Введение
Глава1. Основы баз данных
1.1.Классификация баз данных
1.3Модели описания баз данных
1.4. Основы работы настольных СУБД
1.5.Требования и стандарты, предъявляемые к базам данных
Глава 2. Работа с базой данных Microsoft Access
2.1. Основы работы настольной СУБД Microsoft Access
2.2. Работа с базой данных Microsoft Access
Заключение
Список использованной литературы
Введение
Потоки информации, циркулирующие в мире, который нас окружает, огромны. Во
времени они имеют тенденцию к увеличению. Поэтому в любой организации, как
большой, так и маленькой, возникает проблема такой организации управления
данными, которая обеспечила бы наиболее эффективную работу. Некоторые
организации используют для этого шкафы с папками, но большинство предпочитают
компьютеризированные способы – базы данных, позволяющие эффективно хранить,
структурировать и систематизировать большие объемы данных. И уже сегодня без баз
данных невозможно представить работу большинства финансовых, промышленных,
торговых и прочих организаций. Не будь баз данных, они бы просто захлебнулись в
информационной лавине.
Существует много веских причин перевода существующей информации на компьютерную основу. Сейчас стоимость хранения информации в файлах ЭВМ дешевле, чем на бумаге. Базы данных позволяют хранить, структурировать информацию и извлекать
оптимальным для пользователя образом. Данная тема актуальна в настоящее время, т.к. использование клиент/серверных технологий позволяют сберечь значительные средства, а главное и время для получения необходимой информации, а также упрощают доступ и ведение, поскольку они основываются на комплексной обработке данных и централизации их хранения. Кроме того ЭВМ позволяет хранить любые форматы данных, текст, чертежи, данные в рукописной форме, фотографии, записи голоса и т.д.
Для использования столь огромных объемов хранимой информации, помимо развития
системных устройств, средств передачи данных, памяти, необходимы средства
обеспечения диалога человек - ЭВМ, которые позволяют пользователю вводить
или принимать решения на основании хранимых данных. Для обеспечения этих функций
созданы специализированные средства – системы управления базами данных (СУБД).
Целью данной работы является раскрыть понятие базы данных и системы управления базами данных, а также рассмотреть на конкретном примере работу настольной СУБД.
1.1.Классификация баз данных
База данных – это информационная модель предметной области, совокупность взаимосвязанных, хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. Данные (файлы) хранятся во внешней памяти и используются в качестве входной информации для решения задач.
СУБД - это программа, с помощью которой реализуется централизованное управление данными, хранимыми в базе, доступ к ним, поддержка их в актуальном состоянии.
Системы управления базами данных можно классифицировать по способу установления связей между данными, характеру выполняемых ими функций, сфере применения, числу поддерживаемых моделей данных, характеру используемого языка общения с базой данных и другим параметрам.
Классификация СУБД:
· по выполняемым функциям СУБД подразделяются на операционные и информационные;
· по сфере применения СУБД подразделяются на универсальные и проблемно-ориентированные;
· по используемому языку общения СУБД подразделяются на замкнутые, имеющие собственные самостоятельные языки общения пользователей с базами данных, и открытые, в которых для общения с базой данных используется язык программирования, расширенный операторами языка манипулирования данными;
· по числу поддерживаемых уровней моделей данных СУБД подразделяются на одно-, двух-, трехуровневые системы;
· по способу установления связей между данными различают реляционные, иерархические и сетевые базы данных;
· по способу организации хранения данных и выполнения функций обработки базы данных подразделяются на централизованные и распределенные.
Системы централизованных баз данных с сетевым доступом предполагают две основные архитектуры – файл-сервер или клиент-сервер.
Архитектура файл-сервер. Предполагает выделение одной из машин сети в качестве центральной (главный сервер файлов), где хранится совместно используемая централизованная база данных. Все другие машины исполняют роль рабочих станций. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится их обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает.
Архитектура клиент-сервер. Эта модель взаимодействия компьютеров в сети для современных СУБД фактически стала стандартом. Каждый из подключенных к сети и составляющих эту архитектуру компьютеров играет свою роль: сервер владеет и распоряжается информационными ресурсами системы, клиент имеет возможность пользоваться ими. Помимо хранения централизованной базы данных сервер базы данных обеспечивает выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запроса SQL.
Сервер базы данных представляет собой СУБД, параллельно обрабатывающую запросы, поступившие со всех рабочих станций. Как правило, клиент и сервер территориально отделены друг от друга, и в этом случае они образуют систему распределенной обработки данных.
1.2. Функциональные возможности СУБД
Характеристиками СУБД являются:
· производительность;
· обеспечение целостности данных на уровне баз данных;
· обеспечение безопасности данных;
· возможность работы в многопользовательских средах;
· возможность импорта и экспорта данных;
· обеспечение доступа к данным с помощью языка SQL;
· возможность составления запросов;
· наличие инструментальных средств разработки прикладных программ.
