Перенос центра тяжести с процессоро-ориентированных на дата-ориентированные приложения обуславливает повышение значимости систем хранения данных. Вместе с этим проблема низкой пропускной способности и отказоустойчивости характерная для таких систем всегда была достаточно важной и всегда требовала своего решения.
В современной компьютерной индустрии в качестве вторичной системы хранения данных повсеместно используются магнитные диски, ибо, несмотря на все свои недостатки, они обладают наилучшими характеристиками для соответствующего типа устройств при доступной цене.
Особенности технологии построения магнитных дисков привели к значительному несоответствию между увеличением производительности процессорных модулей и самих магнитных дисков. Если в 1990 г. лучшими среди серийных были 5.25″ диски со средним временем доступа 12мс и временем задержки 5 мс (при оборотах шпинделя около 5 000 об/м 1), то сегодня пальма первенства принадлежит 3.5″ дискам со средним временем доступа 5 мс и временем задержки 1 мс (при оборотах шпинделя 10 000 об/м). Здесь мы видим улучшение технических характеристик на величину около 100%. В тоже время, быстродействие процессоров увеличилось более чем на 2 000%. Во многом это стало возможно благодаря тому, что процессоры имеют прямые преимущества использования VLSI (сверхбольшой интеграции). Ее использование не только дает возможность увеличивать частоту, но и число компонент, которые могут быть интегрированы в чип, что дает возможность внедрять архитектурные преимущества, которые позволяют осуществлять параллельные вычисления.
1 - Усредненные данные.
Сложившуюся ситуацию можно охарактеризовать как кризис ввода-вывода вторичной системы хранения данных.
Увеличиваем быстродействие
Невозможность значительного увеличения технологических параметров магнитных дисков влечет за собой необходимость поиска других путей, одним из которых является параллельная обработка.
Если расположить блок данных по N дискам некоторого массива и организовать это размещение так, чтобы существовала возможность одновременного считывания информации, то этот блок можно будет считать в N раз быстрее, (без учёта времени формирования блока). Поскольку все данные передаются параллельно, это архитектурное решение называется parallel-access array (массив с параллельным доступом).
Массивы с параллельным доступом обычно используются для приложений, требующих передачи данных большого размера.
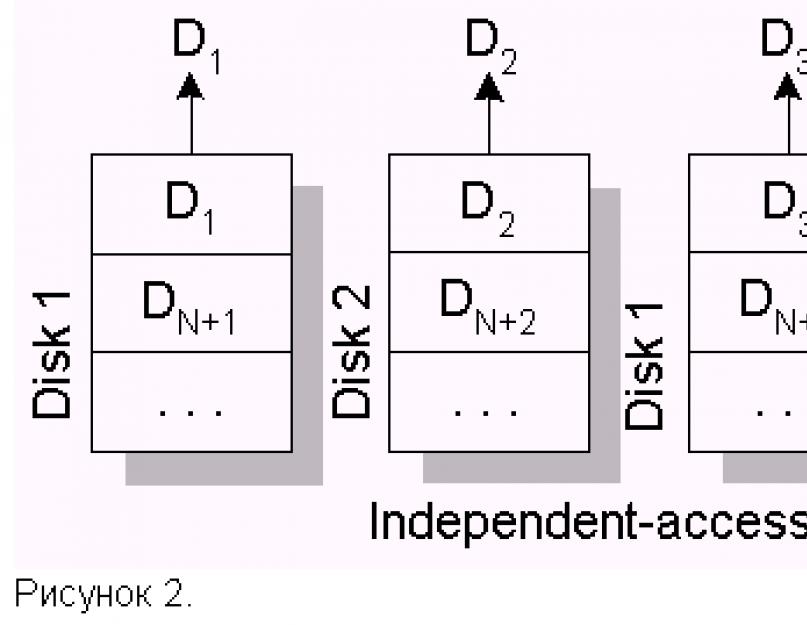
Некоторые задачи, наоборот, характерны большим количеством малых запросов. К таким задачам относятся, например, задачи обработки баз данных. Располагая записи базы данных по дискам массива, можно распределить загрузку, независимо позиционируя диски. Такую архитектуру принято называть independent-access array (массив с независимым доступом).

Увеличиваем отказоустойчивость
К сожалению, при увеличении количества дисков в массиве, надежность всего массива уменьшается. При независимых отказах и экспоненциальном законе распределения наработки на отказ, MTTF всего массива (mean time to failure - среднее время безотказной работы) вычисляется по формуле MTTF array = MMTF hdd /N hdd (MMTF hdd - среднее время безотказной работы одного диска; NHDD - количество дисков).
Таким образом, возникает необходимость повышения отказоустойчивости дисковых массивов. Для повышения отказоустойчивости массивов используют избыточное кодирование. Существует два основных типа кодирования, которые применяются в избыточных дисковых массивах - это дублирование и четность.
Дублирование, или зеркализация - наиболее часто используются в дисковых массивах. Простые зеркальные системы используют две копии данных, каждая копия размещается на отдельных дисках. Это схема достаточно проста и не требует дополнительных аппаратных затрат, но имеет один существенный недостаток - она использует 50% дискового пространства для хранения копии информации.
Второй способ реализации избыточных дисковых массивов - использование избыточного кодирования с помощью вычисления четности. Четность вычисляется как операция XOR всех символов в слове данных. Использование четности в избыточных дисковых массивах уменьшает накладные расходы до величины, исчисляемой формулой: НР hdd =1/N hdd (НР hdd - накладные расходы; N hdd - количество дисков в массиве).
