Шина памяти у старшей модели GeForce GTX 280 составляет 512 бит, что позволило при частоте 2214 МГц памяти GDDR3 добиться пропускной способности в 141,67 ГБ/с – это один из лучших показателей на данный момент. Объём графической памяти равен 1 ГБ, и пока поддерживаются чипы третьего поколения. Поддержка GDDR5, возможно, появится с выходом новых ревизий ядра GT200.
Видеокарта GeForce GTX 260 является аналогом старшей модели, с таким же чипом, но с одним отключённым кластером, уменьшенным до 896 МБ объёмом видеопамяти и урезанной до 448 бит шиной. Данный «обрезанный» вариант GT200 обладает уже 192 потоковыми процессорами, 64 текстурными блоками и 28 ROP.
Видеочипом GT200 поддерживается технология CUDA, то есть видеокарты на базе этого чипа можно использовать для широкого спектра вычислительных задач, а не только для обработки графики. Области применения такого мощного чипа могут быть самыми разнообразными – от астрофизических расчётов до молекулярной динамики. Из более повседневных задач стоит отметить возможность перекодирования видеоданных. Также новые чипы поддерживают физический движок PhysX. Компания NVIDIA уже давно пытается осуществить планы по расчётам физики в играх, но наконец-то от слов она перешла к делу. Для поддержки PhysX достаточно установить последние драйверы на видеокарты серии GTX 2xx.
В технологическом же плане никаких улучшений новое поколение не несёт. Чип производится по техпроцессу 65 нм, как и предшественники, но возросшее количество транзисторов привело к увеличению площади ядра до 576 мм2. Энергопотребление такого технологического «монстра» достигает 240 Вт – это огромная цифра, ещё недавно казавшаяся невозможной. Понятное дело, что охладить такой чип сложно, поэтому блок вывода изображения был вынесен в дополнительный чип NVIO, знакомый нам по видеокартам на базе G80. Кроме двух Dual-Link DVI поддерживаются интерфейсы HDMI и DisplayPort, которые могут быть реализованы через переходники или установлены прямо на плату. Не забыта возможность аппаратного декодирования видеоформатов H.264, VC-1 и MPEG2 благодаря технологии PureVideo HD второго поколения. Видеокарты на базе GT200 поддерживают 3-Way SLI, для чего у плат есть два разъёма MIO, а в качестве интерфейса для связи с материнской платой используется шина PCI Express 2.0.
Технические характеристики
В таблице приведены характеристики всех hi-end-видеокарт NVIDIA, так что можно оценить прогресс в росте вычислительных блоков за последние пару лет. Временно вернувшись к шине 256 бит, NVIDIA снова решила оснащать мощные графические решения более быстрым интерфейсом. Количество шейдерных вычислительных блоков увеличилось ровно в два раза по сравнению с предшественником GeForce 9800GTХ. Однако есть ещё и недавно выпущенный двухчиповый GeForce 9800GX2, основанный на двух ядрах G92, у которого общее количество вычислительных блоков соответствует таковому у нового GeForce GTX 280.
В сегодняшней статье пойдет речь о самом современном и самом мощном в мире графическом чипе от компании NVIDIA под кодовым названием GT200 и о видеоадаптере, выполненным на его основе, GeForce GTX 280. Мы постараемся рассмотреть все наиболее интересные его особенности, новшества и отличия от предыдущих чипов, а также протестировать производительность в равных условиях и сравнить с конкурентами.
Предыстория
Но не все сразу, давайте немного вернемся во времени и отследим историю развития графических чипов. Ни для кого не секрет, что вот уже много лет на рынке графических плат конкурируют две компании: ATI (в настоящем выкупленная AMD и имеющая брэнд AMD Radeon) и NVIDIA . Конечно, присутствуют и мелкие производители, такие как VIA со своими чипами S3 Chrome или Intel с интегрированными видеоадаптерами, но моду всегда диктовала именно конфронтация ATI (AMD) и NVIDIA. И что примечательно, чем сильнее была эта конфронтация или даже не побоимся этого слова «холодная война», тем сильней шагал вперед научно-технический прогресс, и тем большую выгоду получали конечные пользователи – то есть мы с вами. Ведь одним из механизмов борьбы за кошельки пользователей является техническое превосходство продуктов одного из производителей, а другим – ценовая политика и соотношение цена/возможности. Кстати, нередко второй механизм оказывается намного эффективней первого.
Когда одна сторона заметно превосходит конкурента в техническом плане, второму ничего не остается кроме как выдвинуть еще более прогрессивную технологию или же «играть ценами» на уже имеющиеся продукты. Наглядный пример «игры ценами» - конкуренция между Intel и AMD в области центральных процессоров. После анонса архитектуры Core 2, AMD не смогла противопоставить что-то более совершенное и поэтому, чтобы не терять долю рынка, вынуждена была снижать цены на свои процессоры.
Но есть и примеры другого характера. В свое время компания ATI выпустила очень удачную линейку продуктов семейства X1000, которая появилась очень вовремя и очень понравилась многим пользователям, причем, у многих до сих пор стоят видеокарты типа Radeon X1950. NVIDIA тогда не имела в своем распоряжении достойного ответа, и ATI удалось где-то на полугодие просто «выбить» NVIDIA из игры. Но надо отдать должное калифорнийским инженерам, спустя немного времени они выдали на-гора принципиально новое в технологическом плане решение – чип G80 с применением универсальных процессоров. Этот чип стал настоящим флагманом на долгое время, вернул калифорнийской компании пальму первенства и принес рядовым пользователям непревзойденную производительность в играх. Что произошло дальше? А дальше не произошло ничего – ATI (теперь уже под брэндом AMD) не смогла создать что-то более мощное. Ее чип R600 во многом потерпел поражение, заставив канадскую компанию постоянно снижать цены. Отсутствие конкуренции в категории производительных решений позволило NVIDIA расслабится – ведь противников то все равно нет.
Выход нового флагмана
Все интересующиеся 3D-графикой долго ждали настоящего обновления архитектуры G80. Разнообразных слухов о следующем поколении чипов хватало всегда, некоторые из них в дальнейшем подтвердились, но в 2007 году мы дождались лишь минорного архитектурного обновления в виде решений на основе чипов G92. Все выпущенные на их основе видеокарты - неплохие для своих секторов рынка, эти чипы позволили снизить стоимость мощных решений, сделав их менее требовательными к питанию и охлаждению, но энтузиасты ждали полноценного обновления. Тем временем AMD выпустила обновленные продукты на базе RV670, которые принесли ей некий успех.
Но развитие игровой индустрии, новые мощные игры типа Crysis, заставили обе компании разрабатывать новые графические чипы. Только цели у них были разные: у AMD главной целью была борьба за потерянную долю рынка, минимизация затрат на производство и предоставление производительных решений по умеренным ценам, а у NVIDIA была цель сохранить технологическое лидерство, продемонстрировать фантастическую производительность своих чипов.
Сегодня нам представится возможность подробно рассмотреть результаты работы одной из компаний – самый производительный, самый современный чип GT200 производства NVIDIA, представленный компанией 17 июня 2008 года.
Технические подробности
Архитектурно GT200 во многом перекликается с G8x/G9x, новый чип взял у них всё лучшее и был дополнен многочисленными улучшениями. И сейчас мы переходим к рассмотрению особенностей новых решений.
Графический ускоритель GeForce GTX 280
- кодовое имя чипа GT200;
- технология 65 нм;
- 1,4 миллиарда (!) транзисторов;
- унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных;
- аппаратная поддержка DirectX 10.0, в том числе шейдерной модели – Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output);
- 512-битная шина памяти, восемь независимых контроллеров шириной по 64 бита;
- частота ядра 602 МГц (GeForce GTX 280);
- ALU работают на более чем удвоенной частоте 1,296 ГГц (GeForce GTX 280);
- 240 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP 32-бит и 64-бит точности в рамках стандарта IEEE 754(R), выполнение двух операций MAD+MUL за такт);
- 80 блоков текстурной адресации и фильтрации (как и в G84/G86 и G92) с поддержкой FP16 и FP32 компонент в текстурах;
- возможность динамических ветвлений в пиксельных и вершинных шейдерах;
- 8 широких блоков ROP (32 пикселя) с поддержкой режимов антиалиасинга до 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Каждый блок состоит из массива гибко конфигурируемых ALU и отвечает за генерацию и сравнение Z, MSAA, блендинг. Пиковая производительность всей подсистемы до 128 MSAA отсчетов (+ 128 Z) за такт, в режиме без цвета (Z only) – 256 отсчетов за такт;
- запись результатов до 8 буферов кадра одновременно (MRT);
- все интерфейсы (два RAMDAC, Dual DVI, HDMI, DisplayPort, HDTV) интегрированы на отдельный чип.
Спецификации референсной видеокарты NVIDIA GeForce GTX 280
- частота ядра 602 МГц;
- частота универсальных процессоров 1296 МГц;
- количество универсальных процессоров 240;
- количество текстурных блоков – 80, блоков блендинга - 32;
- эффективная частота памяти 2,2 ГГц (2*1100 МГц);
- тип памяти GDDR3;
- объем памяти 1024 МБ;
- пропускная способность памяти 141,7 ГБ/с;
- теоретическая максимальная скорость закраски 19,3 гигапикселей/с;
- теоретическая скорость выборки текстур до 48,2 гигатекселя/с;
- два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600;
- двойной SLI разъем;
- шина PCI Express 2.0;
- TV-Out, HDTV-Out, DisplayPort (опционально);
- энергопотребление до 236 Вт;
- двухслотовое исполнение;
- изначальная рекомендуемая цена $649.
Отдельно отметим, что DirectX 10.1 семейством GeForce GTX 200 не поддерживается. Причиной назван тот факт, что при разработке чипов нового семейства, после консультаций с партнёрами, было принято решение сконцентрировать внимание не на поддержке DirectX 10.1, пока мало востребованного, а на улучшении архитектуры и производительности чипов.
В архитектуре GeForce GTX 280 произошло множество изменений в сравнении с видеокартами GeForce 8800 GTX и Ultra:
- В 1,88 раз увеличено число вычислительных ядер (со 128 до 240).
- В 2,5 раза увеличено число одновременно исполняемых потоков.
- Вдвое увеличена максимальная длина сложного шейдерного кода.
- Вдвое увеличена точность расчетов с плавающей запятой.
- Намного быстрее исполняются геометрические расчеты.
- Объем памяти увеличен до 1 Гб, а шина – с 384 до 512 бит.
- Увеличена скорость доступа к буферу памяти.
- Улучшены внутренние связи чипа между различными блоками.
- Улучшены оптимизации Z-cull и сжатие, что обеспечило меньшее падение производительности в высоких разрешениях.
- Поддержка 10-битной глубины цвета.
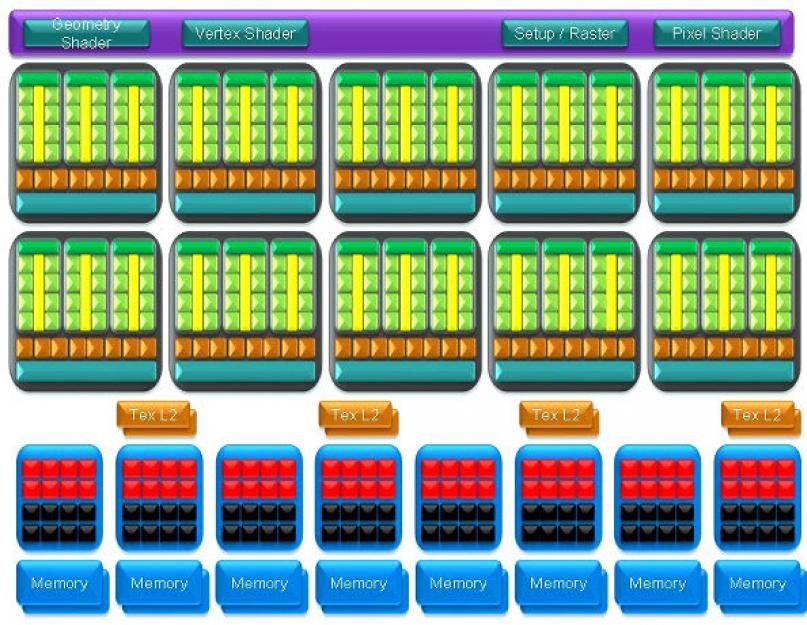
Приведём основную диаграмму чипа GT200:

Основные архитектурные особенности CUDA
С момента анонса архитектуры Core 2 и ее триумфального шествия, появилась мода среди разработчиков рекламировать кроме названий продуктов еще и названия архитектуры, по которой они выполнены. Не исключением стала и NVIDIA, активно рекламирующая свою архитектуру CUDA (Compute Unified Device Architecture) - вычислительная архитектура, нацеленная на решение сложных задач в потребительской, деловой и технической сферах - в любых приложениях, интенсивно оперирующих данными, с помощью графических процессоров NVIDIA. Преимуществом такого подхода является значительное превосходство, на порядок или даже два, графических чипов над современными центральными процессорами. Но, сразу же, всплывает недостаток – для этого надо разрабатывать специальное программное обеспечение. Кстати, NVIDIA проводит конкурс среди разработчиков ПО под архитектуру CUDA.
Видеочип GT200 разрабатывался с прицелом на его активное использование в вычислительных задачах при помощи технологии CUDA. В так называемом расчётном режиме, новый видеочип можно представить как программируемый мультипроцессор с 240 вычислительными ядрами, встроенной памятью, возможностью случайной записи и чтения и гигабайтом выделенной памяти с большой полосой пропускания. Как говорят в NVIDIA, в таком режиме GeForce GTX 280 превращает обычный ПК в маленький суперкомпьютер, обеспечивающий скорость почти в терафлоп, что полезно для многочисленных научных и прикладных задач.
Довольно большое количество наиболее требовательных задач могут быть перенесены с CPU на GPU при помощи CUDA, и при этом удастся получить заметный прирост производительности. На картинке показаны примеры применения CUDA в реальных задачах, приведены цифры, показывающие кратность прироста производительности GPU по сравнению с CPU.

