У пользователей, которым приходится работать с документами, иногда возникает необходимость перевести текст с бумаги в цифровой документ, чтобы с ним можно было впоследствии работать в текстовом редакторе. Набирать текст с листка вручную - занятие довольно трудоемкое и неблагодарное, особенно если этого текста не один листик, а страниц 20-30, или даже больше. В таком случае может сильно пригодиться специальный инструмент для распознавания текста, называемый OCR (Optical Character Recognition). Программа оптического распознавания текста поможет выиграть время, которое вы могли бы потратить на перепечатку текста, а также даст возможность сохранить иллюстрации, что порой тоже очень важно. В данной статье мы проведем небольшой обзор наиболее популярных и востребованных OCR-инструментов
ABBYY Fine Reader
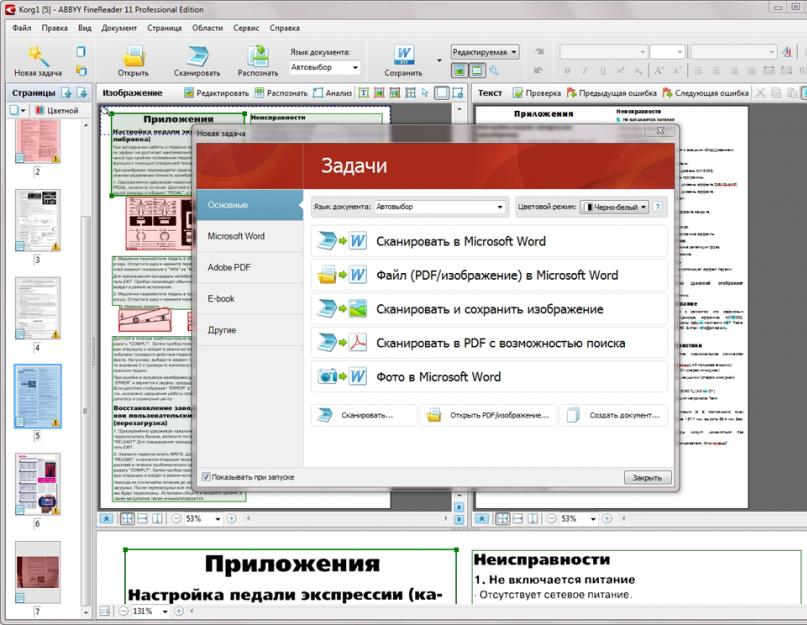
Программа ABBYY Fine Reader является одним из лучших инструментов для распознавания отсканированных документов. Также данная программа может распознавать PDF и DjVu-файлы.

Fine Reader имеет встроенный текстовый редактор с проверкой орфографии, может проводить распознавание текста с изображений почти всех форматов, поддерживает более 180-ти языков. Программа позволяет проводить довольно качественное извлечение текста даже из тех изображений, которые были сделаны при помощи цифровой камеры и имеют неравномерное освещение и недостаточную резкость.
Программа ABBYY Fine Reader выпускается в трех версиях: Home Edition, Professional Edition и Corporate Edition. Первая версия предназначена для домашнего использования и имеет слегка упрощенный интерфейс, вторая больше подходит для профессиональной работы с текстом, так как ее функциональность несколько шире, а версия Corporate Edition ориентирована на совместное использование в различных организациях.
ABBYY Fine Reader является платной программой, пробную демо-версию продукта можно бесплатно скачать на официальном сайте разработчика, который находится по адресу Abbyy.ru
OmniPage
OmniPage – это еще один качественный профессиональный инструмент для распознавания текста с графических и PDF-файлов. Программа обеспечивает качественное и быстрое распознавание документа с полным сохранением его структуры, что особенно важно при распознавании документов, которые содержат таблицы.

OmniPage имеет поддержку более чем 120 языков, также в программу встроены распознавательные словари для юридических, финансовых и медицинских терминов. Помимо распознавания текста, программа также имеет такие функции, как конвертация документов в PDF, конвертация электронных документов в аудиофайл и распознавание текста с изображения напрямую в аудиофайл.
Программа OmniPage также платная, приобрести ее можно на официальном сайте разработчика - Nuance.com .
OCR CuneiFrom
Программа OCR CuneiFrom после разработки позиционировалась как платный продукт, однако со временем компания-разработчик стала распространять ее бесплатно и даже открыла исходные коды программы, предложив всем желающим принять участие в улучшении работы программы. OCR CuneiFrom имеет простой, но приятный интерфейс, и может распознавать текст на более чем 20-ти языках. При распознавании программа сохраняет форматирование текста и расположение таблиц, а встроенные алгоритмы оптического распознавания позволяют выполнять извлечение текста даже из нечетких ксерокопий и факсов.

Программа OCR CuneiFrom является, пожалуй, лучшим бесплатным инструментом для распознавания документов. Скачать бесплатно данную утилиту можно на официальном сайте разработчика по адресу Cognitiveforms.ru .