История и развитие RAID
Несмотря на то, что системы хранения данных, основанные на магнитных дисках, производятся уже 40 лет, массовое производство отказоустойчивых систем началось совсем недавно. Дисковые массивы с избыточностью данных, которые принято называть RAID (redundant arrays of inexpensive disks - избыточный массив недорогих дисков) были представлены исследователями (Петтерсон, Гибсон и Катц) из Калифорнийского университета в Беркли в 1987 году. Но широкое распространение RAID системы получили только тогда, когда диски, которые подходят для использования в избыточных массивах стали доступны и достаточно производительны. Со времени представления официального доклада о RAID в 1988 году, исследования в сфере избыточных дисковых массивов начали бурно развиваться, в попытке обеспечить широкий спектр решений в сфере компромисса - цена-производительность-надежность.
С аббревиатурой RAID в свое время случился казус. Дело в том, что недорогими дисками во время написания статьи назывались все диски, которые использовались в ПК, в противовес дорогим дискам для мейнфрейм (универсальная ЭВМ). Но для использования в массивах RAID пришлось использовать достаточно дорогостоящую аппаратуру по сравнению с другой комплектовкой ПК, поэтому RAID начали расшифровывать как redundant array of independent disks 2 - избыточный массив независимых дисков.
2 - Определение RAID Advisory Board
RAID 0 был представлен индустрией как определение не отказоустойчивого дискового массива. В Беркли RAID 1 был определен как зеркальный дисковый массив. RAID 2 зарезервирован для массивов, которые применяют код Хемминга. Уровни RAID 3, 4, 5 используют четность для защиты данных от одиночных неисправностей. Именно эти уровни, включительно по 5-й были представлены в Беркли, и эта систематика RAID была принята как стандарт де-факто.
Уровни RAID 3,4,5 достаточно популярны, имеют хороший коэффициент использования дискового пространства, но у них есть один существенный недостаток - они устойчивы только к одиночным неисправностям. Особенно это актуально при использовании большого количества дисков, когда вероятность одновременного простоя более чем одного устройства увеличивается. Кроме того, для них характерно длительное восстановление, что также накладывает некоторые ограничения для их использования.
На сегодняшний день разработано достаточно большое количество архитектур, которые обеспечивают работоспособность массива при одновременном отказе любых двух дисков без потери данных. Среди всего множества стоит отметить two-dimensional parity (двухпространственная четность) и EVENODD, которые для кодирования используют четность, и RAID 6, в котором используется кодирование Reed-Solomon.
В схеме использующей двухпространственную четность, каждый блок данных участвует в построении двух независимых кодовых слов. Таким образом, если из строя выходит второй диск в том же кодовом слове, для реконструкции данных используется другое кодовое слово.

Минимальная избыточность в таком массиве достигается при равном количестве столбцов и строчек. И равна: 2 x Square (N Disk) (в «квадрат»).
Если же двухпространственный массив не будет организован в «квадрат», то при реализации вышеуказанной схемы избыточность будет выше.
Архитектура EVENODD имеет похожую на двухпространственную четность схему отказоустойчивости, но другое размещение информационных блоков, которое гарантирует минимальное избыточное использование емкостей. Так же как и в двухпространственной четности каждый блок данных участвует в построении двух независимый кодовых слов, но слова размещены таким образом, что коэффициент избыточности постоянен (в отличие от предыдущей схемы) и равен: 2 x Square (N Disk).
Используя два символа для проверки, четность и недвоичные коды, слово данных может быть сконструировано таким образом, чтобы обеспечить отказоустойчивость при возникновении двойной неисправности. Такая схема известна как RAID 6. Недвоичный код, построенный на основе Reed-Solomon кодирования, обычно вычисляется с использованием таблиц или как итерационный процесс с использованием линейных регистров с обратной связью, а это - относительно сложная операция, требующая специализированных аппаратных средств.
Учитывая то, что применение классических вариантов RAID, реализующих для многих приложений достаточную отказоустойчивость, имеет часто недопустимо низкое быстродействие, исследователи время от времени реализуют различные ходы, которые помогают увеличить быстродействие RAID систем.
В 1996 г. Саведж и Вилкс предложили AFRAID - часто избыточный массив независимых дисков (A Frequently Redundant Array of Independent Disks). Эта архитектура в некоторой степени приносит отказоустойчивость в жертву быстродействию. Делая попытку компенсировать проблему малой записи (small-write problem), характерную для массивов RAID 5-го уровня, разрешается оставлять стрипинг без вычисления четности на некоторый период времени. Если диск, предназначенный для записи четности, занят, то ее запись откладывается. Теоретически доказано, что 25% уменьшение отказоустойчивости может увеличить быстродействие на 97%. AFRAID фактически изменяет модель отказов массивов устойчивых к одиночным неисправностям, поскольку кодовое слово, которое не имеет обновленной четности, восприимчиво к отказам дисков.
Вместо того чтобы приносить в жертву отказоустойчивость, можно использовать такие традиционные способы увеличения быстродействия, как кэширование. Учитывая то, что дисковый трафик имеет пульсирующий характер, можно использовать кеш память с обратной записью (writeback cache) для хранения данных в момент, когда диски заняты. И если кеш-память будет выполнена в виде энергонезависимой памяти, тогда, в случае исчезновения питания, данные будут сохранены. Кроме того, отложенные дисковые операции, дают возможность объединить в произвольном порядке малые блоки для выполнения более эффективных дисковых операций.