Производительность СУБД оценивается:
· временем выполнения запросов;
· скоростью поиска информации;
· временем импортирования баз данных из других форматов;
· скоростью выполнения операций (таких как обновление, вставка, удаление);
· временем генерации отчета и другими показателями.
· Безопасность данных достигается:
· шифрованием прикладных программ;
· шифрованием данных;
· защитой данных паролем;
· ограничением доступа к базе данных (к таблице, к словарю и т.д.).
Обеспечение целостности данных подразумевает наличие средств, позволяющих удостовериться, что информация в базе данных всегда остается корректной и полной. Целостность данных должна обеспечиваться независимо от того, каким образом данные заносятся в память (в интерактивном режиме, посредством импорта или с помощью специальной программы). Используемые в настоящее время СУБД обладают средствами обеспечения целостности данных и надежной безопасности.
Система управления базами данных управляет данными во внешней памяти, обеспечивает надежное хранение данных и поддержку соответствующих языков базы данных. Важной функцией СУБД является функция управления буферами оперативной памяти. Обычно СУБД работают с базами данных больших размеров, часто превышающими размеры оперативной памяти ЭВМ. В развитых СУБД поддерживается свой набор буферов оперативной памяти с собственной дисциплиной их замены.
Наибольшее распространение в настоящее время получили системы управления базами данных Microsoft Access и Oracle.
Этапами работы в СУБД являются:
· создание структуры базы данных, т.е. определение перечня полей, из которых состоит каждая запись таблицы, типов и размеров полей (числовой, текстовый, логический и т.д.), определение ключевых полей для обеспечения необходимых связей между данными и таблицами;
· ввод и редактирование данных в таблицах баз данных с помощью представляемой по умолчанию стандартной формы в виде таблицы и с помощью экранных форм, специально создаваемых пользователем;
· обработка данных, содержащихся в таблицах, на основе запросов и на основе программы;
· вывод информации из ЭВМ с использованием отчетов и без использования отчетов.
Реализуются названные этапы работы с помощью различных команд.
Централизованная база данных обеспечивает простоту управления, улучшенное использование данных на местах при выполнении дистанционных запросов, более высокую степень одновременности обработки, меньшие затраты на обработку.
Распределенная база данных предполагает хранение и выполнение функций управления данными в нескольких узлах и передачу данных между этими узлами в процессе выполнения запросов. В такой базе данных не только различные ее таблицы могут храниться на разных компьютерах, но и разные фрагменты одной таблицы. При этом для пользователя не имеет значения как организовано хранение данных, он работает с такой базой, как с централизованной.
1.3.Модели описания баз данных
Известны три типа моделей описания баз данных – иерархическая, сетевая и реляционная, основное различие между которыми состоит в характере описания взаимосвязей и взаимодействия между объектами и атрибутами базы данных.
Иерархическая модель предполагает использование для описания базы данных древовидных структур, состоящих из определенного числа уровней. «Дерево» представляет собой иерархию элементов, называемых узлами. Под элементами понимается список, совокупность, набор атрибутов, элементов, описывающих объекты.
Инфологическая модель
Инфологическая модель - это описание предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства. Инфологическая модель является моделью ориентированной на человека, полностью независимой от физических параметров среды, способа хранения данных. Инфологическая модель изменяется только в том случае, когда изменения в реальном мире потребуют изменений основной модели. Основные преимущества ER-моделей:
· наглядность;
· модели позволяют проектировать базы данных с большим количеством объектов и атрибутов;
Основные элементы ER-моделей:
· объекты (сущности);
· атрибуты объектов;
· связи между объектами.
Сущность - объект предметной области, имеющий атрибуты.
Связь между сущностями характеризуется:
· типом связи (1:1, 1:N, N:М);
· классом принадлежности. Класс может быть обязательным и необязательным. Если каждый экземпляр сущности участвует в связи, то класс принадлежности - обязательный, иначе - необязательный.
В данном дипломном проекте ER-модель реализована в системе автоматизированного проектирования баз данных ERWin, и изображена на рисунке №2.3.
Рисунок №2.3. Инфологическая модель
Даталогическая модель
Даталогическая модель это отображение логических связей между элементами данных безотносительно их содержанию и среде хранения. Эта модель базируется на языке описания данных (ЯОД), используемом в той конкретной СУБД, в среде которой проектируется БД. Этап создания даталогической модели называется даталогическим проектированием. Описание логической структуры БД на языке СУБД называется даталогической схемой базы данных.
При проектировании логической структуры БД осуществляется преобразование исходной инфологической модели в модель данных, поддерживаемую конкретной СУБД, и проверка адекватности полученной даталогической модели отображаемой предметной области.
