Сокращение затрат на проектирование и разработку ХД может быть достигнуто путем создания витрин данных (ВД). ВД – это упрощенный вариант ХД, содержащий только тематически объединенные данные (Рисунок 3).
Рисунок 3. Структура СППР с самостоятельными ВД
ВД содержит данные, ориентированные на конкретного пользователя, существенно меньше по объему, и для ее реализации требуется меньше затрат. ВД могут строиться как самостоятельно, так и вместе с ХД. ВД внедряются гораздо быстрее и быстрее виден эффект от их использования. Недостатками ВД является многократное хранение одних и тех же данных в различных ВД и отсутствие консолидированности на уровне предметной области.
Обычно информация попадает в ВД из ХД в этом случае ВД называются зависимыми. Возможна также ситуация, когда источником информации для пополнения ВД служат непосредственно OLTP-системы. Такие ВД, получившие название независимых, как правило, рассматриваются как временное решение, позволяющее достаточно быстро и с небольшими затратами решить наиболее важные задачи, оценить преимущества нового подхода, сформулировать некоторые рекомендации для более масштабного проекта разработки общего ХД.
Возможно также совмещение ХД и ВД в рамках одной СППР. ХД в этом случае представляет собой единый источник данных для всей предметной области, а ВД являются подмножествами данных из хранилища, организованными для представления информации по тематическим разделам данной области. В том случае, если пользователю, для которого создавалась ВД, содержащихся в ней данных недостаточно, то он может обратиться к ХД (Рисунок 4).

Рисунок 4. Структура СППР с ХД и ВД
Достоинствами такого решения являются простота создания и наполнения ВД, поскольку наполнение происходит из единого стандартизированного источника очищенных данных – из ХД, простота расширения за счет добавления новых ВД, а также снижение нагрузки на основное ХД.
Недостатки заключаются в избыточности, так как данные хранятся и в ХД, и в ВД, а также дополнительные затраты на разработку СППР с ХД и ВД.
Понятие и модель данных olap
Понятие olap
OLAP(OnlineAnalyticalProcessing) – технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений.
Основное назначение OLAP-систем – поддержка аналитической деятельности, произвольных запросов пользователей – аналитиков. ЦельOLAP-анализа – проверка возникающих гипотез.
Категории данных в хд
Все данные в ХД делятся на три категории (Рисунок 5):

Рисунок 5. Архитектура ХД
детальные данные – данные, переносимые непосредственно из OLTP-подсистем. Соответствуют элементарным событиям, фиксируемым вOLTP-системах. Подразделяются на:
измерения – наборы данных, необходимые для описания событий (товар, продавец, покупатель, магазин, …);
факты – данные, отражающие сущность события (количество проданного товара, сумма продаж, …);
агрегированные (обобщенные) данные – данные, получаемые на основании детальных путем суммирования по определенным измерениям;
метаданные – данные о данных, содержащихся в ХД. Могут описывать:
объекты предметной области, информация о которых содержится в ХД;
места и способы хранения данных;
действия, выполняемые над данными;
время выполнения различных действий над данными;
причины выполнения различных действий над данными.
Еще одним путем к обеспечению единого информационного пространства является использование хранилища данных.
