Если вы хотели узнать, как передаются данные в интернете - эта статья для вас. Я расскажу вам все что знаю о протоколах HTTP и HTTPS, покажу разницу и отличия между ними. Приятного чтения!
HTTP 1.1 - что это за протокол?
HTTP (англ. «протокол передачи гипертекста») - сетевой протокол верхнего уровня для передачи гипертекстовых и произвольных данных в интернете.
При помощи HTTP браузер получает данные от веб-серверов и может отображать их в приемлемом и понятном для интернет-пользователей виде. Точно также происходит и обратный процесс - отправку пользовательских данных обратно, на сервер (например, при регистрации).
Контент отправляемый с сервера и на сервер может быть представлен в любом виде: рисунков, файлов, документов, ссылок и кода - в любом случае, именно благодаря HTTP люди могут пользоваться интернетом и загружать в браузере сотни веб-страниц.
Актуальная версия протокола - 1.1. Ее описание находится в спецификации RFC.
HTTP используется в клиент-серверной инфраструктуре передачи данных. Как это работает? Приложение на стороне «клиент» формирует запрос для обработки на стороне «сервер», после чего ответ отправляется обратно «клиенту». Затем «клиент» может инициировать дополнительные запросы, получать новые ответы. И так далее.
Наиболее распространенное «клиентское» приложение это веб-браузер через который осуществляется доступ к веб-ресурсам. С развитием мобильных технологий к браузерам добавились еще мобильные приложения на разнообразных смартфонах и планшетах. Причем серверная сторона современных многопрофильных приложений может одновременно обрабатывать данные и из браузера, и со смартфона. Все это через протокол HTTP.
Более того, HTTP часто выступает как протокол-транспорт для трансфера других прикладных протоколов и их API: WebDAV, XML-RPC, REST, SOAP. Ну а данные передаваемые по API могут иметь самый разный формат: XML, JSON и другие.
Как передаются эти данные? Чаще всего по TCP/IP-соединению: приложение-клиент по умолчанию использует TCP-порт 80, а сервер может использовать любой другой, но обычно это тоже 80 порт.
Объект манипуляций в HTTP это ресурс, указываемый в URI запроса клиентского приложения, чтобы корректно идентифицировать «что вообще нужно». Обычно это файлы, данные или логические объекты, которые хранятся на сервере. При этом в запросе можно указать, как именно представить одни и те же данные: какой выбрать формат, кодировку, язык. Такая «фича» позволяет обмениваться не только гипертекстом, но и двоичными данными.
Второй особенностью HTTP является отсутствие сохранения состояния между последовательными парами «запрос-ответ». Но это не проблема, потому что компоненты приложений на клиентской или серверной стороне само могут хранить информацию о состоянии последних запросов и ответов. На стороне клиента такая информация называется cookies («куки»), на стороне сервера - sessions («сессии»).
При этом для клиентского браузера не проблема следить за задержкой ответа сервера, а для сервера - хранить заголовки последних запросов и IP-адреса клиентов. Но, еще раз подчеркну, сам протокол об этом ничего не знает - он только передает данные.
Принимать участие в передаче данных могут и посредники (прокси-сервера), для того чтобы отличить прокси от конечных серверов (т.н. «исходный сервер»).
Самое волшебство начинается, когда одна и та же программа (клиентская или серверная) может выполнять функции посредник, клиента, сервера - в зависимости от задач.
HTTP/2 - а это что за протокол?
Первоначальная версия протокола HTTP появилась в ЦЕРНЕ (CERN) в 1991 году. Уже в 1992 году была опубликована публичная версия HTTP 0.9 и его спецификация, благодаря чему были упорядочены правила взаимодействия между клиентскими и серверными приложениями, а также четкому разграничению функциональности.
В 1996 году появился HTTP/1.0, а современная версия протокола - HTTP/1.1 - в 1999 году. На рубеже тысячелетий, протокол HTTP научился поддерживать режим постоянного соединения, т.е. оставлять соединение открытым после того как получен ответ на запрос. Это позволило за одно соединение посылать сразу несколько запросов, а не открывать-закрывать сессию каждый раз.
Шло время и по мере развития интернета размер страниц увеличивался, росло количество запросов - требовалось все больше ресурсов. Так сформировалась потребность в новом протоколе.
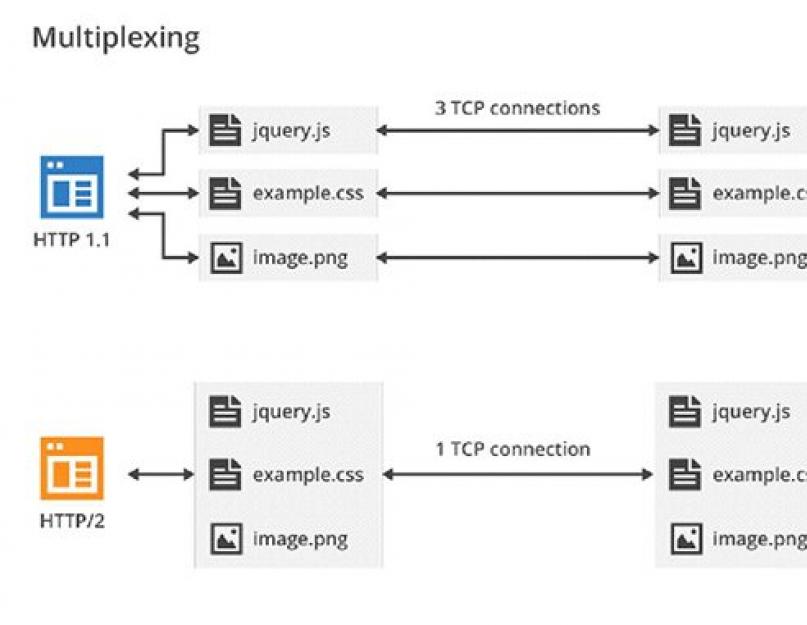
И спустя шестнадцать лет, в 2015 году была опубликована финальная версия черновика спецификации следующей версии протокола - HTTP/2. Бинарный протокол HTTP/2 более подготовлен к современным реалиям, чем прародитель HTTP 1.1 потому что новый протокол решает наиболее существенную проблему передачи данных в интернете - несколько отрытых соединений.
А все потому что нынешние сайты подгружают много элементов, как со своего сервера, так и с CDN: JS-скрипты, CSS-стили, шрифты и картинки. При передаче полного комплекта файлов по протоколу HTTP 1.1 создается несколько соединений. Если мы в будущем перейдем на протокол HTTP/2 - передача будет происходить в рамках одного соединения между клиентом и сервером, что позволит существенно ускорить и оптимизировать загрузку содержимого сайта.
Ключевые особенности HTTP/2, которые будут полезны для сайтов:
- Расстановка и управление приоритетами запросов/потоков - клиент самостоятельно задает для сервера приоритетность ресурсов и данных
- Сжатие HTTP заголовков;
- Мультиплексирование запросов или параллельная загрузка по TCP-соединению нескольких элементов сайта - через одно соединение отправляется несколько запросов, а ответы клиент может получать в любом порядке т.е. теперь не нужны несколько открытых TCP-соединений;
- Наличие и поддержка со стороны сервера проактивных push-уведомлений - сервер самостоятельно может отправлять данные для клиента, которые тот еще не запросил (например на основании информации о том, какую страницу пользователь откроет после этой).
