Для моделирования предметных областей широкое распространение получили реляционные СУБД. Их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточно универсальна. Однако проектирование реляционной БД в терминах отношений часто представляет собой очень сложный и неудобный для проектировщика процесс.
При этом ограниченность реляционной модели данных проявляется в следующих аспектах:
· Модель не обеспечивает достаточных средств представления смыслового содержания данных. Семантика реальной предметной области должна независимым от модели способом отображаться в сознание проектировщика. В частности, это относится к проблеме представления ограничений целостности;
· Для многих приложений трудно моделировать предметную область на основе плоских таблиц. В ряде случаев на самой начальной стадии проектирования разработчику приходится описывать предметную область в виде одной (возможно, даже ненормализованной) таблицы.
Хотя весь процесс проектирования происходит на основе учета зависимостей, реляционная модель не обеспечивает каких-либо средств для представления этих зависимостей.
Несмотря на то, что процесс проектирования начинается с выделения некоторых значимых для приложения объектов предметной области ("сущностей") и выявления связей между этими сущностями, реляционная модель данных не предлагает какого-либо аппарата для разделения сущностей и связей.
Потребности проектировщиков БД в более удобных и мощных средствах моделирования предметной области реализуются при использовании
= семантических моделей данных =
Любая развитая семантическая модель данных, как и реляционная модель, включает структурную , манипуляционную и целостную части.
Главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования БД. При этом в терминах семантической модели производится концептуальная схема БД, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную модель.
Известны два подхода:
· на основе явного представления концептуальной схемы как исходной информации для компилятора;
· построение интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области.
Третья возможность , которая пока только выходит за пределы исследовательских и экспериментальных проектов, – это работа с БД в семантической модели, то есть СУБД, основанные на семантических моделях данных.
При этом снова рассматриваются два варианта:
· обеспечение пользовательского интерфейса на основе семантической модели данных с автоматическим отображением конструкций в реляционную модель данных (это задача примерно такого же уровня сложности, как автоматическая компиляция концептуальной схемы БД в реляционную схему);
· прямая реализация СУБД, основанная на какой-либо семантической модели данных.
Наиболее близко ко второму подходу находятся современные объектно-ориентированные СУБД, модели данных которых по многим параметрам близки к семантическим моделям (хотя в некоторых аспектах они более мощны, а в некоторых – более слабы).
Основные понятия модели «Entity - Relationship».
Семантическая модель данных Entity - Relationship – модель "Сущность - Связи " (ER-модель).
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию БД (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов.
В связи с наглядностью представления концептуальных схем БД ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных БД. Среди множества разновидностей ER-моделей наиболее развитая модель применяется в системе CASE (фирмы ORACLE).
Основными понятиями ER-модели являются:
«сущность – связь – атрибут».
Сущность – это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности – это имя типа, а не некоторого конкретного экземпляра этого типа. Сущность «АЭРОПОРТ», с примерными объектами «Шереметьево» и «Хитроу», приведена на рис. 2.24.
|
Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
Связь – это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ею же самой (рекурсивная связь ).
В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи , степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т. е. любой ли экземпляр данной сущности должен участвовать в данной связи).
Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При этом в месте "стыковки" связи с сущностью используются трехточечный вход в прямоугольник сущности, если для этой сущности в связи может использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности.
Обязательный конец связи изображается сплошной , а необязательный – прерывистой линией.
Как и сущность, связь – это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
В примере, изображенном на рис. 2.25, связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров. При этом конец сущности с именем "для" позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем "имеет" означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.
| Рис. 2.26. Рекурсивная связь, связывающая сущность ЧЕЛОВЕК |
Конец связи с именем "сын" определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем "отец" означает, что не у каждого человека могут быть сыновья.
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно с примерами.
Нормальные формы ER-схем.
Как и в реляционных схемах БД, в ER-схемах вводится понятие нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем.
Приведем краткие и неформальные определения трёх первых нормальных форм:
· устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскированных" под атрибуты;
· устраняются атрибуты, зависящие только от части уникального идентификатора, эта часть уникального идентификатора определяет отдельную сущность.
· устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
К числу более сложных элементов модели относятся следующие:
· Подтипы и супертипы сущностей. Как в языках программирования с развитыми типовыми системами (например в языках объектно-ориентированного программирования), вводится возможность наследования типа сущности, исходя из одного или нескольких супертипов. Интересные нюансы связаны с необходимостью графического изображения этого механизма.
· Связи "many-to-many". Иногда бывает необходимо связывать сущности таким образом, что с обоих концов связи могут присутствовать несколько экземпляров сущности (наприме, все члены кооператива сообща владеют имуществом кооператива ). Для этого вводится разновидность связи "многие – со –
многими".
· Уточняемые степени связи. Иногда бывает полезно определить возможное количество экземпляров сущности, участвующих в данной связи (например служащему разрешается участвовать не более чем в трех проектах одновременно ). Для выражения этого семантического ограничения разрешается указывать на конце связи ее максимальную или обязательную степень.
· Каскадные удаления экземпляров сущностей. Некоторые связи бывают настолько сильными (в случае связи "один – ко – многим"), что при удалении опорного экземпляра сущности (соответствующего концу связи "один") нужно удалить и все экземпляры сущности, соответствующие концу связи "многие". Соответствующее требование "каскадного удаления" можно сформулировать при определении сущности.
· Домены . Как и в случае реляционной модели данных, иногда полезна возможность определения потенциально допустимого множества значений атрибута сущности (домена).
Эти и другие более сложные элементы модели данных "Сущность – Связи" делают ее существенно более мощной, но одновременно несколько усложняют ее использование. При реальном использовании ER-диаграмм для проектирования БД необходимо ознакомиться со всеми возможностями.
Разберем один из упомянутых элементов – подтип сущности .
Сущность может быть разделена на два или более взаимно исключающих подтипа. Каждый из них включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе «подтипизация» может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность , на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т. е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ .
Пример – супертип ЛЕТАТЕЛЬНЫЙ АППАРАТ – приведён на рис. 2.27.
Иногда удобно иметь два или более разных разбиения сущности на подтипы.
Например, сущность ЧЕЛОВЕК может быть разбита на подтипы по профессиональному признаку (ПРОГРАММИСТ, ДОЯРКА и т. д.), а может –
по половому признаку (МУЖЧИНА, ЖЕНЩИНА).
Лабораторная работа №1
Использование семантических сетей
для представления знаний
Цель работы: Научиться использовать семантические сети для представления знаний в информационных аналитических системах.
1. т еоретическая часть
Семантическая сеть – это один из способов представления знаний. Изначально семантическая сеть была задумана как модель представления долговременной памяти в психологии, но впоследствии стала одним из способов представления знаний в экспертной системе.