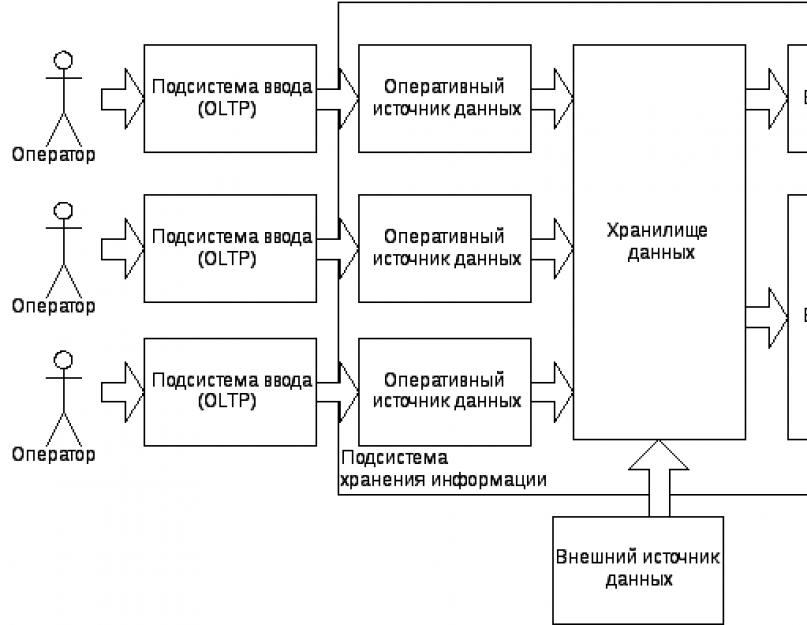
Особенностью информационной системы банка является необходимость обработки двух типов данных, а именно оперативных и аналитических. Поэтому в процессе функционирования ИБС приходится решать два класса задач: обеспечение повседневной работы банка по вводу и обработке информации и организация информационного хранилища в целях анализа данных для выявления тенденций развития, прогнозирования состояний, оценки и управления рисками и т.д. Задачи первого класса полностью решаются OLTP-системами (OnLine Transactional Processing - оперативная обработка транзакции). Для работы с аналитическими данными предназначены OLAP-системы (OnLine Analytical Processing -оперативная аналитическая обработка), которые построены по технологии хранилища данных и служат для агрегированного анализа больших объемов данных. Эти системы являются составной частью систем принятия решений или управленческих систем класса middle и top management, т.е. систем, предназначенных для пользовате-лей среднего и высшего уровня управления банка.
Таким образом, возможности ИБС могут быть расширены путем совместного использования транзакционных OLTP-систем и хранилищ данных (Data Warehouse).
Отличительными чертами хранилища данных являются:
- · ориентация на предметную область - в хранилище данных помещается только та информация, которая может быть полезной для работы аналитических систем;
- · защищенность - в хранилище можно добавлять информацию, но ее нельзя изменять, модифицировать и корректировать;
- · поддержка хронологических данных - для анализа требуется информация, накопленная за длительный период времени;
- · интеграция в едином хранилище ранее разъединенных данных, поступающих из различных источников, а также их проверка, согласование и приведение к единому формату;
- · агрегация - одновременное хранение в базе агрегированных и первичных данных, чтобы запросы на определение суммарных величин выполнялись достаточно быстро.
Таким образом, хранилище данных представляет собой специализированную базу данных, в которой собирается и накапливается информация, необходимая менеджерам банка для подготовки управленческих решений (о клиентах банка, кредитных делах, процентных ставках, курсах валют, котировках акций, состоянии инвестиционного портфеля, операционных днях филиалов и т.д.).
Хранилища данных принято изображать в виде многомерного куба. Величины, хранящиеся в ячейках этого куба и называемые фактами, являются количественными показателями, характеризующими деятельность кредитного учреждения. В частности, это могут быть данные об оборотах и остатках по счетам, структуре расходов и доходов, состоянии и движении денежных средств и т.д. Измерения куба, образующие одну из его граней, - это множество однотипных данных, предназначенных для описания фактов (например, филиалы банка, операционные дни, клиенты и валюты). Агрегация данных выполняется по измерениям куба, поэтому элементы измерений принято объединять в иерархические структуры. Так, филиалы часто группируются по территориальному признаку, клиенты - по отраслевому признаку, даты группируются в недели, месяцы, кварталы и годы. Каждая ячейка данного куба «отвечает» за конкретный набор значений по его отдельным измерениям, например оборотов балансовых счетов за день, квартал, год в разрезе филиалов. Над числовыми фактами, хранящимися в ячейках, можно выполнять различные математические и логические операции, позволяющие рассматривать представленную информацию под разными углами зрения. Операции проводятся с использованием методов управления данными. Вся совокупность методов называется репозиторием методов хранилища данных.
Данные загружаются в хранилище из оперативных систем обработки данных (OLTP-системы головной конторы и отдельных филиалов) и из внешних источников (официальные отчеты предприятий и банков, результаты биржевых торгов и т.д.). При загрузке данных в хранилище выполняется проверка целостности, сопоставимости, полноты загружаемых данных, а также проводятся их необходимое преобразование и трансформация.
Хранилище данных ориентировано на высшее и среднее руководство банка, ответственное за принятие решений и развитие бизнеса. Это руководители структурных, финансовых и клиентских подразделений, а также подразделений маркетинга, управления анализа и планирования.
Для работы с хранилищами данных используются специальные программные продукты, поскольку SQL-серверы не обеспечивают необходимого быстродействия по доступу к данным. Язык запросов при работе с хранилищем данных также отличается от SQL.