Конечно, главное здесь это мультиплексирование потоков. Принцип работы объяснить проще простого: пакеты TCP/IP-соединения смешиваются в рамках одного соединения. Так, в смешанном режиме происходит соединение нескольких «вагонов данных» в один «состав поезда», которые разделяются «по приезду». Ранее «вагоны» были вынуждены ехать дольше и раздельно, сейчас они будут ехать вместе и быстрее.

Вышеперечисленные преимущества протокола HTTP/2 позволят веб-разработчикам дышать полной грудью и отказаться от таких «костылей» как:
- Использование большего числа родственных доменов для обеспечения установки большого количества TCP/IP-соединений (для скачивания файлов);
- Спрайты картинок - когда изображения объединяются в один файл, чтобы снизить число запросов к веб-серверу (а сам файл «раздувается» ведь в него записано больше изображений);
- Объединение CSS- и JS-файлов, которые тоже делаются для уменьшения запросов.
Последнее очевидное преимущество заключается в том, что с самим сайтом (для включения HTTP/2) ничего дополнительно делать не нужно - все работы проводятся на сервере чуть ли не в «1 клик», а для клиентов shared- и VPS-хостингов вообще пройдут незаметно.
Словом, заживем!
HTTP/2 создан и разработан на основе черновика протокола SPDY/3 (Google) и превзошел его - компания Гугл признала преимущества HTTP/2 более многообещающими и в будущем откажется от поддержки SPDY/2.
Прогнозируемое ускорение ответа сервера по протоколу HTTP/2 составит порядка 30%, - реальные тесты уже показали скорости на 19-23% выше и это не предел.


По результатам тестов компании Айри.рф, только от включения протокола HTTP/2 прирост скорости составляет 13-18% (без оптимизации). Почему это важно?
Несмотря на то, что поддержка сайтом протокола HTTP/2 на данный момент не влияет напрямую на ранжирование сайтов в Гугле и Яндекса, на позиции в выдаче влияет скорость загрузки. И раз протокол показывает более высокую скорость загрузки (что является довольно значительным фактором), косвенно он влияет и на ранжирование.
Прежде всего за счет поведенческих факторов. Ускорение загрузки позволяет пользователям меньше уставать и больше концентрироваться на изучении сайта: просматривать больше страниц и не покидать сайт из-за долгой загрузки (уменьшаются отказы).
Большая часть современных браузеров уже поддерживает HTTP/2 - через них проходит ~70% интернет-трафика:
- Chrome 41-52 и Chrome 46+ в Android;
- Firefox 36-48 и Firefox 41+ в Android;
- Opera 28-34 и Opera 30+ в Android;
- Safari 9 и Safari в iOS 9.1;
- IE 11 в Windows 10 и браузер Edge 12, 13.
Когда произойдет полноценный переход на HTTP/2 пока непонятно - вероятнее всего в самом ближайшем будущем. Главное что от HTTP/1.x никто не собирается поспешно отказываться. Как говорится: «Работает - не трогай».
Что значит и где применяется HTTPS-протокол?
Ну, про обмен данными по протоколу HTTP вы уже все знаете: любая передача данных осуществляется через запросы по этому протоколу-транспорту. А зачем тогда нужен HTTPS и что он из себя представляет? Ведь жили же нормально и без него?
Проблема в том что данные по HTTP не защищаются и передаются в открытом виде. Интернет - глобальная распределенная сеть узлов. И если вы передаете открытые данные по незащищенному протоколу (Wi-Fi в ТРЦ сюда тоже относится), то один из этих узлов может перехватить их.

Не специально конечно, может быть просто взлом усилиями злоумышленников. HTTPS и создан для того чтобы соединение было безопасным, а данные передавались в зашифрованном виде по криптографическому протоколу SSL/TLS. Это специальная «обертка» поверх HTTP, она шифрует данные, делая их недоступными для злоумышленников и посторонних людей.
HTTPS - англ. «безопасный протокол передачи гипертекста».
Так что в отличие от 80 порта, используемого по умолчанию в HTTP, в HTTPS используется TCP-порт 443 и есть ключ для шифрования. Ключ может быть длиной 40, 56, 128 или 256 бит, достаточный уровень безопасности на данный момент начинается со 128-битных ключей.
Сейчас все браузеры поддерживают HTTPS - он включается автоматически, когда есть возможность и этого требует сервер.
Жизненно важно использовать HTTPS в следующих сервисах:
- Электронные платежные системы (банки, электронные деньги и прочее);
- Сервисы принимающие и отправляющие приватную информацию и персональные данные, например у Яндекса это: Паспорт, Такси, Директ , Метрика, Почта, Деньги , Вебмастер и другие;
- Социальные сети и личные кабинеты в интернет-сервисах;
- Поисковые системы.
Работает HTTPS просто. Объясню на примере.
Вы кладете важную информацию (логин, пароль, данные карты, персональные данные) в ячейку, «запираете ее на ключ»: ячейка шифрует ваши данные при помощи этого ключа.
Теперь отправляете ее почтой адресату. Адресат получает ячейку-посылку, но открыть ее не может - у него нет ключа. Тогда он запирает (шифрует) ячейку на второй замок и возвращает посылку вам обратно. Вы получаете посылку с двумя замками, при этом ключ к одному у вас есть. Теперь можно отпереть свой замок (расшифровать данные) и отправить посылку обратно еще раз - первоначальному адресату.
Данные при этом остаются защищенными - ведь они никем не просматривались и не менялись и до момента получения адресатом находятся под защитой зашифрованного им ключа. Адресат получает посылку, уже с одним замком, расшифровывает ее и обрабатывает ваши данные. Например, проводит вашу транзакцию.

Все - вот так просто работает HTTPS.
Фишка тут в том, что при первом таком обмене происходит обмен ключом шифрования, чтобы он был известен обоим конечным адресатам, но не известен ни одному из узлов по маршруту следования данных. После обмена шифром можно свободно обмениваться сообщениями (зашифрованными) без опасений о перехвате этих данных, ведь без ключа-шифра открыть и прочитать их не удастся.
Единственный нюанс здесь - надо знать, что вы отправляете данные именно туда, куда нужно. И что конечный пункт и является пунктом назначения. Но нужно подтвердить и точно знать, что конечный адресат существует и управляется тем самым сервером, куда отправляются данные.
Для этого серверы получают в центрах сертификации специальные HTTPS-сертификаты безопасности, которые подтверждают «конечность» пункта назначения (что сайт не является узлом передающим данные дальше) и работоспособность технологии шифрования SSL/TLS, т.е. безопасность соединения.

А вот как выглядит сам сертификат:

На текущий момент HTTPS встроен во все современные браузеры и все что требуется от пользователя для поддержания безопасности отправки данных по HTTPS - регулярно обновлять программное обеспечение для серфинга, приема и отправки важных данных в интернете.
Осуществляя взаимодействие «клиент-сервер» по протоколу HTTPS можно не беспокоиться за сохранность данных - вы надежно защищены от прослушивания сетевого соединения: атак снифферов и man-in-the-middle.