Помимо программ для распознавания текста, вы можете воспользоваться еще и специальными сервисами, с помощью которых можно выполнять распознавание документов в режиме онлайн. Разумеется, их возможности несколько ограничены по-сравнению с возможностями специализированных программ, однако для небольших объемов такие сайты вполне сгодятся.
OCR CuneiForm сможет отсканировать и мгновенно распознать бумажную документацию по технологии Optical Character Recognition в редактируемые текстовые и табличные форматы, совместимые с Microsoft Office Word и Excel. Потом материалы лучше сохранить и редактировать в офисных пакетах, текстовых и табличных редакторах, аналогах Microsoft Word и Microsoft Excel. Программа распространяется "как есть", разработчики не несут ответственности в связи с возможными проблемами и могут отменить действие свободной лицензии для следующих версий, поэтому стоит поторопиться и последнюю версию OCR CuneiForm скачать бесплатно для Windows 10, 8.1, 8, 7, Vista, XP, Linux или Mac OS X. Экономить время с КьюниФорм разработчики предлагают по принципу: чем лучше отсканировать и распознать, тем быстрее исправить и получить готовый результат.
Применение в CuneiForm новых технологических достижений
В начале XXI века считалось, что нормально работающей альтернативы ABBYY FineReader не существует. Несмотря на существование различных программ для OCR распознавания текста, ABBYY FineReader прочно оставался в лидерах индустрии сканирования и оцифровки документов. Это продолжалось до тех пор, пока самые продвинутые пользователи не попробовали для полноценного распознавания сфотографированного или сканированного текста скачать OCR CuneiForm 12 бесплатно без регистрации и SMS и протестировать потенциал этой по-настоящему бесплатной проги для Виндовс. При этом оказалось, что возможности OCR CuneiForm не уступают ABBYY FineReader ни в чем.
OCR CuneiForm умеет мгновенно идентифицировать все стандартные символы всевозможных начертаний и шрифтового исполнения. Распознаванию поддаются книги, журналы, листовки, газетки, принт-листы, факсовые рассылки, неудачные ксероксные копии, тексты с древних пишущих машинок и прочее, исключая декоративный шрифт и рукопись. В программном коде CuneiForm применяется ряд уникальных инновационных технологий Optical Character Recognition, таких как: адаптивное распознавание с применением шрифтонезависимых инструкций, нейронно-аналитические сети нормализации, когнитивная аналитика альтернативных вариантов трактовки текста, спецалгоритмы для матричного принтера, некачественных результатов ксерокопирования, факсов и машинописных страниц и прочие. При необходимости использовать все это для дела всегда можно бесплатно скачать CuneiForm для Windows 10, 8.. CuneiForm способен воссоздать абсолютную копию исходника. Сохраняется форматирование и структурирование, отступы, колонтитулы, сноски, индексы, количество и размеры колонок, абзацы, расположение отдельных фрагментов текста, табличных элементов и иллюстраций, стили шрифтов и другие элементы шрифтового оформления.
Интерфейс, языки, словари и функционал ОСР КьюниФорм
OCR CuneiForm отлично узнает и оцифровывает документацию, удобна в работе и не создает проблем начинающим пользователям, поскольку обладает удобным русскоязычным интерфейсом, имеет встроенные советы и всплывающие подсказки. Для закачки и подключения доступны популярные графические интерфейсы для КьюниФорм: YAGF, OCR Feeder, CF-Qt, Puma и прочие. Стандартный графический интерфейс имеет все инструменты, необходимые для полноценного распознания сканированного или сфотографированного текста. Мультиязычный интерфейс на родном языке способствует ускорению понимания оператором принципов работы и расширению спектра используемых возможностей. В настройках доступно конфигурирование под распознавание символов на русском, инглише, русско-английском и еще 20-ти европейских языковых раскладках. Качество мгновенного распознавания повышается при использовании словарей, которые можно расширять, импортируя слова из словарных файлов.
Основные функциональные преимущества программы OCR CuneiForm:
- достойное OCR распознавание и скорость работы,
- автоподбор оптимальных настроек сканирования,
- импорт отсканированных, сфотографированных или принятых иным путем картинок,
- поворот, переворот, инверсия, очистка и прочее редактирование изображений,
- несколько вариантов идентификации абзацев текста, таблиц и картинок,
- в работу идет любой материал, исключая декор и рукопись,
- словарная поддержка для улучшения качества,
- сравнительная демонстрация исходников и символьных результатов,
- OCR-совместимость со свыше двадцати языками, включая русский.
Бесплатность, множество преимуществ, скорость и отсутствие проблем в работе являются весомыми аргументами, чтобы скачать CuneiForm бесплатно на сайте сайт русскую версию. Использование высокотехнологичного гарантирует высококачественные скан и распознавание документации с бумажных носителей или растровых файлов в форматы, подходящие для редактирования в соответствующих редакторах.