Одним из вариантов реализации на практике хранилища данных является построение витрин данных (Data Marts). Иногда их называют также киосками данных. Витриной данных является предметно-ориентированная совокупность данных, имеющая специфическую организацию. Содержание витрин данных, как правило, предназначено для решения некоего круга однородных задач одной области или нескольких смежных предметных областей. Например, для решения задач, связанных с анализом кредитных услуг банка, используется одна витрина, а для работ по анализу деятельности банка на фондовом рынке - другая.
Следовательно, витрина данных - это относительно небольшое специализированное хранилище данных, содержащее только тематически ориентированные данные и предназначенное для использования конкретным функциональным подразделением. Итак, функционально ориентированные витрины данных представляют собой структуры данных, обеспечивающие решение аналитических задач в конкретной функциональной области или подразделении компании (управление прибыльностью, анализ рынков, анализ ресурсов, анализ денежных потоков, управление активами и пассивами и т.д.). Таким образом, витрины данных можно рассматривать как маленькие хранилища, которые создаются в целях информационного обеспечения аналитических задач конкретных управленческих подразделений компании.
Создание витрины данных определяется необходимостью обеспечить возможности анализа данных той или иной предметной области наиболее оптимальными средствами.
Витрины данных и хранилище данных значительно отличаются друг от друга. Хранилище данных создается для решения корпоративных задач, присутствующих в корпоративной модели данных. Обычно хранилища данных создаются и приобретаются организациями с центральным подчинением, такими, как классические организации информационных технологий, например банк. Хранилище данных составляется усилиями всей корпорации. информационный хранилище данные транзакционный
Витрина данных разрабатывается для удовлетворения потребностей в решении конкретного однородного круга задач. Поэтому в одном банке может быть много различных витрин данных, каждая из которых имеет свой собственный внешний вид и свое содержание.
Следующее отличие состоит в степени детализации данных, так как витрина данных содержит уже агрегированные данные. В хранилище данных, наоборот, находятся максимально детализированные данные. Поскольку уровень интеграции в витринах данных более высок, чем в хранилищах, нельзя легко разложить степень детализации витрины данных в степень детализации хранилища. Но всегда можно последовать в обратном направлении и агрегировать отдельные данные в обобщенные показатели.
В отличие от хранилища витрина данных содержит лишь незначительный объем исторической информации, которая привязана только к небольшому отрезку времени и существенна только в момент, когда она отвечает требованиям решения задачи. Витрины данных можно представить в виде логически или физически разделенных подмножеств хранилища данных.
Витрины данных как правило создаются в многоуровневой технологии, которая оптимальна для гибкости анализа, но не оптимальна для больших объемов данных. Данные в такой витрине снабжены большим количеством индексов.
Структура витрин данных также ориентирована на многомерную организацию данных в виде куба. Однако их построение в силу ограниченности информационного диапазона, обеспечивающего потребности одной функциональной области, значительно проще и выгоднее, чем создание хранилища данных. Физическая структура базы данных в витрине данных создается по модели «звезда» (star schema), являющейся оптимальной при решении группы задач, для которой построена витрина, поскольку обеспечивает высокую скорость выполнения запросов посредством разделения данных. Звездообразная схема предполагает наличие одной центральной таблицы фактов (fact table), в которой содержатся суммирующие или фактические данные, и окружающих ее таблиц измерений (dimensional table), отражающих описательную информацию. Таблица фактов и таблицы измерений связаны между собой идентифицирующими связями, при этом ключевое поле таблицы фактов целиком состоит из всех первичных ключей таблиц измерений.
Существуют два типа витрин данных: зависимые и независимые. Зависимая витрина данных - это та, источником которой служит хранилище данных. Источником независимой витрины данных является среда первичных программных приложений. Зависимые витрины данных стабильны и имеют прочную архитектуру. Независимые витрины данных нестабильны и имеют неустойчивую архитектуру, по крайней мере, при пересылке данных.
Надо отметить, что витрины данных представляются идеальным решением наиболее существенного конфликта при проектировании хранилища данных - производительность или гибкость. В общем, чем более стандартизированной и гибкой является модель хранилища данных, тем менее продуктивно она отвечает на запросы. Это связано с тем, что запросы, поступающие в стандартно спроектированную систему, требуют значительно больше предварительных операций, чем в оптимально спроектированной системе. Направляя все запросы пользователя в витрины данных, поддерживая гибкую модель для хранилища данных, разработчики могут достичь гибкости и продолжительной стабильности структуры хранилища, а также оптимальной производительности для запросов пользователей.