Семантика – означает общие отношения между символами и объектами из этих символов.
Рис.1. Простейший образец семантической сети.
Вершины – это объекты, дуги – это отношения. Семантическая модель не раскрывает сама по себе, каким образом осуществляется представление знаний. Поэтому семантическая сеть рассматривается как метод представления знаний и структурирования знаний.
Характерная особенность семантических сетей – это обязательное наличие 3 типов отношений.
Пример : класс – элемент класса, свойство – значение.
Пример элемента класса.
Существует несколько классификаций семантических сетей:
1) По количеству отношений
1. Однородные с единственным типом отношений;
2. Неоднородные с различными типами отношений.
2) По типам отношений
1. Бинарные сети – в которых отношения связывают 2 объекта;
2. Парные сети – в которых отношения связывают более чем 2 понятия.
Наиболее часто используются в семантических сетях:
1. Связь “часть – целое” (класс подкласс, элемент - множество);
2. Функциональные связи (производит, владеет);
3. Количественные отношения (A > 0, B < 0);
4. Пространственные отношения (далеко от, близко от, над, за и т. п.);
5. Временные (раньше, позже, одновременно);
6. Атрибутивные (иметь свойство, иметь значение);
7. Логические связи – и, или, не.
Минимальный состав отношений в семантической сети - это элемент класса, атрибутные связи и значение свойства.
При расширении семантической сети в ней возникают другие отношения:
IS – A (принадлежит) и PART OF (является частью) отношение:
целое ® часть .
Ласточка IS – A птица, «нос» PART OF «тело». Например:

Рис.2. Расширение семантической сети
Например, в предложении
«человек» IS - A «млекопитающее»
основной мыслью является, что человек принадлежит к классу млекопитающих. Это означает, что имеет место отношение включения или совпадения. Для этих отношений характерным является то, что экземпляры понятий нижнего уровня содержат все атрибуты понятий верхнего уровня. Это свойство называется наследованием атрибутов между уровнями иерархии IS - A..
Отношение «целое – часть» можно иллюстрировать предложением
«нос» PART - OF «тела» ,
которое характеризует то, что экземпляры понятия «нос» являются частью любого экземпляра понятия «тело».
Наиболее часто используется графическое представление семантических сетей в виде диаграммы. Так предложение
«все ласточки – птицы»
можно представить графом, содержащим две вершины соответствующие понятиям и дугу, указывающую отношение между ними (рис. 2.1).
Рис. 2.2. Семантическая сеть - 2
Наряду с тем, что с помощью данной сети описаны два факта
«Юка – ласточка»
«ласточка – птица»
из нее можно вынести, используя отношение наследования, факт
«Юка – птица»
Этот факт показывает, что способ представления семантической сетью позволяет легко делать выводы благодаря иерархии наследования.
Семантическими сетями можно также представлять знания, касающиеся атрибутов объекта. Например, факт «Птицы имеют крылья» можно отобразить в виде рис. 25.3.
 |
Рис. 2.3. Семантическая сеть - 3
Это означает, что, используя отношения «IS – A» и «PART – OF» можно вывести факт «Юка имеет крылья».
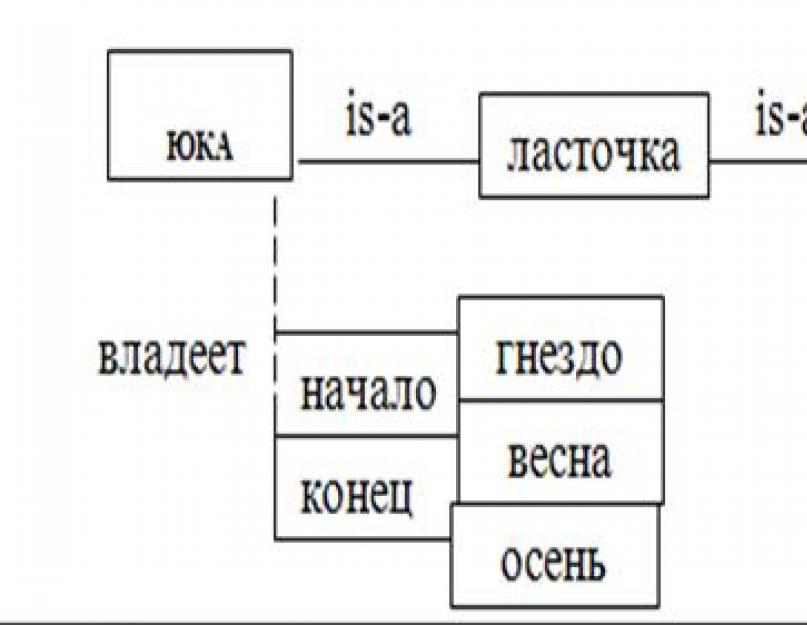
Вершины в семантической сети обычно показывают объект проблемной области, концепт, ситуацию и т. п., а дуги - это отношения между ними. При расширении семантической сети в ней возникают дополнительные отношения. Например, если рассматриваемую сеть дополнить фактами «Юка владеет гнездом» и «Юка владеет гнездом с весны по осень», то получим семантическую сеть, изображенную на рис. 2.4. Здесь гнездо i – это конкретное гнездо, которым владеет Юка, а для вершины ситуации (владеет j) определено несколько связей. Такая вершина называется надежной рамкой и определяет различные аргументы предиката ситуации.

Рис. 2.4. Семантическая сеть - 4
Получается иерархическая структура понятия ЮКА. Можно разбить на подсхемы. Большой проблемой для семантических сетей является то, что результат вывода не гарантирует достоверности, так как вывод есть просто наследование свойств ветви is-a.
Для отображения иерархических отношений между объектами и введения единой семантики в семантические сети было предложено использовать процедурные сети . Сеть строится на основе класса (понятия); вершины, дуги и процедуры представлены как объекты.
Проблема поиска решения в базе знаний типа семантической сети
сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному вопросу.
На рис. 3, 4 и 4-1 изображены примеры семантической сети.

Рисунок 3 – Модель

Рис. 4 Семантическая сеть, показывающая взаимоотношения птицы и самолета.

Рис. 4-1 Семантическая сеть, являющейся описанием объекта автомобиль и ряда связанных с ним понятий
В частности для рис. 4-1 присутствует следующая цепочка понятий:
"Вид автотранспорта имеет частью двигатель" , "Двигатель имеет частью стартёр" . В силу транзитивности отношения имеет частью можно вывести следующее утверждение "Вид автотранспорта имеет частью стартёр" . Аналогично можно сделать вполне очевидные выводы: "Мерседес является видом автотранспорта, который потребляет топливо и имеет частью двигатель" или "Водитель управляет автомобилем и везёт пассажира".