Немного исторических фактов
Cognitive Technologies образовалась в 1993 г. на основе главного центра ИИ ИСА Российской Академии Наук. Как итог научно-практических исследований появилась первая CuneiForm. В конце 1993 года был подписан OEM-контракт с Corel Corporation, по которому код КьюниФорм вошел в пакет Corel Draw. В дальнейшем после многих лет перерыва компания освободила проект, перестав продавать и поддерживать программу, но программа КьюниФорм настолько хороша, что сегодня отсканировать и распознать русский текст лучше и дешевле всего получится, если бесплатно скачать OCR CuneiForm русскую версию на свой компьютер.
Вскоре этот программный продукт оказался одним из наиболее востребованных средств оптического распознавания текстов и заслужил позитивные отзывы и комментарии пользователей на официальном сайте cognitiveforms в домене com, тематических сайтах и форумах, а также в социальных сетях. Сегодня CuneiForm выделяется из массы прочего Optical Character Recognition программного обеспечения достойным распознаванием некачественной документации. Среди достоинств КуниФорма отмечены качественный перевод в цифровой вид бумажной документации и растровых файлов с экспортом в мультиформатный текст и таблицы Microsoft Office Word и Excel или их аналоги.
Ошибка во взаимодействии со сканерами
Сканирование на HP, Epson, Mustek, Canon и некоторых других черевато ошибкой. Причина данной проблемы обусловлена нюансами взаимодействия TWAIN-интерфейса с оборудованием. Лечится проблема простым редактированием строки с содержимым TWAIN_TransferMode в файле C:\Windows\face.ini до состояния: TWAIN_TransferMode=memory-native и перезапуском программы. Как правило, сегодня таких проблем не наблюдается, и чтобы получить из бумажного документа редактируемую электронную версию, нужно просто бесплатно скачать CuneiForm на русском языке с этой страницы сайта сайт без регистрации и СМС и использовать ее по прямому назначению. Это сбережет время и освободит от ручного набирания текста в Microsoft Word и таблиц в Microsoft Excel или аналогах этого ПО.
Последнюю версию CuneiForm 12 скачать бесплатно на русском языке
Бесплатные программы скачать бесплатно
Сейчас Вы находитесь на странице с названием "OCR КьюниФорм для полноценного распознавания сфотографированного или сканированного текста" сайта , где каждый имеет возможность легально скачать программы для компьютера с Microsoft Windows. Эта страница создана/существенно обновлена 10.09.2015. Спасибо, что посетили раздел .
Бумага как основной носитель информации, постепенно утрачивает свое значение. Вместо бумажных документов используют их электронный вариант, если это возможно. Но как перевести в электронный вид имеющиеся архивы? Для решения этой задачи были созданы специальные программы для распознавания текста.
Что такое OCR-программы и как они работают
Эти программные продукты, использующие технологию ORC (Optical character recognition) или ICR (Intelligence character recognition). На русский язык эти аббревиатуры переводятся как «оптическое» или «интеллектуальное распознавание символов».
Программы, использующие OCR, работают следующим образом. Фотография с текстом, полученная от сканера, разбивается на множество фрагментов. Для каждого из них приложение создает несколько предположений. Проверяя их и сравнивая с эталонами, каждому фрагменту дает оценку, соответствующую степени совпадения. Выбирая наибольшую из них, программа «видит» символ и выводит его в поле встроенного текстового редактора.
IRC работает по тому же принципу, но для используются искусственные нейронные сети. Главное преимущество этого способа - компактность программ и непрерывное обучение. Это позволяет эффективно распознавать слова, написанные человеком рукописными буквами. Но эта технология не способна «прочесть» сплошной рукописный текст.
Для каждой из существующих операционных систем разработаны собственные OCR-программы. Наиболее популярными для работы в ОС Windows являются:
- ABBYY FineReader;
- OmniPage;
- Readiris;
- Samsung Scan OCR Program;
Кроме программ для ПК доступно много онлайн-сервисов по распознаванию текста. Среди них наиболее известны FineReader Online, OnlineOCR, FreeOCR.
ABBYY FineReader 14

Этот программный продукт разработан отечественной компанией ABBYY, является одной из лучших среди программ, использующих OCR. Основу программы составляет оригинальный движок под названием Finereader Engine. Он предоставляет следующие возможности:
- Быстрое распознавание печатного текста с точностью выше 98 %. Невосприимчивость к качеству исходного изображения. Это позволяет одинаково на фотографиях, полученных при помощи сканера или фотоаппарата.
- Технология ADRT позволяет распознавать не только текст, но и его форматирование: шрифт, отступы, абзацы, колонки.
- Возможность многопоточной Это позволяет задействовать все ядра процессора (максимум 4) для ускорения процесса распознавания.