Даталогическая модель отображает логические связи между информационными данными в данной концептуальной модели. При переходе от инфологической модели к даталогической следует иметь в виду, что инфологическая модель включает в себя всю информацию о предметной области, необходимую и достаточную для проектирования БД. Даталогическая модель базы данных менеджера по продукции представлена на рисунке №2.3.

Рисунок №2.3. Даталогическая модель.
Программное обеспечение задачи (комплекса задач)
Общие положения (дерево функций и сценарий диалога)
Дерево функций представляет собой схему, в которой отображаются все возможные функции и опции, которые можно выполнять в программе с входящими, исходящими документами, а также дополнительные возможности по настройке системы автоматизации менеджера по продукции. Схематично дерево функций изображено на рисунке № 2.4.
Схема сценариев диалога представляет собой пути диалога пользователя программы с самим программным продуктом. В данной схеме отображается то, как пользователь может дойти до определённого документа или вызвать требуемую функцию. Схема сценариев диалога изображена на рисунке № 2.5.
3 Описание базы данных
Особую значимость для подсистемы составляют базы данных
База данных АИС – совокупность файлов, документов, показателей, данных, упорядоченных по определенным признакам, имеющим общие принципы описания, хранения и манипулирования данными, а также обеспечивающих их независимость от прикладных программ. В базе данных АИС может быть представлена не только экономическая, но и правовая, научная, техническая и другая информация. В основе классификации базы данных могут быть положены различные основания деления. В большинстве случаев выбор оснований систематизации базы данных определяется конкретными условиями работы предприятия и характером функциональных и информационных задач.
По форме представления данных различаются одноконтурные и многоконтурные базы данных. Основная форма представления базы данных двухконтурная. Могут быть и трехконтурные базы данных, когда третий контур представлен и сохраняется на традиционных бумажных документах. БД АИС четвертого контура может быть представлена в форме микрофильмированной ленты и ее отдельных отрезков.
По характеру содержащейся информации различают фактографические, документальные и смешанные базы данных. Фактографическая база данных отображает конкретные сведения, необходимые пользователю – факты, показатели, свойства продукции, формулы расчета какой-либо величины, отрывок (фрагмент) текста документа, документ полностью и др. Документальная БД содержит только сведения о документах – библиографическое описание документа, аннотацию, реферат, идентификатор документа, адрес его хранения в БД и т.д. Сам документ, как правило, во внешнем контуре БД – шкафу, хранилище, библиотеке-депозитарии. В документальных БД по массиву первого контура проводится поиск адреса хранения полного текста документа, а затем по адресу осуществляется доступ и к самому документу.
В смешанных БД представлены как фотографические, так и документальные массивы информации.
БД имеют определенные способы построения, так называемые модели баз данных: иерархические, сетевые, реляционные и объектно-ориентированные.
Иерархическая модель БД построена по принципу древовидного графа, в котором информационные элементы представлены по уровням их соподчиненности (иерархии). В структуре иерархии каждый порожденный узел не может иметь более одного порождающего (выходного) узла. Корень дерева здесь не порожденный, а порождающий узел. Узлы, не имеющие выхода, носят названия листьев. При поиске необходимых данных происходит чтение записей от корня к листьям дерева, т.е. сверху вниз. Достоинством стало то, что подобная структура БД обеспечивает более быстрый доступ и выдачу данных пользователю. Вместе с тем, недостатком представляется жесткость иерархической структуры. Отсутствует информационная гибкость в поиске, так как за один проход невозможно получить данные. В иерархической модели реализована связь между данными по схеме «один-ко-многим».
Сетевая модель БД имеет независимые типы данных, т.е. «Конкуренты», и зависимые типы данных – продукция и цены на продукцию. В сетевых моделях возможны как прямые, так и обратные виды связей между данными (записями). Существует ограничение – каждая связь должна включать в себя основную и зависимую записи. К достоинству сетевой модели можно отнести гибкость организации и доступа к данным относительно иерархической модели. Как недостаток можно указать, что сохраняется относительная жесткость в построении структуры БД. Это влечет необходимость в определенных ситуациях реструктурирования БД, препятствует реализации более гибкой стратегии поиска данных.
Реляционная модель БД имеет независимую организацию взаимосвязи логических и физических записей. Отношения между данными построены в виде двухмерных таблиц и наделены определенными признаками. Каждый элемент таблицы отображает одно данное. Элементы столбца таблицы имеют одинаковую природу, отображая одно свойство (признак) в строке (записи)таблицы.
Объектно-ориентированная модель БД – пример реализации БД более высокого логического уровня. ООБД возникли на концептуальной основе ООП. В отличие от структурного, ООП базируется на процедурных (программных) категориях (циклы, декларации, условия и др.), а на более широкой категории – объектах.