Преимущества модели:
Совпадает с тем, как человек познает мир;
Соответствие долговременной памяти человека.
Недостатки:
Сложность с поиском вывода.
Для реализации семантических сетей в экспертных системах существуют специальные сетевые языки. Систематизация отношений конкретной семантической сети зависит от специфики знаний предметной области и является сложной задачей. Особого внимания заслуживают общезначимые отношения, присутствующие во многих предметных областях. Именно на таких отношениях основана концепция семантической сети. В семантических сетях, так же как при фреймовом представлении знаний, декларативные и процедурные знания не разделены, следовательно, база знаний не отделена от механизма вывода. Процедура логического вывода обычно представляет совокупность процедур обработки сети. Семантические сети получили широкое применение в экспертных системах.
Возможные в семантических сетях отношения приведены в таблице.

Прямой и обратный вывод в экспертной системе продукционного типа.
Любая экспертная система продукционного типа должна содержать три основные компоненты: базу правил, рабочую память и механизм вывода. База правил - формализованные с помощью правил продукций знания о конкретной предметной области. Рабочая память - область памяти, в которой хранится множество фактов, описывающих текущую ситуацию, и все пары атрибут-значение, которые были установлены к определенному моменту. Содержимое рабочая память в процессе решения задачи обычно изменяется, увеличиваясь в объеме по мере применения правил. Другими словами, рабочая память - это динамическая часть базы знаний, содержимое которой зависит от окружения решаемой задачи. В простейших экспертных системах хранимые в рабочей памяти факты не изменяются в процессе решения задачи, однако существуют системы, в которых допускается изменение и удаление фактов из рабочей памяти. Это системы с немонотонным выводом, работающие в условиях неполноты информации.
Механизм вывода выполняет две основные функции:
· просмотр существующих в рабочей памяти фактов и правил из базы правил, а также добавление в рабочую память новых фактов;
· определение порядка просмотра и применения правил. Порядок может быть прямым или обратным.
Прямой порядок - от фактов к заключениям. В экспертных системах с прямыми выводами по известным фактам отыскивается заключение, которое из этих фактов следует. Если такое заключение удается найти, оно заносится в рабочую память. Прямые выводы часто применяются в системах диагностики, их называют выводами, управляемыми данными.
Обратный порядок вывода - от заключений к фактам. В системах с обратным выводом вначале выдвигается некоторая гипотеза о конечном суждении, а затем механизм вывода пытается найти в рабочей памяти факты, которые могли бы подтвердить или опровергнуть выдвинутую гипотезу. Процесс отыскания необходимых фактов может включать достаточно большое число шагов, при этом возможно выдвижение новых гипотез (целей). Обратные выводы управляются целями.
Для выполнения указанных функций механизм вывода включает компоненту вывода и управляющую компоненту. Действие компоненты вывода основано на применении правила логического вывода Modus Ponendo Ponens. Суть применения этого правила в продукционных системах состоит в следующем. Если в рабочей памяти присутствует истинный факт А и в базе правил существует правило вида «если А, то В», то факт В признается истинным и заносится в рабочую память. Такой вывод легко реализуется на ЭВМ, однако при этом часто возникают проблемы, связанные с распознаванием значений слов, а также с тем, что факты могут иметь внутреннюю структуру, и между элементами этой структуры возможны различного рода связи. Например, пусть имеется факт А - «автомобиль Иванова - белый» и правило «если автомобиль - белый, то автомобиль легко заметить ночью». Человек легко выведет заключение «автомобиль Иванова легко заметить ночью», но это не под силу экспертной системе чисто продукционного типа. Она не сможет сформировать такое заключение, потому что А не совпадает точно с антецедентом правила. Кроме того, невысокая интеллектуальная мощность продукционных систем обусловлена тем, что человек выводит заключения, имея в своем распоряжении все свои знания, то есть база знаний огромного объема, в то время как экспертные системы способны вывести сравнительно небольшое количество заключений, используя заданное множество правил. Из сказанного можно сделать вывод о том, что компонента вывода в экспертных системах должна быть организована так, чтобы быть способной функционировать в условиях недостатка информации.
Управляющая компонента определяет порядок применения правил, а также устанавливает, имеются ли еще факты, которые могут быть изменены в случае продолжения работы (при немонотонном выводе). Механизм вывода работает циклически, при этом в одном цикле может сработать только одно правило. Схема цикла приведена на рис. 5. В цикле выполняются следующие основные операции:
· сопоставление - образец (антецедент) правила сравнивается с имеющимися в рабочей памяти фактами;
· разрешение конфликтного набора - выбор одного из нескольких правил в том случае, если их можно применить одновременно;
· срабатывание правила - в случае совпадения образца некоторого правила из базы правил с фактами, имеющимися в рабочей памяти, происходит срабатывание правила, при этом оно отмечается в базе правил;
· действие - изменение содержимого рабочей памяти путем добавления туда заключения сработавшего правила. Если в заключении содержится директива на выполнение некоторой процедуры, последняя выполняется.
Поскольку механизм вывода работает циклически, следует знать о способах завершения цикла. Традиционными способами являются либо исчерпание всех правил из базы правил, либо выполнение некоторого условия, которому удовлетворяет содержимое рабочей памяти (например, появление в ней какого-то образца), либо комбинация этих способов. Особенностью экспертных систем является то, что они не располагают процедурами, которые могли бы построить в пространстве состояний сразу весь путь решения задачи. Траектория поиска решения полностью определяется данными, получаемыми от пользователя в процессе логического вывода.

Рис. 5 Цикл работы вывода.
Рассмотрим простейшие примеры прямого и обратного вывода в системах продукционного типа.
Пример прямого вывода. Пусть в базе правил имеются следующие правила:
Правило 1. «если двигатель не заводится, и фары не горят, то сел аккумулятор».
Правило 2. «если указатель бензина находится на нуле, то двигатель не заводится».
Предположим, что в рабочую память от пользователя экспертной системы поступили факты: фары не горят и указатель бензина находится на нуле. Рассмотрим основные шаги алгоритма прямого вывода.
1. Сопоставление фактов из рабочей памяти с образцами правил из базы правил. Правило 1 не может сработать, а правило 2 срабатывает, так как "образец, совпадающий с его антецедентом, присутствует в рабочей памяти.
2. Действие сработавшего правила 2. В рабочую память заносится заключение этого правила, то есть образец: двигатель не заводится.
3. Второй цикл сопоставления фактов в рабочей памяти с образцами правил. Теперь срабатывает правило 1, так как совпадение условий в его антецеденте становится истинной.
4. Действие правила 1, которое заключается в выдаче пользователю окончательного диагноза - сел аккумулятор.
5. Конец работы (база правил исчерпана).
