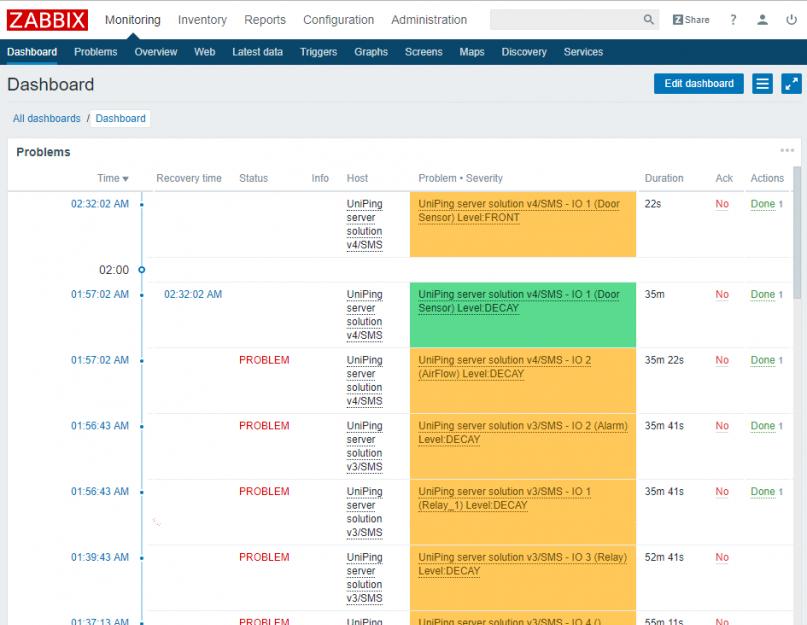
Примеры применения
31.10.2018При выборе системы мониторинга ИТ-инфраструктуры предприятия нужно учесть ряд факторов: в первую очередь оценить соответствие функционала системы мониторинга вашим техническим и бизнес-требованиям и рассмотреть особенности развёртывания и сопровождения, чтобы подобрать инструмент, соответствующий вашей инфраструктуре и уровню компетенции ИТ-специалистов.
В этой статье мы рассмотрим особенности, различия и схожие черты двух популярных систем мониторинга Zabbix vs Nagios .
Краткий обзор продуктов

Использование систем мониторинга с оборудованием NetPing

Ранее в нашем блоге мы неоднократно рассматривали возможность использования систем мониторинга Zabbix и Nagios с и компании .
Процесс подключения устройств к системам мониторинга рассматривается в следующих статьях:
Процесс организации мониторинга при помощи интеграции устройств и систем мониторинга Zabbix и Nagios рассматривается в статьях:
Процесс организации отправки пользовательских сообщений о событиях из систем мониторинга Zabbix или Nagios посредством SMS-сообщений с использованием GSM-модема встроенного в устройства рассматривается в статьях:
Также в нашем блоге доступны для более удобного добавления устройств к мониторингу в системе Zabbix и другие статьи о практическом применении интеграции системы мониторинга Zabbix с устройствами :
- Карта пользователя и уведомления от устройств NetPing в Zabbix
Достоинства и недостатки
Zabbix
Достоинства | Недостатки |
|---|---|
Полностью бесплатный. | Мониторинг серверов и рабочих станций осуществляется через постоянно запущенный агент. |
Конфигурирование через web-интерфейс и с помощью API. | Все данные мониторинга хранятся в базе, что в крупных сетях требует выделения дополнительных вычислительных мощностей для обслуживания базы данных. |
Вся конфигурация хранится в базе, управляется через web-интерфейс. | Не обеспечивается отказоустойчивость. |
Единая точка доступа для пользователей. | |
Разграничение доступа к данным и конфигурации. | |
Минимальный интервал между замерами – 1 секунда. | |
С серверов собираются не результаты проверок (сломалось или нет), а количественные характеристики работы, которые анализируются на стороне сервера. | |
Время хранения данных ограничено лишь дисковым пространством. | |
Развитые возможности анализа собранных данных. |
Nagios
Достоинства | Недостатки |
|---|---|
Простой формат конфигурационного файла. При наличии минимального опыта в программировании можно писать собственные плагины для Nagios. | Нет возможности конфигурирования через web-интерфейс (для бесплатной версии). Все изменения конфигурации выполняются правкой файлов конфигурации с последующим полным перезапуском сервера Nagios (~10-15 минут). |
Позволяет оставлять комментарии с меткой времени. | Слишком большой интервал между проверками и замерами параметров. |
Существуют плагины на все случаи жизни от сторонних производителей. |
И сетевого оборудования , написанная Алексеем Владышевым.
Для хранения данных используется MySQL , PostgreSQL , SQLite или Oracle . Веб-интерфейс написан на PHP . ZABBIX поддерживает несколько видов мониторинга:
- Simple checks - может проверять доступность и реакцию стандартных сервисов, таких как SMTP или HTTP, без установки какого-либо программного обеспечения на наблюдаемом хосте.
- ZABBIX agent - может быть установлен на UNIX-подобных или Windows -хостах для получения данных о нагрузке процессора , использования сети, дисковом пространстве и т. д.
- External check - выполнение внешних программ. ZABBIX также поддерживает мониторинг через SNMP .
Энциклопедичный YouTube
-
1 / 5
Zabbix начался в 1998 году как проект внутреннего программного обеспечения. Спустя 3 года, в 2001 году, он был выпущен публично под лицензией GPL . Прошло более трёх лет до выхода первой стабильной версии - 1.0, которая была выпущена в 2004.
График релизов Дата Релиз Zabbix 1.0 1998 ПО Zabbix началось как внутренний проект в банке Алексеем Владышевым 7 Апреля 2001 Zabbix 1.0alpha1 был выпущен с лицензией GPL 23 Марта 2004 Выпущен Zabbix 1.0 Zabbix 1.1 6 Февраля 2006 Выпущен Zabbix 1.1 Zabbix 1.4 29 Мая 2007 Выпущен Zabbix 1.4 Zabbix 1.6 11 Сентября 2008 Выпущен Zabbix 1.6 Zabbix 1.8 7 Декабря 2009 Выпущен Zabbix 1.8 Zabbix 2.0 21 Мая 2012 Выпущен Zabbix 2.0 Zabbix 2.2.1 21 Декабря 2013 Выпущен Zabbix 2.2.1 Zabbix 2.4.0 11 Сентября 2014 Выпущен Zabbix 2.4.0 Zabbix 3.0 16 Февраля 2016 Выпущен Zabbix 3.0 Архитектура
- Zabbix-сервер - это ядро программного обеспечения Zabbix. Сервер может удаленно проверять сетевые сервисы, является хранилищем, в котором хранятся все конфигурационные, статистические и оперативные данные, и он является тем субъектом в программном обеспечении Zabbix, который оповестит администраторов в случае возникновения проблем с любым контролируемым оборудованием.