Организация ООБД имеет несколько стадий:
1) концептуальная модель, когда множество объектов БД прошли описание по соответствующим правилам;
2) логическая модель, когда определены свойства объектов и указаны логические взаимосвязи между объектами;
3) физическая модель, когда определены адреса и проведено размещение объектов в памяти ЭВМ
В структуру БД АИС входят различные компоненты – агрегаты, массивы, файлы и др. Агрегат – структурированная совокупность информационных объектов, определяемая как единый тип данных.
Массив информации – это поименованная совокупность однотипных (логически однородных) элементов, упорядоченных по индексам, которые определяют положение элементов в массиве
Файл – опорный структурный элемент БД Файл – поименованная область внешней памяти ЭВМ. Он может содержать различную информацию: текстовый документ, рисунок, музыкальное произведение, программу ЭВМ и др..




Расчета премии. Рис. 3.4 – Диаграмма IDEF3. Основные элементы модели представлены в таблицах 3.4 – 3.6. Таблица 3.4. Основные элементы модели Название проекта: Проектирование ИС для расчета оплаты труда в торговле Цель проекта: реализация структурной функциональной модели ИС Технология моделирования: метод описания бизнес-процессов IDEF3 Инструментарий: программный продукт BPwin ...





Начисленные в текущем месяце – ОПВ за текущий месяц – Сумма ИПН, подлежащая удержанию. ЗАКЛЮЧЕНИЕ В данной дипломной работе, при проектировании информационной системы «Начисление заработной платы сотрудникам школы» были рассмотрены принципы проектирования концептуальной модели, логической модели и были рассмотрены основные причины, по которым данный выбор программного обеспечения Delphi был...





Рисунок 5 – Диаграмма классов 3 Описание проблем и формирование концепции информационной системы 3.1 Проблемы предметной области После проведения исследования предметной области были выявлены следующие проблемы: − с увеличением количества пациентов сети поликлиник, увеличивается количество информационных потоков, что приводит к снижению управляемости...
Информационных технологий на деятельность организации. 2. Создание логической модели ЕСВ Нашей первой задачей является создание логической модели информационной системы единой среды взаимодействия студентов для образования полноценного научно-образовательного сообщества. Основным концептуальным понятием общей модели системы мы выбрали процессы. Процессы: · учебная работа · научная...
База данных составлялась на основе реляционной системы. Реляционная модель данных основывается на математических принципах, вытекающих непосредственно из теории множеств и логики предикатов. Эти принципы впервые были применены в области моделирования данных в конце 1960-х гг. доктором Е.Ф. Коддом, в то время работавшим в IBM, а впервые опубликованы - в 1970 г.
Техническая статья «Реляционная модель данных для больших разделяемых банков данных» доктора Е.Ф. Кодда, опубликованная в 1970 г., является родоначальницей современной теории реляционных БД. Доктор Кодд определил 13 правил реляционной модели (которые называют 12 правилами Кодда).
- 12 правил Кодда:
- 1. Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности.
- 2. Информационное правило - вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться строго как значения в таблицах.
- 3. Гарантированный доступ - любое значение в реляционной БД должно быть гарантированно доступно для использования через комбинацию имени таблицы, значения первичного ключа и имени столбца
- 4. Поддержка пустых значений (null value) - СУБД должна уметь работать с пустыми значениями (неизвестными или неиспользованными значениями), в отличие от значений по умолчанию и независимо для любых доменов.
- 5. Онлайновый реляционный каталог - описание БД и ее содержания должны быть представлены на логическом уровне как таблицы, к которым можно применять запросы, используя язык базы данных.
- 6. Исчерпывающий язык управления данными - по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть всеобъемлющим. Он должен поддерживать описание структуры данных и манипулирование ими, правила целостности, авторизацию и транзакции.
- 7. Правило обновления представлений (views) - все представления, теоретически обновляемые, могут быть обновлены через систему.
- 8. Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных, но и вставку, обновление и удаление
- 9. Физическая независимость данных - на программы-приложения и специальные программы логически не влияют изменения физических методов доступа к данным и структур хранилищ данных.
- 10. Логическая независимость данных - на программы-приложения и специальные программы логически не влияют, в пределах разумного, изменения структур таблиц.
- 11. Независимость целостности - язык БД должен быть способен определять правила целостности. Они должны сохраняться в онлайновом справочнике, и не должно существовать способа их обойти.
- 12. Независимость распределения - на программы-приложения и специальные программы логически не влияет, первый раз используются данные или повторно.
- 13. Неподрывность - невозможность обойти правила целостности, определенные через язык базы данных, использованием языков низкого уровня
Кодд предложил применение реляционной алгебры в СУРБД, для расчленения данных в связанные наборы. Он организовал свою систему БД вокруг концепции, основанной на наборах данных.