Существует также множество архитектур, которые, принося в жертву объем, увеличивают быстродействие. Среди них - отложенная модификация на log диск и разнообразные схемы модификации логического размещение данных в физическое, которые позволяют распределять операции в массиве более эффективно.
Один из вариантов - parity logging (регистрация четности), который предполагает решение проблемы малой записи (small-write problem) и более эффективного использования дисков. Регистрация четности предполагает отложение изменения четности в RAID 5, записывая ее в FIFO log (журнал регистраций типа FIFO), который размещен частично в памяти контроллера и частично на диске. Учитывая то, что доступ к полному треку в среднем в 10 раз более эффективен, чем доступ к сектору, с помощью регистрации четности собираются большие количества данных модифицированной четности, которые потом все вместе записываются на диск, предназначенный для хранения четности по всему треку.
Архитектура floating data and parity (плавающие данные и четность), которая разрешает перераспределить физическое размещение дисковых блоков. Свободные сектора размещаются на каждом цилиндре для уменьшения rotational latency (задержки вращения), данные и четность размещаются на этих свободных местах. Для того, чтобы обеспечить работоспособность при исчезновении питания, карту четности и данных нужно сохранять в энергонезависимой памяти. Если потерять карту размещения все данные в массиве будут потеряны.
Virtual stripping - представляет собой архитектуру floating data and parity с использованием writeback cache. Естественно реализуя положительные стороны обеих.
Кроме того, существуют и другие способы повышения быстродействия, например распределение RAID операций. В свое время фирма Seagate встроила поддержку RAID операций в свои диски с интерфейсом Fibre Chanel и SCSI. Что дало возможность уменьшить трафик между центральным контроллером и дисками в массиве для систем RAID 5. Это было кардинальным новшеством в сфере реализаций RAID, но технология не получила путевки в жизнь, так как некоторые особенности Fibre Chanel и SCSI стандартов ослабляют модель отказов для дисковых массивов.
Для того же RAID 5 была представлена архитектура TickerTAIP. Выглядит она следующим образом - центральный механизм управления originator node (узел-инициатор) получает запросы пользователя, выбирает алгоритм обработки и затем передает работу с диском и четность worker node (рабочий узел). Каждый рабочий узел обрабатывает некоторое подмножество дисков в массиве. Как и в модели фирмы Seagate, рабочие узлы передают данные между собой без участия узла-инициатора. В случае отказа рабочего узла, диски, которые он обслуживал, становятся недоступными. Но если кодовое слово построено так, что каждый его символ обрабатывается отдельным рабочим узлом, то схема отказоустойчивости повторяет RAID 5. Для предупреждения отказов узла-инициатора он дублируется, таким образом, мы получаем архитектуру, устойчивую к отказам любого ее узла. При всех своих положительных чертах эта архитектура страдает от проблемы «ошибки записи» («;write hole»). Что подразумевает возникновение ошибки при одновременном изменении кодового слова несколькими пользователями и отказа узла.
Следует также упомянуть достаточно популярный способ быстрого восстановления RAID - использование свободного диска (spare). При отказе одного из дисков массива, RAID может быть восстановлен с использованием свободного диска вместо вышедшего из строя. Основной особенностью такой реализации есть то, что система переходит в свое предыдущее (отказоустойчивое состояние без внешнего вмешательства). При использовании архитектуры распределения свободного диска (distributed sparing), логические блоки spare диска распределяются физически по всем дискам массива, снимая необходимость перестройки массива при отказе диска.
Для того чтобы избежать проблемы восстановления, характерной для классических уровней RAID, используется также архитектура, которая носит название parity declustering (распределение четности). Она предполагает размещение меньшего количества логических дисков с большим объемом на физические диски меньшего объема, но большего количества. При использовании этой технологии время реакции системы на запрос во время реконструкции улучшается более чем вдвое, а время реконструкции - значительно уменьшается.
Архитектура основных уровней RAID
Теперь давайте рассмотрим архитектуру основных уровней (basic levels) RAID более детально. Перед рассмотрением примем некоторые допущения. Для демонстрации принципов построения RAID систем рассмотрим набор из N дисков (для упрощения N будем считать четным числом), каждый из которых состоит из M блоков.

Данные будем обозначать - D m,n , где m - число блоков данных, n - число подблоков, на которые разбивается блок данных D.
Диски могут подключаться как к одному, так и к нескольким каналам передачи данных. Использование большего количества каналов увеличивает пропускную способность системы.
RAID 0. Дисковый массив без отказоустойчивости (Striped Disk Array without Fault Tolerance)
Представляет собой дисковый массив, в котором данные разбиваются на блоки, и каждый блок записываются (или же считывается) на отдельный диск. Таким образом, можно осуществлять несколько операций ввода-вывода одновременно.

Преимущества :
- наивысшая производительность для приложений требующих интенсивной обработки запросов ввода/вывода и данных большого объема;
- простота реализации;
- низкая стоимость на единицу объема.
Недостатки :
- не отказоустойчивое решение;
- отказ одного диска влечет за собой потерю всех данных массива.
RAID 1. Дисковый массив с дублированием или зеркалка (mirroring)
Зеркалирование - традиционный способ для повышения надежности дискового массива небольшого объема. В простейшем варианте используется два диска, на которые записывается одинаковая информация, и в случае отказа одного из них остается его дубль, который продолжает работать в прежнем режиме.

Преимущества :
- простота реализации;
- простота восстановления массива в случае отказа (копирование);
- достаточно высокое быстродействие для приложений с большой интенсивностью запросов.