Данные, попав в хранилище, могут быть распространены среди многих витрин данных для доступа пользовательских запросов. Эти витрины данных могут принимать различные формы - от баз данных «клиент-сервер» до баз данных на рабочем столе, OLAP-кубов или даже динамических электронных таблиц. Выбор инструментов для пользовательских запросов может быть широким и отображать предпочтения и опыт конкретных пользователей. Широкий выбор таких инструментов и простота их применения сделают их внедрение наиболее дешевой частью реализации проекта хранилища данных. Если данные в хранилище имеют хорошую структуру и проверенное качество, то их передача в другие витрины данных станет рутинной и дешевой операцией.
Использование технологий витрин данных, как зависимых, так и независимых, позволяет решать задачу консолидации данных из различных источников в целях наиболее эффективного решения задач анализа данных. При этом источниками могут быть различающиеся по архитектуре и функциональности учетные и справочные системы, в том числе и территориально разрозненные.
Витрина данных (Data Mart ) представляет собой узкоспециализированную подсистему хранилища данных (Data Warehouse), его отдельный элемент.
Если же некоторая область деятельности компании практически не связана с другими, то можно построить независимую витрину данных, работающую автономно, без привязки к централизованному корпоративному хранилищу. Или начать автоматизацию компании не с создания корпоративного хранилища данных, а с независимой витрины данных по предметной области, наиболее востребуемой в компании.
В этом случае под витриной данных понимается узко специализированное хранилище данных, обслуживающее одно из направлений деятельности компании.
Витрины данных по определению намного дешевле и проще в построении, чем хранилища данных, их внедрение не требует больших временных затрат и приносит быстрый и ощутимый эффект. В то же время необходимо понимать, что при таком подходе независимые витрины данных не будут создавать единой информационной системы компании, не будет единой системы извлечения информации, консолидации, управления и обслуживания.
Если компания небольшая, она может смело идти на создание автономных витрин данных. Если же компания крупная, то создание автономных витрин данных должно координироваться из единого центра с тем, чтобы в итоге придти к созданию единого хранилища данных компании.
Создание витрины данных
Создание витрины данных это создание соответствующей базы данных и системы ее загрузки. Если создание базы данных вопрос чисто технический, создание системы загрузки представляет основную сложность. Эта система содержит три этапа:
1. Извлечение данных требует точного знания структуры исходных систем. Структуры и взаимосвязи таблиц, структуры информации в исходной системе. Необходимо четко знать из каких таблиц и полей необходимо извлекать данные и какова структура этих данных.
2. Исходная система изначально никак не ориентирована на работу с витриной данных и данные, извлекаемые из нее, не предназначены для непосредственного использования и должны пройти ряд преобразований. Процесс этих преобразований зависит и от структуры исходных систем, и от требований к самой витрине данных, он может заключать в себе множество функций:
- Создание агрегатных данных
- Изменение форматов данных.
- Проверку достоверности и целостности данных.
- Удаление избыточных данных
- И т.д.
Все эти преобразования осуществляются только на этапе ввода данных в витрину, что обеспечивает высокую скорость извлечения данных из витрины и наилучшее представление этих данных с точки зрения пользователя. В конечном итоге это приводит к лучшему информационному обеспечению пользователя, и способствуют быстрому принятию им правильных управленческих решений.
3. Данные в витрине должны соответствовать данным исходных систем, которые, естественно, изменяются со временем. Поэтому инструменты, осуществляющие преобразования и загрузку данных в витрину должны запускаться периодически при определенных изменениях данных исходных систем и/или автоматически по определенному расписанию.
Из изложенного вытекает довольно важный вывод. Нельзя купить готовую витрину данных для своей компании. Витрина данных это эксклюзивный заказной продукт, который должен создаваться непосредственно под конкретную компанию, под всю ее специфику.
В хранилище данных хранится информация по всем аспектам деятельности организации.Витрина же данных (data mart ) – это специализированное хранилище данных, содержащее данные по одному из направлений деятельности предприятия. Витрины данных - это комплекс тематически связанных баз данных, относящихся к конкретным аспектам деятельности компании. В этом случае аналитики видят и работают не со всеми имеющимися в компании данными, а только с реально необходимыми данными. Это максимально приближает их к конечному пользователю.