Что означает перечеркнутый значок HTTPS и зеленый значок HTTPS, в чем разница? В безопасности. Зеленый - безопасный, красный и перечеркнутый - небезопасный.



И очень удобно, что перечеркнутый значок HTTPS означает, что несмотря на использование этого протокола, соединение не безопасное. Так происходит когда элементы сайта подгружаются не по HTTPS или истек срок действия сертификата. Пользователю сразу видно - ага, небезопасно. И он может уйти с сайта, либо рисковать своими данными.

Что лучше HTTP 1.1, HTTP/2 или HTTPS?
В качестве подведения итога затрону тему предпочтительного использования протоколов.
Понятно, что на данный момент HTTP 1.1 - наиболее распространенный протокол и используется по умолчанию. Время HTTP/2 еще не пришло, но вскоре большая часть интернет-трафика будет идти через вторую версию протокола HTTP. Это упростит жизнь пользователям, потому что сайты будут загружаться быстрее. Администраторы серверов и сайтов тоже будут рады, потому что новый протоко позволяет по новому оптимизировать сайты, ускоряя загрузку и отдачу данных.
При этом, вряд ли возможно, что все сайты перейдут HTTPS, потому что для целей потребления развлекательного контента шифрование ни к чему. Да, сейчас уже 10% сайтов используют HTTPS в рейтинге наиболее посещаемых веб-ресурсов «Alexa». Но это всего десять процентов, среди которых такие гиганты как Гугл, ПейПал, Амазон, Алиэкспресс и другие. То есть множество сайтов, где не использовать HTTPS означает нарушать право интернет-пользователя на безопасность и сохранность данных.
А обычным сайтам типа блога семи блоггеров HTTPS ни к чему - нет приема персональных или платежных данных, нет регистрации и отправки важных сообщений.
Так что в ближайшем будущем мы станем постепенно отходить от HTTP 1.1 в пользу HTTP/2 и HTTPS.
HyperText Transfer Protocol (HTTP) — это протокол высокого уровня (а именно, уровня приложений), обеспечивающий необходимую скорость передачи данных, требующуюся для распределенных информационных систем гипермедиа. HTTP используется проектом World Wide Web с 1990 года.
Практические информационные системы требуют большего, чем примитивный поиск, модификация и аннотация данных. HTTP/1.0 предоставляет открытое множество методов, которые могут быть использованы для указания целей запроса. Они построены на дисциплине ссылок, где для указания ресурса, к которому должен быть применен данный метод, используется Универсальный Идентификатор Ресурсов (Universal Resource Identifier — URI), в виде местонахождения (URL) или имени (URN). Формат сообщений сходен с форматом Internet Mail или Multipurpose Internet Mail Extensions (MIME-Многоцелевое Расширение Почты Internet).
HTTP/1.0 используется также для коммуникаций между различными пользовательскими просмотрщиками и шлюзами, дающими гипермедиа доступ к существующим Internet протоколам, таким как SMTP, NNTP, FTP, Gopher и WAIS. HTTP/1.0 разработан, чтобы позволять таким шлюзам через proxy серверы, без какой-либо потери передавать данные с помощью упомянутых протоколов более ранних версий.
Общая Структура
HTTP основывается на парадигме запросов/ответов. Запрашивающая программа (обычно она называется клиент) устанавливает связь с обслуживающей программой-получателем (обычно называется сервер) и посылает запрос серверу в следующей форме: метод запроса, URI, версия протокола, за которой следует MIME-подобное сообщение, содержащее управляющую информацию запроса, информацию о клиенте и, может быть, тело сообщения. Сервер отвечает сообщением, содержащим строку статуса (включая версию протокола и код статуса — успех или ошибка), за которой следует MIME-подобное сообщение, включающее в себя информацию о сервере, метаинформацию о содержании ответа, и, вероятно, само тело ответа. Следует отметить, что одна программа может быть одновременно и клиентом и сервером. Использование этих терминов в данном тексте относится только к роли, выполняемой программой в течение данного конкретного сеанса связи, а не к общим функциям программы.
В Internet коммуникации обычно основываются на TCP/IP протоколах. Для WWW номер порта по умолчанию — TCP 80, но также могут быть использованы и другие номера портов — это не исключает возможности использовать HTTP в качестве протокола верхнего уровня.
Для большинства приложений сеанс связи открывается клиентом для каждого запроса и закрывается сервером после окончания ответа на запрос. Тем не менее, это не является особенностью протокола. И клиент, и сервер должны иметь возможность закрывать сеанс связи, например, в результате какого-нибудь действия пользователя. В любом случае, разрыв связи, инициированный любой стороной, прерывает текущий запрос, независимо от его статуса.
Общие понятия
Запрос
— это сообщение, посылаемое клиентом серверу.
Первая строка этого сообщения включает в себя метод, который должен быть применен к запрашиваемому ресурсу, идентификатор ресурса и используемую версию протокола. Для совместимости с протоколом HTTP/0.9, существует два формата HTTP запроса:
Запрос = Простой-Запрос | Полный-Запрос Простой-Запрос = "GET" SP Запрашиваемый-URI CRLF Полный-Запрос = Строка-Статус *(Общий-Заголовок | Заголовок-Запроса | Заголовок-Содержания) CRLF [ Содержание-Запроса ]
Если HTTP/1.0 сервер получает Простой-Запрос, он должен отвечать Простым-Ответом HTTP/0.9. HTTP/1.0 клиент, способный обрабатывать Полный-Ответ, никогда не должен посылать Простой-Запрос.
Строка Статус
Строка Статус начинается со строки с названием метода, за которым следует URI-Запроса и использующаяся версия протокола. Строка Статус заканчивается символами CRLF. Элементы строки разделяются пробелами (SP). В Строке Статус не допускаются символы LF и CR, за исключением заключающей последовательности CRLF.
Строка-Статус = Метод SP URI-Запроса SP Версия-HTTP CRLF
Следует отметить, что отличие Строки Статус Полного-Запроса от Строки Статус Простого- Запроса заключается в присутствии поля Версия-HTTP.
Метод
В поле Метод указывается метод, который должен быть применен к ресурсу, идентифицируемому URI-Запроса. Названия методов чувствительны к регистру. Существующий список методов может быть расширен.
Метод = "GET" | "HEAD" | "PUT" | "POST" | "DELETE" | "LINK" | "UNLINK" | дополнительный-метод
Список методов, допускаемых отдельным ресурсом, может быть указан в поле Заголовок-Содержание «Баллов». Тем не менее, клиент всегда оповещается сервером через код статуса ответа, допускается ли применение данного метода для указанного ресурса, так как допустимость применения различных методов может динамически изменяться. Если данный метод известен серверу, но не допускается для указанного ресурса, сервер должен вернуть код статуса «405 Method Not Allowed», и код статуса «501 Not Implemented», если метод не известен или не поддерживается данным сервером. Общие методы HTTP/1.0 описываются ниже.
GET
Метод GET служит для получения любой информации, идентифицированной URI-Запроса. Если URI- Запроса ссылается на процесс, выдающий данные, в качестве ответа будут выступать данные, сгенерированные данным процессом, а не код самого процесса (если только это не является выходными данными процесса).