Пример прямого вывода с конфликтным набором. Теперь допустим, что в базе правил кроме правила 1 и правила 2 присутствует правило 3: «если указатель бензина находится на нуле, то нет бензина». В рабочей памяти находятся те же факты, что в предыдущем примере. В результате сопоставления в первом же цикле возможно применение двух правил - правила 2 и правила 3, то есть возникает конфликтный набор и встает задача выбора: какое из этих правил применить первым. Если выберем правило 2, то в рабочей памяти добавится факт «двигатель не заводится» и на следующем шаге опять возникнет конфликтный набор, так как можно будет применить правило 1 и правило 3. Если будет выбрано правило 1, то к заключению «сел аккумулятор» придем за два шага. При любом другом выборе порядка применения правил к этому же заключению приходим за три шага. Если завершение цикла работы экспертной системы наступает после просмотра всех правил, то число шагов будет равно трем, причем порядок применения правил не будет иметь какого-либо значения.
Пример обратного вывода. Предположим, что в базе правил имеется два правила (правило 1 и правило 2), а в рабочей памяти - те же факты, что в предыдущих примерах с прямым выводом.
Алгоритм обратного вывода содержит следующие шаги.
1. Выдвигается гипотеза окончательного диагноза - сел аккумулятор.
2. Отыскивается правило, заключение которого соответствует выдвинутой гипотезе, в нашем примере - это правило 1.
2. Исследуется возможность применения правила 1, то есть решается вопрос о том, может ли оно сработать. Для этого в рабочей памяти должны присутствовать факты, совпадающие с образцом этого правила. В рассматриваемом примере правило 1 не может сработать из-за отсутствия в рабочей памяти образца «двигатель не заводится». Этот факт становится новой целью на следующем шаге вывода.
3. Поиск правила, заключение которого соответствует новой цели. Такое правило есть - правило 2.
4. Исследуется возможность применения правила 2 (сопоставление). Оно срабатывает, так как в рабочей памяти присутствует факт, совпадающий с его образцом.
5. Действие правила 2, состоящее в занесении заключения «двигатель не заводится» в рабочую память.
6. Условная часть правила 1 теперь подтверждена фактами, следовательно, оно срабатывает, и выдвинутая начальная гипотеза подтверждается.
7. Конец работы.
При сравнении этого примера с примером прямого вывода нельзя заметить преимуществ обратных выводов перед прямыми выводами.
Пример обратного вывода с конфликтным набором. Предположим, что в базе правил записано правило 1, правило 2, правило 3 и правило 4: «если засорился бензонасос, то двигатель не заводится». В рабочей памяти присутствуют те же самые факты: «фары не горят и указатель бензина находится на нуле». В данном случае алгоритм обратного вывода с конфликтным набором включает следующие шаги.
1. Выдвигается гипотеза сел аккумулятор.
2. Поиск правила, заключение которого совпадает с поставленной целью. Это правило 1.
3. Исследуется возможность применения правила 1. Оно не может сработать, тогда выдвигается новая подцель «двигатель не заводится», соответствующая недостающему образцу.
4. Поиск правил, заключения которых совпадают с новой подцелью. Таких правил два: правило 2 и правило 4. Если выберем правило 2, то дальнейшие шаги совпадают с примером без конфликтного набора. Если выберем правило 4, то оно не сработает, так как в рабочей памяти нет образца: «засорился бензонасос». После этого будет применено правило 2, что приведет к успеху, но путь окажется длиннее на один шаг.
Следует обратить внимание на то, что правило 3, не связанное с поставленной целью, вообще не затрагивалось в процессе вывода. Этот факт свидетельствует о более высокой эффективности обратных выводов по сравнению с прямыми выводами. При обратных выводах существует тенденция исключения из рассмотренных правил тех правил, которые не имеют отношения к поставленной цели.
Семантическая сеть как Пролог - программа
Важнейшей концепцией формализма семантических сетей является иерархия понятий и связанное с ней наследование атрибутов между уровнями иерархии IS - A.
Если семантическую сеть рассматривать как описание отношений, которые поддерживаются между понятиями, то ее непосредственно, можно реализовать на языке Пролог.
На рис. 6 представлена структура сети, аналогичная примеру предыдущего раздела.

Рис. 6. Семантическая сеть
Эта сеть может быть реализована в Пролог - программе
является (ласточка, птица)
является (Юка, ласточка)
имеет (крылья, птица)
имеет (X, Y): - является (Y, Z), имеет (X , Z).
/* учитывает иерархию наследования */
При учете в модели знаний, представленных семантической сетью, такого свойства всех ласточек, что они черного цвета, в программу достаточно добавить факт:
имеет (черный цвет, ласточка)
Если модель знаний будет дополнена общим свойством для всего класса птиц, таким, что они летают, то это приведет к добавлению в программу не только факта
летает (птица)
но и правила, которое должно реализовать иерархию наследования, т. е.
летает (Х):- является (Х, Y), летает (Y).
Элементы семантической сети
Семантическая сеть представляет собой ориентированный граф с помеченными (поименованными) дугами и вершинами. Основными элементами сети являются вершины и дуги. При этом вершинам семантической сети соответствуют понятия, события и свойства (рис. 7).
 |
Рис. 7. Вершины семантической сети
Понятия представляют собой сведения об абстрактных или физических объектах предметной области (реального мира).
События представляют собой действия происходящие в реальном мире и определяются:
Указание типа действия;
Указание ролей, которые играют объекты в этом действии.
Свойства используются для уточнения понятий и событий. Применительно к понятиям они описывают их особенности и характеристики (цвет, размер, качество), а применительно к событиям - продолжительность, время, место.
Дуги графа семантической сети отображают многообразие семантических отношений, которые условно можно разделить на четыре класса (рис. 8).
Рис. 8. Классификация семантических отношений
Лингвистические отношения отображают смысловую взаимосвязь между событиями, между событиями и понятиями или свойствами. Лингвистические отношения бывают:
Глагольные (время, вид, род, залог, наклонение);
Атрибутивные (цвет, размер, форма);
Падежными (см. ниже).
Логические отношения - это операции, используемые в исчислении высказываний (алгебра логики): дизъюнкция, конъюнкция, инверсия, импликация.
Теоретико-множественные - это отношение подмножества, отношение части целого, отношение множества и элемента. Примерами таких отношений являются IS-A, PART-OF.
Квантифицированные отношения - это логические кванторы общности и существования. Они используются для представления таких знаний как «Любой станок надо ремонтировать», «Существует работник А, обслуживающий склад Б».
Рассмотренные выше примеры семантических сетей отображали знания о структуре понятий и их взаимосвязях. Далее рассмотрим использование семантических сетей для представления событий и действий.