- Zabbix-прокси - собирает данные о производительности и доступности от имени Zabbix-сервера. Все собранные данные заносятся в буфер на локальном уровне и передаются Zabbix-серверу, к которому принадлежит прокси-сервер. Zabbix-прокси является идеальным решением для централизованного удаленного мониторинга мест, филиалов, сетей, не имеющих локальных администраторов. Он может быть также использован для распределения нагрузки одного Zabbix-сервера. В этом случае, прокси только собирает данные, тем самым на сервер ложится меньшая нагрузка на ЦПУ и на ввод-вывод диска.
- Zabbix-агент - контроль локальных ресурсов и приложений (таких как жесткие диски, память, статистика процессора и т. д.) на сетевых системах, эти системы должны работать с запущенным Zabbix-агентом. Zabbix-агенты являются чрезвычайно эффективными из-за использования родных системных вызовов для сбора информации о статистике.
- Веб-интерфейс - интерфейс является частью Zabbix-сервера, и, как правило (но не обязательно), запущен на том же физическом сервере, что и Zabbix-сервер. Работает на PHP , требует веб сервер (например, Apache).
Обзор возможностей
- Распределённый мониторинг вплоть до 1000 узлов. Конфигурация младших узлов полностью контролируется старшими узлами, находящимися на более высоком уровне иерархии.
- Сценарии на основе мониторинга
- Автоматическое обнаружение
- Централизованный мониторинг лог-файлов
- Веб-интерфейс для администрирования и настройки
- Отчетность и тенденции
- SLA мониторинг
- Поддержка высокопроизводительных агентов (zabbix-agent) практически для всех платформ
- Комплексная реакция на события
- Поддержка SNMP v1, 2, 3
- Поддержка SNMP ловушек
- Поддержка IPMI
- Поддержка мониторинга JMX приложений из коробки
- Поддержка выполнения запросов в различные базы данных без необходимости использования скриптовой обвязки
- Расширение за счет выполнения внешних скриптов
- Гибкая система шаблонов и групп
- Возможность создавать карты сетей
Автоматическое обнаружение
- Автоматическое обнаружение по диапазону IP-адресов, доступным сервисам и SNMP проверка
- Автоматический мониторинг обнаруженных устройств
- Автоматическое удаление отсутствующих хостов
- Распределение по группам и шаблонам в зависимости от возвращаемого результата
Низкоуровневое обнаружение
Низкоуровневое обнаружение может быть использовано для обнаружения и для начала мониторинга файловых систем, сетевых интерфейсов. Начиная с Zabbix 2.0, поддерживаются три встроенных механизма низкоуровневого обнаружения:
- обнаружение файловых систем
- обнаружение сетевых интерфейсов
- обнаружение нескольких SNMP OID’ов
Системные требования для установки ZABBIX-сервера
Поддерживаемые платформы
Платформа ZABBIX-сервер ZABBIX-агент AIX Поддерживается Поддерживается FreeBSD Поддерживается Поддерживается HP-UX Поддерживается Поддерживается Linux Поддерживается Поддерживается Mac OS X Поддерживается Поддерживается Novell Netware - Поддерживается OpenBSD Поддерживается Поддерживается SCO Open Server Поддерживается Поддерживается Solaris Поддерживается Поддерживается Tru64/OSF Поддерживается Поддерживается Windows NT 4.0, Windows 2000, Windows 2003, Windows XP, Windows Vista - Поддерживается Доброго времени суток. В данную серию статей я хочу посвятить одной из замечательных систем мониторинга - zabbix. По долгу службы пришлось мне искать систему мониторинга. Я останавливался на nagios, cacti, mrtg. Но они мне не подошли. И вот я нашел zabbix. Ознакомившись с документацией, я понял, что zabbix - это то, что надо...
И так, что же такое zabbix? Zabbix - это система распределенного мониторинга, которая позволяет мониторить многочисленные параметры сети и узлов сети. Zabbix распространяется под лицензией GPL, а это означает - она бесплатна.Возможности zabbix
Как я уже говорил выше, zabbix обладает огромными возможностями, а конкретно:- мониторинг доступности
- мониторинг по SNMP
- мониторинг по IPMI
- мониторинг по JMX
- собственная настройка порогов срабатывание проблемы
- настройка оповещений
- группировка по хостам, по собираемым данным
- использование шаблонов
- система прав доступа
- и многое другое
Подготовка к установке zabbix
Сразу хочу отметить, что установку я буду производить на Linux, а точнее на Ubuntu Server.
Установку я буду производить из исходников. Поэтому давайте в начале скачаем исходный код Zabbix с . Разархивируем скачанный архив. Для этого переходим в директорию с архивом и вводим комманду:
$ tar -zxvf zabbix-2.0.0.tar.gz
Отлично. Следующим этапом необходимо подготовить нашу систему к установке zabbix. Нам понадобятся следующие пакеты:- snmp
- libsnmp-dev
- snmpd
- libcurl4-openssl-dev
- fping
Если данные пакеты не установлены в системе, установим их:sudo apt-get install snmp libsnmp-dev snmpd libcurl4-openssl-dev fping
После того как все необходимые пакеты установлены, необходимо создать группу zabbix и пользователя zabbix:
groupadd zabbix
useradd -g zabbix zabbix
Теперь нужно подготовить базу данных. Zabbix может работать как с MySQL, так и с PostgreSQL. (поддерживает и другие, Вы можете ознакомиться в официальной документации). Производитель рекомендует использовать в качестве сервера базы данных PostgreSQL, если Вы собираетесь мониторить более 50 узлов.
Но я использую MySQL и на данный момент у меня на мониторинге стоит 123 узла - пока проблем не наблюдал. В дальнейшем планируется увеличение узлов, тогда и посмотрим. И так, создаем базу данных в MySQL:
shell> mysql -u <имя пользователя> -p
<пароль>
mysql> create database zabbix character set utf8
mysql> quit
Теперь заходим в директорию с разархивированными исходниками zabbix. В ней в директории./database/mysql/ находятся три файла:- schema.sql
- images.sql
- data.sql
mysql -u <пользователь> -p < schema.sql
или из самого mysql:
mysql>use zabbix
mysql>source schema.sql
По аналогии запускаем и остальные файлы images.sql и data.sql
Порядок обязателен.
Все на этом этап подготовки к установке завершен. Теперь можно приступить к самой установке zabbix.Установка мониторинга zabbix
Переходим в директорию с кодом zabbix и запускаем:
sudo ./configure --enable-server --enable-agent --with-mysql --with-net-snmp --with-libcurl
Мы подключаем сам zabbix сервер, zabbix агент, поддержку snmp.