- Поддержка более 190 языков, включая те, которые используют алфавит, отличный от латиницы или кириллицы (японский, китайский, арабский).
- Встроенный текстовый редактор позволяет проверить результат распознавания или отредактировать его.
- Взаимодействие с пакетом Office. Оно позволяет экспортировать распознанный текст в Microsoft Word и Exel для дальнейшей обработки.
- Возможность обучения программы. Эта функция позволяет обучить программу «читать» специфические начертания букв. Например, нестандартный шрифт или печатные буквы, написанные рукой.
- Работа с PDF. FineReader позволяет распознавать текст из этого типа файлов и «сшивать» несколько отсканированных изображений в PDF или PDF/A.

Главный недостаток этой программы - цена. Бессрочная лицензия для базовой версии обойдется в 7 тысяч рублей. Версии "Бизнес" и "Энтерпрайз" - в 12 и 39 тысяч рублей, соответственно. Если же предполагается использовать программу только дома, то можно скачать с торрент-трекера взломанную 11-ю или 12-ю версию продукта.
Системные требования:
- Процессор: 32- или 64-битный, с тактовой частотой более 1 ГГц и поддержкой набора инструкций SSE 2. (Intel Celeron M и лучше, AMD Athlon 64 и лучше).
- Оперативная память: 1 ГБ. Если процессор имеет более 1 ядра, то для каждого дополнительно требуется 512 МБ.
- Жесткий диск: 3 ГБ - для установки и работы.
- Сканер: поддерживающий драйверы TWAIN и WIA.
- ОС: Windows 7,8,8.1,10.
Мнение пользователей о FineReader 14
Они отзываются о FineReader положительно, выделяя среди достоинств способность продукта распознавать текст с плохих бумажных оригиналов, удобный и простой интерфейс и высокую скорость обработки изображений.
Среди проблем, возникающих при использовании этой OCR-программы, некоторые юзеры отмечают некорректно работающий менеджер изображений. Например: неадекватная работа регулировки яркости отсканированного изображения.
OmniPage 18

Основной конкурент FineReader на российском рынке ORC-программ. По функционалу она очень похожа на оппонента, но имеет несколько отличий:
- Возможность запуска процесса сканирования и распознавания при помощи кнопок сканера.
- Поддержка 4-ядерных процессоров. Это позволяет уменьшить время распознавания и преобразовывать несколько изображений одновременно.
- Создание собственной электронной библиотеки для букридера (электронной книги) Kindle.
- Автоматическое определение распознаваемого языка.

Среди недостатков программы можно отметить низкую скорость работы, сравнимую с 10-й версией FineReader, и цену за лицензионную копию - 150 долларов.
Системные требования:
- Процессор: x32- или x64-битный, с тактовой частотой более 1 ГГц, Intel Pentium и лучше, AMD Athlon и лучше.
- Оперативная память: 512 МБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800 и глубину цвета 16 бит.
- Жесткий диск: 1,1 ГБ для установки всех компонентов и 100 МБ для работы.
- Сканер: поддерживающий драйверы TWAIN,WIA и ISIS.
- ОС: Windows XP SP3,Vista SP2 x32/x64, 7,8.
Мнение пользователей об OmniPage
Отзываются они о ней резко негативно, т.к. проблемы есть во всех частях программы, начиная от красивого, но непонятного интерфейса, и заканчивая плохой справочной информацией. Продукт не адаптирован к работе в WinXP. Его можно заставить работать, но придется потратить какое-то время.
OmniPage имеет проблемы с распознаванием. Например: он легко распознает простой черный текст на листе бумаги с рисунками или таблицами, полученный со сканера. При использовании изображений с фотоаппарата или мобильного телефона точность распознавания падает до 70 %, а это очень неудобно при обработке больших документов.
Также 18-я версия может не запуститься из-за ошибок в коде. Для устранения этой проблемы нужно установить патч 18.01.
Read Iris Pro 17

Read Iris - это OCR-программа, что за меньшие деньги (8000 против 12 000) способна сравниться по функционалу и производительности с FineReader. Профессиональная версия обладает следующими возможностями:
- Полноценная работа с PDF: распознавание, создание файлов для баз данных, сжатие и озвучивание текста.
- Поддержка 140 языков.
- Распознавание бумажных таблиц и текстов с возможностью экспорта в Exel и Word.
- Получение изображений с любой модели сканера.

Также существует корпоративная версия, позволяющая защищать PDF-файлы водяными знаками и работать с документами объемом более 50 страниц.
Системные требования:
- Процессор: x86 или x64, с тактовой частотой 1 ГГц или выше.
- Оперативная память: 1 ГБ.
- Видеокарта: любая, поддерживающая разрешение 1024 х 800.
- Жесткий диск:400 МБ для установки.
- Сканер: поддерживающий драйверы TWAIN,WIA.
- ОС: Windows 7,8,10 x32/x64.