Недостатки :
- высокая стоимость на единицу объема - 100% избыточность;
- невысокая скорость передачи данных.
RAID 2. Отказоустойчивый дисковый массив с использованием кода Хемминга (Hamming Code ECC).
Избыточное кодирование, которое используется в RAID 2, носит название кода Хемминга. Код Хемминга позволяет исправлять одиночные и обнаруживать двойные неисправности. Сегодня активно используется в технологии кодирования данных в оперативной памяти типа ECC. И кодировании данных на магнитных дисках.

В данном случае показан пример с фиксированным количеством дисков в связи с громоздкостью описания (слово данных состоит из 4 бит, соответственно ECC код из 3-х).
Преимущества :
- быстрая коррекция ошибок («на лету»);
- очень высокая скорость передачи данных больших объемов;
- при увеличении количества дисков, накладные расходы уменьшаются;
- достаточно простая реализация.
Недостатки :
- высокая стоимость при малом количестве дисков;
- низкая скорость обработки запросов (не подходит для систем ориентированных на обработку транзакций).
RAID 3. Отказоустойчивый массив с параллельной передачей данных и четностью (Parallel Transfer Disks with Parity)
Данные разбиваются на подблоки на уровне байт и записываются одновременно на все диски массива кроме одного, который используется для четности. Использование RAID 3 решает проблему большой избыточности в RAID 2. Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Но в этом нет нужды, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, или дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев.

Преимущества :
- очень высокая скорость передачи данных;
- отказ диска мало влияет на скорость работы массива;
Недостатки :
- непростая реализация;
- низкая производительность при большой интенсивности запросов данных небольшого объема.
RAID 4. Отказоустойчивый массив независимых дисков с разделяемым диском четности (Independent Data disks with shared Parity disk)
Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный диск и может быть прочитан отдельно. Четность для группы блоков генерируется при записи и проверяется при чтении. RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу одновременно. Главное отличие между RAID 3 и 4 состоит в том, что в последнем, расслоение данных выполняется на уровне секторов, а не на уровне битов или байтов.

Преимущества :
- очень высокая скорость чтения данных больших объемов;
- высокая производительность при большой интенсивности запросов чтения данных;
- малые накладные расходы для реализации избыточности.
Недостатки :
- очень низкая производительность при записи данных;
- низкая скорость чтения данных малого объема при единичных запросах;
- асимметричность быстродействия относительно чтения и записи.
RAID 5. Отказоустойчивый массив независимых дисков с распределенной четностью (Independent Data disks with distributed parity blocks)
Этот уровень похож на RAID 4, но в отличие от предыдущего четность распределяется циклически по всем дискам массива. Это изменение позволяет увеличить производительность записи небольших объемов данных в многозадачных системах. Если операции записи спланировать должным образом, то, возможно, параллельно обрабатывать до N/2 блоков, где N - число дисков в группе.

Преимущества :
- высокая скорость записи данных;
- достаточно высокая скорость чтения данных;
- высокая производительность при большой интенсивности запросов чтения/записи данных;
- малые накладные расходы для реализации избыточности.
Недостатки :
- скорость чтения данных ниже, чем в RAID 4;
- низкая скорость чтения/записи данных малого объема при единичных запросах;
- достаточно сложная реализация;
- сложное восстановление данных.
RAID 6. Отказоустойчивый массив независимых дисков с двумя независимыми распределенными схемами четности (Independent Data disks with two independent distributed parity schemes)
Данные разбиваются на блочном уровне, аналогично RAID 5, но в дополнение к предыдущей архитектуре используется вторая схема для повышения отказоустойчивости. Эта архитектура является устойчивой к двойным отказам. Однако при выполнении логической записи реально происходит шесть обращений к диску, что сильно увеличивает время обработки одного запроса.

Преимущества :
- высокая отказоустойчивость;
- достаточно высокая скорость обработки запросов;
- относительно малые накладные расходы для реализации избыточности.
Недостатки :
- очень сложная реализация;
- сложное восстановление данных;
- очень низкая скорость записи данных.
Современные RAID контроллеры позволяют комбинировать различные уровни RAID. Таким образом, можно реализовать системы, которые объединяют в себе достоинства различных уровней, а также системы с большим количеством дисков. Обычно это комбинация нулевого уровня (stripping) и какого либо отказоустойчивого уровня.
RAID 10. Отказоустойчивый массив с дублированием и параллельной обработкой
Эта архитектура являет собой массив типа RAID 0, сегментами которого являются массивы RAID 1. Он объединяет в себе очень высокую отказоустойчивость и производительность.

Преимущества :
- высокая отказоустойчивость;
- высокая производительность.
Недостатки :
- очень высокая стоимость;
- ограниченное масштабирование.
RAID 30. Отказоустойчивый массив с параллельной передачей данных и повышенной производительностью.
Представляет собой массив типа RAID 0, сегментами которого являются массивы RAID 3. Он объединяет в себе отказоустойчивость и высокую производительность. Обычно используется для приложений требующих последовательной передачи данных больших объемов.

Преимущества :
- высокая отказоустойчивость;
- высокая производительность.
Недостатки :
- высокая стоимость;
- ограниченное масштабирование.
RAID 50. Отказоустойчивый массив с распределенной четностью и повышенной производительностью
Являет собой массив типа RAID 0, сегментами которого являются массивы RAID 5. Он объединяет в себе отказоустойчивость и высокую производительность для приложений с большой интенсивностью запросов и высокую скорость передачи данных.