Если все прошло хорошо (а об ошибках с которыми я столкнулся и как их решить я опишу ниже) запускаем установку:
sudo make install
На этом установка завершена. Осталось произвести небольшую конфигурацию сервера и агента zabbix.Первоначальная настройка zabbix
Для работы zabbix сервера необходимо произвести первоначальные настройки. Открываем файл конфигурации /usr/local/etc/zabbix_server.conf (так в Ubuntu) и редактируем его:
DBName=[имя базы данных, у меня zabbix]
DBUser = [имя пользователя доступа к MySQL]
DBPassword = [пароль доступа к базе данных]
Вот в принципе и все. Если у Вас MySQL настроен по умолчанию, то все должно заработать.
Теперь настроим агент zabbix. Если zabbix агент находится на той же машине, где и zabbix сервер, то ничего менять не надо. Если же zabbix агент находиться на другой машине, то открываем /usr/local/etx/zabbix_agentd.conf ищем строку Server=127.0.0.1 и заменяем на Server=[адрес zabbix сервера]
Вот и все. Запускаем zabbix сервер и агент командами:
zabbix_server
zabbix_agentd
Пришло время к установке web интерфейса для zabbix.Установка web интерфейса zabbix
Создаем виртуальный хост zabbix, как это сделать я писал в своей статье про . Копируем в директорию созданного виртуального хоста файлы из директории с zabbix/frontends/php
Заходим на наш хост. Тут нужно немного подправить наш php.ini согласно требованиям zabbix.- memory_limit - задает максимальную величину использования памяти скриптом
- post_max_size - устанавливает максимальный размер данных передаваемых методом POST
- upload_max_filesize - максимальный размер загружаемого файла
- max_execution_time - время выполнения скрипта
- max_input_time - максимальное время в секундах, в течение которого скрипт должен разобрать все входные данные
- timezone - в php.ini date.timezone, устанавливает часовой пояс
- datebase support - тип базы данных
- bcmath - вычисления с произвольной точностью
- mbstring - работа с многобайтными строками
- sockets - работа с сокетами
- gd - графическая библиотека
- и др.
После того как все требования zabbix будут удовлетворены, можно перейти к следующему шагу.
На этом шаге нам надо выбрать тип базы данных (в моем случае это MySQL), укаазать адрес сервера (у меня localhost), название базы данных (для моего случае это zabbix), логин и пароль для доступа к базе данных:
После ввода всех данных жмем “Test connection”, если тест прошел успешно переходим к следующему шагу, если же нет, то проверяем введенные данные. Если вся информация введена правильно - переходим к установке, нет - возвращаемся и исправляем.
Как видите у меня все прошло успешно. Учтите, что файл zabbix.conf.php должен быть открыт на запись. Как это сделать я описывал в своей статье об Жмем “Finish”. И переходим к окну авторизации.
По умолчанию логин - Admin, пароль - zabbix.
На этом установка завершена.
Давайте рассмотрим проблемы с которыми я столкнулся при установке zabbix и как их решить.Проблемы возникающие при установке zabbix и их решение
Во время установки мониторинга я столкнулся с двумя ошибками:
- При выполнении configure у меня выскочила ошибка “MySQL library not found”. Решается данная проблема легко, путем установки libmysqlclient16-dev
- Вторая ошибка выскочила при выполнении make install “The programm ‘make’ is currently not installed”. Тут все просто, у меня не установлена программа make.
А на этом я завершаю статью, посвященную установке мониторинга zabbix. В следующей статье мы познакомимся с основными понятиями, затем разберем интерфейс и перейдем к настройке мониторинга хостов (устройств нашей сети). Так, что следите за выходом новых статей.- Перевод
Тех, кто использует или собирается использовать Zabbix в промышленных масштабах, всегда волновал вопрос: сколько реально данных сможет Заббикс «переварить» перед тем как окончательно поперхнется и подавится? Часть моей недавней работы как раз касалось этого вопроса. Дело в том, что у меня есть огромная сеть, насчитывающая более 32000 узлов, и которая потенциально может полностью мониториться Заббиксом в будущем. На форуме давно идут обсуждения о том, как оптимизировать Zabbix для работы в больших масштабах, но, к сожалению, мне так и не удалось найти законченное решение.
В этой статье я хочу показать, как я настраивал свою систему, способную обрабатывать реально много данных. Чтобы вы понимали, о чем речь, вот просто картинка со статистикой системы:

Для начала хочется обговорить, что реально означает пункт «Required server performance, new values per second (далее NVPS) (Требуемое быстродействие в секунду)». Так вот, он не соответствует тому, сколько реально данных попадает в систему в секунду, а является простым математических подсчетом всех активных элементов данных с учетом интервалов опроса. И тогда получается, что Zabbix-trapper в расчете не участвует. В нашей сети trapper использовался достаточно активно, так что давайте посмотрим, сколько реально NVPS в рассматриваемом окружении:

Как показано на графике, в среднем Zabbix обрабатывает около 9260 запросов в секунду. Кроме того, в сети бывали и короткие всплески до 15000 NVPS , с которыми сервер без проблем справился. Честно говоря, это здорово!
Архитектура
Первое, в чем стоит разобраться это архитектура системы мониторинга. Должен ли Zabbix быть отказоустойчивым? Будут ли иметь значение один-два часа простоя? Какие последствия ждут, если упадет база данных? Какие потребуются диски для базы, и какой настраивать RAID? Какая нужна пропускная способность между Zabbix-сервером и Zabbix-proxy? Какая максимальная задержка? Как собирать данные? Опрашивать сеть (пассивный мониторинг) или слушать сеть (активный мониторинг)?Давайте рассмотрим каждый вопрос детально. Если быть честным, то вопрос сети я не рассматривал при разворачивании системы, что привело к проблемам, которые в дальнейшем было трудно продиагностировать. Итак, вот общая схема архитектуры системы мониторинга:

Железо
Точно подобрать правильное железо процесс не из легких. Главное что я здесь сделал, это использовал SAN для хранения данных, так как база Заббикса требует много I/O дисковой системы. Проще говоря, чем быстрее диски у сервера БД, тем больше данных сможет обработать Заббикс.Конечно, ЦПУ и память тоже очень важны для MySQL. Большое количество ОЗУ позволяет Заббиксу хранить часто читаемые данные в памяти, что естественно способствует быстродействию системы. Изначально я планировал для сервера БД 64ГБ памяти, однако все замечательно работает и на 32ГБ до сих пор.
Сервера, на которых стоит сам zabbix_server, тоже должен иметь достаточно быстрые ЦПУ, так как необходимо, чтобы он спокойно обрабатывал сотни тысяч триггеров. Памяти же хватило бы и 12ГБ - так как на самом Заббикс сервере не так много процессов (практически весь мониторинг идет через прокси).