Как видите, задачи самые разнообразные: перекодирование видеоданных, молекулярная динамика, астрофизические симуляции, финансовые симуляции, обработка изображений в медицине и т.п. Причём, приросты от переноса расчётов на видеочип получились порядка 20-140-кратных. Таким образом, новый видеочип поможет ускорить множество разных алгоритмов, если их перенести на CUDA.
Одним из бытовых применений расчётов на GPU можно считать перекодирование видеороликов из одного формата в другой, а также кодирование видеоданных в соответствующих приложениях по их редактированию. Компания Elemental выполнила задачу переноса кодирования на GPU в своём приложении RapidHD, получив следующие цифры:

Мощнейший GPU GeForce GTX 280 отлично показывает себя в этой задаче, прирост скорости по сравнению с быстрейшим центральным процессором составляет более 10 крат. Кодирование двухминутного видеоролика заняло 231 секунду на CPU и всего лишь 21 секунду на GT200. Важно, что применение GPU позволило добиться выполнения данной задачи не просто в реальном времени, но даже и ещё быстрее!
Впрочем, интенсивные вычисления с помощью современных графических видеокарт давно не новость, но именно с появлением графических процессоров семейства GeForce GTX 200 компания NVIDIA ожидает значительного повышения интереса к технологии CUDA.
С точки зрения технологии CUDA новый графический чип GeForce GTX 280 это ни что иное как мощный многоядерный (сотни ядер!) процессор для параллельных вычислений.
NVIDIA PhysX
Это, пожалуй, наиболее интересный аспект новых видеоадаптеров NVIDIA для обычных пользователей. Хотя он относится не только к новым решениям на основе GT200, но и ко всем видеокартам семейства GeForce 8 и GeForce 9.
В современных играх грамотно реализованные физические взаимодействия играют важную роль, они делают игры более интересными. Почти все физические расчёты требовательны к производительности, и соответствующие алгоритмы требуют больших объемов вычислений. До определённого времени эти расчёты выполнялись только на центральных процессорах, потом появились физические ускорители компании Ageia, которые хоть и не получили широкого распространения, но заметно оживили активность на этом рынке. Приобрести такие ускорители могли лишь единицы игроков-энтузиастов.
Но все изменилось, когда компания NVIDIA купила Ageia и вместе с этим получила всю необходимую информацию о PhysX. Именно информацию, так как сами аппаратные устройства ее не интересовали. Надо отдать должное NVIDIA – она взяла правильный курс и приспособила физический движок PhysX под свою архитектуру CUDA и теперь каждый владелец видеокарты с такой архитектурой получает аппаратное ускорение физических процессов в играх путем простого обновления драйверов.
При работе с мощным видеочипом, PhysX может предложить много новых эффектов, таких как: динамические эффекты дыма и пыли, симуляция тканей, симуляция жидкостей и газов, погодные эффекты и т.п. По заявлениям самой NVIDIA, новые видеокарты GeForce GTX 280 способны работать в 10 и более раз быстрей, чем 4-х ядерные процессоры при работе с PhysX. В настоящее время поддержка PhysX реализована в более чем 150 играх.
Улучшенная технология управления питанием
Новый видеочип использует улучшенное управление питанием, по сравнению с предыдущим поколением чипов NVIDIA. Он динамически изменяет частоты и напряжения блоков GPU, основываясь на величине их загрузки, и способен частично отключать некоторые из блоков. В итоге, GT200 значительно снижает энергопотребление в моменты простоя, потребляя около 25 ватт, что очень мало для GPU такого уровня. Решение поддерживает четыре режима работы:
- режим простоя или 2D (около 25 ватт);
- режим просмотра HD/DVD видео (около 35 ватт);
- полноценный 3D режим (до 236 ватт);
- режим HybridPower (около 0 ватт);
Для определения загрузки, в GT200 используются специальные блоки, анализирующие потоки данных внутри GPU. На основе данных от них, драйвер динамически устанавливает подходящий режим производительности, выбирает частоту и напряжение. Это оптимизирует потребление электроэнергии и тепловыделение от карты.
С новшествами и особенностями мы ознакомились – в этом плане NVIDIA добилась поставленной цели, представив совершенно новый графический чип. Но осталась и вторая цель – доказать превосходство в плане производительности. Для этого мы рассмотрим чип GT200 уже воплощенный в виде готовой видеокарты, проведем ее тестирование и сравним всю заложенную в нее мощь с флагманами предыдущего поколения и решениями конкурентов.
Видеокарта на NVIDIA GeForce GTX 280

Подогрев интерес к графическому ускорителю, перейдём непосредственно к его обзору, тестированию, сравнению и, естественно, к разгону. Но для начала еще раз спецификация, теперь уже готового серийного ускорителя.
|
Производитель |
|
|
Название |
ENGTX280/HTDP/1G/A |
|
Графическое ядро |
NVIDIA GeForce GTX 280 (G200-300-A2) |
|
Конвейера |
240 унифицированных потоковых |
|
Поддерживаемые API |
DirectX 10.0 (Shader Model 4.0) |
|
Частота ядра (шейдерного домена), МГц |
|
|
Объем (тип) памяти, МБ |
|
|
Частота (эффективная) памяти, МГц |
|
|
Шина памяти |
512-разрядная |
|
Стандарт шины |
PCI Express 2.0 x16 |
|
Максимальное разрешение |
До 2560 x 1600 в режиме Dual-Link DVI |
|
2x DVI-I (2x VGA через переходники) |
|
|
Поддержка HDCP |
Есть |
|
Драйверы |
Свежие драйверы можно скачать с: |
|
Сайт производителя |


Поставляется видеокарта в достаточно габаритной двойной картонной коробке. Но, в отличие от упаковки предыдущих топовых ускорителей, эта чуть меньше по размерам и лишена пластиковой ручки, видимо ASUS начала экономить картон.

Но одна из боковых сторон упаковки все же раскрывается в виде книжки, рассказывая покупателю об экстремальных возможностях графического ускорителя и фирменных технологий.

На обратной стороне упаковки, кроме перечисления общих возможностей видеокарты и фирменного программного обеспечения, заботливо указана информация о минимальных требованиях к система, в которую будет установлена ASUS ENGTX280/HTDP/1G/A. Наиболее интересной и критичной частью является рекомендация использовать минимум 550 Вт блок питания, который способен выдать до 40 А по линии 12V. Также БП должен обеспечить необходимое число выходов питания, к которым и будут подключаться переходники питания.

Рядом указана и верная схема подачи питания на видеокарту. Обращаем внимания, что для 8-контактного разъема используется переходник с двух 6-контактных PCI Express, а не с пары периферийных, как это можно было увидеть ранее при установке ускорителей AMD/ATI. Учитывая энергопотребление GeForce GTX 280, к питанию придется подойти более тщательно.
Внутри красочной и информативной обложки, т.е. внешней коробки, находится полностью черная внутренняя, которая в свою очередь поделена на еще несколько отдельных боксов и ниш, вмещающих всю комплектацию.

Комплект поставки является более чем достаточным для полноценного использования ускорителя и помимо самого видеоадаптера включает в себя:
два диска с драйверами, утилитами и электронной версией руководства пользователя;
бумажное руководство по быстрой установке видеокарты;
фирменный «кожаный» коврик для мыши;
фирменную папку для дисков;

- переходник с DVI на VGA.
переходник с 2-x Molex (питания периферийных устройств) на 6-pin питание PCI-Express;
переходник с 2-х 6-контактных PCI Express на 8-контактный разъем питания;
удлинитель 8-контактного разъема питания;
переходник с 8-контактного разъема на 6-контактный PCI Express;
переходник c S-Video TV-Out на покомпонентный HDTV-Out;

Видеокарта на GeForce GTX 280 имеет такие же габариты, как ускорители на NVIDIA GeForce 9800 GX2 , а с NVIDIA GeForce 9800 GTX она даже сходна внешне, при взгляде на фронтальную часть, которая полностью скрыта под «примелькавшейся» системой охлаждения. В общем, разработкой всех этих ускорителей и их кулеров занимались примерно одни и те же инженеры, поэтому внешнее сходство не удивительно.
Сразу же отметим, что совершенно не важно кто является конечным продавцом ускорителя, выпуском топовых видеокарт занимается непосредственно сама NVIDIA на производственных мощностях партнеров. Конечные реализаторы занимаются только упаковкой готовых ускорителей и вправе рассчитывать только на возможность прошить свой фирменный BIOS, немного разогнать видеокарту или заменить кулер на альтернативный.

Обратная сторона видеокарты теперь скрыта за металлической пластиной, которая, как выяснилось в процессе разборки, играет роль радиатора для чипов памяти, располагающихся теперь с обеих сторон печатной платы.

Сверху видеокарты, почти у самого края, находятся разъемы подключения дополнительного питания. Имея энергопотребление до 236 Вт, ускорителю необходимо надежное питания, которое обеспечивается одним 6-контактным разъемом PCI Express и одним 8-контактным, как и на двухчиповом GeForce 9800 GX2.


Рядом с разъемами питания под резиновой заглушкой спрятан цифровой аудиовход SPDIF, который должен обеспечить микширование аудиопотока с видеоданными при использовании выхода HDMI.

С другой стороны тоже под заглушкой находится двойной разъем SLI, что обеспечивает поддержку 3-Way SLI и позволяет собрать компьютер с невероятно производительной видеосистемой.

За вывод изображения отвечают два DVI, которые с помощью переходников могут быть преобразованы в VGA или HDMI, а также TV-Out с поддержкой HDTV. Рядом с разъемом телевизионного выхода, возле отверстий вывода нагретого воздуха, расположен индикатор питания видеокарты, отображающий его статус в данный момент.


Под системой охлаждения находится печатная плата, которая во многом напоминает предыдущие топовые решения на G80 (например GeForce 8800 Ultra), только теперь, вследствие доведения объема видеопамяти до 1 ГБ, чипы располагаются с обеих сторон печатной платы и не так плотно. Плюс усилена система питания, чтобы обеспечить работу столь мощного ускорителя.


Основным потребителем электроэнергии является чип NVIDIA G200-300 второй ревизии, который и именуют GeForce GTX 280. Именно он содержит 240 унифицированных потоковых процессоров, которые работают на тактовой частоте 1296 МГц при работе остального ядра на частоте 602 МГц. Обмен данными с видеопамятью производится по 512-битной шине. Этот графический процессор способен обеспечить невероятную производительность при обработке графических данных, но узлы работы с внешними интерфейсами в него не поместились.

За все входы и выходы отвечает отдельный чип NVIO2, причем расположение его «вдали» от основного процессора позволяет говорить об отсутствии различных наводок и помех, что должно обеспечить отличное изображение даже на аналоговых мониторах.

В качестве микросхем памяти используется продукция Hynix. Микросхемы при рабочем напряжении 2,05 В имеют время отклика 0,8 мс, т.е. обеспечивают работу видеопамяти на эффективной частоте до 2200 МГц. На этой же тактовой частоте микросхемы памяти и функционируют.

Отдельно расскажем о кулере. Система охлаждения имеет привычную для NVIDIA конструкцию и занимает соседний с видеокартой слот расширения, обеспечивая отвод нагретого воздуха за пределы корпуса.


Интересно отметить, что за отвод тепла отвечают не только алюминиевые пластины радиатора, но и весь корпус кулера, что хорошо видно по соединению тепловых трубок с ним. Поэтому проветривание видеокарты любым удобным способом может обеспечить заметное улучшение ее температурного режима. А мыслей об улучшении охлаждения мало кому из владельцев этого «горячего монстра» удастся избежать. Уже непродолжительная серьезная нагрузка на видеокарту заставляет турбину раскручиваться до максимальных 1500 об/мин, что заметно нарушает акустический комфорт. Но даже это не избавляет ускоритель от значительного нагрева.

В закрытом хорошо вентилируемом корпусе температура графического процессора перевалила за отметку 100°C, а воздух, выдуваемый системой охлаждения, навел на мысль, что зря NVIDIA представила этот графический процессор к лету – надо было к зиме, чтобы пользователь, купивший очень дорогой ускоритель, мог экономить на отоплении.

Чтобы видеокарта не перегрелась, пришлось открыть корпус и направить в его сторону бытовой вентилятор – это обеспечило снижение на 14 градусов температуры GPU и на 9 градусов всей видеокарты. Именно в таком положении производились все тесты и последующий разгон. Но при открытом корпусе штатный кулер показался еще немного громче.

А вот при отсутствии 3D нагрузки температура видеокарты значительно снижается, что достигается еще и дополнительным снижением рабочих частот и уменьшением напряжения – в режиме 2D видеокарта потребляет на 200 Вт меньше. Этот же факт позволяет медленнее вращаться и турбине кулера, что делает его практически беззвучным.
При тестировании использовался Стенд для тестирования Видеокарт №1
Выберите с чем хотите сравнить GeForce GTX280 1GB ASUS













Среди одночиповых ускорителей решение на NVIDIA GeForce GTX 280, несомненно, занимает лидирующее положение, но вот у двухчиповых ускорителей и multi-GPU конфигураций из карт предыдущего поколения ASUS ENGTX280/HTDP/1G/A выигрывает не всегда, особенно в условиях использования не самого производительного процессора.
2-ядерный процессор против 4-ядерного
А что даст использование более производительного процессора, например четырехъядерного? Именно такие процессоры сейчас часто советуют владельцам высокопроизводительных видеокарт.

