Возврат Слияние(СортировкаСлиянием(лМассив),СортировкаСлиянием(прМассив));
КонецФункции
Функция Слияние(массив1,массив2)
a = 0;
b = 0;
слМассив = Новый Массив;
Для Сч = 0 ПО (Массив1.Количество() + Массив2.Количество())-1 Цикл
слМассив.Добавить();
КонецЦикла;
Для i = 0 ПО (массив1.Количество() + массив2.Количество())-1 Цикл
Если b < массив2.Количество() И a < массив1.Количество() Тогда
Если (массив1[a] > массив2[b]) И (b < массив2.Количество()) Тогда
слМассив[i] = массив2[b];
b = b + 1;
Иначе
слМассив[i] = массив1[a];
a = a + 1;
КонецЕсли;
Иначе
Если b < массив2.количество() Тогда
слМассив[i] = массив2[b];
b = b + 1;
Иначе
слМассив[i] = массив1[a];
a = a + 1;
КонецЕсли;
КонецЕсли;
КонецЦикла;
Возврат слМассив;
КонецФункции
//---}
7. Алгортим "Сортировка Шелла".
Алгоритм назван так в честь американского ученого Дональда Шелла. По своей сути этот алгоритм является усовершенствованным алгоритмом "Сортировка вставками". Смысл алгоритма заключается в том, чтобы сравнивать не только элементы, стоящие рядом друг с другом, но и на некотором удалении. Сначало выбирается Шаг - некий промежуток, через который будут сравниваться элементы массива на каждой итерации. Обычно его определяют так: Пример: 10
,2
,3
,1,14
,5
,7
,12 2. Шаг = 2 3
,1
,7
,2
,10
,5
,14
,12
3. Шаг = 1 1,2,3,5,7,10,12,14 8. Алгортим "Быстрая сортировка".
Наиболее популярный и применяемый алгоритм на практике. Является одним из самых эффективных алгоритмов сортировки данных.
//Алгоритм "Быстрая сортировка" {
Процедура б_Сортировка(Массив,НижнийПредел,ВерхнийПредел)
i = НижнийПредел;
j = ВерхнийПредел;
m = Массив[Цел((i+j)/2)];
Пока Истина Цикл
Пока Массив[i] < m Цикл
i = i + 1;
КонецЦикла;
Пока Массив[j] > m Цикл
j = j - 1;
КонецЦикла;
Если i > j Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Если НижнийПредел < j Тогда
б_Сортировка(Массив,НижнийПредел,j);
КонецЕсли;
Если i < ВерхнийПредел Тогда
б_Сортировка(Массив,i,ВерхнийПредел);
КонецЕсли;
КонецПроцедуры
Функция БыстраяСортировка(Массив)
НижняяГраница = 0;
ВерхняяГраница = Массив.ВГраница();
б_Сортировка(Массив,НижняяГраница,ВерхняяГраница);
Возврат Массив;
КонецФункции
//---}
9. Классическая сортировка массива в 1с.
Передаем массив в список значений. Сортируем стандартным методом "Сортировать".
//Сортировка списком значений {---
Функция СортировкаСпискомЗначений(Знач Массив)
мСписокЗнч = Новый СписокЗначений;
мСписокЗнч.ЗагрузитьЗначения(Массив);
мСписокЗнч.СортироватьПоЗначению(НаправлениеСортировки.Возр);
Возврат мСписокЗнч.ВыгрузитьЗначения();
КонецФункции
//---}
Все сортировки можно ускорить расположив код в циклах в 1 строку. Но для читабельности, оставил так.
Написал обработку в которой реализованы все вышеперечисленные алгоритмы, также поддерживается динамическая анимация процесса сортировки
(Кроме стандартной сортировки 1с).
-При запуске обработки автоматически происходит формирование массива случайных чисел от 0 до 100 размерностью 100 элементов. Динамическая отрисовка процесса сортировки очень сильно снижает производительность, зато наглядно видно как работает алгоритм.
Понятие быстрой сортировки
Алгоритм
Эффективность быстрой сортировки

Реализация алгоритма


1. Задачи сортировки.
1.1.Общие положения.
1.2. Постановка задачи сортировки массивов.
2. Методы сортировки массивов.
2.1. Простые методы сортировки массивов.
2.1.1. Сортировка с помощью прямого включения.