В отличии от СУБД и zabbix_server, Zabbix-прокси не требуют серьезного железа, поэтому я использовал «виртуалки». В основном собираются активные элементы данных, так что прокси служат как точки сбора данных, сами же практически ничего не опрашивают.
Вот сводная таблица, что я использовал в своей системе:
Zabbix server Zabbix БД Zabbix proxies SAN HP ProLiant BL460c Gen8
12x Intel Xeon E5-2630
16GB memory
128GB disk
CentOS 6.2 x64
Zabbix 2.0.6HP ProLiant BL460c Gen8
12x Intel Xeon E5-2630
32GB memory
2TB SAN-backed storage (4Gbps FC)
CentOS 6.2 x64
MySQL 5.6.12VMware Virtual Machine
4x vCPU
8GB memory
50GB disk
CentOS 6.2 x64
Zabbix 2.0.6
MySQL 5.5.18Hitachi Unified Storage VM
2x 2TB LUN
Tiered storage (with 2TB SSD)Отказоустойчивость Zabbix server
Вернемся к архитектурным вопросам, что я озвучивал выше. В больших сетях по понятным причинам не работающий мониторинг является настоящей катастрофой. Однако, архитектура Заббикса не позволяет запускать больше одного экземпляра процесса zabbix server.Поэтому я решил воспользоваться Linux HA с Pacemaker и CMAN. Для базовой настройки прошу глянуть мануал RedHat 6.4 . К сожалению, инструкция была изменена с момента, как я ее использовал, однако конечный результат должен получиться таким же. После базовой настройки дополнительно я настроил:
- Так как общий IP-адрес всегда используется активным Zabbix-сервером, то отсюда следует три преимущества:
- Всегда легко найти какой сервер активен
- Все соединения от Zabbix сервера всегда с одного и того же IP (После установки параметра SourceIP= в zabbix_server.conf)
- Всем Zabbix-прокси и Zabbix-агентам в качестве сервера просто указывается общий IP
- Так как общий IP-адрес всегда используется активным Zabbix-сервером, то отсюда следует три преимущества:
- Процесс zabbix_server
- в случае фейловера zabbix_server будет остановлен на старом сервере и запущен на новом
- Symlink для заданий cron
- Симлинк указывает на директорию, в которой лежат задания, которые должны выполняться только на активном Zabbix-сервере. Crontab должен иметь доступ ко всем задания через этот симлинк
- В случае фейловера симлинк удаляется на старом сервере и создается на новом
- crond
- В случае фейловера crond останавливается на старом сервере и запускается на новом активном сервере
Отказоустойчивость СУБД
Очевидно, что никакой пользы от отказоустойчивости серверов с Zabbix-серверами, если база данных может упасть в любой момент. Для MySQL есть огромное количество путей создать кластер, я расскажу о способе, что я использовал.Я также использовал Linux HA с Pacemaker и CMAN и для базы данных. Как оказалось, в нем есть пару отличный возможностей для управления репликацией MySQL. Я использую (использовал, смотри раздел «открытые проблемы») репликацию для синхронизации данных между активным(master) и резервным(slave) MySQL. Для начала, точно также как и для серверов Zabbix-сервера, мы делаем базовую настройку кластера. Затем в дополнении я настроил:
- Общий IP-адрес (shared IP address)
- В случае фейловера, IP-адрес переходит на сервер, который становится активным
- Так как общий IP-адрес всегда используется активным Zabbix-сервером, то отсюда следует два преимущества:
- Всегда легко найти, какой сервер активен
- В случае фейловера, на самом Zabbix-сервере не требуется никаких действий, чтобы указать адрес нового активного сервера MySQL
- Общий дополнительный (slave) IP-адрес
- Этот IP-адрес может использоваться, когда к происходит запрос на чтение к базе. Таким образом, запрос может обработать slave-сервер MySQL, если он доступен
- дополнительный адрес может быть у любого из серверов, это зависит от следующего:
- если slave-сервер доступен, и часы не отстают на более чем 60 секунд, то адрес будет у него
- В обратном случае адрес будет у master-сервера MySQL
- mysqld
- В случае фейловера новый сервер MySQL станет активным. Если после этого старый сервер вернется в строй, то он останется slave для уже новоиспечённого master.
Zabbix-прокси
Если по какой-то причине вы не слышали о Zabbix-прокси, то, пожалуйста, срочно посмотрите в документации . Прокси позволяют Заббиксу распределить нагрузку мониторинга на несколько машин. После этого уже каждый Заббикс прокси отсылает все собранные данные на Заббикс сервер.Работая с Заббикс прокси важно помнить:
- Заббикс прокси способны обрабатывать очень серьезные объемы данных, если их настроить как следует. Так, например, во время тестов, прокси (назовем ее Proxy А) обрабатывала 1500-1750 NVPS без каких либо проблем. И это виртуалка с двумя виртуальными ЦПУ, 4ГБ ОЗУ и БД SQLite3. При этом прокси находилась на одной площадки с самим сервером, так что задержки на сети можно было просто не учитывать. Также почти все, что собиралась, было активными элементами данных Заббикс агента
- Ранее я уже упоминал, как важна задержка на сети при мониторинге. Так вот, это действительно так, когда речь идет о крупных системах. Фактически, количество данных, которое может отослать прокси, не отставая, напрямую зависит от сети.
На графике ниже хорошо видно как накапливаются проблемы, когда задержка сети не учитывается. Прокси, который не успевает:

Пожалуй, достаточно очевидно, что очередь из данных для передачи не должна увеличиваться. График относится к другому Заббикс-прокси (Proxy B), которая ничем по железу не отличается от Proxy A, но может передавать без проблем только 500NVPS а не 1500NVPS, как Proxy A. Отличие как раз в том, что B находится в Сингапуре а сам сервер в Северной Америке, и задержка между площадками порядка 230мс. Данная задержка имеет серьезный эффект, учитывая способ пересылки данных. В нашем случае, Proxy B может отправить только по 1000 собранных элементов Заббикс серверу каждые 2-3 секунды. По моим наблюдениям, вот что происходит:
- Прокси устанавливает соединение до сервера
- Прокси максимум отправляет за раз 1000 собранных значений элементов данных
- Прокси закрывает соединение
- Первичное подключение очень медленное. В моем случае оно происходит за 0,25 секунды. Уф!
- Так как соединение закрывается после отправки 1000 элементов данных, то TCP-соединение никогда не длится достаточно долго, чтобы успеть использовать всю доступную пропускную способность канала.