Для того чтобы проверить на сколько четырехъядерный процессор окажется предпочтительнее, мы заменили Intel Core 2 Duo E6300 @2800 на Intel Core 2 Quad Q9450 @2800.
|
Тестовый пакет |
Intel Core 2 Duo E6300 @2800 |
Intel Core 2 Quad Q9450 @2800 |
Прирост производительности, % |
|
Как видите, прирост производительности на четырехъядерном процессоре действительно есть, и порою немалый, но именно в высоких разрешениях, для работы в которых и покупают дорогие видеокарты, ускорение наименьшее.
Intel Core 2 Quad против AMD Phenom X4
Еще одной часто озвучиваемой рекомендацией относительно комплектации производительной игровой системы является предпочтение процессорам Intel, как более быстрым. Что ж, попробуем проверить на практике, насколько игровая система на базе процессора AMD Phenom X4 окажется медленнее, если такой факт будет иметь место.

Для «забега» в равных условиях мы разогнали процессор AMD Phenom X4 9850 Black Edition до частоты 2,8 ГГц, что достаточно легко делается только изменением множителя, и провели серию тестов на новой платформе ASUS M3A32-MVP DELUXE/WIFI-AP . При этом оперативная память работала в режиме DDR2-800 с такими же таймингами, как и на системе с процессором Intel Core 2 Quad Q9450.
|
Тестовый пакет |
AMD Phenom X4 9850 @2800 |
Intel Core 2 Quad Q9450 @2800 |
Разность производительности, % |
|
|
Serious Sam 2, Maximum Quality, AA4x/AF16x, fps |
||||
|
Call Of Juarez, Maximum Quality, NO AA/AF, fps |
||||
|
Call Of Juarez, Maximum Quality, AA4x/AF16x, fps |
||||
|
Prey, Maximum Quality, AA4x/AF16x, fps |
||||
|
Crysis, Maximum Quality, NO AA/AF, fps |
||||
|
Crysis, Maximum Quality, AA4x/AF16x, fps |
||||
Итак, при работе на одинаковых тактовых частотах действительно система с процессором Intel Core 2 Quad оказывается немного быстрее аналогичной с процессором AMD Phenom X4. При этом, чем выше разрешение и больше требований к качеству изображения, тем меньше превосходство процессоров Intel. Конечно, используя самую дорогую и производительную видеокарту, маловероятно, что покупатель будет экономить на процессоре и материнской плате, но в других условиях мы бы не рекомендовали «однозначно Intel Core 2 Quad», а предложили бы хорошенько взвесить варианты систем с процессорами от AMD и Intel.
Разгон
Для разгона видеокарты мы использовали утилиту RivaTuner, при этом, как было отмечено выше, корпус был открыт, а дополнительный приток свежего воздуха к видеокарте обеспечивался бытовым вентилятором.

Частота растрового домена в результате разгона поднялась до отметки в 670 МГц, что на 70 МГц (+11,67%) выше значения по умолчанию. Разгон шейдерного домена оказался чуть лучше и частотные показатели, в отличие от значений по умолчанию, возросли на 162 МГц (+12,5%). А вот разгон памяти превзошёл все ожидания. Стабильная работа была отмечена на эффективной частоте почти 2650 МГц, что на 430 МГц (+19,5%) выше номинальной. Отмечаем отменный разгонный потенциал тестируемого ускорителя, особенно видеопамяти.
Теперь посмотрим, как разгон одиночной видеокарты сказывается на производительности:
|
Тестовый пакет |
Стандартные частоты |
Разогнанная видеокарта |
Прирост производительности, % |
|
|
Serious Sam 2, Maximum Quality, AA4x/AF16x, fps |
||||
|
Call Of Juarez, Maximum Quality, AA4x/AF16x, fps |
||||
|
Prey, Maximum Quality, AA4x/AF16x, fps |
||||
|
Crysis, Maximum Quality, AA4x/AF16x, fps |
||||
Только в наиболее тяжелых видеорежимах можно будет увидеть прирост производительности от разгона. Такой результат был достаточно предсказуем. При этом, вполне резонно будет заметить, что ограничивающим фактором почти во всех тестах стал процессор. Но настоятельно рекомендовать владельцам ускорителей на NVIDIA GeForce GTX 280 только самые быстрые процессоры мы не будем, т.к. даже с двухъядерным процессором, который работает на частоте 2,8 ГГц, а может и меньше, можно будет совершенно комфортно играть в практически любые игры на самых максимальных настройках в высоких разрешениях. В таких условиях можно будет увидеть даже прирост от разгона. Но, конечно же, при возможности, на процессоре экономить не стоит, раз не экономили на видеокарте и блоке питания.
Выводы
Вынуждены признать, что все видеокарты на основе GeForce GTX 280 сегодня являются самыми производительными одночиповыми графическими ускорителями, которые способны обеспечить достаточную производительность в любой современной игре. Но, с другой стороны, это и самые дорогие современные видеокарты и самые требовательные к энергообеспечению и, в общем-то, самые «прожорливые» и горячие. То есть GeForce GTX 280 получился во всех отношениях самый-самый, и в плохих и хороших.
Мы говорим обобщенно об ускорителях на GeForce GTX 280, хотя героем обзора является ASUS ENGTX280/HTDP/1G/A, поскольку большинство из них являются точно такими же референсными образцами, отличающимися друг от друга только наклейками, комплектацией и упаковкой. Поэтому выбирая GeForce GTX 280 от ASUS, покупатель получает расширенную комплектацию с парой фирменных бонусов и широкую сеть сервисных центров, а в остальном превосходства над предложениями конкурентов нет.
Достоинства:
- очень высокая производительность в игровых приложениях;
- поддержка DirectX 10.0 (Shader Model 4.0) и OpenGL 2.1;
- поддержка технологий NVIDIA CUDA и NVIDIA PhysX;
- поддержка технологии 3-Way SLI;
- хороший разгонный потенциал.
Недостатки:
- система охлаждения занимает 2 слота, не отличается высокой эффективностью и комфортной тишиной работы;
- довольно высокая стоимость графического ускорителя.
Выражаем благодарность фирме ООО ПФ Сервис (г. Днепропетровск) за предоставленную для тестирования видеокарту.
При написании статьи были использованы материалы с сайта http://www.ixbt.com/ .
Статья прочитана 19856 раз(а)
| Подписаться на наши каналы | |||||
|
|
|
||||
Введение
Прошло полтора года - столько времени GeForce 8800 GTX оставалась на позициях, которые nVidia называла high-end GPU. Конечно, через шесть месяцев после объявления и (какое совпадение!) перед выходом R600 мы получили 8800 Ultra с чуть более высокими тактовыми частотами, но никаких революционных изменений в ней не было. Затем, два с половиной месяца назад, появление 9800 GTX пробудило надежды существенного прироста производительности, но, как оказалось, карта давала весьма ограниченный прирост по сравнению со старой доброй GTX и уступала версии Ultra. nVidia пришлось очень нелегко в том, чтобы убедить владельцев новых видеокарт в существенном преимуществе дополнительных мегагерц или вообще устанавливать два GPU на одну видеокарту.
Наконец, nVidia снизошла и услышала наши молитвы: GTX 280 первая видеокарта на действительно доработанной архитектуре G8x. Теперь мы уже знаем принцип работы компании: представить новую архитектуру на проверенном техпроцессе. Из-за очень большого числа транзисторов чип дорого обходится в производстве, карты получаются тоже очень дорогими, но захват рынка всё же происходит. Затем, в последующие годы, nVidia совершенствует свою архитектуру на всех сегментах рынка, используя более тонкий техпроцесс, но менее оптимизированный на высокие тактовые частоты. Наконец, когда новый техпроцесс будет освоен, nVidia переносит его и на high-end, который к тому времени становится более доступным. Мы видели подобный подход с G70/G71 и G80/G92, теперь история повторяется с GT200 - настоящий "монстр" с 1,4 млрд. транзисторов, изготавливающийся по 65-нм техпроцессу.

Новое поколение, новое название. Похоже, переход за номер "10 000" в линейке производителям не нравится. Если ATI решила эту проблему, введя римские цифры, nVidia решила полностью изменить номенклатуру карт. Теперь мы получили GeForce 200 GTX. Но возникает любопытный вопрос: что случилось с картой GeForce 100 GTX?
| GTX 260 | GTX 280 | |
| Частота GPU | 576 МГц | 602 МГц |
| Частота памяти | 999 МГц | 1 107 МГц |
| Частота потоковых процессоров | 1 242 МГц | 1 296 МГц |
| Число потоковых процессоров | 192 | 240 |
| Число текстурных блоков | 64 | 80 |
| Число блоков растровых операций (ROP) | 28 | 32 |
| Контроллер памяти | 448 битов (7 каналов по 64 бита) | 512 битов (8 каналов по 64 бита) |
| Тип памяти | GDDR3 | GDDR3 |
Как мы видим, nVidia представляет новую архитектуру, но её нельзя назвать совсем уж "с нуля". Зарождение G80 началось с "чистой страницы", но затем архитектура доказала свою высокую эффективность. Целью GT200 было исправить все "ошибки молодости" архитектуры, а также подготовить её к будущим играм. Мы получили примерно то, чем G70 стал для NV40, внеся множество мелких улучшений, а также шагнув вперёд по вычислительной мощности. Так получилось и в случае 8800 GTX с мощностью вычислений с плавающей запятой 518 GFlops, а GTX 280 уже приблизилась к терафлопу - с впечатляющей мощностью 933 GFlops. В реальности отрыв ещё больше, поскольку значение 518 GFlops у G80 рассчитано на выполнение двух операций с плавающей запятой за такт (одна MAD и одна MUL) - что, из-за ограничений G80, на практике достичь было невозможно. С выпуском GT200 nVidia гарантирует, подтверждая тестами, что проблемы решены. Чтобы почти удвоить вычислительную мощность предыдущего GPU, nVidia ощутимо подняла число мультипроцессоров - с 16 до 30.
nVidia и AMD соглашаются друг с другом в том, что будущим играм потребуется существенно более высокая вычислительная производительность по сравнению с текстурированием, поэтому вряд ли удивляет то, что число текстурных блоков увеличилось скромнее. С 64 у 9800 GTX, мы получили увеличение GTX 280 до 80 (и если сравнивать 8800 GTX и GTX 280 на этот раз, мы ушли от теоретического соотношения арифметических инструкций к числу отфильтрованных текселей 14,1:1 на 19,4:1). Что же это значит на практике?
Для оценки арифметической производительности можно использовать синтетические тесты с процедурными текстурами (они требуют немало вычислений). Конечно, nVidia нравится 3DMark Vantage и его тест Perlin Noise, где мы замерили прирост производительности 129% при переходе от 9800 GTX до GTX 280. Но, учитывая важность, которую nVidia приписывает этому тесту, и лёгкость, с которой можно оптимизировать под него новые драйверы (кстати, по-разному для GTX 280 и 9800 GTX), чтобы тест делал то, что от него хочет производитель (см. на эту тему), давайте проанализируем результаты забытой версии RightMark 3D с Pixel Shader 2.0 (Direct3D 9.0). Поскольку результаты разных тестов существенно различаются по абсолютным значениям, мы выразили результаты в процентах и взяли за основу 9800 GTX.

Как видим, улучшения намного скромнее, хотя они присутствуют - меньше для процедурных шейдеров и больше для сложных эффектов освещения, где мы наблюдаем прирост до 78%. Теперь давайте перейдём к версии 2 пакета RightMark и его шейдерам 4.0 (Direct3D 10.0).

Здесь прирост виден, но он ближе к повышению приведённого выше соотношения арифметических расчётов с плавающей запятой к фильтрации текселей, чем к числам, которые даёт 3DMark Vantage.
ROP
С блоками растровых операций (ROP) нас ждал приятный сюрприз - их число возросло с 24 у G80 (16 у G92) до 32. Чтобы обеспечить их загрузку, nVidia использовала 512-битную шину, которая, учитывая характеристики GPU, явно будет здесь более полезна, чем на R600.