Метод GET изменяется на «условный GET», если сообщение запроса включает в себя поле заголовка «If-Modified-Since». В ответ на условный GET, тело запрашиваемого ресурса передается только, если он изменялся после даты, указанной в заголовке «If-Modified-Since». Алгоритм определения этого включает в себя следующие случаи:
- Если код статуса ответа на запрос будет отличаться от «200 OK», или дата, указанная в поле заголовка «If-Modified-Since» некорректна, ответ будет идентичен ответу на обычный запрос GET.
- Если после указанной даты ресурс изменялся, ответ будет также идентичен ответу на обычный запрос GET.
- Если ресурс не изменялся после указанной даты, сервер вернет код статуса «304 Not Modified».
Использование метода условный GET направлено на разгрузку сети, так как он позволяет не передавать по сети избыточную информацию.
HEAD
Метод HEAD аналогичен методу GET, за исключением того, что в ответе сервер не возвращает Тело- Ответа. Метаинформация, содержащаяся в HTTP заголовках ответа на запрос HEAD, должна быть идентична информации HTTP заголовков ответа на запрос GET. Данный метод может использоваться для получения метаинформации о ресурсе без передачи по сети самого ресурса. Метод «Условный HEAD», аналогичный условному GET, не определен.
POST
Метод POST используется для запроса сервера, чтобы тот принял информацию, включенную в запрос, как субординантную для ресурса, указанного в Строке Статус в поле URI-Запроса. Метод POST был разработан, чтобы была возможность использовать один общий метод для следующих функций:
- Аннотация существующих ресурсов
- Добавление сообщений в группы новостей, почтовые списки или подобные группы статей
- Доставка блоков данных процессам, обрабатывающим данные
- Расширение баз данных через операцию добавления
Реальная функция, выполняемая методом POST, определяется сервером и обычно зависит от URI- Запроса. Добавляемая информация рассматривается как субординатная указанному URI в том же смысле, как файл субординатен каталогу, в котором он находится, новая статья субординатна группе новостей, в которую она добавляется, запись субординатна базе данных.
Клиент может предложить URI для идентификации нового ресурса, включив в запрос заголовок «URI». Тем не менее, сервер должен рассматривать этот URI только как совет и может сохранить тело запроса под другим URI или вообще без него.
Если в результате обработки запроса POST был создан новый ресурс, ответ должен иметь код статуса, равный «201 Created», и содержать URI нового ресурса.
PUT
Метод PUT запрашивает сервер о сохранении Тело-Запроса под URI, равным URI-Запроса. Если URI-Запроса ссылается на уже существующий ресурс, Тело-Запроса должно рассматриваться как модифицированная версия данного ресурса. Если ресурс, на который ссылается URI-Запроса не существует, и данный URI может рассматриваться как описание для нового ресурса, сервер может создать ресурс с данным URI. Если был создан новый ресурс, сервер должен информировать направившего запрос клиента через ответ с кодом статуса «201 Created». Если существующий ресурс был модифицирован, должен быть послан ответ «200 OK», для информирования клиента об успешном завершении операции. Если ресурс с указанным URI не может быть создан или модифицирован, должно быть послано соответствующее сообщение об ошибке.
Фундаментальное различие между методами POST и PUT заключается в различном значении поля URI-Запроса. Для метода POST данный URI указывает ресурс, который будет управлять информацией, содержащейся в теле запроса, как неким придатком. Ресурс может быть обрабатывающим данные процессом, шлюзом в какой нибудь другой протокол, или отдельным ресурсом, допускающим аннотации. В противоположность этому, URI для запроса PUT идентифицирует информацию, содержащуюся в Содержание-Запроса. Использующий запрос PUT точно знает какой URI он собирается использовать, и получатель запроса не должен пытаться применить этот запрос к какому-нибудь другому ресурсу.
DELETE
Метод DELETE используется для удаления ресурсов, идентифицированных с помощью URI-Запроса. Результаты работы данного метода на сервере могут быть изменены с помощью человеческого вмешательства (или каким-нибудь другим способом). В принципе, клиент никогда не может быть уверен, что операция удаления была выполнена, даже если код статуса, переданный сервером, информирует об успешном выполнении действия. Тем не менее, сервер не должен информировать об успехе до тех пор, пока на момент ответа он не будет собираться стереть данный ресурс или переместить его в некоторую недостижимую область.
LINK
Метод LINK устанавливает взаимосвязи между существующим ресурсом, указанным в URI-Запроса, и другими существующими ресурсами. Отличие метода LINK от остальных методов, допускающих установление ссылок между документами, заключается в том, что метод LINK не позволяет передавать в запросе Тело-Запроса, и в том, что в результате работы данного метода не создаются новые ресурсы.
UNLINK
Метод UNLINK удаляет одну или более ссылочных взаимосвязей для ресурса, указанного в URI- Запроса. Эти взаимосвязи могут быть установлены с помощью метода LINK или какого-нибудь другого метода, поддерживающего заголовок «Link». Удаление ссылки на ресурс не означает, что ресурс прекращает существование или становится недоступным для будущих ссылок.
Поля Заголовок-Запроса
Поля Заголовок-Запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте.
Заголовок-Запроса = Accept | Accept-Charset | Accept-Encoding | Accept-Language | Authorization | From | If-Modified-Since | Pragma | Referer | User-Agent | extension-header
Кроме того через механизм расширения могут быть определены дополнительные заголовки; приложения, которые их не распознают, должны трактовать эти заголовки, как Заголовок-Содержание.
Ниже будут рассмотрены некоторые поля заголовка запроса.
From
В случае присутствия поля From, оно должно содержать полный E-mail адрес пользователя, который управляет программой-агентом, осуществляющей запросы. Этот адрес должен быть задан в формате, определенном в RFC 822. Формат данного поля следующий: From = «From» «:» спецификация адреса. Например:
From: [email protected]
Данное поле может быть использовано для функций захода в систему, а также для идентификации источника некорректных или нежелательных запросов. Оно не должно использоваться, как несекретная форма разграничения прав доступа. Интерпретация этого поля состоит в том, что обрабатываемый запрос производится от имени данного пользователя, который принимает ответственность за применяемый метод. В частности, агенты-роботы должны использовать этот заголовок для того, чтобы можно было связаться с тем человеком, который отвечает за работу робота, в случае возникновения проблем. Почтовый Internet адрес, указывающийся в этом поле, не обязан соответствовать адресу того хоста, с которого был послан данный запрос. По возможности, адрес должен быть доступным Internet адресом вне зависимости от того, является ли он в действительности Internet E-mail адресом или Internet E-mail представлением адреса других почтовых систем.
Замечание: Клиент не должен использовать поле заголовка From без позволения пользователя, так как это может войти в конфликт с его частными интересами или с местной, используемой им, системой безопасности. Настоятельно рекомендуется предоставление пользователю возможности запретить, разрешить или модифицировать это поле в любой момент перед запросом.