Преимущества :
- высокая отказоустойчивость;
- высокая скорость передачи данных;
- высокая скорость обработки запросов.
Недостатки :
- высокая стоимость;
- ограниченное масштабирование.
RAID 7. Отказоустойчивый массив, оптимизированный для повышения производительности. (Optimized Asynchrony for High I/O Rates as well as High Data Transfer Rates). RAID 7® является зарегистрированной торговой маркой Storage Computer Corporation (SCC)
Для понимания архитектуры RAID 7 рассмотрим ее особенности:
- Все запросы на передачу данных обрабатываются асинхронно и независимо.
- Все операции чтения/записи кэшируются через высокоскоростную шину x-bus.
- Диск четности может быть размещен на любом канале.
- В микропроцессоре контроллера массива используется операционная система реального времени ориентированная на обработку процессов.
- Система имеет хорошую масштабируемость: до 12 host-интерфейсов и до 48 дисков.
- Операционная система контролирует коммуникационные каналы.
- Используются стандартные SCSI диски, шины, материнские платы и модули памяти.
- Используется высокоскоростная шина X-bus для работы с внутренней кеш памятью.
- Процедура генерации четности интегрирована в кеш.
- Диски, присоединенные к системе, могут быть задекларированы как отдельно стоящие.
- Для управления и мониторинга системы можно использовать SNMP агент.
Преимущества :
- высокая скорость передачи данных и высокая скорость обработки запросов (1.5 - 6 раз выше других стандартных уровней RAID);
- высокая масштабируемость хост интерфейсов;
- скорость записи данных увеличивается с увеличением количества дисков в массиве;
- для вычисления четности нет необходимости в дополнительной передаче данных.
Недостатки :
- собственность одного производителя;
- очень высокая стоимость на единицу объема;
- короткий гарантийный срок;
- не может обслуживаться пользователем;
- нужно использовать блок бесперебойного питания для предотвращения потери данных из кеш памяти.
Рассмотрим теперь стандартные уровни вместе для сравнения их характеристик. Сравнение производится в рамках архитектур, упомянутых в таблице.
| RAID | Минимум дисков | Потребность в дисках | Отказо- устойчивость | Скорость передачи данных | Интенсивность обработки запросов | Практическое использование |
|---|---|---|---|---|---|---|
| 0 | 2 | N | очень высокая до N х 1 диск | Графика, видео | ||
| 1 | 2 | 2N * | R > 1 диск W = 1 диск | до 2 х 1 диск W = 1 диск | малые файл-серверы | |
| 2 | 7 | 2N | ~ RAID 3 | Низкая | мейнфреймы | |
| 3 | 3 | N+1 | Низкая | Графика, видео | ||
| 4 | 3 | N+1 | R W | R = RAID 0 W | файл-серверы | |
| 5 | 3 | N+1 | R W | R = RAID 0 W | серверы баз данных | |
| 6 | 4 | N+2 | самая высокая | низкая | R > 1 диск W | используется крайне редко |
| 7 | 12 | N+1 | самая высокая | самая высокая | разные типы приложений |
Уточнения :
- * - рассматривается обычно используемый вариант;
- k - количество подсегментов;
- R - чтение;
- W - запись.
Некоторые аспекты реализации RAID систем
Рассмотрим три основных варианта реализации RAID систем:
- программная (software-based);
- аппаратная - шинно-ориентированная (bus-based);
- аппаратная - автономная подсистема (subsystem-based).
Нельзя однозначно сказать, что какая-либо реализация лучше, чем другая. Каждый вариант организации массива удовлетворяет тем или иным потребностям пользователя в зависимости от финансовых возможностей, количества пользователей и используемых приложений.
Каждая из вышеперечисленных реализаций базируется на исполнении программного кода. Отличаются они фактически тем, где этот код исполняется: в центральном процессоре компьютера (программная реализация) или в специализированном процессоре на RAID контроллере (аппаратная реализация).
Главное преимущество программной реализации - низкая стоимость. Но при этом у нее много недостатков: низкая производительность, загрузка дополнительной работой центрального процессора, увеличение шинного трафика. Программно обычно реализуют простые уровни RAID - 0 и 1, так как они не требуют значительных вычислений. Учитывая эти особенности, RAID системы с программной реализацией используются в серверах начального уровня.
Аппаратные реализации RAID соответственно стоят больше чем программные, так как используют дополнительную аппаратуру для выполнения операций ввода вывода. При этом они разгружают или освобождают центральный процессор и системную шину и соответственно позволяют увеличить быстродействие.
Шинно-ориентированные реализации представляют собой RAID контроллеры, которые используют скоростную шину компьютера, в который они устанавливаются (в последнее время обычно используется шина PCI). В свою очередь шинно-ориентированные реализации можно разделить на низкоуровневые и высокоуровневые. Первые обычно не имеют SCSI чипов и используют так называемый RAID порт на материнской плате со встроенным SCSI контроллером. При этом функции обработки кода RAID и операций ввода/вывода распределяются между процессором на RAID контроллере и чипами SCSI на материнской плате. Таким образом, центральный процессор освобождается от обработки дополнительного кода и уменьшается шинный трафик по сравнению с программным вариантом. Стоимость таких плат обычно небольшая, особенно если они ориентированы на системы RAID - 0 или 1 (есть также реализации RAID 3, 5, 10, 30, 50, но они дороже), благодаря чему они понемногу вытесняют программные реализации с рынка серверов начального уровня. Высокоуровневые контроллеры с шинной реализацией имеют несколько другую структуру, чем их младшие братья. Они берут на себя все функции, связанные с вводом/выводом и исполнением RAID кода. Кроме того, они не так зависимы от реализации материнской платы и, как правило, имеют больше возможностей (например, возможность подключения модуля для хранения информации в кеш в случае отказа материнской платы или исчезновения питания). Такие контроллеры обычно стоят дороже низкоуровневых и используются в серверах среднего и высокого уровня. Они, как правило, реализуют RAID уровней 0,1, 3, 5, 10, 30, 50. Учитывая то, что шинно-ориентированные реализации подключаются прямо к внутренней PCI шине компьютера, они являются наиболее производительными среди рассматриваемых систем (при организации одно-хостовых систем). Максимальное быстродействие таких систем может достигать 132 Мбайт/с (32bit PCI) или же 264 Мбайт/с (64bit PCI) при частоте шины 33MHz.