Мы наблюдаем 78% прирост производительности GTX 280 над 9800 GTX, что близко к теоретическим значениям, поскольку увеличение ROP сопровождало падение частоты (675 МГц у 9800 GTX).
И поскольку мы начали говорить об AMD, следует отметить, что этой компании нужно как можно быстрее пересмотреть свои high-end GPU, которые ограничиваются 16 текстурными блоками и 16 ROP ещё с объявления X800 в 2004 году! Если GPU AMD остаются конкурентоспособными по вычислительной мощности, с другой точки зрения, их серьёзно обходит nVidia, которые вносит улучшения с каждым новым поколением. Будем надеяться, что новая архитектура AMD, которая будет представлена совсем скоро, закроет эту брешь.
Кстати, приведённые результаты HD 3870 X2 показывают, что пусть ATI уступает по числу блоков на чип, не забывайте, что новая стратегия производителя заключается в использовании карт на двух GPU против карт на одном GPU у nVidia! По этой причине, а также из-за чуть более высокой (825 МГц) частоты, 3870 X2 лидирует в этом тесте, синтетическом, но релевантном.
А что насчёт Direct3D 10.1?
После кампании, которую nVidia уже некоторое время проводит по поводу его бесполезности, нас вряд ли удивило отсутствие поддержки нового API Microsoft в 200 GTX. Нас это не удивило, но огорчило. По информации nVidia, поддержка API изначально планировалась, но опрошенные разработчики были уверены в том, что она "не важна". Конечно, Direct3D 10.1 не добавляет ничего революционного - как мы уже отметили в обзоре карт Radeon HD 38x0 , однако корректирует недостатки, присутствующие в спецификациях Direct3D 10. Да и есть несколько новых интересных функций, которые могут стать полезными для движков рендеринга, такие как отложенное затенение (deferred shading), которое становится всё более популярным, а также алгоритмы для рендеринга прозрачных поверхностей без сортировки.
Да, это может показаться несколько избыточным в данной ситуации, когда Direct3D 10 ещё не показал своего превосходство на девятой версией, но объяснения nVidia кажутся невнятными. Мысль о бесполезности Direct3D 10.1 в данное время нельзя назвать ложной (хотя Assassin"s Creed доказывает обратное), однако мы попадаем в замкнутый круг - без поддержки со стороны nVidia вполне очевидно, что разработчики не будут серьёзно относиться к ATI. Мы уже наблюдали подобную ситуацию и раньше, но она была обратной: какие разработчики использовали Shader Model 3, когда вышла NV40? Особенно на первых GeForce 6, где основные функции, подобные Vertex Texture Fetch и динамическому ветвлению в шейдерах, были слабо реализованы. Но, конечно, в то время nVidia считала себя авангардом 3D API.
Поэтому наше мнение с предыдущей статьи не изменилось. Пусть даже DirectX 10.1 нельзя использовать прямо сейчас, нам нравится, когда в новых 3D-процессорах используются последние технологии, с которыми могут знакомиться разработчики. Мы ругали ATI в то время, а теперь нашу критику получила nVidia.
Архитектура в деталях
Архитектура SIMT?
Вы наверняка знакомы с терминами SIMD (одна инструкция, много данных) и MIMD (много инструкций, много данных), но в GT200 nVidia описывает мультипроцессоры шейдеров как "блоки SIMT". Чем же они являются на самом деле? Сокращение расшифровывается как Single Instruction Multiple Threads (одна инструкция, много потоков), и основное отличие от режима SIMD заключается в том, что обрабатываемые векторы не имеют чётко заданной ширины. При достаточном числе потоков процессор работает как скалярный. Чтобы разобраться, давайте вспомним, как блоки пиксельных шейдеров работали в предыдущих архитектурах.
Растеризатор генерирует квады - квадраты пикселей 2x2, где каждый пиксель задаётся вектором с четырьмя значениями с плавающей запятой одинарной точности (R, G, B, A) или (X, Y, Z, W) - наиболее часто используемый формат в 3D-вычислениях. Квады затем поступают в потоковые процессоры (ALU), которые работают в 16-канальном режиме SIMD, то есть одинаковая инструкция применяется ко всем 16 числам с плавающей запятой. Конечно, мы несколько всё упростили, но принцип понят можно; на самом деле у GeForce 6 и 7 есть режим co-issue для выполнения двух инструкций на вектор.
После G80 данный режим работы был изменён - растеризатор по-прежнему генерировал квады, которые записывались в буфер. Когда 8 квадов (32 пикселей, "warp" по терминологии CUDA) накапливались в буфере, они могли выполниться мультипроцессором в режиме SIMD. В чём разница? В том, как теперь организуются данные: вместо работы над четырьмя векторами по четыре операции с плавающей запятой, которые могут выглядеть, например, (R, G, B, A, R, G, B, A, R, G, B, A, R, G, B, A), мультипроцессор работает над векторами с 32 числами с плавающей запятой, каждое из которых представляет одинаковый компонент из 32 потоков: например, (R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R), затем (G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G, G) и т.д.
В программировании SIMD первое выравнивание данных называется AoS (Array Of Structures), а второе - SoA (Structure of Arrays). Вторая организация даёт более высокую производительность. Если будет достаточно данных для заполнения вектора, процессор, с точки зрения программиста, выглядит как скалярный блок, так как SIMD-блоки всегда используются на 100% независимо от ширины обрабатываемых данных. Следовательно, AoS достигает пиковой производительности, только в том случае, когда одинаковая инструкция накладывается на все четыре компонента каждого вектора.
Нажмите на картинку для увеличения.
Каждый из восьми TPC (Texture Processor Clusters, кластеры текстурных процессоров) оснащён текстурным блоком и двумя потоковыми мультипроцессорами Streaming Multiprocessors (SM). У GT200 nVidia увеличила число блоков TPC до 10, каждый по-прежнему оснащён текстурным блоком, но уже тремя мультипроцессорами.
 |
Нажмите на картинку для увеличения.
Это изменение свидетельствует об изменении ориентации современных шейдеров, акцент которых ставится на арифметические инструкции. Текстурные блоки каждого кластера TPC используют такую же модель, как у G84 и G92 - адресная мощность такая же, как и мощность фильтрации, в отличие от G80, где мощность фильтрации в два раза превышала адресную. Так, в простом режиме фильтрации текстур RGBA8, текстурные блоки G84/G92/GT200 в два раза производительнее G80. С более продвинутыми режимами фильтрации или текстурами RGBA16, изменение не влияет на результат.
Есть и другое улучшение, которое относится к GT200: nVidia утверждает, что теперь используется более эффективная система диспетчеризации для текстурных операций, что должно приблизить результат к пиковой производительности по сравнению с G92. Давайте посмотрим на результаты Fillrate Tester.

Переход с 64 на 80 текстурных блоков, с учётом разницы в частоте GPU, должен дать GTX 280 преимущество всего 11% над 9800 GTX. Но мы замерили 43% при использовании четырёх текстур и 118% при использовании двух! Улучшение в системе диспетчеризации вряд ли сможет объяснить разницу. Однако увеличение числа ROP (удвоение) тоже сыграло свою роль. В любом случае, вполне очевидно, что GTX 280 намного ближе к значениям теоретической скорости заполнения с одной или двумя текстурами (97%), чем 9800 GTX (между 80 и 91%), означая, что улучшения nVidia оправдали себя на практике. Как мы уже объясняли выше, плата AMD с двумя GPU, которая ещё и работает на более высоких тактовых частотах по сравнению с nVidia, всего на 32% уступает GTX 280 с четырьмя текстурами.
Теперь давайте посмотрим на результаты теста текстурирования RightMark3D 2.0 PS 4.0.

Результат первого теста шейдеров (Fur, мех) удивляет: 14% прирост, что немного, учитывая оптимизацию смешения, геометрических шейдеров и скорости заполнения, хотя всё зависит от реализации шейдеров. С другой стороны, 59% прирост в тесте Steep Parallax Mapping более впечатляет, на уровне с нашими ожиданиями.
Кроме увеличения числа, каждый мультипроцессор прошёл через несколько оптимизаций. Первая заключается в увеличении числа активных потоков на мультипроцессор - с 768 до 1 024 (с 24 32-поточных "варпов" до 32). Большее число потоков особенно полезно для компенсации задержек текстурных операций. В масштабах GPU мы получаем увеличение числа активных потоков с 12 288 до 30 720.
Число регистров на мультипроцессор удвоилось - с 8 192 до 16 384. С сопутствующим повышением числа потоков, число регистров, которые одновременно может использовать поток, увеличилось с 10 до 16. На G8x/G9x наш тестовый алгоритм использовал 67% вычислительных блоков; на GT200 это число должно быть 100%. Учитывая два текстурных блока, производительность должна быть существенно выше, чем у G80, которую мы тоже взяли для теста. К сожалению, CUDA 2.0 требует драйвер, который всё ещё находится в состоянии бета-версии, он не распознаёт GeForce 200 GTX. Когда в основной ветке драйверов появится поддержка, мы повторим тест.
 |
Нажмите на картинку для увеличения.
Это не единственное улучшение, которое nVidia сделала со своими мультипроцессорами: компания заявила об оптимизации режима dual-issue. Как вы помните со времён G80, мультипроцессоры предположительно позволяют выполнять две инструкции за такт: одну MAD и одну MUL с плавающей запятой. Мы упомянули "предположительно", поскольку в то время мы не смогли проверить это поведение в наших синтетических тестах - мы не знаем, с чем было связано это ограничение, с аппаратной поддержкой или с драйверами. Несколько месяцев спустя, после нескольких версий драйверов, мы знаем, что MUL не всегда легко отделить на G80, так что проблема, скорее всего, аппаратная.
Но как работает режим dual-issue? Во времена G80 nVidia не дала детали, но затем, изучая патент, мы узнали чуть больше о способе выполнения инструкций на мультипроцессорах. Начнём с того, что патент чётко выделяет, что мультипроцессоры могут запускать выполнение только одной инструкции на каждый такт GPU. Так где же знаменитый режим dual-issue? Фактически, он сводится к специализации "железа": одна инструкция использует два такта GPU (четыре такта потокового процессора/ALU), её можно применить к "варпу" (выполнение 32 потоков на 8-канальных блоках SIMD), но начало конвейера мультипроцессора может запускать выполнение только одной инструкции каждый такт, если они относятся к разным типам: MAD в одном случае, SFU в другом.
Кроме трансцендентных операций и интерполяции значений каждой вершины, SFU способны выполнять умножение с плавающей запятой. Чередуя выполнение инструкции MAD и MUL, можно получить "перехлёст" времени выполнения инструкций. Таким образом, каждый такт GPU даёт результат MAD или MUL в "варпе" - то есть 32 скалярных значения. По описанию nVidia можно ожидать, что вы получите MAD и MUL каждые два такта GPU. На самом деле, результат такой же, но с аппаратной точки зрения начало конвейера существенно упрощается, он поддерживает подачу инструкций на выполнение по одной каждый такт.
 |
Нажмите на картинку для увеличения.
То, что ограничивало подобную функцию на G8x/G9x, было исправлено на GT200? nVidia, к сожалению, не уточняет. Представители компании просто говорят о том, что они доработали такие блоки, как выделение регистров, планирование и запуск инструкций на выполнение. Но мы сделали предположение, близкое к реальности. Теперь давайте посмотрим, насколько изменения nVidia повлияли на практику - на синтетический тест GPUBench.

В целях сравнения мы добавили результаты 9800 GTX. На этот раз всё понятно: вы можете видеть более высокую скорость выполнения инструкций MUL по сравнению с инструкциями MAD. Но мы по-прежнему далеки от удвоения значений, примерно 32% по сравнению с MAD. Но и то хорошо. Следует отметить, что результаты для инструкций DP3 или DP4 не следует принимать во внимание, поскольку числа не были постоянными. То же самое касается инструкций POW, что, вероятно, связано с проблемой драйверов.
Последнее изменение, сделанное с потоковыми мультипроцессорами, касается поддержки двойной точности (64-битное число с плавающей запятой вместо 32-битного). Честно говоря, дополнительная точность редко используется в графических алгоритмах. Но, как мы знаем, GPGPU (использование GPU для расчётов) становится для nVidia всё более важным, и в некоторых научных приложениях двойная точность необходима.
nVidia - не первая компания, которая это заметила. Не так давно IBM модернизировала процессоры Cell, чтобы повысить производительность SPU на этом типе данных. По производительности, конечно, реализация GT200 оставляет желать лучшего - вычисления с плавающей запятой двойной точности реализованы на отдельном блоке потокового мультипроцессора. Блок позволяет выполнять одно вычисление MAD двойной точности за такт, что даёт пиковую производительность 1,296 x 10 (TPC) x 3 (SM) x 2 (Multiply+Add) = 77,78 Gflops, или где-то между 1/8 и 1/12 от производительности с одинарной точностью. AMD добавила такую же поддержку, используя одинаковые вычислительные блоки за несколько тактов, что дало ощутимо лучший результат - всего в два-четыре раза медленнее, чем расчёты с одинарной точностью.
ROP
Как мы уже говорили, число блоков растровых операций (ROP) увеличилось, но каких-либо новых функций мы не получили. Впрочем, стоит признать ROP у G8x уже довольно полные, с поддержкой 16- и 32-битных кадровых буферов с плавающей запятой со смешением и сглаживанием; сглаживание до 8x или 16x в режиме CSAA; Z-рендеринг в восемь раз быстрее и т.д. Вряд ли нужно что-то добавлять. Поэтому nVidia занялась оптимизацией производительности. Для смешения в кадровых буферах RGBA8 мы получили на G8x/G9x производительность, уменьшенную в два раза, с 12 пикселями на такт. У GT200 это ограничение было снято, а добавление 512-битной шины, с пропускной способностью больше 140 Гбайт/с, новые ROP могут сделать карты GeForce непобедимыми по пропускной способности. Ниже приведены результаты для пиксельного Z-заполнения.

По чистой производительности результаты не разочаровывают, мы поставили новый рекорд: 75 537 мегапикселей в секунду! Впрочем, значение всё же можно признать разочарованием в том отношении, что мы получили четырёхкратный, а не восьмикратный прирост базовой скорости заполнения. Для 9800 GTX мы получили 5,2 увеличение - чуть лучше, но, опять же, ниже теоретического значения.
Результаты Fillrate Tester
Производительность геометрических шейдеров предыдущих процессоров nVidia Direct3D 10 не очень впечатляла из-за неправильно оцененных и слишком маленьких внутренних буферов. Помните, что по спецификациям Direct3D 10 геометрический шейдер способен создавать до 1 024 значений с плавающей запятой одинарной точности на входящую вершину. Поэтому, с существенной нагрузкой на геометрию, буферы быстро заполнялись и предотвращали дальнейший расчёт геометрии. У GT200 размер буферов был увеличен в шесть раз, что существенно повышает производительность в некоторых случаях, как мы увидим. Чтобы выжать максимум из размера буферов, nVidia пришлось поработать над диспетчеризацией потоков геометрических шейдеров.