Мнение пользователей о ReadIris
Они отзываются об этой OCR-программе распознавания текста как о хорошем и быстром PDF to Word конвертере с рядом проблем:
- Сложный интерфейс, в котором новичку нелегко разобраться.
- Автоматическое пересканирование документа при изменении области сканирования.
- Плохая техническая поддержка.
- Иногда программа не активируется из-за ошибок в коде программы.
Samsung Scan OCR Program - что это за программа?
Это бесплатное программное обеспечение, входящее в комплектацию многофункциональных устройств «3 в 1» (принтер, сканер, копир) от компании "Самсунг". Оно разработано в сотрудничестве с компанией Iris, создавшей ReadIris Pro, и оптимизировано для работы с МФУ этого производителя. От оригинального "Ридирис" Samsung Scan ORC отличается интерфейсом, урезанным функционалом и размерами - на жестком диске она занимает 40 МБ.
Онлайн-сервисы
Они являются альтернативой ресурсоемким стационарным программам для распознавания текста. Например, OCR программе FineReader. Свойства систем подобных проектов позволяют распознавать текст с изображений намного быстрее, чем на автономном ПК. Среди сервисов, занимающихся извлечением текста из фотографий, можно выделить 3 наиболее удобных: FineReaderOnline, FreeOCR, OnlineOCR.

Первый является прямым развитием стационарной версии продукта. При регистрации новому пользователю дается 10 бесплатных страниц для обработки и 5 каждый месяц. Снять это ограничение можно, купив годовую подписку за 3200, 5500, 17800 рублей за 2000, 5000 и 10000 страниц соответственно. Если у пользователя есть лицензия для FineReader 14, то ему достаточно зарегистрироваться и активировать ее для использования в онлайн-версии. В этом случае он получит количество страниц, соответствующее типу приобретенной лицензии: "Стандарт" (2000), "Бизнес" (5000) или "Энтерпрайз" (10000).

Сервис OnlineOCR.com позволяет преобразовывать 15 изображений/час (ограничение для незарегистрированных пользователей) в текст и сохранять их в виде файлов.docx, .xlsx или.txt. После регистрации становится доступным:
- Сохранение в.pdf, .doc, .xlx, .rtf.
- Преобразование многостраничных PDF-файлов.
- Количество страниц увеличивается до 50.

Если страниц недостаточно, то их можно приобрести в количестве 50-50 000 штук.

Проект FreeOCR.com отличается от предыдущего своей полной бесплатностью и отсутствием ограничений на количество обрабатываемых страниц. OCR-движок этого сайта поддерживает русский, украинский, турецкий, вьетнамский и все европейские языки - всего 29. Единственным недостатком этого портала является работа только с графическими изображениями, загружаемых последовательно, так как очередь обработки не предусмотрена создателями. Выводится распознанная информация без какого-либо форматирования в формате TXT.
Мнение пользователей об онлайн-OCR-сервисах
Эти сайты необходимы в тех случаях, когда загрузка и установка полноценной ORC-программы нецелесообразна. Например, для вставки в реферат нескольких объемных цитат из книги или журнала. Среди недостатков таких сайтов выделяют условную бесплатность (FineReader) и слабый функционал (FreeOCR,OnlineOCR).
Подводя итог, можно сказать, что OCR-программ распознавания текста с изображением или PDF-файлов создано немало, а в статье приведены лишь самые известные. Поэтому OCR-программу для сканера каждый пользователь сможет себе подобрать в соответствии с требованиями и бюджетом. Либо воспользоваться одним из множества бесплатных OCR-сервисов.
Как только человек изобрел компьютер, он стал переносить в него свои знания. Поскольку главным носителем знаний до появления компьютерной техники были книги, возникла задача - каким образом накопленную информацию можно быстро перевести в "цифру"? Глупо было бы использовать для этого самый простой и очевидный способ перевода книг в цифровой формат - набор вручную. Человечество тысячелетиями накапливало различные тексты, поэтому процесс их повторного "написания" занял бы невероятно много времени. Для решения этой задачи необходимо было найти какой-то простой и эффективный способ автоматизации процесса повторного набора текста. Так возникли различные технологии оптического распознавания текста или сокращенно OCR (optical character recognition). В наши дни с процедурой перевода машинописного листа в текстовый документ знаком каждый студент и школьник. Печатный текст сканируется (или фотографируется), затем с помощью специального программного обеспечения компьютер анализирует снимок текста, выделяет на изображении отдельные элементы и создает новый документ, в который заносит все распознанные буквы и символы. Такой документ, как правило, является редактируемым, благодаря чему можно исправлять ошибки машинного распознавания и работать с ним как с набранным текстом. В зависимости от сложности исходного текста и качества отсканированного изображения, процесс обработки документа OCR-приложением занимает больше или меньше времени. К счастью, сегодня процедура перевода набранного текста в формат электронного документа занимает намного меньше времени, чем несколько лет назад - аппаратные возможности компьютеров за последние десять лет заметно увеличились, а благодаря постоянным усовершенствованиям алгоритмов анализа изображения процент ошибок стал намного меньше. Более того, теперь распознавание текста можно доверить даже онлайновым сервисам, преимущества которых перед обычными настольными приложениями очевидны - не нужно раскошеливаться на дорогостоящее ПО и тратить время на установку приложения. Наконец, используя для распознавания онлайновые средства, можно получить редактируемый текст из снимка даже на таких компьютерах, где просто нет возможности устанавливать программы, например, на публичном ПК в библиотеке.