Вместе с перечисленными преимуществами шинно-ориентированная архитектура имеет следующие недостатки:
- зависимость от операционной системы и платформы;
- ограниченная масштабируемость;
- ограниченные возможности по организации отказоустойчивых систем.
Всех этих недостатков можно избежать, используя автономные подсистемы. Эти системы имеют полностью автономную внешнюю организацию и в принципе являют собой отдельный компьютер, который используется для организации систем хранения информации. Кроме того, в случае удачного развития технологии оптоволоконных каналов быстродействие автономных систем ни в чем не будет уступать шинно-ориентированным системам.
Обычно внешний контроллер ставится в отдельную стойку и в отличие от систем с шинной организацией может иметь большое количество каналов ввода/вывода, в том числе и хост-каналов, что дает возможность подключать к системе несколько хост-компьютеров и организовывать кластерные системы. В системах с автономным контроллером можно реализовать горячее резервирование контроллеров.
Одним из недостатков автономных систем остается их большая стоимость.
Учитывая вышесказанное, отметим, что автономные контроллеры обычно используются для реализации высокоемких хранилищ данных и кластерных систем.
Небольшой, но, надеюсь, обоснованный ответ на топик Почему RAID-5 - «mustdie»? .
Ниже я произведу простейший расчёт надёжности RAID10 и RAID5 и сравнение их характеристик, а также укажу на некоторые принципиальные недостатки RAID1 и RAID10.
Небольшая вводная:
Рассматривать мы будем простейшие случаи - RAID10 из 4-х дисков и RAID5 из 3-х дисков. Все диски в системе примем одинаковыми.В первоначальной версии статьи вместо RAID10 упоминался RAID0+1, но это вносит лишнюю путаницу. Корректное название конечно же RAID10 - сыплю голову пеплом.
Пусть n - вероятность отказа одного диска;
Итак - RAID10:
Кол-во дисков в массиве - 4;Цена массива равна стоимости четырёх дисков;
Ёмкость массива будет равна удвоенной ёмкости используемых дисков (одного диска);
Максимальная скорость чтения данных равна удвоенной скорости одного диска;
Вероятность отказа массива для самого лучшего случая (когда контроллер реализует RAID1+0 как единую матрицу и умеет комбинировать накопители произвольным образом):
Вероятность отказа одного диска: P1=n(1-n)^3;
Вероятность отказа двух дисков: P2=(n^2)*(1-n)^2;
Вероятность отказа трёх дисков: P3=(n^3)*(1-n);
Вероятность отказа четырёх дисков: P4=n^4;
Вероятность безотказной работы: P0=(1-n)^4;
Полная вероятность: 4*P1+6*P2+4*P3+P4+P0=1;
Вероятность отказа массива: P(RAID10)=2*P2+4*P3+P4;
* В первом слагаемом вместо 6 стоит 2, так как только в двух случаях (при повреждении дисков с одинаковыми ыми данными) массив не может быть восстановлен.
Отдельно замечу, что большинство контроллеров не умеют комбинировать накопители, а значит отказ двух любых накопителей ведёт к потере данных, и надёжность массива в целом получается значительно ниже.
RAID5:
Кол-во дисков в массиве - 3;Цена массива равно стоимости трёх дисков;
Ёмкость массива равна ёмкости двух дисков;
максимальная скорость чтения равна полуторной скорости чтения одного диска;
Вероятность отказа массива равна вероятности отказа двух дисков в нём:
Вероятность отказа одного диска: P1=n(1-n)^2;
Вероятность отказа двух дисков: P2=(n^2)*(1-n);
Вероятность отказа трёх дисков: P3=n^3;
Вероятность безотказной работы: P0=(1-n)^3;
Полная вероятность: 3*P1+3*P2+P3+P0=1;
Вероятность отказа массива: P(RAID5)=3*P2+P3;
Выводы:
Начнём конечно же с вероятности отказа - отнимем вероятность отказа RAID5 от вероятности отказа RAID10:P(RAID10)-P(RAID5)=2n^2*(n-1)^2-n^3+n^4+3*n^2*(n-1)-4*n^3*(n-1)
Учитывая, что n->0 P(RAID10)-P(RAID5)<0, т.е. надёжность RAID5 НИЖЕ надёжности RAID10. Разница совсем небольшая, но в пользу RAID10;
Если же допустить, что накопители не могут комбинироваться произвольным образом, то RAID5 надёжнее.
Соотношение цен: RAID5 в 1.333 раза дешевле.
Соотношение скоростей: RAID5 в 1.333 раза медленнее чем RAID10, но при этом в полтора раза быстрее одиночного накопителя.