На первом шейдере Galaxy прирост очень скромный - 4%. С другой стороны, на Hyperlight он составил 158% - свидетельство улучшений работы с подобными типами шейдеров, хотя всё зависит от реализации и от мощности (число точек/чисел с плавающей запятой, сгенерированных на одну входящую вершину). В целом, GTX 280 закрыла разрыв и обошла 3870 X2 на том же шейдере.
Теперь давайте взглянем на результаты теста Rightmark 3D Point Sprites (Vertex Shading 2.0).

Почему мы говорим об этом тесте в разделе, посвящённом геометрическим шейдерам? Просто потому, что с момента Direct3D 10 за обработку точечных спрайтов отвечают геометрические шейдеры, что объясняет удвоение производительности между 9800 GTX и GTX 280!
Разные улучшения
nVidia оптимизировала несколько аспектов архитектуры. Кэш-память пост-трансформации была увеличена. Роль этой кэш-памяти заключается в том, чтобы избежать повторной трансформации одной вершины несколько раз с индексированными примитивами или полосками треугольников, записывая результат вершинных шейдеров. Из-за повышения числа ROP производительность отсечения Early-Z была существенно улучшена. GT200 способна отсекать до 32 пикселей по маске за такт перед применением пиксельного шейдера. Кроме того, nVidia заявляет об оптимизации передачи данных и команд между драйвером и началом конвейера GPU.
Поскольку от практически удвоения числа потоковых процессоров (ALU) можно ждать определённых улучшений, давайте сначала посмотрим, как карты работают в тесте вершинных шейдеров Rightmark Vertex Shaders.

Удивительно, несмотря на разные регулировки и повторные тестовые прогоны, GTX 280 не только показала меньшую производительность, чем 9800 GTX, но и упала на 12%! nVidia получила такие же результаты, и мы смогли их изменить, только включив сглаживание 4x - удивительный шаг для геометрического теста. Но следует заметить, что, несмотря на возросшую мощность обработки (и выросшую производительность трансформации), движок настройки (setup engine) не изменился. Как и в случае 9800 GTX, карта способна генерировать только один треугольник за такт. И преимущество 9800 GTX по частоте (675 МГц против 600 МГц) объясняет разницу.

Как обычно бывает в случае RightMark 2.0, первый тест шейдеров не показал улучшения на новой видеокарте, а второй дал 25% прирост.
Мы уже весьма подробно поговорили об улучшениях в расширенных пиксельных шейдерах (в частности, в разделе арифметических тестов), но давайте посмотрим на простые шейдеры, а именно на тест попиксельного затенения Fillrate Tester, который мы используем уже четыре года.

Прошло уже немало лет, поэтому мы могли бы ожидать прирост производительности GTX 280 побольше 40%. Мы не будем показывать все результаты ShaderMark (который использует Pixel Shader 3.0), но и там улучшение составило от 20 до 26% для последних шести шейдеров, а максимальный прирост - не больше 43%.
Все результаты оказались удивительными, они демонстрируют разрыв между теоретическим увеличением мощности (которое должно повлиять на вершинные и пиксельные шейдеры, даже старые) и реальным приростом в приложениях. Конечно, драйверы пока ещё не полностью оптимизированы, и не следует забывать, что при запуске даже самого специфического теста очень сложно изолировать какую-либо часть конвейера, чтобы на неё не влияли остальные, особенно в современных архитектурах.
Спецификации: ещё выше!
Как часто случалось, nVidia подготовила к анонсу две видеокарты: экстремальную high-end версию GeForce GTX 280 и чуть более доступную, но всё ещё high-end видеокарту GeForce GTX 260. Давайте посмотрим на характеристики этих видеокарт по сравнению с конкурентами.
| Спецификации основных видеокарт | |||||
| GPU | HD 3870 X2 | 9800 GX2 | 8800 Ultra | GTX 260 | GTX 280 |
| Частота GPU | 825 МГц | 600 МГц | 612 МГц | 576 МГц | 602 МГц |
| Частота ALU | 825 МГц | 1 500 МГц | 1 512 МГц | 1 242 МГц | 1 296 МГц |
| Частота памяти | 900 МГц | 1 000 МГц | 1 080 МГц | 999 МГц | 1 107 МГц |
| Ширина шины памяти | 2x256 битов | 2x256 битов | 384 бита | 448 битов | 512 битов |
| Тип памяти | GDDR3 | GDDR3 | GDDR3 | GDDR3 | GDDR3 |
| Объём памяти | 2 x 512 Мбайт | 2x512 Мбайт | 768 Мбайт | 896 Мбайт | 1 024 Мбайт |
| Число ALU (потоковых процессоров) | 640 | 256 | 128 | 192 | 240 |
| Число текстурных блоков | 32 | 128 | 32 | 64 | 80 |
| Число ROP | 32 | 32 | 24 | 28 | 32 |
| Производительность шейдеров | 1 TFlops | (1152) GFlops | (581) GFlops | 715 GFlops | 933 GFlops |
| Пропускная способность памяти | 115,2 Гбайт/с | 128 Гбайт/с | 103,7 Гбайт/с | 111,9 Гбайт/с | 141,7 Гбайт/с |
| Число транзисторов | 1 334 млн. | 1 010 млн. | 754 млн. | 1 400 млн. | 1 400 млн. |
| Техпроцесс | 55 нм | 65 нм | 80 нм | 65 нм | 65 нм |
| Площадь кристалла | 2 x 196 мм² | 2 x 324 мм² | 484 мм² | 576 мм² | 576 мм² |
| Поколение | 2008 | 2008 | 2007 | 2008 | 2008 |
| Поддерживаемая модель шейдеров | 4.1 | 4.0 | 4.0 | 4.0 | 4.0 |
С 1 400 млн. транзисторов и площадью кристалла 576 мм², nVidia создала ещё одного "монстра" - самый крупный GPU, когда либо производившийся, который побил уже впечатляющий рекорд G80 (он на 16% меньше). В принципе, площадь кристалла меняется мало с поколениями (хотя для "массовых" процессоров она снижается). Очевидно, что производство GT200 обходится nVidia очень дорого, даже на хорошо отработанном, но не самом тонком техпроцессе, что и объясняет существование такого крупного чипа.
Ещё один интересный момент: продолжая использовать GDDR3 nVidia отстаёт уже не на одно, а на два поколения от конкурента, поскольку GDDR5 появится в Radeon HD 4870, который выйдет в ближайшее время. Однако следует отметить, что благодаря 512-битной шине памяти, увеличение пропускной способности всё ещё составляет 64% по сравнению с 86,4 Гбайт/с у 8800 GTX. Мы, наконец, увидели появление high-end видеокарты с объёмом памяти больше 512 Мбайт (не считая относительно старую и не самую распространённую 8800 Ultra)! С 1 Гбайт (и 896 Мбайт для GTX 260, что тоже неплохо), производительность в разрешении 2 560 x 1 600 должна быть очень даже достойной.
Наконец, частоты оказались весьма консервативными, особенно для потоковых процессоров (ALU), которые, кроме всего прочего, медленнее, чем на 8800 Ultra.
GTX 280 или GTX 260?
С 30% большей производительностью расчётов с плавающей запятой и на 27% большей пропускной способностью памяти, теоретический разрыв между двумя новыми видеокартами nVidia вполне заметен. На практике карты очень похожи друг на друга, а также и на последние high-end модели GeForce 9 - печальное последствие универсальных "чёрных коробок", корпусов, которые nVidia использует на последних видеокартах. Только крупный 8-см радиальный вентилятор, немного наклонённый, чтобы продувать основание, а также разъёмы дополнительного питания, без которых уже не обойтись, выставляются наружу. Для питания используется два шестиконтактных разъёма PCI Express или один шести- и один восьмиконтактный: с такой мощностью придётся работать блоку питания, если вы хотите установить GeForce GTX 280 или GTX 260. Но и здесь ничего нового, поскольку ATI приучила нас к подобным требованиям в прошлом году, выпустив 2900 XT.
 |
Нажмите на картинку для увеличения.
Разъёмы SLI и звуковой вход HDMI, которые присутствуют, скрыты за съёмными заглушками. Единственное реальное отличие от GeForce 9800 GTX заключается в том, что хотя во второй слотовой заглушке есть вентиляционная решётка для выброса горячего воздуха, часть воздуха от карты выходит через вторую решётку, поступая наверх, поэтому он остаётся внутри корпуса - не очень хорошая новость. Длина карт по-прежнему составляет 26,7 см (10,5") - стандарт для high-end моделей за последние два года, а вес чуть не дотягивает до килограмма - 915 грамм, что чуть легче, чем 940 грамм HD 3870 X2.
 |
Нажмите на картинку для увеличения.
Для тестов мы получили видеокарты Leadtek, которые, традиционно для high-end моделей в момент запуска, используют эталонный дизайн, а производителя можно узнать разве что по паре наклеек на корпусе. В комплект GTX 280 входит игра NeverWinter Nights 2 (не самый свежий вариант, который бы показал мощь видеокарты), переходник DVI-VGA, кабель HDTV (YUV и S-Video), два переходника с Molex на шестиконтактную вилку PCI Express и переходник с Molex на восьмиконтактную вилку PCI Express.
Для данного теста мы использовали эталонную конфигурацию, а также тестировали игры исключительно с помощью Fraps, в реальных условиях. Большинство игр, которые помогали нам раньше, включены в обзор, мы традиционно их обновили (установив последние патчи), однако мы добавили две новые игры: Mass Effect, космическую сагу-RPG от Bioware, которая, несмотря на корни Xbox 360, была успешна портирована. Без этой игры мы бы вряд ли могли обойтись (тем более, что она закрывает разрыв после того, как мы отказались от Fable). Вторая игра - Race Driver: GRID, которая, несмотря на интерфейс, является кошмаром для тестеров (подобно предыдущей Colin McRae Dirt от того же издателя, Codemasters). Данная игра визуально очень привлекательная, она использует последнюю версию Ego Engine.
Все синтетические тесты DirectX 9 проводились под Windows XP из-за их нестабильности под Vista (Fillrate Tester, RightMark 1050, ShaderMark 2.1 и SPECviewperf 10). RightMark 3D 2.0 (DirectX 10) запускался, вполне понятно, под Windows Vista (без SP1, поскольку с ним тест тоже был нестабилен), а для всех игр мы использовали Vista SP1, как и для тестов CUDA, измерений шума и температуры, а также для разгона. Мы отключили UAC, Aero, SuperFetch и индексацию, чтобы получать повторяемые результаты.
Для теста мы использовали только два разрешения: 1 920 x 1 200 (24/26") и, конечно, 2 560 x 1 600, поддерживаемое 30" мониторами (Samsung 305T в нашем случае). Причина в том, что, как нам кажется, подобные high-end видеокарты будут использовать только для таких разрешений. Если ваш монитор имеет меньшее разрешение (вплоть до 22"), то вам вряд ли стоит тратиться на подобные модели, чтобы получить плавную и красивую картинку, как мы уже .

| Тестовая конфигурация | |
| Материнская плата | Asus P5E3 Deluxe (Intel X38) |
| Процессор | Intel Core 2 Quad QX6850 (3 ГГц) |
| Память | Crucial 2 x 1 Гбайт DDR3 1333 МГц 7-7-7-20 |
| Жёсткий диск | Western Digital WD5000AAKS |
| Оптический привод | Asus 12x DVD |
| Блок питания | Cooler Master RealPower Pro 850W |
| Программное обеспечение | |
| ОС | Windows XP, Vista, Vista SP1 |
| Драйверы nVidia | ForceWare 177.34 beta (GTX 260 и GTX 280 под Vista) ForceWare 177.26 beta (GTX 280 под XP) ForceWare 175.16 WHQL (9800 GTX, 9800 GX2, 8800 Ultra) |
| Драйверы AMD | Catalyst 8.5 WHQL (HD 3870 X2) |
 |
Нажмите на картинку для увеличения.
Зачем тестировать последние high-end видеокарты на игре, которая, как известно, упирается в CPU? Причина простая: нужно убедиться, что новые видеокарты ведут себя, по крайней мере, не хуже, чем предыдущее поколение, а также проверить проработанность драйвера. Как мы уже не раз убеждались, Flight Simulator X может скрывать некоторые сюрпризы.


Как видим, новые GeForce GT200 отнюдь не радуют. Ни одна из них не смогла выдать больше 23 fps, что смущает, пусть даже это Flight Simulator X. Но 9800 GX2 и 8800 Ultra подобрались вплотную к порогу 30 fps, что намного лучше. Мы уверены, что в следующей версии драйверов ситуация должна улучшиться, так как несколько парадоксально покупать последнее поколение видеокарт nVidia, чтобы получить падение производительности. Даже в игре, где производительность CPU играет важную роль.
 |
Нажмите на картинку для увеличения.


Если видеокарта GTX 280 хорошо показала себя в Call of Duty 4, обогнав 9800 GTX на 41% (1 920 x 1 200) и 91% (2 560 x 1 600 + фильтры), то 9800 GX2 оказалась тяжёлым соперником. Она даже обогнала 280 на разрешении 1 920 x 1 200 (на солидные 17%), вероятно из-за большего числа текстурных блоков - единственное теоретическое значение, по которому последние видеокарты nVidia с двумя GPU обгоняют других. На 30" пропускная способность памяти и её удвоенное количество дали GTX 280 лидерство, но только после включения сглаживания 4x (играть всё ещё можно). Мы начали подозревать, что на данных видеокартах можем получить результаты, очень близкие друг к другу. Обратите внимание, что GTX 260 на 21-26% отстаёт от "старшей" модели, что вполне ожидаемо по спецификациям. Видеокарта явно обходит 8800 Ultra, но ощутимо уступает 9800 GX2 в данном тесте.
 |
Нажмите на картинку для увеличения.