⇡ FineReader Online
Начнем с онлайнового сервиса компании ABBYY. Нет ничего удивительного в том, что она использует в качестве системы для распознавания текста популярную программу FineReader. В рекламе этот продукт не нуждается - сегодня это приложение можно считать одним из лучших вариантов OCR.
Причин успешного продвижения этой программы очень много. Прежде всего, это отшлифованный алгоритм идентификации печатных символов. Движок самой популярной системы оптического распознавания текста, FineReader, совершенствовался годами, механизм анализа изображения улучшался от версии к версии. В программу вносились различные изменения и улучшения, которые уменьшали количество нераспознанных или некорректно определенных символов при обработке сканированного изображения. FineReader включает в себя множество средств и вспомогательных инструментов, которые дают возможность выполнить тонкую настройку программы, улучшить качество исходного изображения, определить тип распознаваемых символов, установить области для обработки и т.д. Онлайновый сервис является бесплатным проектом, который дает возможность пользователям оценить точность работы FineReader. Одно из его главных достоинств - поддержка большого количества определяемых языков (всего доступно 37 языков). Для того чтобы воспользоваться сервисом, необходимо пройти регистрацию. Поскольку этот проект носит отчасти рекламный характер, возможности распознавания текста в нем существенно ограничены. Во-первых, анализ изображения происходит в полностью автоматическом режиме. Пользователь может лишь указать язык распознавания и включить опцию, которая позволит получить ссылку на результат распознавания на введенный адрес электронной почты. Во-вторых, объем файла, загружаемого на сервер, не должен превышать 10 мегабайт. Но самое неприятное ограничение - небольшое количество документов, которое можно распознать. Зайдя под одной учетной записью, можно обработать не более десяти файлов. Однако и это, согласитесь, неплохо. FineReader Online может также обрабатывать тексты, содержащие любые комбинации поддерживаемых языков. При этом сервис не позволяет выбирать более трех языков распознавания для одного документа. Разработчики мотивируют это тем, что подобная функция существенно замедлила бы процесс распознавания текста. Готовый результат распознавания текста может быть сохранен в один из форматов - MS Word (.doc), MS Excel (.xls), PDF, PDF/A, RTF и TXT. В принципе, сервис справляется с поставленной задачей и определяет текст. Однако, справедливости ради, следует сказать, что даже очень хорошее качество исходного изображения не дает стопроцентной гарантии распознавания. Даже такое "идеальное" изображение, как скриншот всплывающей подсказки на странице сервиса, FineReader Online распознал с ошибками.
⇡ ocrNow!
ocrNow! - британский сервис, который также использует в качестве системы для распознавания текста FineReader. Уже на этапе регистрации можно выбрать формат, в котором по умолчанию будут сохранены данные - RTF, PDF, XLS, XLM, TXT или Web Archive. Изменить формат можно при загрузке каждого нового файла. Кроме этого, есть возможность получить текст по почте. Стоит отметить, что результаты могут быть запакованы в ZIP-архив, благодаря чему время на загрузку полученного файла сократится. Сервис поддерживает загрузку изображений в форматах TIF, PNG и JPG (JPEG), а также PDF. Кроме этого, можно загрузить ZIP-архивы, содержащие файлы поддерживаемых типов, и они будут распакованы и обработаны автоматически. ZIP-архив удобен не только тем, что позволяет уменьшить размер файлов, которые необходимо загрузить на сервер, но и тем, что благодаря ему можно загрузить несколько файлов за один раз.OcrNow! работает с шестнадцатью языками, в том числе с документами на русском английском, французском, чешском, испанском, итальянском. Выбор языка осуществляется при загрузке файла. Даже если не указать язык, сервис попытается определить его автоматически, правда, не исключено, что он ошибется, поэтому лучше все же выбрать язык вручную. Стоит заметить, что выбрать можно лишь один язык. Каждому зарегистрированному пользователю предоставляется два бесплатных кредита, которые можно использовать для распознавания двух страниц формата A4. Если необходимо работать с бо льшим количеством данных, необходимо купить кредиты. Их стоимость зависит от того, сколько кредитов вы решите приобрести за один раз. Например, если купить 20 кредитов, то распознавание одного листа A4 обойдется в 0,1 фунта стерлингов (около 4,6 рубля), а если приобрести сразу 500, то стоимость распознавания одного листа снизится примерно до 2,96 рубля. Создатели сервиса предлагают специальную утилиту , позволяющую использовать его совместно с Apple iPhone. При помощи этой программы можно фотографировать документы, а затем отсылать их на сервис и получать результаты. Бесплатная версия этой программы дает возможность обработать десять фотографий, а коммерческий вариант, снимающий это ограничение, обойдется в 14 долл.