Внимание вопрос какой вариант лучше? Тот, который дороже и менее надёжен, хоть и немного быстрее. Или тот, что дешевле и надёжнее?
Лично моё мнение склоняется в сторону более надёжного и дешёвого RAID5 никуда не склоняется.
Дополнение:
В комментариях уважаемый track аргументировано указал , что в некоторых случаях RAID-5 может оказаться намного медленнее RAID1. По моему скромному мнению это должны быть очень и очень специфичные случаи, но иметь в виду следует.
Всякого рода замечания:
Время восстановления:
Восстановление RAID10 в идеале равно времени копирования всего объёма данных.Для RAID5 ситуация сложнее, так как требуется восстановление данных по кодам коррекции.
При программной реализации время восстановления RAID5 будет определяться быстродействием процессора.
При аппаратной реализации время восстановления RAID5 равно времени восстановления RAID10.
Учитывая, что современные процессоры без проблем справляются с потоком данных порядка 100МБ/с (приблизительная пиковая скорость чтения современных накопителей) можно утверждать, что при правильной реализации программный RAID5 будет не намного медленнее RAID10.
Про надёжность во время восстановления. Для рассматриваемого случая об этого говорить вообще не приходится - резервные копии делать нужно! В общем же случае следует принимать во внимание, что на момент восстановления количество дисков в RAID10 больше, чем в RAID5, а значит вероятность отказа выше, и нельзя говорить о том, что на время восстановления RAID10 однозначно надёжнее.
Дополнение:
Если используется RAID-5EE, то в случае первого отказа он «сжимается» в RAID-5, что может занять очень длительное время. Однако, следует учитывать, что в результате получается полноценный RAID-5, который устойчив к одиночным отказам, т.е. фактически (при некоторых ограничениях) система может пережить два отказа подряд.
Загрузка процессора:
Программная реализация RAID5 нагружает процессор. Для современных процессоров, это как правило не критично, но для быстрых накопителей нужно иметь в виду, что чем быстрее накопитель, тем сильнее нагрузка на процессор.И снова надёжность - последний гвоздь в крышку гроба:
Почему-то при разговоре о RAID10 и особенно о RAID1 все упускают из вида один очень важный момент.Да, в случае физического отказа накопителя он обеспечивет восстановление данных из копии, но что будет, если накопители вернут разные данные? Ведь в RAID1 нет способа узнать какие данные верны! Можно попытаться определить достоверность данных по их содержанию, но это не тривиальная задача, которая может быть выполнена только вручную, причём, далеко не всегда.
Именно по этой причине я вообще не рассматриваю здесь RAID1 - он не обеспечивает механизма контроля достоверности данных. И RAID10 в общем случае тоже.
А RAID5 (6?) в общем случае очень даже обеспечивает - если один из трёх накопителей вернёт неверные данные, то будет однозначно известно, что они не достоверны.
Как такое (недостоверность данных) может случиться?
Проблемы с перегревом дисков. Проблемы с питанием. Проблемы с прошивкой дисков. Масса вариантов! Вплоть до полного выгорания электроники в результате выхода их строя компьютерного источника питания. В таком случае диски можно попытаться оживить, поставив платы с аналогичных устройств, но не будет гарантии, что все данные на дисках достоверны.
И ещё один гвоздик туда же. В топике с которого всё началось много расписано про BER (bit error rates). Не вдаваясь в подробности лишь замечу что, во-первых, для жёстких дисков все же принято больше говорить о MTBF (mean time between failures), во-вторых, если и говорить о BER, то о UBER (uncorrectable bit error rates), а, в-третьих, это будет аргумент в пользу RAID5 - если накопители вернут искажённые данные (которые прошли через все процедуры коррекции), то как узнать какому накопителю верить?
Дополнение:
Вики говорит обратное - информация для восстановления не используется до тех пор, пока один из дисков не выйдет из строя. Жизненный опыт, правда, говорит иначе, но это было давно и я даже не помню на каком контроллере (возможно это был один нестандартных уровней RAID). Так что однозначно о достоверности данных можно говорить лишь для ZFS/RAID-6.
Вердикт:
Вердикт прост - если не нужны лишние проблемы на ровном месте, то не нужно городить ни RAID1 ни RAID0+1 - нужно смотреть в сторону RAID5, 5E, 6, ZFSВердикт по отношению к «чистому» RAID5 не однозначен:)
Udpate:
Поправил расчёт вероятности - вывод не изменился. Поправил «RAID0+1» на «RAID10». Замечу, что в описываемом случае «RAID0+1» идентичен «RAID1+0». Но корректное название конечно же «RAID10».
Udpate2:
Вот так легко и не замысловато смысл статьи изменился если и не на противоположный, то уж точно кардинально.