Производительность базы данных
Высокая производительность базы данных является ключевой для системы мониторинга, так как абсолютно вся собранная информация попадает туда. При этом, с учетом большого количества операций записи в базу, производительность дисков - это первое бутылочное горлышко с которым сталкиваешься. Мне повезло и у меня в распоряжении оказались SSD-диски, однако все равно это не является гарантией быстрой работы базы. Вот пример:- Изначально в системе я использовал MySQL 5.5.18. Сначала никаких видимых проблем с производительностью не наблюдалось, однако, после 700-750 NVPS MySQL стал загружать процессор на 100% и система буквально «замерла». Дальнейшие мои попытки исправить ситуацию, подкручивая параметры в конфигурационном файле, активируя large pages или partitioning ни к чему не привели. Более хорошее решение предложила моя жена: сначала обновиться MySQL до 5.6 и потом разбираться. На мое удивление, простой апдейт решил все проблемы с производительностью, который я никак победить в 5.5.18. На всякий случай, вот копия my.cnf .

Обратите внимание, что больше всего запросов «Com_update». Причина кроется в том, что каждое полученное значение влечет Update в таблицу «items». Также в базе данных в основном операции на запись, так что MySQL query cache никак не поможет. По сути, он может быть даже вредным для производительности, учитывая, что постоянно придется маркировать запросы как неверные.
Другой проблемой для производительности может стать Zabbix Housekeeper. В больших сетях его настоятельно рекомендую отключать. Для этого в конфиг-файле выставите DisableHousekeeping=1. Понятно, что без Housekeeping старые данные(элементы данных, события, действия) не будут удаляться из базы. Тогда удаление можно организовать через partitioning.
Однако, одно из ограничений MySQL 5.6.12 в том, что partitioning не может быть использован в таблицах с foreign keys и как раз они присутствуют почти повсеместно в базе Заббикс. Но кроме таблиц history, которые нам и нужны. Partitioning дает нам два преимущества:
- Все исторические данные таблицы разбитые по днем/неделям/месяцам/и т.д. могут находиться в отдельных файлах, что позволяет в дальнейшем удалять данные без каких либо последствий для базы. Также очень просто понимать сколько данных собирается за определенный период времени.
- После очистки таблиц InnoDB не возвращает место диску, оставляя его себе для новых данных. В итоге с InnoDB невозможно очистить место на диске. В случае с partitioning это не проблема, место может быть освобождено, простым удалением старых партиций.
Собирать или слушать
В Заббиксе существует два метода сбора данных: активный и пассивный: В случае пассивного мониторинга Заббикс сервер сам опрашивает Заббикс агентов, а в случае активного - ждет когда Zabbix-агенты сами подключаться к серверу. Под активный мониторинг также попадает Zabbix trapper , так как инициация отсылки остается на стороне узла сети.Разница в производительности может быть серьезной при выборе одного или другого способа как основного. Пассивный мониторинг требует запущенных процессов на Заббикс сервере, которые будут регулярно посылать запрос к Заббикс агенту и ждать ответа, в некоторых случаях ожидание может затянуться даже до нескольких секунд. Теперь умножьте это время хотя бы на тысячу серверов, и становится ясно, что «поллинг» может занять время.
В случае активного мониторинга процессов опроса нет, сервер находится в состоянии ожидания, когда агенты сами начнут подключаться к Zabbix-серверу, чтобы получить список элементов данных, которые требуется мониторить.
Далее, агент начнет сам собирать элементы данных с учетом полученного с сервера интервала и отправлять их, при этом соединение будет открыто только тогда, когда агенту есть что отправить. Таким образом, отпадает необходимость в проверке до получения данных, которая присутствует при пассивном мониторинге. Вывод: активный мониторинг увеличивает скорость сбора данных, что и требуется в нашей большой сети.
Мониторинг самого Заббикса
Без мониторинга самого Zabbix эффективная работа большой системы просто не представляется возможной - критически важно понимать в каком месте произойдет «затык», когда система откажется принимать новые данные. Существующие элементы данных для мониторинга Заббикса могут быть найдены . В версиях 2.х Заббикса они были любезно собраны в шаблон для мониторинга Zabbix server, предоставляемый «из коробки». Пользуйтесь!Одной полезной метрикой является свободное место в History Write Cache (HistoryCacheSize в в конфиг-файле сервера). Данный параметр должен всегда быть близок к 100%. Если же кэш переполняется - это означает, что Zabbix не успевает добавлять в базу поступающие данные.
К сожалению, подобный параметр не поддерживается Zabbix-прокси. Кроме того, в Zabbix, отсутствует элемент данных, указывающий, сколько данных ожидает отправки на Zabbix-сервер. Впрочем, этот элемент данных легко сделать самому через SQL-запрос к базе прокси:
SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name="history_lastid"
Запрос вернет необходимо число. Если у вас стоит SQLite3 в качестве БД для Zabbix-прокси, то просто добавьте следующую команду как UserParameter в конфиг-файле Zabbix-агента, установленного на машине, где крутится Zabbix-прокси.
UserParameter=zabbix.proxy.items.sync.remaining,/usr/bin/sqlite3 /path/to/the/sqlite/database "SELECT ((SELECT MAX(proxy_history.id) FROM proxy_history)-nextid) FROM ids WHERE field_name="history_lastid"" 2>&1
{Hostname:zabbix.proxy.items.sync.remaining.min(10m)}>100000
Итого статистика
Напоследок предлагаю графики загрузки системы. Сразу говорю, что не знаю, что произошло 16 июля - мне пришлось пересоздать все базы прокси (SQLite на тот момент), чтобы решить проблему. С тех пор я перевел все прокси на MySQL и проблема не повторялась. Остальные «неровности» графиков совпадают со временем проведения нагрузочного тестирования. В целом, из графиков видно, что у используемого железа большой запас прочности.





А вот графики с сервера базы данных. Приросты трафика каждый день соответствуют времени снятия дампа(mysqldump). Также провал 16 июля на графике запросов(qps) относится к той же проблеме, что я описывал выше.





Управление
Итого в системе используется 2 сервера под Zabbix-сервера, 2 сервера под MySQL, 16 виртуальных серверов под Zabbix-прокси и тысячи наблюдаемых серверов с Zabbix-агентами. При таком количестве хостов о внесении изменений руками не могло быть и речи. И решением стал Git-репозиторий, к которому имеют доступ все сервера, и где я расположил все конфигурационные файлы, скрипты, и все остальное, что нужно распространять. Далее, я написал скрипт, который вызывается через UserParameter в агенте. После запуска скрипта сервер подключается к Git-репозиторию, скачивает все необходимые файлы и обновления и затем перезагружает Zabbix-агента/прокси/сервера, если конфиг-файлы имели изменения. Обновление стало не сложнее, чем запустить zabbix_get!Открытые проблемы
Несмотря на все усилия, которые я приложил, осталась одна существенная проблема, которую мне только предстоит решить. Речь о том, что когда система достигает 8000-9000NVPS, то резервная база MySQL больше не успевает за основной, таким образом никакой отказоустойчивости на самом деле и нет.У меня есть идеи, как данную проблему можно решить, но еще не было времени это имплементировать:
- Использовать Linux-HA с DRBD для partitioning БД.