Представление структуры понятий семантической сетью
Основой для определения любого понятия является множество его отношений с другими понятиями. Обязательными отношениями являются:
Класс, которому принадлежит данное понятие;
Свойства, выделяющие понятие из всех понятий данного класса;
Примеры (экземпляры) данного понятия.
Так как термы, используемые в определении понятия, сами являются понятиями, то их определение организуется по той же схеме. В итоге связи понятий образуют структуру, в общем случае сетевую, в которой используется как минимум два типа связей (IS - A и PART – OF).
Пример : Семантическая сеть, отображающая связи понятий при описании знаний о структуре понятия юридическое лицо будет иметь вид (рис. 9):
0 " style="border-collapse:collapse;border:none">
Падеж
Лингвистическое (падежное) отношение,
определяющее связь действия с:
Предметом, являющимся инициатором действия
Предметом, подвергающимся действию
источник
Размещение предмета перед действием
приемник
Размещение предмета после действия
Моментом выполнения действия
Местом проведения действия
Действием другого события
Так, например, семантическая структура знания о событии «Директор завода «Салют» остановил 30.03.96 цех №4 чтобы заменить оборудование» будет представлена в виде рис. 10.
https://pandia.ru/text/80/351/images/image017_7.jpg" width="563" height="136 id=">
Рис. 11. Семантическая сеть «Подчиненность сотрудников организации»
Приведенные связи показывают подчиненность первого сотрудника. Остальные сотрудники связываются через вершины сети. Остальные сотрудники связываются через вершины сети «руководит 2», «руководит 3» и т. д.
Запрос: «Кто руководит Сидоровым?», представим в виде подсети (рис. 12.
DIV_ADBLOCK277">
Выделим основные факты этих знаний, соответствующие действиям:
F1 - станок закончил обработку
F2 - работник грузит
F3 - робокар перевозит
F4 - кассета содержит детали
Заметим, что при описании фраз естественного языка факты часто называют высказываниями. Схема семантической сети будет следующей (рис. 13):

Рис. 13. Построение семантической сети
Пример фрагмента программы прямой цепочки рассуждений приведен на рис. 14. Для простоты предполагается, что правила не содержат переменных.

Рис. 14. Пример фрагмента программы прямой цепочки рассуждений
Поиск решения:
1. На основании фактов, известных на момент решения задачи, можно решить только правило %3. В результате состав фактов станет таким:
Вода(гостиная)
Сухо(ванная)
Закрыто (окно)
Неисправность (кухня)
2. Делается попытка решить очередное правило. Таким правилом станет правило %4. В результате к фактам добавится ещё один:
Вода(гостиная)
Сухо(ванная)
Закрыто (окно)
Неисправность (кухня)
НеПоступает (вода, снаружи)
3. Становится возможным решение правила %2, и получается ответ YES
Необходимо отметить ряд преимуществ семантической сети:
Описание понятий и событий производится на уровне, очень близком к естественному языку;
Обеспечивается возможность сцепления различных фрагментов сети;
Отношение между понятиями и событиями образуют достаточно небольшое и хорошо формализованное множество;
Для каждой операции над данными и знаниями можно выделить из полной сети, представляющей всю семантику (или все знания), некоторый ее участок, который охватывает необходимые в данном запросе смысловые характеристики.
1. Изучить теоретическую часть по приведенным выше данным и дополнительной литературе;
2. Просмотреть демонстрационные примеры;
3. Получить у преподавателя вариант задания для выполнения;
4. Построить семантическую модель заданного объекта;
5. Реализовать программу с использованием семантической модели.
3. Варианты заданий
Используя соответствующие дуги построить семантическую сеть, касающуюся:
1. географии какого-либо региона. Дуги: государство, страна, континент, широта.
2. диагностики глазных заболеваний. Дуги: категории болезней, патофизиологическое состояние, наблюдения, симптомы.
3. распознавания химических структур. Дуги: формула вещества, свойства вещества, область применения, меры предосторожности.
10. иерархической структуры БД. Дуги: система, состояние, назначение, взаимодействие составляющих.
4. К онтрольные вопросы
1. Что такое семантическая сеть и для чего ее применяют?
2. В чем состоит идея создания семантической сети?
3. Каким образом представляются данные в семантической сети?
4. Существуют ли ограничения на число связей элементов, свойств и сложность при построении семантической сети?
5. Какие отношения предложены в качестве операторов отношения для группировки вершин?
Термин семантическая означает смысловая, а семантика - это наука, устанавливающая отношения между символами и объектами, которые они обозначают, то есть наука, определяющая смысл знаков. Семантическая сеть - это ориентированный граф, вершины которого это понятия, а дуги - отношения между ними.
Понятия делятся на:
- События
Под событием понимают различные объекты проблемной области: суждения, факты, результаты наблюдений и т.д. Одно событие не может встречаться в одном разделе семантической сети больше одного раза.
События делятся на характеризуемые и характеризующие. Например, событие дождливая погода характеризуется событием идет дождь, так как без дождя дождливой погоды не может быть.
Если характеризующее событие имеет несколько значений, то оно называется атрибутом. Например, свойством понятия Времена года является Погода. Так как последнее имеет несколько значений: Холодная, Теплая, Дождливая и т.д., то ее можно считать атрибутом Времени года.
Атрибуры
Комплексы признаков
Процедуры – специфические элементы сети, которые выполняют преобразование информации. Они позволяют вычислять значения одних атрибутов на основании других, оперируя как с числами, так и с символами.
В семантических сетях используются следующие отношения:
Элемент класса;
Атрибутные связи;
Значение свойства;
Пример элемента класса;
Связи типа «часть-целое»;
Функциональные связи, определяемые глаголами «производит», «влияет»;
Количественные (больше, меньше, равно …);
Пространственные (далеко от, близко от, за, под, над …);
Временные (раньше, позже, в течение…);
Логические связи (и, или, не) и др.
Минимальный состав отношений в семантической сети - это элемент класса, атрибутные связи и значение свойства.
На рис. 8 изображен пример семантической сети.
Рис. 8 Семантическая сеть, показывающая взаимоотношения птицы и самолета.
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети или подсети, соответствующей поставленному вопросу.
Вывод знаний в сетевой модели
Для вывода знания события в сетевой модели делятся на исходные (признаки) и целевые (гипотезы).
Значения признаков предполагаются известными.
Все признаки, помимо присущих им значений: Истинно (Да) и Ложно (Нет) - имеют еще два стандартных значения: Пока неизвестно и Неизвестно. При задании последнего значения признак исключается из рассмотрения. Значения исходных атрибутов либо выбираются из определенного списка, либо вводятся извне. Объектами вывода в рассматриваемой модели являются гипотезы. К ним относятся рекомендации, диагнозы, прогнозы и другие решения, определяемые спецификой ПО. Условием вывода должно быть существование хотя бы одной гипотезы. В этом случае решением является оценка ее истинности.