If-Modified-Since
Поле заголовка If-Modified-Since используется с методом GET для того, чтобы сделать его условным: если запрашиваемый ресурс не изменялся во времени, указанного в этом поле, копия этого ресурса не будет возвращена сервером; вместо этого, будет возвращен ответ «304 Not Modified» без Тела- Ответа.
If-Modified-Since = "If-Modified-Since" ":" HTTP-дата
Пример использования заголовка:
Целью этой особенности является предоставление возможности эффективного обновления информации локальных кэшей с минимумом передаваемой информации. Тот же результат может быть достигнут применением метода HEAD с последующим использованием GET, если сервер указал, что содержимое документа изменилось.
User-Agent
Поле заголовка User-Agent содержит информацию о пользовательском агенте, пославшем запрос. Данное поле используется для статистики, прослеживания ошибок протокола, и автоматического распознавания пользовательских агентов. Хотя это не обязательно, пользовательские агенты должны всегда включать это поле в свои запросы. Поле может содержать несколько строк, представляющих собой название программного продукта, необязательную косую черту с указанием версии продукта, а также другие программные продукты, составляющие важную часть пользовательского агента. По соглашению, продукты указываются в списке в порядке убывания их значимости для идентификации приложения.
User-Agent = "User-Agent" ":" 1*(продукт) продукт = строка ["/" версия-продукта] версия-продукта = строка
User-Agent: CERN-LineMode/2.15 libwww/2.17b3
Строка, описывающая название продукта, должна быть короткой и давать информацию по существу — использование данного заголовка для рекламирования какой-либо другой, не относящейся к делу, информации не допускается и рассматривается, как не соответствующее протоколу. Хотя в поле версии продукта может присутствовать любая строка, данная строка должна использоваться только для указания версии продукта. Поле User-Agent может включать в себя дополнительную информацию в комментариях, которые не являются частью его значения.
Структура ответа
После получения и интерпретации запроса, сервер посылает ответ в соответствии со следующей формой:
Ответ = Простой-Ответ | Полный-Ответ Простой-Ответ = [ Содержание-Ответа ] Полный-Ответ = Строка-Статус *(Общий-Заголовок | Заголовок-Ответа | Заголовок-Содержания) CRLF [ Содержание-Ответа ]
Простой-Ответ должен посылаться только в ответ на HTTP/0.9 Простой-Запрос, или в том случае, если сервер поддерживает только ограниченный HTTP/0.9 протокол. Если клиент посылает HTTP/1.0 Полный-Запрос и получает ответ, который не начинается со Строки-Статус, он должен предполагать, что ответ сервера представляет собой Простой-Ответ, и обрабатывать его в соответствии с этим. Следует заметить, что Простой-Ответ состоит только из запрашиваемой информации (без заголовков) и поток данных прекращается в тот момент, когда сервер закрывает сеанс связи.
Строка Статус
Первая строка Полного-Запроса является Строкой-Статус, состоящей из версии протокола, за которой следует цифровой код статуса и ассоциированное с ним текстовое предложение. Все элементы Строки-Статус разделены пробелами. Не разрешены символы CR и LF, за исключением завершающей последовательности CRLF.
Строка-Статус=Версия-HTTP SP Статус-Код SP Фраза-Об"яснение.
Так как Строка-Статус всегда начинается с версии протокола «HTTP/» 1*ЦИФРА «.» 1*ЦИФРА (например HTTP/1.0), существование этого выражения рассматривается как основное для определения того, является ли ответ Простым-Ответом, или Полным-Ответом. Хотя формат Простого-Ответа не исключает появления подобной строки (что привело бы к неправильной интерпретации сообщения ответа и принятию его за Полный-Ответ), вероятность такого появления близка к нулю.
Статус-Код и пояснение к нему
Элемент Статус-Код представляет собой 3-х цифровой целый код, идентифицирующий результат попытки интерпретации и удовлетворения запроса. Фраза-Об’яснение, следующая за ним, предназначена для краткого текстового описания Статус-Кода. Статус-Код нацелен на то, чтобы его использовала машина, а Фраза-Об’яснение предназначена для человека. Клиент не обязан исследовать и выводить на экран Фразу-Об’яснение.
Первая цифра Статус-Кода предназначена для определения класса ответа. Последние две цифры не выполняют никакой категоризирующей роли. Существует 5 значений для первой цифры:
- 1xx: Информационный — Не используется, но зарезервирован для использования в будущем
- 2xх: Успех — Запрос был полностью получен, понят, и принят к обработке.
- 3xx: Перенаправление — Клиенту следует предпринять дальнейшие действия для успешного выполнения запроса. Необходимое дополнительное действие иногда может быть выполнено клиентом без взаимодействия с пользователем, но настоятельно рекомендуется, чтобы это имело место только в тех случаях, когда метод, использующийся в запросе безразличен (GET или HEAD).
- 4xx: Ошибка клиента — Запрос, содержащий неправильные синтаксические конструкции, не может быть успешно выполнен. Класс 4xx предназначен для описания тех случаев, когда ошибка была допущена со стороны клиента. Если клиент еще не завершил запрос, когда он получил ответ с Статус-Кодом- 4xx, он должен немедленно прекратить передачу данных серверу. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
- 5xx: Ошибка Сервера — Сервер не смог дать ответ на корректно поставленный запрос. В этих случаях
сервер либо знает, что он допустил ошибку, либо не способен обработать запрос. За исключением ответов на запросы HEAD, сервер посылает описание ошибочной ситуации и то, является ли это состояние временным или постоянным, в Содержание-Ответа. Данный тип Статус-Кодов применим для любых методов, употребляющихся в запросе.
Отдельные значения Статус-Кодов и соответствующие им Фразы-Об’яснения приведены ниже. Данные Фразы-Об’яснения только рекомендуются — они могут быть замещены любыми другими фразами, сохраняющими смысл и допускающимися протоколом.
Статус-Код = "200" ; OK | "201" ; Created | "202" ; Accepted | "203" ; Provisional Information | "204" ; No Content | "300" ; Multiple Choices | "301" ; Moved Permanently | "302" ; Moved Temporarily | "303" ; Method | "304" ; Not Modified | "400" ; Bad Request | "401" ; Unauthorized | "402" ; Payment Required | "403" ; Forbidden | "404" ; Not Found | "405" ; Method Not Allowed | "406" ; None Acceptable | "407" ; Proxy Authentication Required | "408" ; Request Timeout | "409" ; Conflict | "410" ; Gone | "500" ; Internal Server Error | "501" ; Not Implemented | "502" ; Bad Gateway | "503" ; Service Unavailable | "504" ; Gateway Timeout | Код-Рассширения Код-Расширения = 3ЦИФРА Фраза-Об"яснение = строка *(SP строка)
От HTTP приложений не требуется понимание всех Статус-Кодов, хотя такое понимание, очевидно, желательно. Тем не менее, от приложений требуется способность распознавания классов Статус-Кодов (идентифицирующихся первой цифрой) и отношение ко всем Статус-Кодам статуса ответа, как если бы они были эквивалентны Статус-Коду x00.
Поля Заголовок-Ответа
Поля заголовка ответа позволяют серверу передать дополнительную информацию об ответе, которая не может быть внесена в Строку-Статус. Эти поля заголовков не предназначены для передачи информации о содержании ответа, передаваемого в ответ на запрос, но там может быть информация собственно о сервере.