- LUN-репликация на SAN с репликацией на другой LUN
- Percona XtraDB cluster. В версии 5.6 еще недоступен, так что с этим придется подождать(как я писал, были проблемы с производительностью в MySQL 5.5)
Мониторинг был и остается важнейшей частью системного и сетевого администрирования. Но если для маленькой локальной сети зачастую достаточно время от времени смотреть логи, то в случае крупных систем приходится использовать специализированные средства. Об одном из них - Zabbix и поговорим сегодня.
Введение
Начнем с архитектуры. Система мониторинга Zabbix состоит из нескольких подсистем, причем все они могут размещаться на разных машинах:
- сервер мониторинга, который периодически получает и обрабатывает данные, анализирует их и производит в зависимости от ситуации определенные действия, в основном оповещение администратора;
- база данных - в качестве таковой могут использоваться SQLite, MySQL, PostgreSQL и Oracle;
- веб-интерфейс на PHP, который отвечает за управление мониторингом и действиями, а также за визуализацию;
- агент Zabbix, запускается на той машине/устройстве, с которой необходимо снимать данные. Его наличие хоть и желательно, но, если установить его на устройство невозможно, можно обойтись SNMP;
- Zabbix proxy - используется в основном в тех случаях, когда необходимо мониторить сотни и тысячи устройств для снижения нагрузки на собственно сервер мониторинга.
Логическая единица мониторинга - узел. Каждому узлу присваивается описание и адрес - в качестве адреса можно использовать как доменное имя, так и IP. Узлы могут объединяться в группы, к примеру группа роутеров, для удобства наблюдения. Каждому серверу соответствует несколько элементов данных, то есть отслеживаемых параметров. Поскольку для каждого сервера настраивать параметры, за которыми нужно следить, неудобно (особенно это верно для больших сетей), можно создавать узлы-шаблоны и каждому серверу или группе серверов будет соответствовать несколько шаблонов.
В статье будут рассмотрены интересные сценарии использования Zabbix, но сначала опишем установку этого решения на RHEL-подобные системы с MySQL в качестве БД.
Установка и первичная настройка
Перво-наперво надо подключить репозиторий EPEL:
# yum install http://ftp.yandex.ru/epel/6/i386/epel-release-6-8.noarch.rpm
Затем поставить нужные пакеты:
# yum install zabbix20-server zabbix20-agent zabbix20-web-mysql nmap httpd policycoreutils-python net-snmp net-snmp-utils # yum groupinstall "MySQL Database Client" "MySQL Database Server"
Для чего нужен httpd и утилиты SNMP, полагаю, понятно. А вот Nmap нужен для некоторых проверок, чтобы заполнить элементы данных. Теперь необходимо настроить автозапуск служб и их запустить.
# chkconfig httpd on # chkconfig mysqld on # chkconfig zabbix-server on # chkconfig zabbix-agent on # service mysqld start
И конечно же, надо произвести начальную настройку MySQL.
# mysql_secure_installation
Затем заходим в консоль MySQL и создаем БД и пользователя:
Mysql> CREATE DATABASE zabbix CHARACTER SET utf8; mysql> GRANT ALL PRIVILEGES ON zabbix.* TO "zabbix"@"localhost" IDENTIFIED BY "zabbixpassword";
Теперь импортируем базы данных:
# mysql -u zabbix -p zabbix < /usr/share/zabbix-mysql/schema.sql # mysql -u zabbix -p zabbix < /usr/share/zabbix-mysql/images.sql # mysql -u zabbix -p zabbix < /usr/share/zabbix-mysql/data.sql
Редактируем файл конфигурации сервера Zabbix (/etc/zabbix_server.conf):
# <...> DBHost=localhost DBName=zabbix DBUser=zabbix DBPassword=zabbix
Слегка подкрутим конфигурацию PHP (/etc/php.ini):
# <...> max_execution_time = 300 max_input_time = 300 post_max_size = 16M date.timezone = Asia/Omsk
Настраиваем SELinux:
# semanage port -a -t http_port_t -p tcp 10051 # setsebool -P httpd_can_network_connect on
Наконец, запускаем оставшиеся службы:
# service httpd start # service zabbix-server start # service zabbix-agent start
В браузере подключаемся к http://server_name/zabbix и производим начальную конфигурацию фронтенда Zabbix (то есть имя БД, имя пользователя и пароль). После этого начальную настройку можно считать завершенной.


Мониторинг nginx и memcache
Для мониторинга nginx можно, разумеется, использовать самописные скрипты. Но в некоторых случаях, когда времени катастрофически не хватает, хочется найти что-нибудь готовое. В случае с nginx таким готовым решением будет набор питоновских скриптов ZTC. Для их установки сперва нужно установить некоторые пакеты:
# yum install lm_sensors smartmontools
Затем используй следующие команды:
# wget https://bitbucket.org/rvs/ztc/downloads/ztc-12.02.1-1.el6.noarch.rpm # rpm -ivh --nodeps ztc-12.02.1-1.el6.noarch.rpm
Опция —nodeps нужна по причине того, что пакет требует версию Zabbix 1.8, но ничто не мешает попробовать ZTC и на последних его версиях.
Теперь добавим еще один конфиг nginx (/etc/nginx/conf.d/nginx_status.conf):
Server { listen localhost; server_name nginx_status.localhost; location /server-status { stub_status on; access_log off; allow 127.0.0.1; deny all; } }
И поправим конфиг nginx в ZTC (/etc/ztc/nginx.conf):
# <...> proto=http host=localhost port=80 resource=/server-status
Проверим работу скрипта ZTC:
# /opt/ztc/bin/nginx.py ping # /opt/ztc/bin/nginx.py ping
Если все нормально, настраиваем Zabbix-agent на нужной машине (/etc/zabbix-agentd.conf):
# <...> UserParameter=nginx[*],/opt/ztc/bin/nginx.py $1
Теперь нужно настроить веб-интерфейс. Для этого необходимо импортировать шаблон Template_app_nginx.xml , что лежит в /opt/ztc/templates/ . Замечу, что лежит он именно на том компьютере, где установлен ZTC, так что если у тебя на сервере нет GUI, то файл придется копировать на машину, на которой установлен браузер и с которой собственно и ведется мониторинг.
Не стоит забывать, что в этом наборе скриптов кроме мониторинга nginx есть еще мониторинг и других приложений, таких, например, как MongoDB. Настраивается он аналогично, поэтому рассматривать его смысла нет.