В реляционной модели данные разбиваются на наборы, которые составляют табличную структуру. Эта структура таблиц состоит из индивидуальных элементов данных, называемых полями. Одиночный набор или группа полей известна как запись.
Модель данных, или концептуальное описание предметной области - самый абстрактный уровень проектирования баз данных.
С точки зрения теории реляционных БД, основные принципы реляционной модели на концептуальном уровне можно сформулировать следующим образом:
- 1. все данные представляются в виде упорядоченной структуры, определенной в виде строк и столбцов и называемой отношением;
- 2. все значения являются скалярами. Это означает, что для любой строки и столбца любого отношения существует одно и только одно значение;
- 3. все операции выполняются над целым отношением, и результатом их выполнения также является целое отношение. Этот принцип называется замыканием
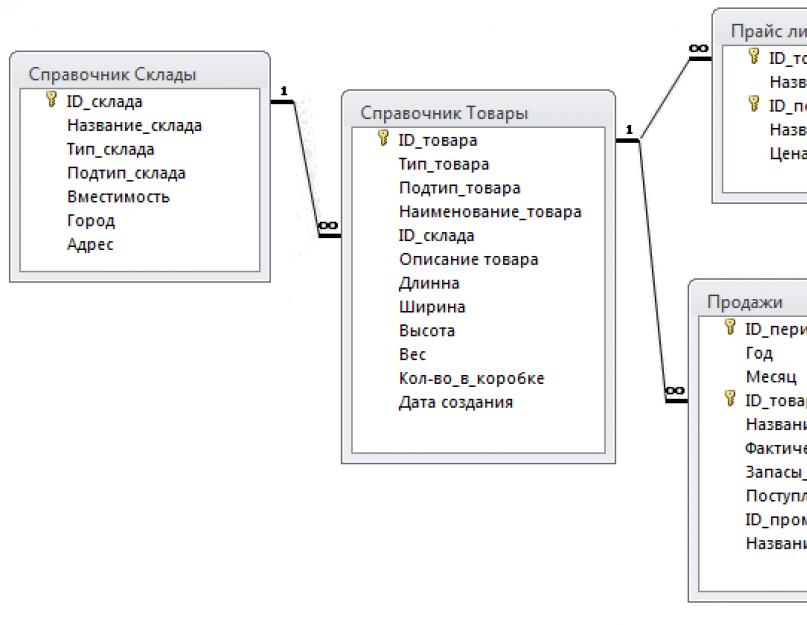
Реляционная БД на физическом уровне состоит из таблиц, между которыми могут существовать связи по ключевым значениям. Одновременно с таблицами и информацией о связях в реляционной базе данных могут присутствовать «хранимые процедуры» и, в частности, «триггеры», обеспечивающие соблюдение условий ссылочной целостности базы. База данных, содержащая информацию о проектной организации состоит из нескольких таблиц. Таблица, содержащая информацию о заключенных договорах называется dogovor и содержит следующий список полей:
- · D_id - № по порядку
- · D_name - № договора
- · Stoimost - стоимость договора
- · Obor - оборудование
- · Data_zakl - дата заключения договора
- · Srok_deistv - срок действия договора
Таблица dogovor_dop - дополнительная информация по договорам:
- · P_name - №-ра проектов
- · Zakazchik - заказчик
- · Rukovoditel - руководитель договора
- · Ispolnitel - исполнители договора
Таблица proekt:
- · P_name - № проекта
- · Stoimost - стоимость
- · Data - дата исполнения проекта
Таблица proekt_dop:
- · P_name - № проекта
- · D_name - №-ра договоров
- · Zakazchik - заказчик
- · Rukovoditel - руководитель проекта
- · Ispolnitel - исполнители проекта
Таблица obor:
- · Otdel_id - № отдела
- · Ob_name - название оборудования
- · P_name - №-ра проектов
- · Data - дата эксплуатации
Таблица otdel_dop:
- · Otdel_id - № отдела
- · Prinadlegn - принадлежность отделу
- · Ispolzovanie - пользование отделом
Таблица otdel_dop:
- · Otdel - название отдела
- · Dolznost - должность
- · Familia - фамилия
- · Name - имя
- · Otchestvo - отчество
- · God_rozden - год рождения
- · Zarplata - заработная плата
Таблица kontragenti:
- · Kg_name - название организации
- · Specifik - спецификация
- · Adres - адрес
- · Tel - телефон
- · Bank_rekv - банковские реквизиты
База данных – это совокупность структурированных и взаимосвязанных данных, относящихся к определенной предметной области.
Для создания, хранения, обработки и коллективного использования информации применяются специальные программные системы, называемые системами управления базами данных (СУБД).
