Здравствуйте, уважаемые читатели блога сайт. При изучении механизма, отвечающего за корректное функционирование сети интернет, никуда не уйти от необходимости уделить время его основным аспектам, в число коих, вне всякого сомнения, входит протокол передачи данных HTTP и его безопасная версия HTTPS.
Основой работы этого инструмента, позволяющего браузеру пользователя открывать нужные файлы и документы для получения информации, является технология «клиент-сервер», подробности которой рассмотрим в этой статье чуть ниже.
Конечно, тем, кто желает по-настоящему посвятить свою деятельность работе с компьютерными сетями и разработке сетевых программ, необходимо изучить этот вопрос по максимуму для получения соответствующей квалификации. Но нам это не требуется.
Главное — понять, что представляет из себя HTTP в общих чертах и каковы главные особенности HTTPS, а также постичь базовые принципы, которые в них заложены. Подобные знания будут полезны в том числе для для оптимизации и продвижения вашего сайта, этому вы получите безусловное подтверждение из этой и последующих статей, посвященных данной теме.
Что такое HTTP и как он работает?
Чтобы получить нужный документ в интернете, пользователю достаточно ввести в поисковую строку браузера нужный URL-адрес ( о структуре урлов подробности), который как раз содержит название протокола HTTP (или HTTPS).
3. HTTP/Версия — указывается действующая модификация протокола. На данный момент это HTTP 1.1 (вы можете ознакомиться с ее спецификацией). Однако, в черновом виде уже существует следующая версия протокола 2.0, который основан на .
Нижняя строка представляет собой заголовок Host в составе HTTP-запроса, отсылаемого браузером серверу в соответствии с полученным от ДНС IP. Для чего это надо? Для идентификации нужного сайта, поскольку на вебсерверах обычно расположен не один ресурс.
Разберем наглядный пример для закрепления пройденного. Скажем, браузер получил "задание" от пользователя отобразить страничку вот с таким адресом:
Http://subscribe.ru/group/
Тогда HTTP-запрос посредством метода GET может быть составлен следующим образом (в этом случае обычно тело сообщения отсутствует):
GET /group/ HTTP/1.1 Host: subscribe.ru
Для наглядности я предоставил лишь самый простой пример, включающий один заголовок Host, на самом деле, их может быть несколько. Но это не все. Ведь для полноценного общения необходим диалог, который и устанавливается после того, как на запрос браузера сервер дает ответ. Начальную строку ответа тоже можно изобразить схематически:
HTTP/Версия Код состояния Пояснение
Теперь пробежимся вкратце и по составу ответа сервера:
1. Версия HTTP указывается по аналогии с запросом.
2. Код состояния (Status Code) — три цифры, информирующие о том, каков статус документа, запрошенного браузером. Например, 200 — ОК, страница существует и будет отображена в браузере, 301 — осуществлен (перенаправление) на другой урл, — вебстранички по такому адресу нет (возможно, она удалена либо юзер ошибся при вводе URL).
3. Пояснение (Reason Phrase) — текст дополнения к коду ответа. В некоторых случаях пояснение может отличаться от стандартного либо отсутствовать вовсе. Это связано в том числе с настройкой ПО, размещенного на сервере.
Реальный пример? Пожалуйста. Попробуем получить ответ сервера на запрос, приведенный мною в качестве примера выше (урл «http://subscribe.ru/group/»). Он будет выглядеть так (начальная строка с заголовками):
HTTP/1.1 200 OK Server: nginx Date: Sat, 10 Jun 2017 06:36:38 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Content-Language: ru Set-Cookie: Subscribe::Viziter=UQkivlk7k3YO3DgjAxM2Ag==; expires=Thu, 31-Dec-37 23:55:55 GMT; domain=subscribe.ru; path=/ P3P: policyref="/w3c/p3p.xml", CP="NOI PSA OUR BUS UNI"
В данном случае отсутствуют пояснение и тело сообщения, которое при использовании метода GET может содержать, например, HTML-код запрашиваемого документа (веб-странички). В зависимости от типа приложения клиента эти разделы могут присутствовать.
Итак, резюмируем вкратце выше изложенное. Если пользователь вводит урл искомой страницы, имея ввиду получить ее содержимое для просмотра, браузер посылает GET запрос на нужный сервер и получает ответ. В результате этого общения либо (при благоприятных обстоятельствах) контент запрошенного документа будет отображен, либо нет.
В любом случае, по содержанию HTTP-ответа сервера (включая код состояния) можно получить полезную информацию, связанную с запрашиваемым документом.