В игре Test Drive Unlimited нет никакого сомнения в превосходстве новых high-end видеокарт nVidia, пусть даже 9800 GX2 оказалась очень близка (отставание меньше 8% на первых трёх режимах и 17% на максимальном). Ещё одна хорошая новость для производителя - превосходство GTX 280 становится заметным от разрешения 1 920 x 1200, где производительность в два раза превышает 9800 GTX (с фильтрацией и сглаживанием). Однако переход на 30" не усилил лидерство, а, наоборот, уменьшил, однако отрыв всё ещё составляет 50% без фильтров и 76% с ними. Что касается GTX 260, то её отрыв от 8800 Ultra на том же разрешении тоже снизился, до 11% в среднем.
 |
Нажмите на картинку для увеличения.
Crysis по-прежнему привлекает к себе удивительно много внимания. Ниже представлены наши тесты (мы тестировали игру на новой сцене, которая не так загружает GPU, как предыдущая).


Из-за высоких требований игры (на этот раз мы тестировали её на тех же разрешениях, что и другие игры), иерархия на диаграмме соответствует результатам без фильтров, поскольку они бесполезны. Можно ли играть в Crysis на разрешении 1 920 x 1 200 на новой GTX 280? Да, но не так плавно, как на 9800 GX2 на нашей тестовой сцене. Только включение сглаживания позволило 280 выйти вперёд, но частота кадров слишком низкая, чтобы играть в режиме детализации "Very High". И проблема в том, что хотя на трёх из четырёх тестовых прогонах GTX 280 обгоняла 9800 GX2 в Crysis, играть вряд ли получится. И это несмотря на боле, чем удвоенную производительность на 2 560 x 1 600 и тот факт, что новые карты оказались единственными, за исключением 8800 Ultra, кто мог выводить игру с активным сглаживанием. В целом, мы были разочарован.
 |
Нажмите на картинку для увеличения.


Перед нами ещё одна "тяжёлая" игра, но, в любом случае, играть можно и на разрешении 2 560 x 1 600 без фильтров. Однако видеокарта в World in Conflict уступила "тёмной лошадке" на разрешении 1 920 x 1 200: Radeon HD 3870 X2! Опять же, после включения фильтров карта AMD на двух GPU, которая замечательно подходит для этой игры, обеспечила более высокую производительность, ненамного обогнав GTX 280. На 30" дисплее карта AMD сохранила своё преимущество, а объём памяти GTX 280 вновь хорошо показал себя на последнем режиме, хотя вряд ли на нём можно комфортно играть. И это ещё не всё: на этом же разрешении в лидеры вышла карта nVidia, но 9800 GX2, а не GT200. Поэтому, если вы играете в World in Conflict и Crysis, то GTX 280 вряд ли вам понадобится...
 |
Нажмите на картинку для увеличения.


Данная игра со временем стала уже не такой прожорливой, особенно по сравнению с некоторыми свежими играми. Однако Supreme Commander всё ещё актуальна, особенно для игр по сети. На поле боя, но с не слишком большим числом юнитов (чтобы производительность не упиралась в CPU), GTX 280 так ни разу и не смогла обойти 9800 GX2, которая лидирует на 39% на разрешении 2 560 x 1 600. Да, результаты GTX 280 вряд ли можно назвать ужасными, поскольку они на 45% превышают 9800 GTX и 8800 Ultra, хотя мы ожидали большего.
 |
Нажмите на картинку для увеличения.


Две новинки интересно проанализировать в Unreal Tournament 3. Если результаты в 1 920 x 1 200 не удивляют, то в 2 560 x 1 600 "тёмная лошадка" 9800 GX2 вновь вышла вперёд. К сожалению, ограниченный объём памяти на этой видеокарте не позволил нам протестировать её с фильтрами, хотя GTX 280 справилась с этой задачей и обеспечила плавную игру. Средний отрыв от видеокарты предыдущего поколения 9800 GTX составил 59%. GTX 260 хорошо показала себя, выдав около 83% производительности GTX 280 на трёх из четырёх разрешений, что даёт этой видеокарте хорошее соотношение цена/производительность, как мы увидим ниже.
 |
Нажмите на картинку для увеличения.


Будучи портированной с Xbox 360, игра Mass Effect очень хорошо работает на Radeon HD 3870 X2, за исключением того, что она не справилась со сглаживанием. Однако она вполне хороша для 1 920 x 1 200 и 2 560 x 1 600. Но это не помешало тому, что GTX 280 не смогла выйти в лидеры, поскольку 9800 GX2 не очень хорошо показывает себя в этой игре, заметно уступая (34% на 1 920 x 1 200 + фильтры и 62% на 2 560 x 1 600). Отрыв GTX 280 от 9800 GTX составил 220% на разрешении 1 920 x 1 200 + фильтры, а GeForce GTX 260 идёт чуть позади "старшей" модели.
 |
Нажмите на картинку для увеличения.


Игра слишком новая для появления профиля SLI (он необходим для работы карт с двумя GPU, такими как 9800 GX2), поэтому 9800 GX2 среди аутсайдеров. Это как раз помогает GTX 280 выйти вперёд. Производительность видеокарты очень хороша: если она обходит GTX 260 всего примерно на 20%, лидерство над 9800 GTX увеличивается до 50% (за исключением 1 920 x 1 200 и 2 560 x 1 600 + фильтры). Что более важно, две новых видеокарты оказались единственными, которые позволяют играть в разрешении 2 560 x 1 600 + 4X сглаживание, режим, очень приятный для глаз.
BadaBOOM Media Converter, Folding@Home
BadaBOOM Media Converter является программой перекодирования видео, разработанной Elemental Technologies, которая преобразовывает Video DVD (только MPEG2) в формат H.264 для большинства портативных медиаплееров, включая iPhone, iPod и PSP (только с предварительно заданными профилями). Программа оптимизирована для CUDA (через видеоплатформу RapiHD от ETI), поэтому она позволяет удобно сравнить мощность совместимых GeForce (все модели GeForce 8 и 9), которые ускоряют эту требовательную задачу - когда то объявленную AMD через AVIVO. Однако кодировщик Elemental не такой "глючный" и даёт более высокую скорость компрессии.
 |
Нажмите на картинку для увеличения.
На предыдущей версии, которая была совместима только с GT 200, мы смогли сжать тестовое видео (400 Мбайт) в формат iPhone (640 x 365) с максимальным качеством за 56,5 секунд на GTX 260 и 49 секунд на GTX 280 (на 15% быстрее). В целях сравнения, кодировщик iTunes H.264 работает восемь минут, используя ресурсы CPU (потребляя больше мощности в целом, но существенно меньше на пиках). Впрочем, следует помнить, что перед нами далеко не самый оптимизированный компрессор H.264, да и BadaBOOM явно не хватает гибкости в работе, пусть даже результат весьма хороший.
Folding@Home
У нас появилась возможность протестировать пре-бета клиент Folding@Home на CUDA, чья финальная версия должна появиться в ближайшие дни. К сожалению, он тоже работает только на GeForce 200.
 |
Нажмите на картинку для увеличения.
Здесь, опять же, nVidia имеет более, чем годовую задержку по сравнению с ATI, чьи видеокарты Radeon участвуют в проекте, но GeForce 200 (поскольку мы не смогли протестировать другие видеокарты nVidia) дают более высокую производительность. На нашей тестовой конфигурации мы получили 560 ns в день на GTX 280 и 480 ns в день на GTX 260. Для сравнения PS3 даёт производительность около 150-200 ns в день по сравнению с менее 10 для процессора и 200 для простого Radeon HD 3870.
Однако важно понимать, что производительность может легко меняться в зависимости от клиента на данной архитектуре (оптимизация кода ещё далеко не завершеня для клиентов ATI и nVidia). Mike H считает, что тот же самый HD 3870 может дать 300 ns в день, но не меньше 250. Ещё одна проблема в том, что при смене протеина, требующаяся для клиента GeForce, производительность тоже меняется. В общем, на сегодня мы бы хотели подчеркнуть случайную природу и временный характер приведённых выше результатов. Мы уверены, что с появлением клиента, который будет поддерживать CUDA-совместимые видеокарты GeForce (все, начиная с GeForce 8, включая модели начального уровня), для проекта появятся интересные возможности, поскольку установочная база насчитывает примерно 7 000 TFlops.
 |
Нажмите на картинку для увеличения.
1 400 млн. транзисторов по 65-нм техпроцессу заставляют ожидать высокое энергопотребление видеокарты. Давайте посмотрим на энергопотребление системы, включающее потери на блоке питания (энергопотребление всей системы и 20% потерь на блоке питания).

Первое, что стоит отметить: в играх энергопотребление новых видеокарт очень высокое, но не рекордное. GTX 280 демонстрирует энергопотребление, сравнимое с 8800 Ultra, но уступающее 9800 GX2. А то, что видеокарта 3870 X2 потребляет меньше энергии, связано с недостаточной нагрузкой в протестированной игре. В том же Fillrate Tester мы заметили более высокие пики энергопотребления: 404 Вт для 3870X2 против всего 340 Вт для GTX 280 и 279 Вт для 9800 GTX. Энергопотребление GTX 260 лишь ненамного превышает 9800 GTX, что радует. Что касается максимального энергопотребления самих карт, то nVidia указывает 236 Вт для GTX 280 и 182 Вт для GTX 260.
С другой стороны, инженеры nVidia хорошо поработали над энергопотреблением в режиме бездействия. У видеокарт есть чип, который постоянно замеряет процент использования GPU, и в соответствие с данной информацией драйвер автоматически регулирует частоты, напряжение и активность каждого участка чипа. Следует признать, что результаты GT 200 действительно впечатляют, устраняя историческое отставание чипов nVidia от GPU AMD и даже обгоняя последнюю по минимальному энергопотреблению. GTX 260 получает 20-Вт падение в энергопотреблении на входе блока питания по сравнению с 9800 GTX, да и GTX 280 потребляет существенно меньше энергии - около 25 Вт в 2D (частоты падают до 300 МГц для GPU и 100 МГц для памяти) и примерно 35 Вт во время воспроизведения дисков Blu-ray. Результат действительно великолепен, он в той или иной степени отменяет преимущество технологии HybridPower, для которой нужно менять материнскую плату, чтобы полностью отключать внешнюю 3D-карту, теряя при этом игровую 3D-производительность!
Учитывая низкое энергопотребление в режиме бездействия и высокое, но не чрезмерное энергопотребление под нагрузкой, мы были уверены, что GT200 от nVidia будет соответствовать репутации относительно тихих high-end видеокарт со времён GeForce 7800 GTX. Мы ошибались.

После старта Windows вентилятор GT200 работал тихо (516 об/мин или 30% от максимальной скорости). Затем, после запуска игры, он превращал компьютер в пылесос, достигая уровня шума, который вряд ли можно назвать терпимым - особенно у GTX 280. GTX 260 показала себя чуть лучше, но тоже сильно шумела на 1 250 об/мин (причём шумел воздушный поток, а не сам вентилятор). Впрочем, наши значения шума в режиме бездействия замерялись после проведения всех тестов, после всего нескольких минут бездействия. Проблема в том, что GTX 280 никогда не спускается обратно на минимальный уровень, да и вентилятор GTX 260, который шумит меньше, всё равно вращается на 700 об/мин - относительно громко.
Результаты сложно понять, учитывая низкое энергопотребление GT200 в режиме бездействия, они могут быть связаны как с ошибкой в BIOS (хотя она тогда проявлялась на обеих видеокартах) или в драйверах, что оставляет надежду на исправление. С другой стороны, вентилятор всегда можно заметить вручную с помощью специального ПО, если вы будете следить за температурой (см. следующую страницу). В общем, вентиляторы данных видеокарт нас сильно разочаровали, особенно с учётом того, что часть горячего воздуха возвращается обратно в корпус и нагревает другие компоненты, включая сам GPU.
Наконец, мы обратили, что и аналогично тестам энергопотребления, результаты 3870 X2 под нагрузкой слишком хорошие. Тому есть причина: Test Drive Unlimited одна из немногих игр, в которой у этой видеокарты работает только один GPU, что снижает нагрев.
Теперь давайте посмотрим на температуру GPU, которую мы записали (для Radeon HD 3870 X2 она указана для активного GPU, вторая температура никогда не превышает 56°C под нагрузкой).