Виды семантических связей
Семантическая связь (СС) отражает отношение понятий в понятийной системе. В лексике им соответствуют лексемы любого вида, в том числе представляющие предикаторы «меньше», «равно», «если, то» и др.
Внелексические свойства СС выражаются через:
Rf - рефлексивность;
Nrf - нерефлексивность;
Arf - антирефлексивность (ни одной рефлексии);
Sm - симметричность;
Ns - несимметричность;
Ans - антисимметричность (ни одной симметрии);
As - асимметричность (контекстное свойство - обращение связи дает иную связь из списка);
Тг - транзитивность;
Ntr - нетранзитивность.
Внелексические свойства семантических связей в суждениях проверяются следующим образом.
Относительно сочетания перечисленных свойств СС делятся на типы, представленные в (табл. 2.1.).
1. Рефлексивность определяется по критерию подстановки:
вместо объекта А подставляется объект В(АгВ -> ВгВ) и выбирается один из следующих ответов:
вполне возможно (тавтология) ~» Rf;
не исключено -> Nrf;
невозможно -> Arf.
Пример. Вегетативные расстройства сопровождаются вегетативными расстройствами. Ответ 1 для Com.
2. Симметричность определяется по критерию перестановки: объекты А и В меняются местами (АгВ -» ВгА) и выясняется справедливость полученного предложения. При утвердительном ответе высказыванию приписывается свойство Sm, в противном случае - свойство Ns.
Пример. Головная боль всегда сопровождается вегетативными расстройствами, и Вегетативные расстройства всегда сопровождаются головной болью. Ответ «Нет» для Com. Это соответствует свойству Ns. Свойство Ns уточняется на более сильные свойства: Ans и As. Первое имеет место для любых примеров анализируемой связи. Например, для связи Com имеет место свойство Ans.
Плюс модели: Легка в реализации.
Минус модели: Плохо структурирована – при большом количестве элементов можно запутаться, а при увеличении объема информации – может произоти комбинаторный взрыв.При создании любой вещи, любого изделия, любого произведения человек встает перед необходимостью неизбежного выбора среди огромного числа возможных вариантов. К чему при этом может привести простой перебор этих вариантов проследим на следующем явлении. Это явление известно в кибернетике под названием комбинаторный взрыв. Что это за "зверь" нетрудно продемонстрировать на простом примере. Допустим, что имеется некий алфавит, состоящий всего из 10 символов (букв).
Из такого алфавита можно составить 10^^100 текстов длиной по 100 букв. Гипотетический компьютер, обладающий возможностью обрабатывать 10^^18 таких текстов в секунду, потратит на общий анализ всех текстов 10^^74 лет. Для сравнения – по современным космогоническим представлениям с момента Большого взрыва исследованной части Вселенной прошло ~10^^10 лет.
Модель семантических сетей
Семантические сети представляют собой ориентированные графы с помеченными дугами. Аппарат семантических сетей является естественной формализацией ассоциативных связей, которыми пользуется человек при извлечении каких-то новых фактов из имеющихся. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т. п.
Обычно в семантической сети предусматриваются четыре категории вершин:
Понятия (объекты),
События,
Свойства,
Значения.
Понятия представляют собой константы или параметры, которые определяют физические или абстрактные объекты.
События представляют действия, происходящие в реальном мире, и определяются указанием типа действия и ролей, которые играют объекты в этом действии.
Свойства используются для представления состояния или для модификации понятий и событий.
Сведения семантической сети образуют сценарий, который является набором понятий, событий и причинно-следственных связей.
Необходимо различать вершины, обозначающие экземпляры объектов, и вершины, представляющие классы объектов. Например, Новиков - экземпляр типа Студент. В семантической сети экземпляр может принадлежать более чем одному классу (Новиков – и Студент, и Спортсмен).
В других моделях в отличие от семантической сети типы объектов указаны в схеме, а экземпляры объектов представлены значениями в базе данных. В семантической сети один и тотже экземпляр объекта может быть соотнесен с несколькими типами.
В синтаксических моделях (реляционной, сетевой или иерархической) для обеспечения такой связи потребуется дублирование информации об объекте.
Все семантические отношения предметной области можно разделить на следующие:
Лингвистические,
Логические,
Теоретико-множественные,
Квантификационные.
Лингвистические отношения бывают глагольные (время, вид, род, число, залог, наклонение) и атрибутивные (модификация, размер, форма).
Логические отношения подразделяются на конъюнкцию (и), дизъюнкцию (или), отрицание (не) и импликацию (если – то).
Теоретико-множественные отношения - это отношение подмножества, отношение части и целого, отношение множества и элемента.
Квантификационные отношения делятся на логические кванторы общности и существования («каждый», «все»), нелогические кванторы («много», «несколько») и числовые характеристики.
При установлении структуры понятий существуют две обязательные связи
1- связь "есть-нек" (от слов "есть некоторый"). Направлена от частного понятия к более общему и показывает принадлежность элемента к классу;
2- связь "есть-часть". Показывает, что объект содержит в своем составе разнородные компоненты (объекты), не подобные данному объекту.
Пример семантической сети для описания структуры понятия "юридическое лицо" приведен на следующем рисунке.
Рисунок 4.2 Элементы семантической сети
Связь "есть-нек" обозначается одной линией, связь "есть-часть" – двумя.
Рассмотрим представление событий и действий с помощью семантической сети. Выделяются простые отношения, которые характеризуют основные компоненты события. В первую очередь из события выделяется действие, которое обычно описывается глаголом. Далее необходимо определить объекты, которые действуют, объекты, над которыми эти действия производятся, и т. д. Все эти связи предметов, событий и качеств с глаголом называются падежами. Обычно рассматривают следующие падежи:
1. агент - предмет, являющийся инициатором действия;
2. объект - предмет, подвергающийся действию;
3. источник - размещение предмета перед действием;
4. приемник - размещение предмета после действия;
5. время - указание на то, когда происходит событие;
6. место - указание на то, где происходит событие;
7. цель - указание на цель действия.
Рассмотрим пример: Директор завода "САЛЮТ" остановил 25.03.90 цех № 4, чтобы заменить оборудование

Рисунок 4.3 Пример семантической сети
Преимущества семантических сетей:
1) описание объектов и событий на уровне, очень близком к естественному языку;
2) обеспечивается возможность сцепления различных фрагментов сети;
3) возможные отношения между понятиями и событиями образуют достаточно небольшое и хорошо формализованное множество;
4) можно выделить из полной сети, представляющей все знания, некоторый участок семантической сети, который необходим в конкретном запросе.