Для того, чтобы выше предложенная информация без усилий ложилась в пазл, не хватает конкретного примера. Его мы рассмотрим с помощью одного из (именно этот веб-обозреватель является моим рабочим инструментом), именуемого HTTP Headers.
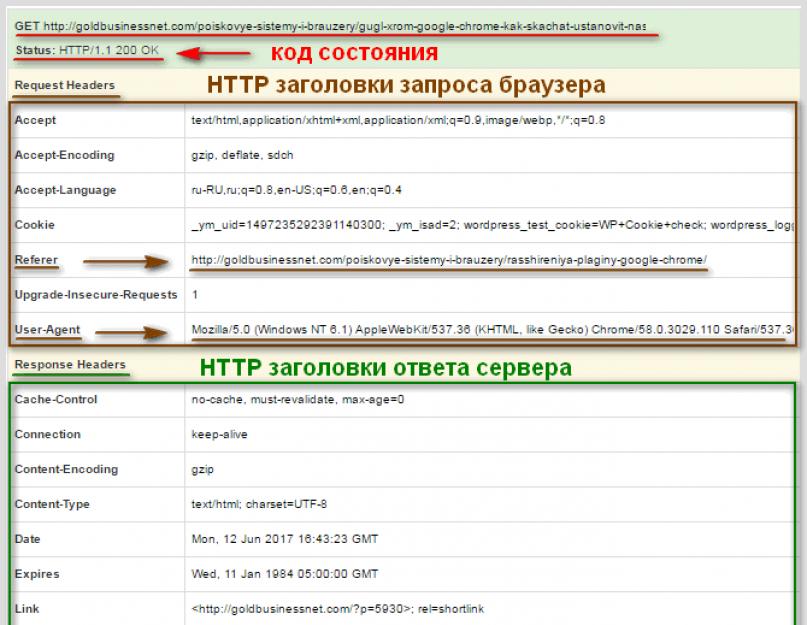
Он удобен тем, что дает полную картину взаимодействия «клиент-сервер», предоставляя в "одном флаконе" содержание HTTP запроса (request) и ответа (response) . Посмотрите, какой документ выдал этот плагин при переходе по ссылке с одной страницы моего блога на другую:

Здесь в самом верху отмечен метод GET, с помощью которого браузер обращается к серверу, а также статус странички, отмеченный кодом состояния 200 OK, который дает понять, что сервер передал все данные в отношении запрашиваемой вебстраницы.
Интерес вызывают также HTTP Headers (заголовки) , отображенные ниже. Например, пункт «Referer» дает информацию в виде урла, откуда был осуществлен переход.
Заголовок «User Agent» отражает как раз клиентское приложение, отправившее запрос вебсерверу. В данном случае это браузер, но могут быть и другие (мобильные устройства, поисковые роботы и т.д.). Данные, представленные в Юзер Агенте, необходимы серверному программному обеспечению для идентификации приложения, посылающего запрос.
Как раз боты поисковых систем , сканирующие страницы сайтов для получения информации, влияющей на ранжирование, нас и интересуют в первую очередь, потому как именно они решают судьбу той или иной страницы в плане эффективности ее продвижения.
Вот потому-то в следующей публикации я планирую поподробнее остановится на том, как просмотреть HTTP-заголовки и проверить коды ответов сервера именно на запрос робота, что исключительно важно для вебмастеров в свете SEO оптимизации ресурса. Поэтому оформляйте подписку , чтобы своевременно получить свежую статью.
В чем особенность безопасного протокола HTTPS?
Уверен, всем без исключения пользователям интернета, включая начинающих, известно о существовании особого протокола HTTPS (Hypertext Transfer Protocol Secure), который служит для защиты персональных данных на сервисах, где используется их передача (платежные системы, интернет магазины, крупные специализированные порталы и т.д.).
Если ввести адрес страницы какого-нибудь подобного сайта, то данное соединение будет особым образом обозначено. В Google Chrome (), например, отобразится замочек с надписью «Надёжный» зеленого цвета, при нажатии на который вы увидите некоторую информацию, связанную с защитой личных данных:

Что такое HTTPS? Строго говоря, он не является самостоятельным протоколом. Это стандартный HTTP, который действует через механизмы TLS или SSL , способные гарантировать шифрование, что исключает перехват и получение конфиденциальных данных злоумышленниками.
По умолчанию при работе защищенного протокола применяется порт 443 (если помните, для стандартного HTTP — 80). Для шифрования в HTTPS используется длина ключа в 40, 56, 128 и 256 бит (). Однако, первые два варианта даже не стоит рассматривать, поскольку они не могут обеспечить достаточного уровня безопасности.