Неудивительно, что 260 GTX и 280 GTX очень хорошо охлаждаются - мы получили самые низкие температуры в режиме бездействия и одни из самых низких под нагрузкой. Неудивительно, поскольку данные видеокарты потребляют не самый высокий уровень энергии, и, как мы уже упоминали, используют агрессивную систему охлаждения. Мы так никогда и не подошли к уровню 105°C, когда частоты автоматически уменьшаются для защиты видеокарты. То есть, как мы и предполагали, nVidia имеет хороший запас для снижения уровня шума видеокарты как в режиме бездействия, так и под нагрузкой.
Разгон
В тестах разгона мы смогли разогнать GeForce GTX 260 с частот 576/1242/999 МГц (GPU/ALU/память) до 648/1397/1184 МГц, то есть на 12% и 18%, соответственно. Результат неплохой, он позволил выжать ещё 16% или 8,4 кадров в секунду в тестах 2 560 x 1 600 в Test Drive Unlimited - всего на 6% медленнее, чем GTX 280!
Вполне понятно, что мы разогнали и GTX 280: с частот 602/1296/1107 МГц до 655/1410/1290 при сохранении очень хорошей стабильности, с приростом 9% и 16%. Test Drive Unlimited вновь выиграла от прироста, увеличив частоту кадров на 13% - весьма неплохо по сравнению с 16%, которые мы получили у 9800 GTX. В целом, результаты приятные, особенно для разгона, который иногда определяется больше долей везения.
Заключение
Каково будет наше заключение по поводу новых видеокарт? Начнём с того, что параллель с GeForce 7800 GTX слишком очевидна. Карты построены на уже проверенной архитектуре, с исправленными слабыми местами, которые обнаружили инженеры nVidia, и с существенным приростом вычислительной мощности. Поэтому никаких неприятных сюрпризов по поводу архитектуры мы не выявили, за возможным исключением отсутствия поддержки Direct3D 10.1 или немного разочаровывающей производительности с числами с плавающей запятой двойной точности.
С другой стороны, в отличие от современной ситуации, во времена 7800 GTX у nVidia не было такой мощной видеокарты с двумя GPU, какой является 9800 GX2. Это можно считать недостатком во время объявления новых продуктов. У GTX 280 практически удвоилась чистая теоретическая производительность по сравнению с предыдущим поколением (и даже практическая производительность благодаря улучшению эффективности, хотя некоторые наши синтетические тесты не показали такое увеличение скорости, на какое мы надеялись). Но GTX 280 не так хорошо работает по сравнению с 9800 GX2, которая часто обгоняет новинку в игровых тестах. Конечно, вряд ли имеет смысл рекомендовать карту предыдущего поколения, которая имеет в два раза меньше полезной памяти и намного более высокое энергопотребление в режиме бездействия (если не считать других недостатков), её результаты в тестах всё же отняли часть славы у новой экстремальной high-end видеокарты. В этом сложно винить nVidia, поскольку на уже гигантском ядре сложно увеличивать число потоковых процессоров (АЛУ). Да и сравните с производительностью конкурента.
Есть ещё несколько огорчений. И самое основное среди них - очень высокий уровень шума, который сложно для GTX 280 и 260 сложно объяснить, поскольку их энергопотребление ниже, чем у видеокарт с двумя GPU под нагрузкой и очень незначительное в режиме бездействия. Не забывайте и про отсутствие поддержки DirectX 10.1, что можно назвать явно политическим выбором, который замедлит или даже предотвратит распространение этого стандарта среди разработчиков, а это несколько обидно в свете игры Assassin"s Creed. Да и цена GTX 280 ($650 на мировом рынке), благодаря которой карта позиционируется на самый экстремальный high-end, тоже весьма проблематична в свете очень агрессивной цены на "младшую" GTX 260 - а производительность последней всего на 18% уступает "старшей" модели. Цена для GTX заявлена почти в два раза ниже - $400! В итоге на дату начала продаж (26 июня) видеокарта станет весьма привлекательным решением, тем более, что она использует такой же GPU GT200.
Наконец, мы не можем не упомянуть очень интересных перспектив приложений CUDA. Хотя последние полтора года почти никто не упоминал CUDA в качестве позитивных особенностей GeForce 8, но сегодня ситуация изменилась, первые три интересные приложения уже готовы или почти готовы. Мы имеем в виду кодировщик видео BadaBOOM и бета-клиент Folding@Home GeForce, которые оставляют CPU и конкурирующие Radeon далеко позади, а также и поддержку GeForce PhysX, которая немало бы дала разработчикам. Они смогли бы объявить о поддержке технологии в следующих играх, хотя нам ещё предстоит оценить, какую разницу даст реализация на практике. Всё это существенно расширяет сферу применения CUDA-совместимых GeForce GPU (начиная с GeForce 8), если выход оптимизированного ПО для разных вычислений продолжится, и если AMD не попытается "перетянуть одеяло на себя".
nVidia GeForce GTX 280
Заключение по GTX 280 будет таково. Новая экстремальная high-end видеокарта GTX 280 от nVidia ($650) немного уступает в сравнении с 9800 GX2, которая регулярно выходит в лидеры в игровых тестах, несмотря на все недостатки карт с двумя GPU. Но, в реальности, настоящей угрозой является "младшая" модель GTX 260, особенно с учётом того, что за цену GTX 280 вы почти что сможете купить две GTX 260 в SLI!
Преимущества .
- общая высокая производительность;
Недостатки .
- Нет поддержки DirectX 10.1;
- слабая производительность по сравнению с 9800 GX2;
- высокий уровень шума;
- высокая цена GTX 280 по сравнению с конкурентами nVidia.
nVidia GeForce GTX 260
Карта намного более привлекательная благодаря очень приятной цене. GTX 260 достойно себя показывает в игровых тестах и имеет большинство преимуществ GTX 280 без высокой цены. Карта начнёт продаваться на следующей неделе на мировом рынке за $400.
Мы вынуждены обратить внимание, что представительство nVidia в России работает неудовлетворительно: мы до сих пор не получили никакой информации ни о ценах, ни о доступности карт в нашей стране. Будем надеяться, что в России не станут задирать на них цены.
Преимущества .
- Улучшенная архитектура GeForce 8;
- производительность всего на 18% уступает GTX 280;
- очень низкое энергопотребление в режиме бездействия;
- ускорение CUDA-совместимых программ.
Недостатки .
- Нет поддержки DirectX 10.1;
- высокий уровень шума.


Наиболее производительным одночиповым решением доселе являлся GeForce GTX 280 - обладает 240 шейдерными процессорами, 80 текстурными процессорами, поддерживает до 1 Гб видеопамяти. Фактически современное графическое ядро семейства GeForce GTX 200 можно представить как универсальный чип, поддерживающий два разных режима – графический и вычислительный. Архитектуру чипов семейств GeForce 8 и 9 обычно представляют массивами масштабируемых процессоров (Scalable Processor Array, SPA). Архитектура чипов семейства GeForce GTX 200 основана на доработанной и улучшенной архитектуре SPA, состоящей из ряда так называемых "кластеров обработки текстур" (TPC, Texture Processing Clusters) в графическом режиме или "кластеров обработки потоков" в режиме параллельного вычисления.
При этом каждый модуль TPC состоит из массива потоковых мультипроцессоров (SM, Streaming Multiprocessors), и каждый SM содержит восемь процессорных ядер, также называемых потоковыми процессорами (SP, Streaming Processor), или тредовыми процессорами (TP, Thread Processor). Каждый SM также включает в себя процессоры текстурной фильтрации для графического режима, также используемый для различных операций фильтрации в вычислительном режиме.
Ниже представлена блок-схема GeForce 280 GTX в традиционном графическом режиме.

Переключаясь в вычислительный режим, аппаратный диспетчер потоков (вверху) управляет тредами TPC.

Кластер TPC при ближайшем рассмотрении: распределённая память для каждого SM; каждое процессорное ядро SM может распределять данные между другими ядрами SM посредством распределённой памяти, без необходимости обращения к внешней подсистеме памяти.
Таким образом, унифицированная шейдерная и компьютерная архитектура NVIDIA использует две совершенно разные вычислительные модели: для работы TPC используется MIMD (multiple instruction, multiple data), для вычислений SM - SIMT (single instruction, multiple thread), продвинутая версия, SIMD (single instruction, multiple data).
Касаясь общих характеристик, по сравнению с предшествовавшими поколениями чипов семейство GeForce GTX 200 обладает следующими преимуществами:
Возможность обработки втрое большего количества потоков данных в единицу времени
Новый дизайн планировщика выполнения команд, с повышенной на 20% эффективностью обработки текстур
512-битный интерфейс памяти (384 бита у предыдущего поколения)
Оптимизированный процесс z-выборки и компрессии для достижения лучших результатов производительности при высоких разрешениях экрана
Архитектурные усовершенствования для увеличения производительности при обработке теней
Полноскоростной блендинг буфера кадров (против полускоростного у 8800 GTX)
Вдвое увеличенный буфер команд для повышения производительности вычислений
Удвоенное количество регистров для более оперативного обсчёта длинных и сложных шейдеров
Удвоенная точность обсчета данных с плавающей запятой в соответствии со стандартом версии IEEE 754R
Аппаратная поддержка 10-битного цветового пространства (только с интерфейсом DisplayPort)
Так выглядит список основных характеристик новых чипов:
Поддержка NVIDIA PhysX
Поддержка Microsoft DirectX 10, Shader Model 4.0
Поддержка технологии NVIDIA CUDA
Поддержка шины PCI Express 2.0
Поддержка технологии GigaThread
Движок NVIDIA Lumenex
128-битные вычисления с плавающей запятой (HDR)
Поддержка OpenGL 2.1
Поддержка Dual Dual-link DVI
Поддержка технологии NVIDIA PureVideo HD
Поддержка технологии NVIDIA HybridPower
Отдельно отмечено, что DirectX 10.1 семейством GeForce GTX 200 не поддерживается. Причиной назван тот факт, что при разработке чипов нового семейства, после консультаций с партнёрами, было принято сконцентрировать внимание не на поддержке DirectX 10.1, пока мало востребованного, а на улучшении архитектуры и производительности чипов.
Основанная на пакете физических алгоритмов, реализация технологии NVIDIA PhysX представляет собой мощный физический движок для вычислений в реальном времени. В настоящее время поддержка PhysX реализована в более чем 150 играх. В сочетании с мощным GPU, движок PhysX обеспечивает значительное увеличение физической вычислительной мощи, особенно в таких моментах как создание взрывов с разлётом пыли и осколков, персонажей со сложной мимикой, новых видов оружия с фантастическими эффектами, реалистично надетых или разрываемых тканей, тумана и дыма с динамическим обтеканием объектов.
К реализации физических эффектов в играх уже давно стремятся многие девелоперы и разработчики игр. С каждым годом это направление становится все актуальнее. В современных играх взаимодействие объектов с окружающей средой осуществляется силами двух движков, набравших наибольшую популярность - Havok и PhysX.
Havok является старейшим движком, на котором пишется немало игр под PC и консоли. Еще в далеком 2006 году, тогда еще независимая ATI, демонстрировала ускорение физических эффектов силами видеокарт Radeon X1900XT. Однако позже Havok купила компания Intel, которая заявила, что физические эффекты будут рассчитываться данным движком силами процессоров.

PhysX был разработан компанией AGEIA, которая реализовывала "физику" акселераторами собственной разработки. Но так сложилось, что, не смотря на большую популярность этого движка среди разработчиков игр, реализация физических эффектов в играх силами специализированных ускорителей оказалась весьма спорной.
И вот в прошлом году компания NVIDIA купила AGEIA PhysX. Были сделано заявление, что посредством оптимизации драйверов движок PhysX будет адаптирован под использование видеокарт GeForce 8800GT и выше.
Ещё одно немаловажное новшество – новые режимы экономии энергии. Благодаря использованию прецизионного 65 нм техпроцесса и новых схемотехнических решений удалось добиться более гибкого и динамичного контроля энергопотребления. Так, потребление семейства графических чипов GeForce GTX 200 в ждущем режиме или в режиме 2D составляет около 25 Вт; при воспроизведении фильма Blu-ray DVD - около 35 Вт; при полной 3D нагрузке TDP не превышает 236 Вт. Графический чип GeForce GTX 200 может вовсе отключаться благодаря поддержке технологии HybridPower с материнскими платами на HybridPower-чипсетах nForce с интегрированной графикой (например, nForce 780a или 790i), при этом поток графики незначительной интенсивности попросту обсчитывается GPU, интегрированным в системную плату. Помимо этого, GPU семейства GeForce GTX 200 также обладают специальными модулями контроля энергопотребления, призванными отключать блоки графического процессора, не задействованные в данный момент.

Пользователь может конфигурировать систему на базе двух или трёх видеокарт семейства GeForce GTX 200 в режиме SLI при использовании материнских плат на базе соответствующих чипсетов nForce. В традиционном режиме Standard SLI (с двумя видеокартами) декларируется примерно 60-90% прирост производительности в играх; в режиме 3-way SLI – максимальное количество кадров в секунду при максимальных разрешениях экрана.
В рамках анонса новой серии графических процессоров семейства GeForce GTX 200 компания NVIDIA предлагает совершенно по-новому взглянуть на роль центрального и графического процессоров в современной сбалансированной настольной системе. Такой оптимизированный ПК, базирующийся на концепции гетерогенных вычислений (то есть, вычислений потока разнородных разнотипных задач), по мнению специалистов NVIDIA, обладает гораздо более сбалансированной архитектурой и значительно большим вычислительным потенциалом. Имеется в виду сочетание центрального процессора со сравнительно умеренной производительностью с наиболее мощной графикой или даже SLI-системой, что позволяет добиться пиковой производительности в наиболее тяжёлых играх, 3D и медиа приложениях.
прочем, интенсивные вычисления с помощью современных графических видеокарт давно не новость, но именно с появлением графических процессоров семейства GeForce GTX 200 компания NVIDIA ожидает значительного повышения интереса к технологии CUDA.
CUDA (Compute Unified Device Architecture) - вычислительная архитектура, нацеленная на решение сложных задач в потребительской, деловой и технической сферах - в любых приложениях, интенсивно оперирующих данными, с помощью графических процессоров NVIDIA. С точки зрения технологии CUDA новый графический чип GeForce GTX 280 это ни что иное как мощный многоядерный (сотни ядер!) процессор для параллельных вычислений.
Как было указано выше, графическое ядро семейства GeForce GTX 200 можно представить как чип, поддерживающий графический и вычислительный режимы. В одном из этих режимов – "вычислительном", тот же GeForce GTX 280 превращается в программируемый мультипроцессор с 240 ядрами и 1 Гб выделенной памяти – этакий выделенный суперкомпьютер с производительностью под терафлоп, что в разы повышает результативность работы с приложениями, хорошо распараллеливающими данные, например, кодирование видео, научные вычисления и пр.
Графические процессоры семейств GeForce 8 и 9 стали первыми на рынке, поддерживающими технологию CUDA, сейчас их продано более 70 млн. штук и интерес к проекту CUDA постоянно растёт. Подробнее узнать о проекте и скачать файлы, необходимые для начала работы можно здесь. В качестве примера на приведённых ниже скриншотах показаны примеры прироста производительности вычислений, полученные независимыми пользователями технологии CUDA.