А вот для memcache среди этих скриптов нет ничего, так что придется нам его написать самим. Проверим его работо- и дееспособность:
# echo -e "stats\nquit" | nc -q2 127.0.0.1 11211
В ответ должны посыпаться статистические данные. Теперь пишем скрипт-однострочник /etc/zabbix/scripts/memcache.sh (при этом не забываем сделать его исполняемым):
#!/bin/bash echo -e "stats\nquit" | nc 127.0.0.1 11211 | grep "STAT $1 " | awk "{print $3}"
Как и в случае с nginx, правим конфиг Zabbix-agent (/etc/zabbix-agentd.conf) и не забываем его рестартовать:
# <...> UserParameter=memcache[*],/etc/zabbix/scripts/memcache.sh $1
Берем шаблон отсюда и импортируем его в веб-интерфейс.

INFO
Для сети средних размеров (когда нужно мониторить около десятка устройств) достаточно разместить сервер мониторинга, веб-интерфейс и БД на одной системе, а Zabbix-агенты - на узлах, требующих присмотра.Мониторинг различных устройств с помощью Zabbix
В основном Zabbix используется для мониторинга серверов, но помимо собственно серверов есть еще множество других устройств, которые также нуждаются в мониторинге. Далее будет описана настройка Zabbix для мониторинга некоторых из них.
В большинстве сетей среднего и крупного размера имеется гремучая смесь всевозможного железа, которая досталась нынешнему админу со времен развертывания (и, скорее всего, это развертывание происходило еще при царе Горохе). По счастью, абсолютное большинство сетевого (да и не только) оборудования поддерживает открытый протокол SNMP, с помощью которого можно как получать о нем информацию, так и управлять параметрами. В данном случае нас интересует первое. Вкратце опишу нужные действия:
- включить поддержку SNMP на устройствах. Не забывай о безопасности - по возможности используй третью версию протокола, устанавливай авторизацию и изменяй имена community;
- добавить нужные элементы в Zabbix. Одному параметру SNMP соответствует один элемент; также нужно указать OID (идентификатор параметра) версию SNMP и, в зависимости от нее, параметры авторизации;
- добавить триггеры на нежелательное изменение параметров.
У каждой железки могут быть десятки отслеживаемых параметров, и вручную их добавлять замучаешься. Но в Сети можно найти множество шаблонов, которые уже содержат в себе все необходимые элементы, триггеры и графики, - остается только их импортировать и подключить нужные хосты. Также существуют стандартные OID, которые описаны в RFC. К таковым относится, например, uptime с OID .1.3.6.1.2.1.1.3.0 или - для коммутаторов - статус порта с OID .1.3.6.1.2.1.2.2.1.8.X, где X - номер порта.
Существует онлайн-генератор шаблонов , который генерирует их на основе стандартных OID. В основном он предназначен для железа от Cisco, но ничто не мешает его использовать для другого оборудования.
Zabbix также поддерживает и карту сети. К сожалению, ее нужно составлять вручную. Есть возможность поставить над соединительными линиями скорость - для этого требуется добавить в подпись нужный элемент в фигурных скобках. Помимо этого, в случае падения соединения можно раскрашивать соединительные линии красным цветом.
Тот же человек, что написал упомянутый генератор шаблонов, написал также и дополнение к фронтенду, которое отображает в удобном виде статус порта (скрипт для второго Zabbix лежит ). Установка его, как его автор сам и признает, достаточно заморочена - скрипт писался в первую очередь для внутреннего применения.
SNMP Traps в Zabbix
Протокол SNMP, помимо пассивного получения данных устройства, поддерживает также и активную их рассылку со стороны устройства. В англоязычной документации это именуется SNMP Trap, в русскоязычной же используется термин SNMP-трап. Трапы удобны, когда нужно срочно уведомить систему мониторинга об изменении какого-либо параметра. Для отлова трапов в Zabbix имеется три способа (во всех трех случаях нужен еще и демон snmptrapd):
- с помощью SNMPTT (SNMP Trap Translator);
- используя скрипт на Perl;
- используя скрипт на bash.
Далее описан первый вариант. Прежде всего, не забываем разрешить 161-й порт UDP и по необходимости временно отключить SELinux. Затем ставим нужные пакеты (предполагается, что репозиторий EPEL у тебя подключен):
# yum install net-snmp net-snmp-utils net-snmp-perl snmptt
Настраиваем snmptrapd (/etc/snmp/snmptrapd.conf):
DisableAuthorization yes traphandle default snmptthandler
Первая строчка отключает проверки доступа, что, в общем-то, крайне не рекомендуется делать в условиях промышленного использования (здесь она исключительно для простоты конфигурации), вторая указывает обработчик всех поступивших трапов, коим и является snmptthandler.
Затем настраиваем snmptt (/etc/snmp/snmptt.ini):
# <...> net_snmp_perl_enable = 1 mibs_environment = ALL date_time_format = %H:%M:%S %Y/%m/%d
Теперь нужно настроить шаблоны для маппинга трапов на Zabbix SNMP. Ниже будет приведен пример такого шаблона для двух видов трапов - coldStart и всех остальных (/etc/snmp/snmptt.conf).
# <...> EVENT general .* "General event" Normal FORMAT ZBXTRAP $aA $1 EVENT coldStart .1.3.6.1.6.3.1.1.5.1.0.33 "Status Events" Normal FORMAT ZBXTRAP $aA Device reinitialized (coldStart)
Первые две строчки описывают любые трапы, а вторая пара - конкретный трап с OID. Замечу, что для того, чтобы Zabbix ловил эти трапы, они должны быть именно в формате «ZBXTRAP адрес».
Включаем нужные службы:
# chkconfig snmptt on # chkconfig snmptrapd on # service snmptt start # service snmptrapd start
Посылаем тестовые трапы и смотрим логи:
# snmptrap -v 1 -c public 127.0.0.1 ".1.3.6.1.6.3.1.1.5.1" "0.0.0.0" 6 1 "55" .1.3.6.1.6.3.1.1.5.1 s "teststring000" # snmptrap -v 1 -c public 127.0.0.1 ".1.3.6.1.6.3.1.1.5.1" "0.0.0.0" 6 33 "55" .1.3.6.1.6.3.1.1.5.1 s "teststring000" # tail /var/log/snmptt/snmptt.log
Если все нормально, переходим к конфигурированию Zabbix. В файле /etc/zabbix_server.conf укажем местонахождение лога и включим встроенный SNMPTrapper:
# <...> SNMPTrapperFile=/var/log/snmptt/snmptt.log StartSNMPTrapper=1
После этого нужно зайти в веб-интерфейс Zabbix, по необходимости добавить в узле сети интерфейс SNMP и добавить элемент для трапа. Ставим все необходимые действия, если это нужно, и проверяем, для чего точно так же создаем тестовый трап.