Технология RAID разработаная в 1980-х годах задумывалась как обьединение нескольких дисков в дисковый массив с целью увеличения емкости, повышения надежности и доступности данных. Рассмотрим вкратце основные уровни RAID
RAID0: Чередование (Striping)
Описание : Данные распределены по всем дискам массива равномерно. В массиве участвуют два или более дисков
Производительность : Одновременно может быть записан и прочитан бит данных
Плюсы : Быстродействие чтения/записи
Минусы : Нет резервирования. Любой диск вышедший из строя приведет к разрушению массива и как следствие потере всех данных
Использование : Приложения, которым необходим скоросной обмен данными, хранилище временных файлов, некритичные данные
RAID1: Зеркалирование (Mirroring)
Описание : Запись/чтение данных происходит одновременно на два или более дисков массива
Производительность : Операции чтения выполняются бстрее т.к. данные считываются со всех дисков массива одновременно. Операции записи медленнее т.к. запись выполняется дважды или более раз (зависит от количества дисков в массиве)
Плюсы : Выход из строя любого количества дисков массива кроме последнего не приводит к потере данных
Минусы : Стоимость. Пропорциональна количеству дисков в массиве
Использование : Системные разделы, разделы с важными данными, приложения использующие транзакции
RAID3: Чередование с выделенным диском чётности (Virtual disk blocks)
Описание : Данные чередуются по дискам массива на уровне байтов. Необходим дополнительный диск на котором хранится информация о четности. Минимально три диска в массиве
Производительность : Низкая на операциях записи
Плюсы : Данные остаются полностью доступными при выходе из строя одного диска
Минусы : Производительность
Использование : Редко меняющиеся, часто считываемые данные
RAID4: Чередование с выделенным диском чётности (Dedicated parity disk)
Описание : Данные чередуются на уровне блоков. Необходим дополнительный диск на котором хранится информация о четности. Минимально три диска в массиве
Производительность : Низкая на операциях записи
Плюсы : Это лучше чем RAID3. Данные остаются полностью доступными при выходе из строя одного диска. В массив можно добавить любое количество дисков
Минусы : Узкое место такого массива — выделенный диск четности. Данные не считаются записанными, пока не будет записана контрольная сумма на диск четности
Использование : Не подходит для высокопроизводительных систем с активной записью/чтением
RAID5: Чередование чётности (Striped parity)
Описание : В отличии от RAID4 данные и четность чередуются по всем дискам массива. Очень хорошо иметь дополнительный вакантный диск (hot spare disk) на случай если один из дисков массива выйдет из строя. Тогда контроллер подхватит вакантный диск и массив будет перестроен. Минимально три диска в массиве
Производительность : Лучше, чем в RAID4 т.к. решена проблема выделенного диска четности
Плюсы : Достигнут баланс чтения/записи/резервирования
Минусы : Просадка производительности во время перестройки массива. Если не используется кеш записи (рейд-контроллер не оборудован батарейкой и не настроен), то просадка будет особенно чуствительна
Использование : Веб-сервера, файловые сервера где используется интенсивное чтение данных
RAID6: Двойное чередование чётности (Dual parity)
Описание : Похож на RAID5 с той разницей, что в массиве присутствует два диска контроля четности, что повышает надежность системы. Минимально четыре диска в массиве
Производительность : Хуже на 10%-15% чем в RAID5 из-за более сложного алгоритма рассчета контрольных сумм. Больше операций чтения/записи
Плюсы : Повышена надежность сохранности данных. Система останется в работе при двух отказавших дисках
Минусы : Стоимость. Просадка производительности во время перестройки массива
Использование : Резервные хранилища данных с повышенной надежностью
RAID10
Описание : Из групп массивов RAID1 строится RAID0
Производительность : Считается самым быстрым и надежным массивом
Плюсы : Повышена надежность сохранности данных. Массив будет жизнеспособен пока в каждой группе массивов RAID1 будет рабочим последний диск
Минусы : Стоимость, один из самых дорогих
Использование : Веб-сервера с активным чтением данных, приложения используюшие транзакции
RAID10 не равно RAID01 и вот почему. К примеру у нас есть восемь хардов
Рассмотрим случай с RAID01
Этот уровень имеет два набора RAID0 (А и В). В каждом наборе по четыре диска. Наборы между собой в RAID1 (зеркало)
Теперь представим, что любой диск из набора А выходит из строя. Таким образом весь массив А деградирует, данные перестают туда записываться и система работает на наборе В. Если из строя выйдет любой диск из набора В, то крах системы и потеря данных неизбежны. Надеюсь Вы делали бекапы
Теперь случай с RAID10
 Этот уровень имеет четыре набора RAID1. В каждом наборе по два диска. Наборы между собой в RAID0
Этот уровень имеет четыре набора RAID1. В каждом наборе по два диска. Наборы между собой в RAID0
Допустим из строя выход диск набора 1. Система продолжит работу поскольку в наборе 1 есть второй диск. Если предположить, что в наборе 1 из строя выходит второй диск, то крах системы, потеря данных и все дальнейшее, что с этим связано. Опять вопрос о бекапах
Если из строя выходит диск из любого другого набора, то система продолжит работу. Таким образом система останется на плаву при вылете одного диска из каждого набора, поскольку работа каждого набора обеспечивается работой другого диска
Немного математики
Для RAID01 вероятность отказа расчитывается по формуле (n/2)/(n — 1)*100, где n — общее количество дисков в системе
Для RAID10 вероятность отказа расчитывается по формуле 1/(n — 1)*100
Таким образом для системы из восьми дисков вероятность потери последнего диска после чего наступит крах системы равна ~57% для RAID01 и ~14% для RAID10. Это верно для систем с двумя дисками в зеркале
Резюме
- Производительность обоих массивов одинакова
- Дисковый размер обоих масивов одинаков
- При восстановлении массива в случае с RAID10 синхронизация данных будет происходить по формуле 1-на-1, а в случае с RAID01 n/2-на-n/2. А это время и возможность поймать ошибку чтения
- В RAID10 можно потерять не более половины дисков. При этом система останется в строю. В RAID01 вылет всего двух дисков приведет к потере данных и не имеет значения четыре было диска в массиве или двадцать четыре
- Таким образом если стоит выбор между RAID10 и RAID01 выбирайте RAID10
перевод Александр Черных
системный администратор