Витрина данных представляет собой срез хранилища данных, представляющий собой массив тематической, узконаправленной информации, ориентированный на пользователей одной конкретной рабочей группы. Часто витрины еще называют киосками данных.
Т.к. Витрины Данных обычно содержат тематические подмножества заранее агрегированных данных, то их проще проектировать и настраивать. Витрина данных проектируются для ответов на конкретный ряд вопросов. Данные в витрине оптимизированы для использования определенными группами пользователей, что облегчает процедуры их наполнения, а также способствует повышению производительности
Т.к. конструирование хранилища данных - сложный процесс, который может занять несколько лет, некоторые организации вместо этого строят витрины данных, содержащие информацию для конкретных подразделений. Например, витрина данных отдела маркетинга может содержать только информацию о клиентах, продуктах и продажах и не включать в себя планы поставок. Существуют также витрина данных отдела продаж, витрина данных финансового отдела, витрина данных отдела анализа рисков и т.п. Несколько витрин данных для подразделений могут сосуществовать с основным хранилищем данных, давая частичное представление о содержании хранилища. Витрины данных строятся значительно быстрее, чем хранилище, но впоследствии могут возникнуть серьезные проблемы с интеграцией, если первоначальное планирование проводилось без учета полной бизнес-модели.
Независимые витрины данных (см. рис.10) часто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.
Конец работы -
Эта тема принадлежит разделу:
Учебное пособие учебной Дисциплины Информационные технологии в профессиональной деятельности
Учебное пособие учебной ДИСЦИПЛИНЫ Информационные технологии в.. Разработчик к э н доцент Ярошенко Е В..
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Все темы данного раздела:
Корпоративная информационная система
Решение управленческих задач на основе оперативной и достоверной информации при постоянном увеличении количества факторов, влияющих на работу предприятия и, одновременно, сокращении времени на прин
Методология планирования материальных потребностей предприятия. MRP системы
MRP (Material Requirement Planning)- Планирование потребности в материалах.
Методология планирования потребности в материальных ресурсах (MRP) заключается
Системы планирования производственных ресурсов. MRP II системы
MRP II (Manufacturing Resource Planning) – Планирование производственных ресурсов.
Основными целями MRP систем являются: удовлетворение потребности в материалах, компонент
Система планирования ресурсов предприятий. ERP система
ERP система (Enterprise Resource Planning System) – система планирования ресурсов предприятий.
Новым этапом в развитии и внедрении систем управления предприятием, основанн
Разновидности ERP-систем
ERP представляет собой интегрированный программный продукт, позволяющий управлять дистрибуцией, логистикой, запасами, доставкой, бухгалтерским учётом.
На российском рынке представлены все
CRM системы
CRM система (Customer Relationship Management System)– система управления взаимоотношениями с клиентами. Это современная стратегия, основанная на и
Цели, процессы, структура
Функциональность CRM охватывает маркетинг, продажи и сервис, что соответствуют стадиям привлечения клиента, самого акта совершения сделки (транзакция) и послепродажного обслуживания, то есть все те
Обзор CRM-решений в России
Если на западном рынке количество CRM-систем измеряется сотнями, то в России представлен довольно узкий спектр решений, в основном крупных поставщиков, давно предлагающих свои ERP-системы. В то же
SRM системы
SRM система (Supplier Relationship Management) – это системы управления отношениями с поставщиками. SRM система - инструмент укрепления отношений с поставщиками. Многие предприятия стараются повыси
Базы данных и хранилища данных
Часто в речи мы подменяет слово «информация» словом «данные». Между данными и информацией действительно существует тесная связь. Существование одного без другого невозможно.
Преобр
Расхождения в требованиях к хранению данных в БД и ХД
В базе данных хранятся только последние значения какой-либо информации (например, текущее значение счета клиента, текущее значение имени и параметров клиента). В хранилище данных будет содержаться
Проблема хранения исходной информации компании
Основное назначение Хранилищ данных -обеспечение менеджеров всех уровней управления аналитическими данными для принятия решений в кратчайшие сроки и с минимумом затрат. Основные пользователи информ
Business Intelligence (BI)
Внедрение BI-технологий в различные программные продукты является новым и перспективным подходом к управлению данными и знаниями компании.