INFO
Масштабирование в Zabbix работает достаточно хорошо - при должной настройке он выдерживает 6000 узлов.Мониторинг VPN-туннелей на оборудовании Cisco
Возникла необходимость мониторинга загрузки кучи туннелей VPN на цисках. Все хорошо, SNMP как на циске, так и на Zabbix настроен, но есть одна загвоздка - OID для каждого соединения формируются динамически, как и их списки. Это связано с особенностями протокола IPsec, в которые я вдаваться не буду - скажу лишь, что это связано с процедурой установления соединения. Алгоритм извлечения нужных счетчиков, таким образом, настолько замудрен, что реализовать его встроенными средствами Zabbix не представляется возможным.
По счастью, имеется скрипт , который это делает сам. Его нужно скачать и закинуть в каталог ExternalScripts (в моем случае это был /var/lib/zabbixsrv/externalscripts). Проверим его работоспособность:
# /var/lib/zabbixsrv/externalscripts/query_asa_lan2lan.pl ciscocom 192.168.10.1 ASA get RX 94.251.99.1
Если проверка прошла успешно, применим комбинацию LLD с этим скриптом. Создаем шаблон с правилом обнаружения (OID 1.3.6.1.4.1.9.9.171.1.2.3.1.7) и двумя элементами данных с внешней проверкой и ключами ‘queryasa lan2lan.pl[«{$SNMPCOMMUNITY}», «{HOST.IP}», «ASA», «get, «RX», «{#SNMPVALUE}»]’ и ‘queryasa lan2lan.pl[«{$SNMP COMMUNITY}», «{HOST.IP}», «ASA», «get», «TX», «{#SNMPVALUE}»]’, назвав их соответственно «Incoming traffic in tunnel to {#SNMPVALUE}» и «Outgoing traffic in tunnel to {#SNMPVALUE}». После этого применяем шаблон к нужным узлам и ждем автообнаружения.
К сожалению, LLD сейчас не поддерживает объединение графиков из нескольких прототипов данных, так что приходится добавлять нужные элементы ручками. По окончании этой работы любуемся графиками.
Прикручиваем MIB к Zabbix
Сам по себе Zabbix не поддерживает MIB (Management Information Base), а готовые шаблоны есть отнюдь не для всех устройств. Конечно, все OID можно добавить и вручную (с помощью snmpwalk), но это работает, только если их у тебя не очень много. Однако существует плагин для веб-интерфейса Zabbix под названием SNMP Builder, который позволяет конвертировать MIB-файлы в шаблоны и уже эти шаблоны допиливать под свои нужды. Берем его из Git-репозитория:
# git clone https://github.com/atimonin/snmpbuilder.git
Накладываем патч (в твоем случае, разумеется, имена каталогов могут быть другими, и подразумевается, что ты находишься в каталоге, где размещен фронтенд Zabbix - в случае с RHEL-based системами это /usr/share/zabbix):
# patch -p1 < /home/centos/snmpbuilder/snmpbuilder-2.0.5.patch
Копируем недостающие файлы и распаковываем картинки:
# tar xzvf /home/centos/snmpbuilder/snmpbuilder-2.0_imgs.tar.gz # cp -r /home/centos/snmpbuilder/zabbix/* .
По необходимости редактируем переменную MIBSALL PATH в файле snmp_builder.php . В отдельных случаях может также понадобиться слегка подправить его код, начиная со строки foreach(glob($path.»/*.mib»). Код в этом случае будет выглядеть примерно так:
# <...> foreach(glob($path."/*.mib") as $filename){ if (preg_match("/^".preg_quote($path,"/")."\/(.+)\.mib$/",$filename,$matches)){ $result=exec("cat ".$filename."| grep -i "DEFINITIONS.*::=.*BEGIN"|awk "{print $1}""); $cmbMibs->addItem($result,$result); } }
Теперь можно уже использовать.
Прежде всего нужно найти MIB-файлы для твоего железа. Некоторые производители их скрывают, некоторые - нет. После того как ты их нашел, эти файлы нужно поместить в папку, которую ты указал в вышеуказанной переменной. В отдельных случаях могут возникнуть зависимости - в подобной ситуации нужно найти соответствующий MIB-файл, чтобы их разрешить. Итак, выбери шаблон, MIB-файл и укажи адрес устройства. Если все нормально, ты увидишь список OID, которые нужно затем выбрать для добавления к шаблону. После выбора нужно нажать кнопку «Сохранить». Добавленные элементы появятся в указанном шаблоне.
В отдельных ситуациях нужно отредактировать новодобавленные элементы, поскольку по дефолту интервал обновления 60 секунд, что в случае, например, с именем хоста не имеет особого смысла - лучше в подобных ситуациях ставить его равным 86 400 секунд (24 часа). Для счетчиков же нужно изменить формат хранения на «Дельта в секунду». Кроме того, с некоторыми элементами нужно настроить еще и преобразование их значений в удобочитаемый вид. Для этого перейди в «Администрирование -> Общие» и в выпадающем меню выбери «Преобразование значений», а там уже добавляй его.
В общем-то, модуль мы настроили - все остальное ты уже настраивай самостоятельно.
Версии протокола SNMP
Существует несколько версий SNMP. Первая версия появилась в 1988 году и на данный момент, хоть и считается устаревшей, все еще очень популярна. Версия 2 (фактически сейчас под ней подразумевают версию 2c) появилась в апреле 1993 года. Она была несовместима с первой версией. Основные новшества второй версии протокола заключались в обмене информацией между управляющими компьютерами. Кроме того, появилась команда получения сразу нескольких переменных (GetBulk).
Во времена разработки первой версии мало кто заботился о безопасности, поэтому о какой-либо защите в SNMPv1 и говорить нечего. Аутентификации как таковой не было - не считать же за нее строку Community, передаваемую в открытом виде? Были, конечно, попытки реализовать безопасность SNMPv1, но успехом они не увенчались. Во второй версии кардинальных изменений тоже не появилось. А вот SNMPv3 уже начала поддерживать как безопасность сообщений (USM), так и контроль доступа (VACM). В USM поддерживаются MD5 и SHA-1 для обеспечения защиты от модификации данных и DES (сейчас уже AES) для шифрования. VACM же вводит как возможность авторизации, так и возможность указывать, какой управляющий компьютер какими атрибутами может манипулировать.
Несмотря на то что настраивать SNMPv3 сложнее, крайне рекомендуется использовать именно его, а остальные версии протокола отключать.
Заключение
В данной статье я рассмотрел интересные возможности системы мониторинга Zabbix. Полагаю, если ты хороший админ, то эти возможности можешь применить с пользой для себя. Но не стоит забывать, что мониторинг не вещь в себе - его нужно применять в комплексе с организационными мерами.