В последнее время поисковики, особенно Гугл, активно склоняют владельцев всех сайтов к переходу на защищенный протокол, тонко намекая, что этот момент будет учитываться при ранжировании. В итоге теперь многие ресурсы (даже обычные блоги), а не только сайты, тесно связанные с передачей личных данных, уже работают с HTTPS.
Более того, передовые хостеры предлагают по приобретению безопасного сертификата SSL, который необходим для включения защищенного соединения.
Конечно, мы не рассмотрели все нюансы использования протокола HTTP (HTTPS), коих немало. Эта тема может занять несколько внушительных мануалов. Однако основные аспекты, которые пригодятся как продвинутому пользователю, так и вебмастеру, освещены. Если вы все-таки не удовлетворены объемом полученной информации, то можете с легкостью дополнить ее из ниже следующей видеолекции, где, в частности, подробнее говорится о методах:
Вашему вниманию предлагается описание основных аспектов протокола HTTP - сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP - широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol , «протокол передачи гипертекста». В соответствии со спецификацией OSI , HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616 .
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP - обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных - сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP - это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.Предположим, что он ввёл в адресной строке следующее:
Http://alizar.сайт/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.сайт.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
Telnet alizar.сайт 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод - это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) - по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко - HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок - это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar..ru или m.. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется - и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Теги:
- http
- alizar
- spdy
Основной протокол для страниц в интернете — HTTP. Используется этот протокол каждый раз, когда вы заходите на новый сайт, когда на сайте отображается текст, картинка, когда вы нажимаете ссылки.
Весь интернет основывается на HTTP, пусть большая часть пользователей даже и не подозревают, насколько популярен в их привычной жизни HTTP.
HTTP — протокол, по которому передается гипертекст (HyperText Transfer Protocol).
На этом протоколе строится взаимодействие вашего браузера и сервера с информацией. Благодаря его простоте, браузер и сервер соединяются очень быстро. Но нам не обязательно вникать во все подробности работы протокола, мы объясним лишь базовый принцип его работы.
В Интернете можно пользоваться множеством протоколов, HTTP — лишь один многих, у которого собственные задачи с целями.
Все настолько просто, что вы уже знакомы с программным обеспечением, необходимым для работы с HTTP — это ваш браузер.
Независимо от названия браузера, к адресной строке всегда по умолчанию добавляется название протокола: «http://». Вы можете и не видеть эту надпись, если браузер ее скрывает. Но стоит только скопировать название сайта, вместе с ним в нужном месте вставится и протокол HTTP.
- Что значит приставка «http://» перед названием сайта?
- Это значит, что вы обращаетесь к ресурсу по HTTP протоколу.
Зачем создали протокол HTTP
С его помощью передают гипертекстовые документы, а проще говоря — страницы на нужных нам сайтах.
Принимает веб-страницы клиент (браузер), а отдаёт страницы сервер. Эта технология так и называется — клиент-серверная технология.
Благодаря HTTP стало возможно передавать веб-страницы в интернете. А что же содержится в самих страницах, которые пересылает нам сервер? Обыкновенный HTML-код, который поступает в браузер, которому остается только верно интерпретировать полученную информацию и показать вам готовый сайт.
Еще в 2006 году практически половина HTTP-трафика Северной Америки складывалась из потокового звука и видео.
Как работает HTTP
- Браузер отправляет запрос, запрашивая нужную страницу сервера.
- Сервер получает запрос и начинает искать страницу.
- Браузер получает ответ от сервера с результатами запроса:
- Код запрашиваемой страницы и служебная информация — если страница найдена.
- Код ошибки и служебная информация в случае сбоя.
Когда браузер дает запрос на файл, запрос содержит специальную команду HTTP. Если запрашиваемый файл и правда есть на сервере, файл отправляется. А вот принимающей странице уже стоит решить, показать файл на экране, сохранить на диск или сделать с результатом что-то еще.
Чтобы идентифицировать ресурсы в сети, протокол HTTP пользуется глобальными URI. Отличие HTTP от других протоколов — он не сохраняет свое состояние. То есть не сохраняется состояние между парой «запрос-ответ».
HTTP — это не единственный протокол, который используют в Интернете. Также используются:
- FTP (File Transfer Protocol) — протокол передачи файлов.
- POP (Post Office Protocol) и SMTP (Simple Mail Transport Protocol) — для обмена сообщениями электронной почты.
- SHTTP (Secure Hypertext Transfer Protocol) — шифрованная разновидность HTTP. Информация, которая передается по этому протоколу, кодируется. Обычно безопасность важна в случае обмена конфиденциальными данными.