Пользователям, которые часто обращаются к услугам сервиса со своего настольного компьютера, предлагается скачать утилиту Unimessage Solo, предназначенную для сканирования файлов. Особенность этой программы в том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого, созданные с ее помощью файлы можно загрузить на Facebook.
⇡ OnlineOCR.ru
Данный сервис является коммерческим. Для работы с ним необходимо приобретать кредиты, каждый кредит - возможность распознавания одной страницы документа. Однако даже в демонстрационном режиме с его помощью можно переводить небольшие фрагменты текста. Сервис предлагает очень удобную загрузку файлов - на сервер можно загружать одновременно несколько изображений, упаковав их в ZIP-архив. Максимальный размер файла - 20 мегабайт, но можно использовать и файлы большего размера, однако для получения такой возможности необходимо связаться с администрацией сервиса. В качестве исходного формата графического файла можно использовать TIFF (поддерживаются в том числе и многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF.Если с помощью данного сервиса распознается многостраничный документ, например, PDF, можно указать только отдельные страницы для распознавания. Для этого в настройках распознавания необходимо установить флажок напротив "Многостраничный документ" и в поле для диапазона страниц указать необходимые страницы через запятую (или диапазон страниц через дефис). Если указать, скажем "4,13", сервис распознает только четвертую и тринадцатую страницы. В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь текст, а только его часть. Всего сервис поддерживает 28 языков, включая русский, английский, белорусский, венгерский, голландский, греческий, датский, испанский, латвийский, латинский, немецкий, польский, шведский, финский, французский, украинский и др. Сервис позволяет хранить файлы с результатом распознавания в виртуальном рабочем кабинете online, редактировать, отправлять их по почте и выводить на печать.
⇡ NewOCR.com
Проект NewOCR.com не требует ни регистрации, ни дополнительных денежных трат со стороны пользователя. Сервис имеет минималистический интерфейс, и его настройки сводятся к выбору языка. Если загруженное изображение имеет неправильную ориентацию, например, повернуто в процессе сканирования на 90 градусов, в выпадающем меню сервиса можно установить угол поворота картинки. Качество обработки графического файла оставляет желать лучшего - конечный документ содержит многочисленные ошибки распознавания, поэтому вряд ли стоит использовать этот сервис для обработки большого числа страниц. Этот недостаток несколько смягчает то обстоятельство, что проект поддерживает работу с 29 языками (включая русский).Распознавать можно изображения в форматах JPEG, PNG, GIF, BMP, а также многостраничные файлы TIFF. Размер файлов не должен превышать пять мегабайт, а для многостраничных PDF-документов лимит составляет 20 мегабайт. После обработки отсканированного изображения сервис продемонстрирует результат в отдельном поле, рядом с копией загруженного изображения. Распознанный текст можно экспортировать в формат.doc или.txt.
⇡ Free-OCR.com
Этот сервис можно использовать бесплатно, причем регистрация не требуется. Для защиты от спама используется контрольное изображение (Captcha). Однако, выбрав этот сервис для обработки своих файлов, следует учитывать ограничения, которые касаются обрабатываемых изображений. Так, размер загружаемых на сервер файлов ограничен двумя мегабайтами. Еще одно ограничение сервиса, которое касается загружаемых файлов, - разрешение каждого из графических изображений не должно превышать 5000 точек по ширине. Кроме этого, Free-OCR.com устанавливает лимит на количество обработанных документов. В час можно загрузить не более десяти изображений.На данный момент сервис не умеет распознавать многостраничные документы PDF или TIFF, поэтому при обработке таких файлов распознается только первая страница. Сервис позволяет обрабатывать страницы с многочисленными столбцами текста. В настройках Free-OCR.com нельзя выбрать более одного языка, поэтому, если попробовать распознать, например, русский текст с английскими терминами, ошибок будет предостаточно. Общее количество поддерживаемых языков, которые можно выбирать для распознавания, довольно много - двадцать девять, в том числе и русский. Качество распознавания документов удовлетворительное.
⇡ Заключение
Далеко не все услуги онлайновых сервисов для распознавания текста предоставляются бесплатно. Однако цена, которую просят их создатели, заметно ниже стоимости специализированного ПО. Естественно, если вам необходимо распознавать десятки документов ежедневно, то платить создателям онлайнового сервиса для вас вряд ли будет выгодно - гораздо дешевле будет один раз заплатить за лицензию программы. Но если вы пользуетесь подобными средствами лишь время от времени, то проще заплатить за распознавание необходимого числа страниц или попытаться обойтись полностью бесплатными сервисами.Foxit’s Maestro Server OCR converts paper and scanned documents into searchable PDF files. Engineered for automated, high-volume document scanning & OCR needs, Maestro replaces manual document processes with fast, cost-efficient operations.