Заголовок-Ответа= Public | Retry-After | Server | WWW-Authenticate | extension-header
Хотя дополнительные поля заголовка ответа могут быть реализованы через механизм расширения, приложения, которые не распознают эти поля, должны обрабатывать их как поля Заголовок-Содержание. Полное описание этих полей можно получить в спецификации протокола HTTP в CERN.
Общие Понятия
Полный-Запрос и Полный-Ответ может использоваться для передачи некоторой информации в отдельных запросах и ответах. Этой информацией является Содержание-Запроса или Содержание-Ответа соответственно, а также Заголовок-Содержания.
Поля Заголовок-Содержания
Поля Заголовок-Содержания содержат необязательную метаинформацию о Содержании-Запроса или Содержании-Ответа соответственно. Если тело соответствующего сообщения (запроса или ответа) не присутствует, то Заголовок-Содержания содержит информацию о запрашиваемом ресурсе.
Некоторые из полей заголовка содержания описаны ниже.
Allow
Поле заголовка Allow представляет собой список методов, которые поддерживает ресурс, идентифицированный URI-Запроса. Назначение этого поля — точное информирование получателя о допустимых методах, ассоциированных с ресурсом; это поле должно присутствовать в ответе со статус кодом «405 Method Not Allowed».
Allow = "Allow" ":" 1#метод
Пример использования:
Allow: GET, HEAD, PUT
Конечно, клиент может попробовать использовать другие методы. Однако, рекомендуется следовать тем методам, которые указаны в данном поле. У этого поля нет значения по умолчанию; если оно оставлено неопределенным, множество разрешенных методов определяется сервером в момент каждого запроса.
Content-Length
Поле Content-Length указывает размер тела сообщения, посланного сервером в ответ на запрос или, в случае запроса HEAD, размер тела сообщения, которое было бы послано в ответ на запрос GET.
Content-Length = "Content-Length" ":" 1*ЦИФРА
Например:
Content-Length: 3495
Хотя это не обязательно, но все же приложениям настоятельно рекомендуется использовать это поле для анализа размеров передаваемого сообщения, независимо от типа содержащейся в нем информации. Для поля Content-Length допустимым является любое целочисленное значение больше нуля.
Content-Type
Поле заголовка Content-Type идентифицирует тип информации в теле сообщения, которая посылается получающей стороне или, в случае метода HEAD, тип информации (среды), который был бы послан, если использовался метод GET.
Content-Type = "Content-Type" ":" тип-среды
Типы сред определены отдельно.
Пример:
Content-Type: text/html; charset=ISO-8859-4
Поле Content-Type не имеет значения по умолчанию.
Last-Modified
Поле заголовка содержит дату и время, в которое, по мнению отправляющей стороны, ресурс был последний раз модифицирован. Семантика данного поля определена в терминах, описывающих, как получатель должен его интерпретировать: если получатель имеет копию ресурса, которая старше, чем передаваемая в поле Last-Modified дата, то копия должна считаться устаревшей.
Last-Modified = "Last-Modified" ":" HTTP-дата
Пример использования:
Точное значение этого поля заголовка зависит от реализации отправляющей стороны и сути самого ресурса. Для файлов, это может быть просто его время последней модификации. Для шлюзов к базам данных, это может быть время последнего обновления данных в базе. В любом случае, получатель должен беспокоиться лишь о результате — о том, что находится в данном поле, — и не беспокоиться о том, как результат был получен.
Тело сообщения
Под телом сообщения понимается Содержание-Запроса или Содержание-Ответа соответственно. Тело сообщения, если оно присутствует, посылается в HTTP/1.0 запросе или ответе в формате и кодировке, определяемыми полями Заголовок-Содержания.
Тело-Сообщения = *OCTET (где OCTET это любой 8-битный символ)
Тело сообщения включается в запрос, только если метод запроса подразумевает его наличие. Для спецификации HTTP/1.0 такими методами являются POST и PUT. В общем, на присутствие тела сообщения указывает присутствие таких полей заголовка содержания, как Content-Length и/или Content- Transfer-Encoding, в передаваемом запросе.
Прочитав эту статью вы узнаете, почему так важно использовать сжатие, и какое влияние оно может оказывать на ваш веб-сайт. Эта статья основана на двух ключевых…
HTTP - это протокол передачи гипертекста между распределёнными системами. По сути, http является фундаментальным элементом современного Web-а. Как уважающие себя веб разработчики, мы должны знать о нём как можно больше.
Давайте взглянем на этот протокол через призму нашей профессии. В первой части пройдёмся по основам, посмотрим на запросы/ответы. В следующей статье разберём уже более детальные фишки, такие как кэширование, обработка подключения и аутентификация.
Также в этой статье я буду, в основном, ссылаться на стандарт RFC 2616 : Hypertext Transfer Protocol -- HTTP/1.1.
Основы HTTP
HTTP обеспечивает общение между множеством хостов и клиентов, а также поддерживает целый ряд сетевых настроек.
В основном, для общения используется TCP/IP, но это не единственный возможный вариант. По умолчанию, TCP/IP использует порт 80, но можно заюзать и другие.
Общение между хостом и клиентом происходит в два этапа: запрос и ответ. Клиент формирует HTTP запрос, в ответ на который сервер даёт ответ (сообщение). Чуть позже, мы более подробно рассмотрим эту схему работы.
Текущая версия протокола HTTP - 1.1, в которой были введены некоторые новые фишки. На мой взгляд, самые важные из них это: поддержка постоянно открытого соединения, новый механизм передачи данных chunked transfer encoding, новые заголовки для кэширования. Что-то из этого мы рассмотрим во второй части данной статьи.
URL
Сердцевиной веб-общения является запрос, который отправляется через Единый указатель ресурсов (URL). Я уверен, что вы уже знаете, что такое URL адрес, однако для полноты картины, решил всё-таки сказать пару слов. Структура URL очень проста и состоит из следующих компонентов:

Протокол может быть как http для обычных соединений, так и https для более безопасного обмена данными. Порт по умолчанию - 80. Далее следует путь к ресурсу на сервере и цепочка параметров.
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET : получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST : используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT : обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE : служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD : аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE : во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS : используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант - это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted : запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content : в теле ответа нет сообщения.
- 205 Reset Content : указание серверу о сбросе представления документа.
- 206 Partial Content : ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently : ресурс теперь можно найти по другому URL адресу.
- 303 See Other : ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified : сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности - Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request : вопрос был сформирован неверно.
- 401 Unauthorized : для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden : сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed : неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict : сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented : сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable : это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.

Давайте посмотрим на структуру передаваемого сообщения через HTTP:
Message =
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
General-header = Cache-Control | Connection | Date | Pragma | Trailer | Transfer-Encoding | Upgrade | Via | Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache - это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.
Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
Entity-header = Allow | Content-Encoding | Content-Language | Content-Length | Content-Location | Content-MD5 | Content-Range | Content-Type | Expires | Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
Формат запроса
Запрос выглядит примерно так:
Request-Line = Method SP URI SP HTTP-Version CRLF Method = "OPTIONS" | "HEAD" | "GET" | "POST" | "PUT" | "DELETE" | "TRACE"
SP - это разделитель между токенами. Версия HTTP указывается в HTTP-Version. Реальный запрос выглядит так:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Список возможных заголовков запроса:
Request-header = Accept | Accept-Charset | Accept-Encoding | Accept-Language | Authorization | Expect | From | Host | If-Match | If-Modified-Since | If-None-Match | If-Range | If-Unmodified-Since | Max-Forwards | Proxy-Authorization | Range | Referer | TE | User-Agent
В заголовке Accept определяется поддерживаемые mime типы, язык, кодировку символов. Заголовки From, Host, Referer и User-Agent содержат информацию о клиенте. Префиксы If- предназначены для создания условий. Если условие не прошло, то возникнет ошибка 304 Not Modified.
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
HTTP/1.1 200 OK
Заголовки ответа могут быть следующими:
Response-header = Accept-Ranges | Age | ETag | Location | Proxy-Authenticate | Retry-After | Server | Vary | WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Инструменты для определения HTTP трафика
Существует множество инструментов для мониторинга HTTP трафика. Вот несколько из них:
Наиболее часто используемый - это Chrome Developers Tools:

Если говорить об отладчике, можно воспользоваться Fiddler :

Для отслеживания HTTP трафика вам потребуется curl, tcpdump и tshark.
Библиотеки для работы с HTTP - jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте .
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({ url: "http://www.articles.com/latest", type: "GET", beforeSend: function (jqXHR) { jqXHR.setRequestHeader("Accepts-Language", "en-US,en"); } });
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({ statusCode: { 404: function() { alert("page not found"); } } });
Итог
Вот такой вот он, тур по основам протокола HTTP. Во второй части будет ещё больше интересных фактов и примеров.
HTTP . В его основу положено взаимодействие " клиент-сервер ", то есть предполагается, что:- Потребитель- клиент инициировав соединение с поставщиком-сервером посылает ему запрос;
- Поставщик- сервер
, получив запрос, производит необходимые
действия и возвращает обратно клиенту ответ с результатом.
При этом возможны два способа организации работы компьютера-клиента:
- Тонкий клиент - это компьютер-клиент, который переносит все задачи по обработке информации на сервер. Примером тонкого клиента может служить компьютер с браузером, использующийся для работы с веб-приложениями.
- Толстый клиент , напротив, производит обработку информации независимо от сервера, использует последний в основном лишь для хранения данных.
Прежде чем перейти к конкретным клиент-серверным веб-технологиям, рассмотрим основные принципы и структуру базового протокола HTTP .
Протокол HTTP
HTTP (HyperText Transfer Protocol - RFC 1945, RFC 2616) - протокол прикладного уровня для передачи гипертекста.
Центральным объектом в HTTP является ресурс , на который указывает URL в запросе клиента. Обычно такими ресурсами являются хранящиеся на сервере файлы. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя изначально данный протокол предназначен для передачи символьной информации. На первый взгляд это может показаться излишней тратой ресурсов. Действительно, данные в символьном виде занимают больше памяти, сообщения создают дополнительную нагрузку на каналы связи, однако подобный формат имеет много преимуществ. Сообщения, передаваемые по сети, удобочитаемы, и, проанализировав полученные данные, системный администратор может легко найти ошибку и устранить ее. При необходимости роль одного из взаимодействующих приложений может выполнять человек, вручную вводя сообщения в требуемом формате.
В отличие от многих других протоколов, HTTP является протоколом без памяти. Это означает, что протокол не хранит информацию о предыдущих запросах клиентов и ответах сервера. Компоненты, использующие HTTP , могут самостоятельно осуществлять сохранение информации о состоянии, связанной с последними запросами и ответами. Например, клиентское веб- приложение , посылающее запросы, может отслеживать задержки ответов, а веб- сервер может хранить IP-адреса и заголовки запросов последних клиентов.
Все программное обеспечение для работы с протоколом HTTP разделяется на три основные категории:
- Серверы - поставщики услуг хранения и обработки информации (обработка запросов).
- Клиенты - конечные потребители услуг сервера (отправка запросов).
- Прокси-серверы для поддержки работы транспортных служб.
Основными клиентами являются браузеры , например: Internet Explorer, Opera, Mozilla Firefox, Netscape Navigator и другие. Наиболее популярными реализациями веб-серверов являются: Internet Information Services ( IIS ), Apache, lighttpd, nginx. Наиболее известные реализации прокси-серверов: Squid, UserGate, Multiproxy, Naviscope.
"Классическая" схема HTTP -сеанса выглядит так.
- Установление TCP-соединения.
- Запрос клиента.
- Ответ сервера.
- Разрыв TCP-соединения.
Таким образом, клиент посылает серверу запрос , получает от него ответ, после чего взаимодействие прекращается. Обычно запрос клиента представляет собой требование передать HTML -документ или какой-нибудь другой ресурс , а ответ сервера содержит код этого ресурса.
В состав HTTP -запроса, передаваемого клиентом серверу, входят следующие компоненты.
- Строка состояния (иногда для ее обозначения используют также термины строка-статус, или строка запроса).
- Поля заголовка.
- Пустая строка.
- Тело запроса.
Строку состояния вместе с полями заголовка иногда называют также заголовком запроса .
Рис.
2.1.
Строка состояния имеет следующий формат:
метод_запроса URL_pecypca версия_протокола_НТТР
Рассмотрим компоненты строки состояния, при этом особое внимание уделим методам запроса.
Метод , указанный в строке состояния, определяет способ воздействия на ресурс , URL которого задан в той же строке. Метод может принимать значения GET , POST , HEAD , PUT , DELETE и т.д. Несмотря на обилие методов, для веб-программиста по-настоящему важны лишь два из них: GET и POST .
- GET . Согласно формальному определению, метод GET предназначается для получения ресурса с указанным URL. Получив запрос GET , сервер должен прочитать указанный ресурс и включить код ресурса в состав ответа клиенту. Ресурс, URL которого передается в составе запроса, не обязательно должен представлять собой HTML-страницу, файл с изображением или другие данные. URL ресурса может указывать на исполняемый код программы, который, при соблюдении определенных условий, должен быть запущен на сервере. В этом случае клиенту возвращается не код программы, а данные, сгенерированные в процессе ее выполнения. Несмотря на то что, по определению, метод GET предназначен для получения информации, он может применяться и в других целях. Метод GET вполне подходит для передачи небольших фрагментов данных на сервер.
- POST . Согласно тому же формальному определению, основное назначение метода POST - передача данных на сервер. Однако, подобно методу GET , метод POST может применяться по-разному и нередко используется для получения информации с сервера. Как и в случае с методом GET , URL, заданный в строке состояния, указывает на конкретный ресурс. Метод POST также может использоваться для запуска процесса.
- Методы HEAD и PUT являются модификациями методов GET и POST.
Версия протокола HTTP , как правило, задается в следующем формате:
HTTP/версия.модификация
Поля заголовка , следующие за строкой состояния, позволяют уточнять запрос , т.е. передавать серверу дополнительную информацию. Поле заголовка имеет следующий формат:
Имя_поля: Значение
Назначение поля определяется его именем, которое отделяется от значения двоеточием.