4.4 Базы знаний
В современных системах управления вопрос о принятии решений информационной системой требует фиксации знаний об управляемом объекте и реализации моделей принятия решений, характерных для человека-специалиста (инженера, технолога, экономиста, бухгалтера). Способность человека накапливать и использовать знания, принимать решения можно назвать естественным интеллектом, соответствующие возможности информационной системы получили название искусственный интеллект.
Система понятий для представления знаний существенно отличается от понятий для представления данных, поэтому отображение знаний производится в базу знаний. Вместе с тем база знаний способна хранить данные как простую разновидность знаний.
Запросы, которые формулируются пользователями информационной системы, реализуются одним из двух возможных способов:
Сообщения, являющиеся ответом на запрос, хранятся в явном виде в БД, и процесс получения ответа представляет собой выделение подмножества значений из файлов БД, удовлетворяющих запросу;
Ответ не существует в явном виде в БД и формируется в процессе логического вывода на основании имеющихся данных.
Последний случай принципиально отличается от рассмотренной ранее технологии использования баз данных и рассматривается в рамках представления знаний, т. е. информации, необходимой в процессе вывода новых фактов. База знаний содержит:
Сведения, которые отражают существующие в предметной области закономерности и позволяют выводить новые факты, справедливые в данном состоянии предметной области, но отсутствующие в БД, а также прогнозировать потенциально возможные состояния предметной области;
Сведения о структуре ЭИС и БД (метаинформация);
Сведения, обеспечивающие понимание входного языка, т. е. перевод входных запросов во внутренний язык.
Принято говорить не о "знаниях вообще", а о знаниях, зафиксированных с помощью той или иной модели знаний.
Принципиальными различиями обладают три модели представления знаний - продукционная модель, модель фреймов и модель семантических сетей.
4.5 Продукционная модель знаний
Продукционная модель состоит из трех основных компонентов:
Набора правил, представляющего собой в продукционной системе базу знаний;
Рабочей памяти, в которой хранятся исходные факты и результаты выводов, полученных из этих фактов;
Механизма логического вывода, использующего правила ц соответствии с содержимым рабочей памяти и формирующего новые факты.
Каждое правило содержит условную и заключительную части. В условной части правила находится одиночный факт либо несколько фактов (условий), соединенных логической операцией "И".
В заключительной части правила находятся факты, которые необходимо дополнительно сформировать в рабочей памяти, если условная часть правила является истинной.
Пример
Предположим, что в рабочей памяти хранятся следующие факты:
Доля выборки записей равна 0,09;
ЭВМ - PC XT.
Правила логического вывода имеют вид:
1) Если метод доступа индексный, то СУБД - dBASE 3.
2) Если метод доступа последовательный, то СУБД - dBASE 3.
3) Если доля выборки записей <0,1, то метод доступа - индексный.
4) Если СУБД - dBASE 3 и ЭВМ - PC XT, то программист -Иванов.
Механизм вывода сопоставляет факты из условной части каждого правила с фактами, хранящимися в рабочей памяти. В данном примере сопоставление условия правила 3 с фактами из рабочей памяти приводит к добавлению нового факта "Метод доступа - индексный" и исключению правила 3 из списка применяемых правил.
С учетом нового факта становится справедливой условная часть правила 1, и в рабочей памяти появляется факт "СУБД -dBASE З". Далее становится применимым правило 4, что приводит к фиксации в рабочей памяти факта "Программист - Иванов". В этот момент дальнейшее применение правил невозможно, и процесс вывода останавливается. Наш пример показывает, что применимость каждого правила из базы знаний в процессе вывода вовсе не обязательна.
Новые факты, полученные механизмом вывода:
Метод доступа - индексный,
СУБД-dBASE 3,
Программист - Иванов.
В приведенном примере для получения вывода правила применялись к фактам, записанным в рабочей памяти, и в результате применения правил добавлялись новые факты. Такой способ действий называется прямым выводом. Возможен также обратный вывод целей. В качестве цели выступает подтверждение истинности факта, отсутствующего в рабочей памяти. При обратном выводе исследуется возможность применения правил, подтверждающих цель, необходимые для этого дополнительные факты становятся новыми целями и процесс повторяется.
Предположим, что в нашем примере запрос цели имеет вид:
? "программист - Иванов".
Эта цель подтверждается правилом 4. Необходимые для правила 4 факты - "ЭВМ - PC XT" и "СУБД - dBASE 3". Первыйизних присутствует в рабочей памяти, а второй становится новой целью. Для этой цели требуется подтверждение правила 1 или правила 2. Факт-условие правила 2 не содержится в рабочей памяти и не является заключением существующих правил. Поэтому данная ветвь обратного вывода обрывается. Для применения правила 1 необходим факт "Метод доступа - индексный", он является заключением правила 3, а условие правила 3 соблюдается (в рабочей памяти хранится факт "Доля выборки записей равна 0.09").
В итоге первоначальная цель "программист-Иванов" признается истинной.
В случае обратного вывода условием останова системы является окончание списка правил, которые относятся к доказываемым целям. При прямом выводе останов происходит по окончании списка применимых правил. Следует отметить, что на каждом шаге вывода количество одновременно применимых правил может быть любым (в отличие от примеров, приведенных выше). Последовательность выбора подходящих правил не влияет на однозначность получаемого ответа; однако может существенно увеличить требуемое число шагов вывода. В реальных базах знаний с большим числом правил это может существенно снизить быстродействие системы. В системах с обратным выводом есть возможность исключить из рассмотрения правила, не имеющие отношения к выводу требуемых целей, и тем самым несколько ослабить указанный отрицательный эффект. По этой причине системы с обратным выводом целей получили большее распространение.
Представление знаний в виде набора правил имеет следующие преимущества:
Простота создания и понимания отдельных правил;
Простота механизма логического вывода.
К недостаткам этого способа организации базы знаний относятся:
Неясность взаимных отношений правил;
Отличие от человеческой структуры знаний.
4.6 Фреймы
В основе теории фреймов лежит фиксация знаний путем сопоставления новых фактов с рамками, определенными для каждого объекта в сознании человека. Структура в памяти ЭВМ, представляющая эти рамки, называется фреймом. С помощью фреймовмы пытаемся представить процесс систематизации знаний в форме, максимально близкой к принципам систематизации знаний человеком.
Фрейм представляет собой таблицу, структура и принципы организации которой являются развитием понятия отношения в реляционной модели данных. Новизна фреймов определяется двумя условиями:
1) имя атрибута может в ряде случаев занимать в фрейме позицию значения,
2) значением атрибута может служить имя другого фрейма или имя программно реализованной процедуры. Структура фрейма показана ниже.
Слотом фрейма называется элемент данных, предназначенный для фиксации знаний об объекте, которому отведен данный фрейм. Перечислим параметры слотов.