К основным функциям СУБД относятся следующие:
· физическое размещение в памяти данных и их описаний;
· поддержка баз данных в актуальном состоянии;
· механизмы поиска запрашиваемых данных;
· доступ к данным при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
· способы обеспечения защиты данных от некорректных обновлений и/или несанкционированного доступа.
Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры.
Тщательное проектирование базы данных – первый и очень важный шаг создания базы. Он позволяет избежать затрат, связанных с внесением исправлений в структуру хранящихся данных. Проектирование базы данных начинается с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). На этапе проектирования выявляются объекты информации и их характеристики, определяются виды данных, требующие регулярного обновления, и способы представления информации на экране и в отчетах, формулируются вопросы, на которые необходимо регулярно отвечать при поиске данных. Это помогает конкретизировать требования к хранимой информации. В любой момент можно изменить структуру хранящейся в базе информации, подкорректировав структуру таблиц и, соответственно, форм и отчетов. За проектирование и поддержку базы данных отвечает администратор базы данных (АБД).
СУБД использует следующие модели и описания:
· инфологическую;
· даталогическую;
· физическую.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ.
Первоначально создается обобщенное неформальное описание создаваемой базы данных. Это описание называют инфологической моделью данных, и оно выполняется с использованием естественного языка, блок-схем, математических формул, таблиц, графиков и других средств. Инфологическая модель отражает предметную область, для которой проектируется база данных, и полностью независима от физических параметров среды хранения данных. Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты). Инфологическая модель не должна изменяться до тех пор, пока изменения в реальном мире не повлекут за собой изменения предметной области и, следовательно, изменения в модели.
Описание, создаваемое разработчиками базы данных по инфологической модели данных, называют даталогической моделью данных. Конечным результатом даталогического проектирования является описание логической структуры базы данных на ЯОД – языке описания данных конкретной СУБД. При создании даталогической модели данных обеспечивается однозначное соответствие между конструкциями языка описания данных и графическими обозначениями информационных единиц и связей между ними.
В основе каждой СУБД лежит концепция модели данных, то есть некоторой абстракции представления данных. Изначально были успешными две конкурирующие модели – иерархическая и сетевая. Иерархическая БД состоит из упорядоченного набора деревьев. Корпорация IBM разработала и внедрила язык описания данных DL/I (Data Language One), который моделировал данные в иерархической форме (представление данных в форме деревьев). Эта модель была разработана совместно с промышленными предприятиями и предназначалась для хранения и поддержки данных, которые иерархически связаны между собой, например, сметы материалов и списки деталей. Типичным представителем иерархической СУБД является СУБД IMS (Information Management System) компании IBM, первая версия которой появилась в 1968 г.
На рис.8.1 показан пример схемы иерархической БД. Тип записи ФАКУЛЬТЕТ является предком (родительской или исходной записью) для типов записей КАФЕДРЫ и ДЕКАНАТ, а записи КАФЕДРЫ и ДЕКАНАТ – потомки (дочерние или порожденные записи) для записи ФАКУЛЬТЕТ.
Все экземпляры определенного типа порожденной записи, относящиеся к одному экземпляру исходной записи, называются близнецами. Иерархическая модель реализует отношение между исходной и дочерними записями по схеме один-ко-многим., то есть одной родительской записи может соответствовать любое число дочерних. В иерархической базе данных существует единственный иерархический путь доступа к любой записи, начиная с корня дерева, т.е. порядок обхода дерева – сверху-вниз, слева-направо. По сути иерархическая модель – ориентированный граф.
Рис. 8.1. Схема иерархической модели базы данных
В терминологии IMS вместо термина "запись" использовался термин "сегмент", а под термином "запись базы данных" понималось все дерево сегментов. В 1970 году группа CODASYL, которая разрабатывала стандарты для языка COBOL, создала модель под названием DBTG (Data Base Task Group, группа задач базы данных). Модель DBTG была готова к представлению как иерархических, так и сетевых данных. Однако эта модель была очень сложной, поэтому не имела большого успеха.
Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. Сетевой подход к организации данных является расширением иерархического подхода. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование. В сетевой модели допускается несколько исходных записей для одной порожденной записи наряду с возможностью наличия записей без исходной записи (рис.8.2). Другими словами, в сетевой модели любая запись может участвовать в нескольких отношениях предок-потомок. Сетевая модель – неориентированный граф.

Рис. 8.2. Схема сетевой модели базы данных
Большинство применяемых сегодня баз данных основаны на реляционной модели. Основная идея реляционной модели – представить произвольную структуру данных в виде двумерных таблиц. Наиболее распространенной в настоящее время настольной реляционной базой данных является MS Access, пример которой рассматривается в разделе 6.3.3.