Имена некоторых наиболее часто встречающихся в запросе клиента полей заголовка и их назначение приведены в таблице 2.1 .
| Поля заголовка HTTP -запроса | Значение |
|---|---|
| Host | Доменное имя или IP-адрес узла, к которому обращается клиент |
| Referer | URL документа, который ссылается на ресурс, указанный в строке состояния |
| From | Адрес электронной почты пользователя, работающего с клиентом |
| Accept | MIME-типы данных, обрабатываемых клиентом. Это поле может иметь несколько значений, отделяемых одно от другого запятыми. Часто поле заголовка Accept используется для того, чтобы сообщить серверу о том, какие типы графических файлов поддерживает клиент |
| Accept-Language | Набор двухсимвольных идентификаторов, разделенных запятыми, которые обозначают языки, поддерживаемые клиентом |
| Accept-Charset | Перечень поддерживаемых наборов символов |
| Content-Type | MIME-тип данных, содержащихся в теле запроса (если запрос не состоит из одного заголовка) |
| Content-Length | Число символов, содержащихся в теле запроса (если запрос не состоит из одного заголовка) |
| Range | Присутствует в том случае, если клиент запрашивает не весь документ, а лишь его часть |
| Connection | Используется для управления TCP-соединением. Если в поле содержится Close, это означает, что после обработки запроса сервер должен закрыть соединение. Значение Keep-Alive предлагает не закрывать TCP-соединение, чтобы оно могло быть использовано для последующих запросов |
| User-Agent | Информация о клиенте |
Во многих случаях при работе в Веб тело запроса отсутствует. При запуске CGI-сценариев данные, передаваемые для них в запросе, могут размещаться в теле запроса.
HTTP (англ. Hyper Text Transfer Protocol – «протокол передачи гипертекста») - протокол передачи данных прикладного уровня, разработанный специально для обмена информацией между веб-сайтом и пользовательским агентом (браузером). Это один из тех стандартов, на которых основан весь World Wide Web. Взаимодействие поисковых систем с сайтами также проходит в рамках протокола HTTP .
Бессмысленно полностью и в деталях пересказывать здесь содержание RFC - ниже даны ссылки для подробного ознакомления. Здесь изложен только минимум, необходимый для понимания процесса обмена информацией в рамках протокола.
О терминах
Многие термины могут пониматься в разных смыслах. Необходимо сразу договориться, в каком смысле употребляется в этой статье тот или другой термин.
Веб-сервер (сервер)
- не компьютер, стоящий в датацентре, а исполняемая на этом компьютере программа, которая принимает запросы и отправляет запрошенные документы.
Пользовательский агент (клиент, User-agent)
- программа, посылающая запросы веб-серверу и получающая от него документы. Это может быть ваш браузер, а может быть и сканирующий бот поисковой системы.
Документ
- любая отдельная единица информации, имеющая свой адрес в домене. По умолчанию подразумевается HTML -страница, но документами также считаются файлы рисунков, CSS , Java-скриптов и т.п.
Порядок обмена информацией
В HTTP предусмотрено всего два типа сообщений: запрос клиента и ответ сервера. Клиент шлет серверу запрос, указывая имя домена и адрес внутри домена, по которому должен находиться нужный документ. Сервер принимает сообщение, ищет документ (или запускает скрипт, которым этот документ генерируется) и при успешном завершении отправляет ответное сообщение.
Структура этих сообщений одинакова:
Стартовая строка
Заголовки
Тело сообщения
Стартовую строку и строки заголовков часто называют вместе «заголовком запроса» (или ответа).
Пример стартовой строки запроса:
GET /index.php HTTP/1.1
Передан метод запроса (GET), адрес документа внутри домена и версия протокола, которая используется.
Пример стартовой строки ответа:
HTTP/1.1 200 OK
Передана версия протокола, числовой код статуса (200) и расшифровка статуса (OK).
Заголовки
В заголовках запроса передается дополнительная информация, которая может влиять на дальнейший обмен сообщениями. Обязательно передается имя домена, из которого запрашивается документ. Также может передаваться ожидаемый медиатип документа, возможность приема в сжатом формате, ожидаемый язык для текстовых документов, название пользовательского агента, отправившего запрос. В заголовке могут также передаваться условия запроса. Например, If-Modified-Since: [метка времени] - запрашивается документ при условии, что его содержание изменилсь со времени, указанного в заголовке.
В заголовке ответа также передается дополнительная информация - название сервера, текущее время, медиатип и кодировка передаваемого документа, возможно и другие данные (язык для текстовых документов, дата модификации, размер в байтах и т.д.). Все это - сопроводительная информация к документу, который будет передан после заголовков (в теле сообщения), если запрос выполнен успешно.
При невозможности передачи документа код статуса в сообщении сервера соответствует характеру ошибки, а вместо тела документа передается специальная HTML -страница с текстом сообщения об ошибке. Обратите внимание, что статус ошибки не мешает браузеру отобразить эту страницу.
Методы запроса
Протоколом в редакции RFC 2616 описано восемь методов для обращения к серверу. Но на сегодняшний день не все они реализованы для большинства веб-серверов, а обязательными к реализации признаны только два. Основные методы, которые нас интересуют и поддерживаются практически всеми веб-серверами - это GET, HEAD и POST.
Метод GET
Это самый обычный метод запроса для получения веб-страницы или другого документа. В ответ на этот запрос сервер должен отыскать (или сформировать) документ и при успешном завершении отправить его клиенту.
Формат запроса:
GET HTTP[версия протокола]
Метод HEAD
Этот метод аналогичен GET, но с одним отличием: в ответ на запрос HEAD сервер выполняет поиск (или формирование документа), но отправляет только заголовки ответа, не передавая тело сообщения. Таким способом можно проверить существование или доступность документа по данному адресу, получить всю информацию о документе, передаваемую в заголовках, не получая сам документ.
Формат запроса:
HEAD HTTP[версия протокола]
Тело сообщения в запросе отсутствует.
Метод POST
Этот метод предназначен для передачи данных на сервер - например, данные, введенные в форму, обычно передаются методом POST.
Формат запроса:
POST HTTP[версия протокола]
Поле [ URI ] содержит адрес скрипта-обработчика формы, который принимает и обрабатывает данные. В теле сообщения передаются данные, введенные в поля формы в виде [имя_поля=введенное_значение].
Коды статуса
Коды статуса (состояния) отображают результат обработки запроса сервером. Код представлен трехзначным десятичным числом, старший разряд которого указывает на класс ответа. Таким образом, под каждый класс ответов зарезервировано до ста разных кодов статуса. Всего определено пять классов:
1xx: Informational - информационный
Коды от 100 до 199, входящие в этот класс, информируют клиента, что запрос получен. Сообщения с такими статусами содержат только стартовую строку и (если нужно) заголовки, но не содержат тело сообщения. Отправлять что-либо в ответ на это клиент не должен.
2xx: Success - успешно
Сообщения этого класса означают, что запрос успешно получен, интерпретирован и обработан. Из этих кодов статуса нас интересует только 200 «OK» - признак нормального завершения, после которого в теле сообщения клиенту пересылается запрошенный документ.