Maestro automates the OCR process by converting any document as it enters a watched folder according to configurable settings chosen by the user. Beyond OCR automation, Maestro incorporates unlimited multi-threading and batch OCR to accommodate high-volume scanning, up to billions of pages per year to make Maestro a robust enterprise OCR software solution.
Maestro is designed for high OCR accuracy, speed, and simplicity. The software delivers highly accurate text recognition rates by utilizing in-house PDF expertise as well as a proprietary voting OCR engine. Further, Maestro can process up to 6,000 pages per hour per core (on average) to handle the highest volume environments while accelerating business processes and improving labor productivity. It is a flexible OCR solution which integrates easily into existing document imaging workflows while providing multiple workflow accessibility, allowing users to perform many image processing functions beyond OCR.
Server OCR Use Cases
Convert Scanned Documents to Searchable PDF
Generate searchable PDF assets from paper and image documents from a scanner, fax, or MFP that can be utilized more effectively in your systems and workflows.
Enable Insights and Automation
Maestro provides high OCR accuracy to reduce errors and automatically create great data to feed into your RPA, document indexing, and big data analytics systems.
Improve Employee Productivity with Faster Information Search
Replace costly, manual information hunting with simple, instant keyword search using Optical Character Recognition software.
Enable Compliance with Regulatory Submission Requirements
Regulated environments often require full text-searchable PDF submission, such as when applying for NDAs to the FDA in the life sciences space.
Create More Accessible Documents
Screen readers and other assistive technologies require text layer data to function properly. Create more accessible documents with automated OCR.
Optimize Document Archiving and Mitigate Legal Exposure
Comply with records retention requirements by converting TIFFs, JPGs, BMPs, and paper to digital, ISO-certified PDF/A documents.
Maestro Server OCR Software Features
OCR Software for Highly Efficient Document Scanning, Storage and Retrieval
Enterprises, government agencies, and growing organizations utilize Maestro Server OCR to reliably and efficiently convert their scanned paper and image documents to text searchable PDF files. Maestro combines image pre-processing and a proprietary voting OCR engine to deliver high text recognition accuracy out of the box, substantially reducing errors compared to manual document processing from human error.
In addition, the OCR software utilizes automation and multiple high-volume processing capabilities to streamline document scanning, storage, and archiving workflows even at an enterprise scale. Faster OCR pushes documents through business processes faster, facilitating shorter response times to customers, better CSAT, and places your organization in a better position to generate new revenue as a result.
OCR Accuracy, Reliability in Maestro Server OCR
Highly accurate OCR can replace hours spent manually searching for critical information with a simple, instant keyword search. The OCR engine within Maestro is one of the most accurate OCR products available. Maestro"s OCR recognizes difficult text often missed by competing products, including text within low resolution captured documents, documents containing multi-directional text, and documents containing low-contrast color text.
More accurate OCR results translate into greater efficiency in indexing, searching for, and working with scanned documents. It also enables more accurate data extraction, data mining for big data applications, and more efficient employees. With Maestro, users are able to instantly locate a single word within a multi-page document that may contain 1 or 1,000 pages; this is analogous to finding the needle in a haystack.
Image Processing
Maestro Server OCR also offers advanced image processing capabilities. With Maestro, images can be de-skewed & de-speckled for enhanced document quality. Maestro also supports IP features including auto-rotation, auto color inversion, auto-cropping, and color re-sampling. Maestro"s robust image processing functionality provides enhanced image quality prior to processing with highly accurate OCR.
Advanced PDF Control
Maestro Server OCR provides superior PDF control including: PDF linearization, advanced security, PDF/A compliance, metadata insertion, PDF display control, Bates stamping, and headers & footers. Maestro can output a linearized PDF for fast web view, allowing users to view a specified page within the PDF immediately while the rest of the document loads in the background. Maestro also provides advanced security functionality, including options for edit-protection, print-protection, and read-protection. With Maestro, users can reliably archive their documents with PDF/A compliance.
OCR Software Feature Summary
Intel Pentium Processor or compatible 2.0 GHz and higher
Cores
At least 2 cores is recommended
RAM
1GB RAM per core (At least 2GB per core is recommended)
OS
Windows 10 / 8.1 / 8 / 7 / 2012 / 2008
Linux Users
Run Windows emulation using VirtualBox 3 or later (VirtualBox is freeware)
Mac Users
The following are two methods in which you can run Foxit software on a Mac:
- Mac OS X running on an emulation (VM Fusion 2.0) of Windows
- Mac running on a Windows Operating System (directly or using Bootcamp)