Реляционная модель впервые была предложена Э.Ф. Коддом (E.F. Codd) в 1970 году. Понятие модели данных, введенное Коддом, впоследствии развил Кристофер Дейт. Согласно Дейту, реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части. Данные хранятся в таблицах. Столбцы таблиц называются полями, а строки – записями. В каждом поле может храниться информация только одного типа. Запросы предназначены для манипулирования данными, содержащимися в базе данных.
Кодд определил правила реляционной модели, которые получили название "12 правил Кодда". Позже Кодд добавил "нулевое" правило.
1. Реляционная СУБД должна быть способна полностью управлять базой данных, используя связи между данными.
2. Информационное правило: вся информация в реляционной БД, включая имена таблиц и столбцов, должна определяться строго как значения таблиц.
3. Гарантированный доступ: любое значение БД должно быть гарантированно доступным через комбинацию имени таблицы, первичный ключ и имя столбца.
4. Поддержка нулевого значения: СУБД должна уметь работать с нулевыми (пустыми) значениями. Нулевое значение – это неизвестное, независимое, неприменимое значение, в отличие от значений по умолчанию и обычных значений.
5. Активный, оперативный реляционный каталог – описание БД и ее содержимое – должны быть определены на логическом уровне через таблицы, к которым можно применять запросы, используя DML (Data Manipulation Language – язык манипулирования данными).
6. Исчерпывающее подмножество языка данных: по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть самодостаточным. Он должен поддерживать определение данных и манипулирование ими, правила целостности, авторизацию и транзакции.
7. Правило обновления представлений: все представления, теоретически обновляемые, могут быть обновлены через систему.
8. Вставка, обновление и удаление: СУБД поддерживает не только запрос данных, но и вставку, обновление и удаление.
9. Физическая независимость данных: логика программ-приложений остается прежней при изменении физических методов доступа к данным и структур хранения.
10. Логическая независимость данных: логика программ-приложений остается прежней, в пределах разумного, при изменении структур таблиц.
11. Независимость целостности: язык БД должен быть способен определять ограничения целостности. Они должны быть доступны из оперативного каталога, и не должно быть способа их обойти.
12. Независимость распределения: перенос базы данных с одного компьютера на другой компьютер не должен оказывать влияния на запросы программ-приложений. Реляционная СУБД не должна зависеть от потребностей конкретного клиента.
13. Согласованность языков всех уровней: низкоуровневый язык доступа к данным не должен игнорировать правила безопасности и целостности, поддерживаемые языком более высокого уровня.
Предложив реляционную модель данных, Э.Ф. Кодд создал и инструмент для удобной работы с отношениями – реляционную алгебру – формальную систему манипулирования отношениями, основными операциями которой являются проекция, соединение, пересечение и объединение.
Реляционное исчисление – это еще одна формальная система, которая манипулирует отношениями. Реляционное исчисление основано на логике первого порядка. Так же как и выражения реляционной алгебры, формулы реляционного исчисления определяются над отношениями реляционных баз данных, и результатом вычисления также является отношение.
Реляционная алгебра и реляционное исчисление имеют одинаковую выражающую мощность; т. е. все запросы, которые можно сформулировать с помощью реляционной алгебры, могут быть также сформулированы с помощью реляционного исчисления и наоборот. Первым это доказал Э. Ф. Кодд в 1972 году. Это доказательство основано на алгоритме, по которому произвольное выражение реляционного исчисления может быть сокращено до семантически эквивалентного выражения реляционной алгебры. Алгоритм носит название "алгоритм редукции Кодда".
Реляционные базы данных имеют следующие специфические особенности.
· Для каждого поля таблицы базы данных определен тип данных, таким образом нельзя в одно поле разных записей вводить данные разных типов.
· СУБД позволяют не только вводить данные в таблицы, но и контролировать правильность вводимых данных. Имеются в виду не только ограничения по типу данных, но и контроль допустимых значений, количество вводимых знаков и т.п. СУБД не позволит сохранить в записи те данные, которые не удовлетворяют заданным правилам.
· Таблицы баз данных могут включать в себя количество записей, исчисляемое сотнями тысяч, и при этом СУБД обеспечивает удобные способы извлечения нужной информации из этого множества записей.
· Все данные хранятся, независимо от их структуры и содержания, в одном файле, и доступ к этим данным осуществляется постранично, не превышая ограничений на ресурсы компьютера.
· Можно устанавливать связи между таблицами и затем при помощи запросов совместно использовать данные разных таблиц. Данные, полученные в результате запроса, представляются также в виде таблицы.
· Запрос на выборку может быть обращен к одной или нескольким таблицам одновременно. Данные в выборке являются динамическими, т. е. при повторном запуске запроса по измененным данным, выборка изменяется.
· Благодаря установке взаимосвязей между отдельными таблицами удается избежать ненужного дублирования данных, сэкономить память компьютера, а также увеличить скорость обработки информации.