Впервые о таком понятии, как «bus
Многомерный анализ данных на основе OLAP
Для решения аналитических задач, связанных со сложными расчетами, прогнозированием, моделированием сценариев «Что, если…» применяется технология многомерного анализа данных - Технол
Технология Data Mining
По данным компании Gartner, неструктурированные документы составляют более 80% корпоративных данных, а количество внешних источников (интернет-ресурсов, блогов, форумов, СМИ) исчисл
Типы закономерностей, которые позволяют выявлять методы Data Mining
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогн
Процесс принятия решений
Как принять правильное решение? Этот вечный вопрос мы задаём себе на протяжении всей жизни. И как часто принимаем решения в лучшем случае на основе интуиции. Методами рационального
Задачи принятия решения
Задача принятия решения имеет две главные разновидности:
1. задача выбора (выбрать или отвергнуть несколько вариантов из группы возможных)
2. задача распр
Технология принятия решения
При принятии решения все решения можно разделить на четыре большие группы:
1. решения, основанные на теории управления
2. решения, основанные на модели Карнеги (модель ограниченно
Влияние быстро меняющейся окружающей среды на процесс принятия решения
В настоящее время в некоторых отраслях темпы конкурентных и технологических изменений настолько стремительны, что сведения о рынке оказываются либо недоступными, либо устаревшими, стратегические ок
Ошибки при принятии управленческих решений
При принятии решений в организациях часто делаются ошибки, особенно тогда, когда управленческие решения принимаются в условиях крайней неопределенности. Менеджеры просто не в силах определить или п
Системы поддержки принятия решений (СППР)
Система поддержки принятия решений (СППР) - это автоматизированная информационная система, помогающая лицам, принимающим решение (ЛПР) сделать мотивированный выбор лучшего варианта
Структура сппр
Основными компонентами СППР являются: оборудование (рабочие станции), программное обеспечение (СППР-генераторы), базы данных, базы моделей. В СППР используются аналитические модели, специализирован
Экспертные системы
ИС управления предназначены для удовлетворения информационных потребностей сотрудников фирмы, имеющих дело с принятием решений. Эти системы необходимы для того, чтобы увидеть тенден
Участники разработки и создания экспертных систем
Эксперт -специалист, имеющий репутацию человека, умеющего находить правильные решения в конкретной предметной области.
Инженер знаний –ИТ-специалист, имею
Реализация
Практическая разработка ЭС с использованием выбранных инструментальных средств: традиционных языков программирования, языков обработки списков и процедурных языков, языка логического программирован
Финансовый риск
Финансовый риск связан с возможностью невыполнения фирмой своих финансовых обязательств. Это опасность денежных потерь в результате наступления ущерба из-за проведения каких-либо операций в финансо
Стратегия управления рисками
Риском необходимо управлять, используя разнообразные методы, позволяющие прогнозировать наступление рискового события и вовремя принимать меры к снижению степени риска. В российской практике риск п
Управление рисками ИТ-проекта
Управление рисками ИТ-проекта, в целом, включает следующие процессы:
выявление и идентификацию предполагаемых рисков; анализ и оценку рисков; выбо
При разработке хранилища данных, возникают и должны быть решены следующие вопросы:
1) какие данные должны быть помещенный в хранилища
2) Как найти и извлечь эти данные
3) Как обеспечить корректность данных.
По сути если вы знаете ответы на эти вопросы, то вы определяете спектр задач для которых предназначенная проектируемая вами база данных и соответственно круг пользователей. Таким образом возникает задача сбора, очистки и агрегирования.
Под сбором данных понимается процесс, состоящий в организации передачи данных из внешнего источника в хранилище. Сегодня этот процесс не предоставляет принципиальных трудностей. Почти любой программист может сделать перекачку из одной базы в другую.