Имя слота. Каждый слот должен иметь уникальное имя во фрейме, к которому он принадлежит. Имя слота в некоторых случаях может быть служебным. Среди служебных имен отметим имя пользователя, определяющего фрейм; дату определения или модификации фрейма; комментарий.
Указатель наследования. Он показывает, какую информацию об атрибутах слотов во фрейме верхнего уровня наследуют слоты с теми же именами во фрейме нижнего уровня. Приведем типичные указатели наследования:
S (тот же). Слот наследуется с теми же значениями данных;
U (уникальный). Слот наследуется, но данные могут принимать любые значения;
I (независимый). Слот не наследуется.
Указатель типа данных. К типам данных относятся:
FRAME (указатель) - указывает имя фрейма верхнего уровня;
ATOM (переменная),
TEXT (текстовая информация),
LIST (список),
LISP (присоединенная процедура).
С помощью механизма управления наследованием по отношениям "есть-нек" осуществляются автоматический поиск и определение значений слотов фрейма верхнего уровня и присоединенных процедур.
Рассмотримпример использования системы фреймов. Иерархия фреймов, показанная на рис. 4.4.а, отображает организационную структуру и работы, выполняемые в некотором отделе конструкторского бюро. Она предназначена для фиксации факта окончания отдельных работ исполнителями, группами и отделом в целом. Фрейм ROOT является стандартным фреймом, все другие фреймы должны быть подчинены ему. Слот АКО используется для установления иерархии фреймов.
Работа начинается посредством передачи сообщения в слот фрейма верхнего уровня DEP. При этом запускается присоединенная процедура, которая передает в фреймы нижнего уровня значение текущей даты. Когда происходит заполнение какого-то слота в фрейме, делается попытка дать значения всем слотам этого фрейма, в том числе попытка выполнения присоединенной процедуры.
Фреймовые системы обеспечивают ряд преимуществ по сравнению с продукционной моделью представления знаний:
1)знания организованы на основе концептуальных объектов;
2)допускается комбинация представления декларативных (как устроен объект) и процедурных (как взаимодействует объект) знаний;
3)иерархия фреймов вполне соответствует классификации понятий, привычной для восприятия человеком;
4)система фреймов легко расширяется и модифицируется.
Трудности применения фреймовой модели знаний в основном связаны с программированием присоединенных процедур.

| Имя слота | Указатель наследования | Указатель Типа | Значение слота |
| FRAME-NAME: DEP | |||
| АКО | (U) ROOT | FRAME ROOT | |
| DESINF | (U) ROOT | TEXT | (ОТДЕЛ 23) |
| DATE | (U) ROOT | LIST | |
| ТЕМА | (I) .TOP. | LIST | (TEMA1 ТЕМА2) |
| ТЕМА1 | (I) «TOP» | LIST | NIL |
| ТЕМА2 | (I) .TOP. | LIST | NIL |
| FLAG1 | (I) «TOP. | ATOM | |
| FLAG2 | (I) TOP. | ATOM | |
| LOGIC | (U) «TOP. | LISP | MAIN |
| FRAME-NAME: TEMA1 | |||
| АКО | (U) ROOT | FRAME DEP | |
| DESINF | (U) ROOT | TEXT | (КОНСТРУИРОВАНИЕ ПЛЕЕРА) |
| DAE | (U) ROOT | LIST | |
| FAM | (I) «TOP. | LIST | (FAM1 FAM2 FAM3) |
| FAM1 | (I) TOP» | LIST | NIL |
| FAM2 | (I) «TOP. | LIST | NIL |
| FAM3 | (I) TOP. | LIST | NIL |
| FLAG1 | (1) .TOP* | ATOM | |
| FLAG2 | (1) «TOP» | ATOM | |
| FLAG3 | (1) TOP» | ATOM | |
| LOGIC | (U) TOP. | LISP | COMP1 |
| FRAME-NAME: FAM1 | |||
| AKO | (U) ROOT | FRAME TEMA1 | |
| DESINF | (U) ROOT | TEXT | (ЛЕНТОПРОТЯЖНЫЙ |
| МЕХАНИЗМ) | |||
| DATE | (U) ROOT | LIST | |
| TODAY | (1) «TOP» | ATOM | |
| ENDDATE | (1) .TOP. | ATOM | 02.04.91 |
| LOGIC | (U) .TOP» | LISP | COMPDATE |
Рисунок 4.4 Пример базы знаний фреймового типа:
а - иерархия фреймов; б - значения слотов
4.7 Семантические сети для представления знаний
Особенность семантической сети как модели знаний состоит в единстве базы знаний и механизма вывода новых фактов. На основании вопроса к базе знаний строится семантическая сеть, отображающая структуру вопроса, и ответ получается в результате сопоставления общей сети для базы знаний в целом и сети для вопроса.
Рассмотримпример семантической сети, отображающий подчиненность сотрудников в отделе учреждения, приведенный на рис. 35,а. Приводятся связи, показывающие подчиненность первого сотрудника. Остальные сотрудники отдела связываются через вершины сети связями типа "руководит 2", "руководит 3" и т. д.
Вопрос "Кто руководит Серовым?" представляется в виде подсети, показанной на рис. 4.5,б. Сопоставление общей сети с сетью запроса начинается с фиксации вершины "руководит", имеющей ветвь "объект", направленную к вершине "Серов". Затем производится переход по ветви "руководит", что и приводит к ответу "Петров"

Рисунок 4.5 Примеры: а - семантической сети;
б - сети логического вывода для запроса
Преимущества семантических сетей состоят в том, что это достаточно понятный способ представления знаний на основе отношений между вершинами и дугами сети. Однако с увеличением размеров сети ухудшается се обозримость и увеличивается время вывода новых фактов с помощью механизма сопоставления.
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. Притом, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Семантическая модель - модель предметной области, предназначенная для представления семантики предметной области на самом высоком уровне абстракции. Это означает, что устранена или минимизирована необходимость использовать понятия «низкого уровня», связанные со спецификой физического представления и хранения данных.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Наиболее известным представителем класса семантических моделей является модель «сущность-связь» (ER-модель).
Основные преимущества ER-моделей:
- § наглядность;
- § модели позволяют проектировать базы данных с большим количеством объектов и атрибутов;
- § ER-модели реализованы во многих системах автоматизированного проектирования баз данных (например, ERWin).
Основные элементы ER-моделей:
- § объекты (сущности);
- § атрибуты объектов;
- § связи между объектами
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа.
Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой. В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи). Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Графически связь изображается в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При этом в месте "стыковки" связи с сущностью используются трехточечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией.
- · Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой).
- · Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой).
- · Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности.
В моем курсовом проекте ER-модель имеет связь типа один-ко-многим.