2.1.2.Сортирвка с помощью прямого выбора.
2.2. Улучшенные методы сортировки массивов.
2.2.1.Метод Шелла.
1. Находим минимальный элемент в массиве.
2. Меняем местами минимальный и первый элемент местами.
3. Опять ищем минимальный элемент в неотсортированной части массива
4. Меняем местами уже второй элемент массива и минимальный найденный, потому как первый элемент массива является отсортированной частью.
5. Ищем минимальные значения и меняем местами элементы,пока массив не будет отсортирован до конца.
1. Каждый элемент массива сравнивается с последующим и если элемент[i] > элемент происходит замена. Таким образом самые "легкие" элементы "всплывают" - перемещаются к началу списка,а самые тяжелые "тонут" - перемещаются к концу.
2. Повторяем Шаг 1 n-1 раз, где n - Массив.Количество ().
Дик Грун
Элементарный пример: При игре в дурака, вы тянете из колоды карту и вставляете ее в соответствующее место по возрастанию в имеющихся у вас картах. Или
в магазине вам дали сдачу 550 рублей- одна купюра 500, другая 50. Заглядываете в кошелек, а там купюры достоинством 10,100,1000. Вы вставляете купюру
достоинсвом 50р. между купюрами достоинством 10р и 100р, а купюру в 500 рублей между купюрами 100р и 1000р. Получается 10,50,100,500,1000 - Вот вам
и алгоритм "Сортировка вставками".
Таким образом с каждым шагом алгоритма, вам необходимо отсортировать подмассив данных и вставить значение в нужное место.
//Сортировка вставками {---
Функция СортировкаВставками(Знач Массив)
Для i = 0 По Массив.ВГраница()-1 Цикл
Ключ = i + 1;
Замена = Массив[Ключ];
j = i + 1;
Пока j > 0 И Замена < Массив Цикл
Массив[j] = Массив;
Замена = j - 1;
Ключ = j - 1;
j = j - 1;
КонецЦикла;
Массив[Ключ] = Замена;
КонецЦикла;
Возврат Массив;
КонецФункции
//---}
Для первой итерации Шаг = Цел(Массив.Количество()/2), для последующих Шаг = Цел(Шаг/2). Т.е. постепенно шаг сокращается и когда Шаг будет равен 1 произойдет последние сравнение и массив будет отсортирован.
Дан массив (10,5,3,1,14,2,7,12).
1. Шаг = 4.
Сортируем простыми вставками каждые 4 группы по 2 элемента (10,14)(5,2)(3,7)(1,12)
Сортируем простыми вставками каждые 2 группы по 4 элемента (10,3,14,7)(2,1,5,12)
Сортируем простыми вставками каждую 1 группу по 8 элементов.
//Сортировка Шелла {---
Функция СортировкаШелла(Знач Массив)
Шаг = Цел(Массив.Количество()/2);
Пока Шаг > 0 Цикл
i = 0;
Пока i < (Массив.Количество() - Шаг) Цикл
j = i;
Пока j >= 0 И Массив[j] > Массив Цикл
Замена = Массив[j];
Массив[j] = Массив;
Массив = Замена;
j = j - 1;
Если ПрименитьОтображениеСортировки Тогда
ОтобразитьДиаграммуСортировки(Массив);
КонецЕсли;
КонецЦикла;
i = i + 1;
КонецЦикла;
Шаг = Цел(Шаг/2);
ОбработкаПрерыванияПользователя();
КонецЦикла;
Возврат Массив;
КонецФункции
//---}
Вся суть алгоритма сводится к тому, чтобы разбить сложную задачу на маленькие и решить их по отдельности. Выбирается некая опорная точка и все значения которые меньше перебрасываются влево, все остальные вправо. Далее для каждой полученной части выполняетя тоже самое, до тех пор пока дробить части уже нельзя. В конце мы получаем множество отсортированных частей, которые необходимо просто склеить в 1 целое.
-Для создания другого массива необходимо нажать на кнопку "Создание ГСЧ массива ", также можно выбирать необходимый диапазон.
-Для включения динамической анимации необходимо поставить галочку на "Отобразить сортировку в диаграмме". Советую на неэффективных алгоритмах устанавливать галочку при размерности массива до 100 элементов, иначе состаритесь ждать сортировки:)