Вторая часть связанная со сбором – это периодическое пополнение. Здесь надо решить как будет пополняться База данных ежемесячно, ежеквартально и т.д. Решается это как правило с использованием механизмом событий, тут в ручную никто конечно ничего не делает. Составляется программа, которая по каким то события автоматически это дело делает. Попадание этих данных на склад, это не самое простой процесс, поскольку данные надо обустроить – обеспечить регулярность попадания, попадание в требуемом виде. Например: город Москва должен быть написан идентично (кто-то напишет маленькими буквами, кто-то большими). Проблема исключения дубликата, такие сведения могут быть возможны. Вторая проблема при этом – восстановление пропущенных данных. Например: для мед учреждение характерно и в силу той или иной болезни, врач заносит данные не все. Бывает анализ мочи – снимают показания не для всех параметров, а для определенной болезни. Сняли 5 данных … а в таблице 20 показателей. Восстановление пропущенных данных очень большая проблема, потому как не ясно решить. Потому как что куда поставить. С одной стороны это мешает обобщению отсутствие данных, потому как пусто нужно просуммировать с какими-то конкретными данными и сразу показатели по каким то колонкам ухудшаются. А с другой стороны написать фиктивно, что-то не соответствующие действительности, для одной болезни показатель важен, а для другой нет. (ой дальше его понесло). Удаление нежелательных символов, приведение к единому формату. Таким образом здесь при сборе данных очень важно разрабатывать сложную систему, которая начинает приводить к общему виду. Это не сложная, но кропотливая и долгая работа учитывать все нюансы. К примеру: продавцы в разных местах могут одну и туже кассету назвать по разному.
Витрины данных
Концепция витрин данных была предложена в 1992 году. Появление концепции витрин данных связано с тем что оказалось, не смотря на то что хранилище данных вещь хорошая, но разработка ее и внедрение происходит в течение нескольких лет. И это сказывается на затратах предприятиях, которые долго не окупаются. Из-за того что часто информационная структура компаний бывает сложна и запутана – сделать хранилище данных не представляется сделать одним махом. Вторых проблема как уже было сказано с инвестициями. В третьих очень часто существующие операционные системы ОЛТП приходится тоже переделывать, чтобы они тоже хранили или запоминали те данные, которые нужны для кубов. Важный пункт то, что существующие технологии в принятиях решений трудно поддаются модификации и изменению и поэтому под них приходиться подстраиваться, то есть подстраивать свои данные и под существующие технологии. Поэтому появление витрин данных была попыткой смягчить требования к хранилищам данных. По сути под витриной данных понимают специализированные хранилища, обслуживающие одно из направлений деятельности. К примеру: маркетинг, учет запасов и ст.д. Из всего хранилища данных выделяют направления и они автоматизируются. Как правило в 1 очередь берутся те процессы которые легко автоматизируются, хорошо изучены, не так сложны и внедрение этих витрин данных позволяет уже на маленьких примерах быстро получить окупаемость. Таким образом очень часто разработка хранилища данных и витрин данных идет параллельно, то есть в перспективе нужно хранилище данных, но походу разрабатываются витрины, которые начинают давать отдачу, с другой стороны позволяют разработчикам показать заказчикам, что эффект есть. Также как и для хранилищ данных стандартом является структура звезды и таблица фактов.
Витрины данных имеют ряд несомненных достоинств:
-ну во-первых, аналитики, которые работают с витриной данных, всегда работают с теми данными, которые легко понятные и видны. Например: аналитик из отдела сбыта. У него не заботится голова поставками, производством и т.д. главное у него есть набор фирм, куда он сбывает какой-то продукт. У него голова не болит как, чего, производство и т.д.
— Кроме того поскольку витрины данных гораздо меньше баз данных, то уже требуется большие вложения в мощность вычислительной техники.
На сегодня имеется достаточно много промышленных систем, которые подходят под понятие витрин данных. Прежде всего фирма информатика выпустила продукт PowerMarcSuit. Далее Stgentehnology выпустила DataMapSollution. Oracale выпустила продукт DataMapSuit. В 94 году было предложено объединить концепции витрин данных и хранилища данных и использовать хранилища для витрин данных. Поскольку программное обеспечение для анализа хранилищ данных составляется очень долго, а само хранилище сделать трудно, собрать данные соединить в базу не так сложно, трудно приделать ей программное обеспечение, которое анализ бы делала, поэтому целью объединения было то, чтобы сами витрины данных основывались бы на данных, которые хранятся в хранилищах. Ну и было предложено так называемая многоуровневая архитектура из трех уровней.
Первый уровень общекорпоративной базы данных на основе распределенной СУБД.
Второй уровень базы данных подразделений. Как правило на основе десктоп СУБД. Здесь храниться агрегированные данные, то есть реляционные базы данных хранят операционные данные, а агрегированные данные отбрасываются на 2 уровень, где можно использовать Десктоп СУБД.
И третий уровень это конкретные места пользователей-аналитиков. Те пользователи, которые на основе витрин данных делают какие-то выводы.