По сравнению с предыдущим лидером GeForce 8800 GTX новый флагманский процессор GeForce GTX 280 обладает в 1,88 раза большим количеством процессорных ядер; способен обрабатывать примерно в 2,5 больше тредов на чип; обладает удвоенным размером файловых регистров и поддержкой вычислений с плавающей запятой с удвоенной точностью; поддерживает 1 Гб памяти с 512-битным интерфейсом; оборудован более эффективным диспетчером команд и улучшенными коммуникационными возможностями между элементами чипа; улучшенным модулем Z-буфера и компрессии, поддержкой 10-битной цветовой палитры и т.д.
Впервые новое поколение чипов GeForce GTX 200 изначально позиционируется не только в качестве мощного 3D графического акселератора, но также в качестве серьёзного компьютерного решения для параллельных вычислений.
Характеристики NVIDIA GeForce GTX 280
| Наименование | GeForce GTX 280 |
| Ядро | GT200 (D10U-30) |
| Техпроцесс (мкм) | 0.065 |
| Транзисторов (млн) | 1400 |
| Частота работы ядра | 602 |
| Частота работы памяти (DDR) | 1107 |
| Шина и тип памяти | GDDR3 512-bit |
| ПСП (Гб/с) | 141,67 |
| Унифицированные шейдерные блоки | 240 |
| Частота унифицированных шейдерных блоков | 1296 |
| TMU на конвейер | 80 |
| ROP | 32 |
| Shaders Model | 4.0 |
| Fill Rate (Mtex/s) | 48160 |
| DirectX | 10 |
| Интерфейс | PCIe 2.0 |
Революции не произошло, новый графический процессор GT200 и протестированная сегодня видеокарта GeForce 280GTX(285GTX , 295GTX) являются дальнейшим развитием унифицированной шейдерной архитектуры от компании NVIDIA. Новый графический процессор содержит большее количество функциональных блоков, чем у предшественников, что даёт ему право называться мощнейшим GPU на сегодняшний день.
Однако вначале о технических особенностях. Являясь логичным развитием серий GeForce 8 и GeForce 9, представлявших первое поколение унифицированной визуальной вычислительной архитектуры NVIDIA, новинки семейства GeForce GTX 200 выполнены на базе второго поколения этой архитектуры.
Графические процессоры NVIDIA GeForce GTX 280 и 260 представляют собой наиболее массивные и сложные графические чипы из известных доселе – шутка ли, 1,4 миллиарда транзисторов в каждом! Наиболее производительное решение - GeForce GTX 280, обладает 240 шейдерными процессорами, 80 текстурными процессорами, поддерживает до 1 Гб видеопамяти. Подробные характеристики чипов GeForce GTX 280 и GeForce GTX 260 приведены в таблице ниже.
Спецификации NVIDIA GeForce GTX 280 и GTX 260 |
||
| Графическое ядро | ||
| Нормы технологического процесса | ||
| Количество транзисторов | ||
| Тактовая частота графики (в т.ч. диспетчера, модулей текстур и ROP) | ||
| Тактовые частоты процессорных модулей | ||
| Количество процессорных модулей | ||
| Тактовая частота памяти (частота/данные) | 1107 МГц / 2214 МГц |
999 МГц / 1998 МГц |
| Ширина интерфейса памяти | ||
| Пропускная способность шины памяти | ||
| Объём памяти | ||
| Количество модулей ROP | ||
| Количество модулей текстурной фильтрации | ||
| Производительность модулей текстурной фильтрации | 48,2 Гигатекселей/с |
36,9 Гигатекселей/с |
| Поддержка HDCP | ||
| Поддержка HDMI | Есть (адаптер DVI-HDMI) |
|
| Интерфейсы | 2 x Dual-Link DVI-I |
|
| RAMDAC, МГц | ||
| Шина | ||
| Форм-фактор | Два слота |
|
| Конфигурация разъёмов питания | 1 x 8-контактный |
2 x 6-контактных |
| Максимальное энергопотребление | ||
| Граничная температура GPU | ||
Фактически современное графическое ядро семейства GeForce GTX 200 можно представить как универсальный чип, поддерживающий два разных режима – графический и вычислительный. Архитектуру чипов семейств GeForce 8 и 9 обычно представляют массивами масштабируемых процессоров (Scalable Processor Array, SPA). Архитектура чипов семейства GeForce GTX 200 основана на доработанной и улучшенной архитектуре SPA, состоящей из ряда так называемых "кластеров обработки текстур" (TPC, Texture Processing Clusters) в графическом режиме или "кластеров обработки потоков" в режиме параллельного вычисления. При этом каждый модуль TPC состоит из массива потоковых мультипроцессоров (SM, Streaming Multiprocessors), и каждый SM содержит восемь процессорных ядер, также называемых потоковыми процессорами (SP, Streaming Processor), или тредовыми процессорами (TP, Thread Processor). Каждый SM также включает в себя процессоры текстурной фильтрации для графического режима, также используемый для различных операций фильтрации в вычислительном режиме. Ниже представлена блок-схема GeForce 280 GTX в традиционном графическом режиме.
Переключаясь в вычислительный режим, аппаратный диспетчер потоков (вверху) управляет тредами TPC.
Кластер TPC при ближайшем рассмотрении: распределённая память для каждого SM; каждое процессорное ядро SM может распределять данные между другими ядрами SM посредством распределённой памяти, без необходимости обращения к внешней подсистеме памяти.
Таким образом, унифицированная шейдерная и компьютерная архитектура NVIDIA использует две совершенно разные вычислительные модели: для работы TPC используется MIMD (multiple instruction, multiple data), для вычислений SM - SIMT (single instruction, multiple thread), продвинутая версия, SIMD (single instruction, multiple data). Касаясь общих характеристик, по сравнению с предшествовавшими поколениями чипов семейство GeForce GTX 200 обладает следующими преимуществами:
- Возможность обработки втрое большего количества потоков данных в единицу времени
- Новый дизайн планировщика выполнения команд, с повышенной на 20% эффективностью обработки текстур
- 512-битный интерфейс памяти (384 бита у предыдущего поколения)
- Оптимизированный процесс z-выборки и компрессии для достижения лучших результатов производительности при высоких разрешениях экрана
- Архитектурные усовершенствования для увеличения производительности при обработке теней
- Полноскоростной блендинг буфера кадров (против полускоростного у 8800 GTX)
- Вдвое увеличенный буфер команд для повышения производительности вычислений
- Удвоенное количество регистров для более оперативного обсчёта длинных и сложных шейдеров
- Удвоенная точность обсчета данных с плавающей запятой в соответствии со стандартом версии IEEE 754R
- Аппаратная поддержка 10-битного цветового пространства (только с интерфейсом DisplayPort)
- Поддержка NVIDIA PhysX
- Поддержка Microsoft DirectX 10, Shader Model 4.0
- Поддержка технологии NVIDIA CUDA
- Поддержка шины PCI Express 2.0
- Поддержка технологии GigaThread
- Движок NVIDIA Lumenex
- 128-битные вычисления с плавающей запятой (HDR)
- Поддержка OpenGL 2.1
- Поддержка Dual Dual-link DVI
- Поддержка технологии NVIDIA PureVideo HD
- Поддержка технологии NVIDIA HybridPower
Пользователь может конфигурировать систему на базе двух или трёх видеокарт семейства GeForce GTX 200 в режиме SLI при использовании материнских плат на базе соответствующих чипсетов nForce. В традиционном режиме Standard SLI (с двумя видеокартами) декларируется примерно 60-90% прирост производительности в играх; в режиме 3-way SLI – максимальное количество кадров в секунду при максимальных разрешениях экрана.
Следующая инновация – поддержка нового интерфейса DisplayPort с разрешениями выше 2560 х 1600, с 10-битным цветовым пространством (предыдущие поколения графики GeForce обладали внутренней поддержкой 10-битной обработки данных, но выводился только 8-битные компонентные цвета RGB). В рамках анонса новой серии графических процессоров семейства GeForce GTX 200 компания NVIDIA предлагает совершенно по-новому взглянуть на роль центрального и графического процессоров в современной сбалансированной настольной системе. Такой оптимизированный ПК , базирующийся на концепции гетерогенных вычислений (то есть, вычислений потока разнородных разнотипных задач), по мнению специалистов NVIDIA, обладает гораздо более сбалансированной архитектурой и значительно большим вычислительным потенциалом. Имеется в виду сочетание центрального процессора со сравнительно умеренной производительностью с наиболее мощной графикой или даже SLI-системой, что позволяет добиться пиковой производительности в наиболее тяжёлых играх, 3D и медиа приложениях. Иными словами, вкратце концепцию можно сформулировать так: центральный процессор в современной системе берёт на себя служебные функции, в то время как бремя тяжёлых вычислений ложится на графическую систему. Примерно те же выводы (правда, более комплексные и численно обоснованные) наблюдаются в серии наших статей, посвящённых исследованиям зависимости производительности от ключевых элементов системы, см. статьи Процессорозависимость видеосистемы. Часть I - Анализ ; Процессорозависимость видеосистемы. Часть II – Влияние объема кэш-памяти CPU и скорости оперативной памяти ; Ботозависимость, или зачем 3D-играм мощный CPU ; Процессорозависимость видеосистемы. Переходная область. "Критическая" точка частоты CPU . Впрочем, интенсивные вычисления с помощью современных графических видеокарт давно не новость, но именно с появлением графических процессоров семейства GeForce GTX 200 компания NVIDIA ожидает значительного повышения интереса к технологии CUDA. CUDA (Compute Unified Device Architecture) - вычислительная архитектура, нацеленная на решение сложных задач в потребительской, деловой и технической сферах - в любых приложениях, интенсивно оперирующих данными, с помощью графических процессоров NVIDIA. С точки зрения технологии CUDA новый графический чип GeForce GTX 280 это ни что иное как мощный многоядерный (сотни ядер!) процессор для параллельных вычислений. Как было указано выше, графическое ядро семейства GeForce GTX 200 можно представить как чип, поддерживающий графический и вычислительный режимы. В одном из этих режимов – "вычислительном", тот же GeForce GTX 280 превращается в программируемый мультипроцессор с 240 ядрами и 1 Гб выделенной памяти – этакий выделенный суперкомпьютер с производительностью под терафлоп, что в разы повышает результативность работы с приложениями, хорошо распараллеливающими данные, например, кодирование видео, научные вычисления и пр. Графические процессоры семейств GeForce 8 и 9 стали первыми на рынке, поддерживающими технологию CUDA, сейчас их продано более 70 млн. штук и интерес к проекту CUDA постоянно растёт. Подробнее узнать о проекте и скачать файлы, необходимые для начала работы можно . В качестве примера на приведённых ниже скриншотах показаны примеры прироста производительности вычислений, полученные независимыми пользователями технологии CUDA.
Подводя итог нашему краткому исследованию архитектурных и технологических улучшений, реализованных в новом поколении графических процессоров NVIDIA, выделим главные моменты. Второе поколение унифицированной архитектуры визуальных вычислений, реализованное в семействе GeForce GTX 200, является значительным шагом вперёд по сравнению с предшествовавшими поколениями GeForce 8 и 9.
По сравнению с предыдущим лидером GeForce 8800 GTX новый флагманский процессор GeForce GTX 280 обладает в 1,88 раза большим количеством процессорных ядер; способен обрабатывать примерно в 2,5 больше тредов на чип; обладает удвоенным размером файловых регистров и поддержкой вычислений с плавающей запятой с удвоенной точностью; поддерживает 1 Гб памяти с 512-битным интерфейсом; оборудован более эффективным диспетчером команд и улучшенными коммуникационными возможностями между элементами чипа; улучшенным модулем Z-буфера и компрессии, поддержкой 10-битной цветовой палитры и т.д. Впервые новое поколение чипов GeForce GTX 200 изначально позиционируется не только в качестве мощного 3D графического акселератора, но также в качестве серьёзного компьютерного решения для параллельных вычислений. Ожидается, что видеокарты GeForce GTX 280 с 1 Гб памяти появятся в рознице по цене порядка $649, новинки на базе GeForce GTX 260 с 896 Мб памяти – по цене около $449 (или даже $399). Проверить, насколько рекомендованные цены совпадают в реальной розницей, можно будет уже совсем скоро, поскольку по всем данным анонс семейства GeForce GTX 200 отнюдь не "бумажный", решения на этих чипах объявили многие партнёры NVIDIA, и в самом ближайшем времени новинки объявятся на прилавках. Теперь переходим к описанию первой видеокарты GeForce GTX 280, попавшей в нашу лабораторию, и к результатам её тестирования.