· Большинство баз данных может поддерживать одновременную работу с базой данных нескольких пользователей, при этом все пользователи гарантированно будут работать с актуальными данными.
· По сравнению с другими прикладными пакетами в базах данных имеется развитая система защиты от несанкционированного доступа, которая предоставляет, помимо парольной защиты файла, возможность каждому пользователю или группе пользователей видеть и изменять только те объекты, к которым пользователи имеют право доступа.
При проектировании реляционной базы данных большое внимание уделяется процессу нормализации таблиц. Целью нормализации является создание такого проекта базы данных, где будет исключена избыточность информации, т. е. каждый квант информации будет сохраняться лишь в одном месте. Основное назначение нормализации – исключение возможной противоречивости хранимых данных и экономия памяти. Пренебрежение нормализацией делает структуру базы данных запутанной, а саму базу – ненадежной в работе.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
Поле А многозначно определяет поле В той же таблицы, если для каждого значения поля А существует определенное множество соответствующих значений В.
Процесс нормализации представляет собой последовательное преобразование исходной БД к нормализованной базе данных путем поэтапного приведения таблиц к нормальным формам (НФ). При этом каждая следующая НФ обязательно включает в себя предыдущую, что позволяет разбить процесс на этапы и производить его однократно, не возвращаясь к предыдущим этапам. Всего в реляционной теории насчитывается 6 нормальных форм: первая нормальная форма (1НФ), вторая нормальная форма (2НФ), третья нормальная форма (3НФ), нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ) и пятая нормальная форма (5НФ).
По существу, таблица находится в 2НФ, если она находится в 1НФ и удовлетворяет, кроме того, некоторым дополнительным условиям. Таблица находится в 3НФ, если она находится в 2НФ и, помимо этого, удовлетворяет другим дополнительным условиям и т.д.
Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом.
Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и ни одно из ее неключевых полей не зависит функционально от любого другого неключевого поля.
Кодд и Бойс обосновали и предложили более строгое определение для 3НФ, которое учитывает, что в таблице может быть несколько ключей. Таблица находится в нормальной форме Бойса-Кодда (НФБК), если и только если любая функциональная зависимость между ее полями сводится к полной функциональной зависимости от возможного ключа.
В следующих нормальных формах (4НФ и 5НФ) учитываются не только функциональные, но и многозначные зависимости между полями таблицы.
В настоящее время практически каждый производитель СУБД предлагает собственный программный продукт автоматизированного проектирования. Это Oracle Designer (Oracle), Power Desinger (Sybase) и другие. Демонстрационные версии данных программных продуктов можно загрузить с соответствующих сайтов (www.oracle.com, www.sybase.com). Кроме того, для автоматизированного проектирования представлены решения фирм, не производящих СУБД. Наиболее распространенными являются программные продукты фирмы AllFusion – AllFusion ERwin Data Modeler и AllFusion Process Modeler (ранее – BPwin) (см. www.interface.ru).
Реляционные языки обеспечивают типовые операции по обработке реляционных таблиц, позволяют формулировать логические условия, используемые в операциях выборки, проверку целостности (непротиворечивости) данных взаимосвязанных таблиц. Они оперируют с данными как со множествами, применяя к ним основные операции теории множеств. На входе реляционного оператора – множество записей одной или нескольких реляционных таблиц, на выходе – множество записей новой реляционной таблицы. Реляционные языки имеют различный уровень процедурности – содержание и последовательность перехода от входных данных к выходным.
Выделяют следующие разновидности языков реляционной алгебры:
· dBASe-подобные языки приближены к языкам структурного программирования. Эти языки обеспечивают создание интерфейса пользователя и типовые операции обработки данных;
· графические реляционные языки, ориентированные на конечных пользователей;
· SQL-подобные языки запросов, реализованные в большинстве многопользовательских и распределенных систем управления базами данных.
dBASe-подобные языки используют базы данных dBASe, Paradox, FoxPro, Clipper, Rbase и др.
Типичным представителем графического реляционного языка является язык QBE (Query By Example), реализованный в среде электронных таблиц, в различных базах данных, например, в MS Access, в пакете Microsoft Query. Этот язык относится к языкам манипулирования данными и имеет простейшие синтаксические конструкции, легко осваиваемые пользователями-непрограммистами.
SQL (Structured Query Language) применяется при работе с реляционными базами данных в современных СУБД (ORACLE, dBASE IY, dBASE Y, Paradox, Access и др.). Для отдельных СУБД синтаксис версий языка SQL может различаться.
Язык SQL стал стандартом языков запросов для работы с реляционными базами данных архитектуры "файл-сервер" и "клиент-сервер" и для управления распределенными базами данных. Это реляционно полный язык, предназначенный для работы с базами данных, создания запросов на выборку данных, для выполнения вычислений, для обеспечения целостности баз данных.