И другие протоколы, у которых есть одно хорошее свойство — все они работают незаметно для нас с вами.
Март 1991 года — Тим Бернерс-Ли предложил использовать HTTP.
Именно Бернерс-Ли разработал все первое, что связано с Интернетом: браузер, сервер, гиперссылки, первый сайт (info.cern.ch) Как выглядел первый сайт, можно увидеть по ссылке.
Версии HTTP со временем совершенствуются, популярной стала версия HTTP 1.1, которая позволяет на долгое время оставлять открытым соединение сервера с браузером, что сделало протокол более эффективным.
В 2015 году появился HTTP/2, который стал бинарным, изменились способы, которыми информацию разбивали на фрагменты.
Безопасность протокола HTTP
Сам HTTP не подразумевает шифрование информации. Но есть расширение для протокола, которое умеет упаковывать данные в протокол SSL или TLS.
HTTPS (S — Secure) — популярное решение, которое не позволяет перехватывать передаваемую информацию и защитить информацию от MITM- атак «man-in-the-middle» или атака посредника.
MITM по сути испорченный телефон, в котором информация подменяется намеренно. О подмене не знает ни клиент ни сервер.
Из чего состоит HTTP
Мы много упоминали, что сервер и клиент отправляют и получают запросы. Так что же содержится в этих запросах? Каждое сообщение HTTP состоит из трех частей:
- Стартовая строка, которая определяет тип сообщения.
- Заголовки, с помощью которых характеризуют тело сообщения.
- Тело сообщения, где содержатся уже нужные данные.
Благодаря особенностям HTTP, сумели создать поисковые машины, форумы, интернет-магазины. В интернет пришла коммерция, начали появляться интернет провайдеры и другие компании, деятельность которых проходит в сети Интернет. А все благодаря протоколу HTTP, с которым вы теперь хорошо знакомы.
HTTP - это протокол передачи гипертекста между распределёнными системами. По сути, http является фундаментальным элементом современного Web-а. Как уважающие себя веб разработчики, мы должны знать о нём как можно больше.
Давайте взглянем на этот протокол через призму нашей профессии. В первой части пройдёмся по основам, посмотрим на запросы/ответы. В следующей статье разберём уже более детальные фишки, такие как кэширование, обработка подключения и аутентификация.
Также в этой статье я буду, в основном, ссылаться на стандарт RFC 2616 : Hypertext Transfer Protocol -- HTTP/1.1.
Основы HTTP
HTTP обеспечивает общение между множеством хостов и клиентов, а также поддерживает целый ряд сетевых настроек.
В основном, для общения используется TCP/IP, но это не единственный возможный вариант. По умолчанию, TCP/IP использует порт 80, но можно заюзать и другие.
Общение между хостом и клиентом происходит в два этапа: запрос и ответ. Клиент формирует HTTP запрос, в ответ на который сервер даёт ответ (сообщение). Чуть позже, мы более подробно рассмотрим эту схему работы.
Текущая версия протокола HTTP - 1.1, в которой были введены некоторые новые фишки. На мой взгляд, самые важные из них это: поддержка постоянно открытого соединения, новый механизм передачи данных chunked transfer encoding, новые заголовки для кэширования. Что-то из этого мы рассмотрим во второй части данной статьи.
URL
Сердцевиной веб-общения является запрос, который отправляется через Единый указатель ресурсов (URL). Я уверен, что вы уже знаете, что такое URL адрес, однако для полноты картины, решил всё-таки сказать пару слов. Структура URL очень проста и состоит из следующих компонентов:

Протокол может быть как http для обычных соединений, так и https для более безопасного обмена данными. Порт по умолчанию - 80. Далее следует путь к ресурсу на сервере и цепочка параметров.
Методы
С помощью URL, мы определяем точное название хоста, с которым хотим общаться, однако какое действие нам нужно совершить, можно сообщить только с помощью HTTP метода. Конечно же существует несколько видов действий, которые мы можем совершить. В HTTP реализованы самые нужные, подходящие под нужды большинства приложений.
Существующие методы:
GET : получить доступ к существующему ресурсу. В URL перечислена вся необходимая информация, чтобы сервер смог найти и вернуть в качестве ответа искомый ресурс.
POST : используется для создания нового ресурса. POST запрос обычно содержит в себе всю нужную информацию для создания нового ресурса.
PUT : обновить текущий ресурс. PUT запрос содержит обновляемые данные.
DELETE : служит для удаления существующего ресурса.
Данные методы самые популярные и чаще всего используются различными инструментами и фрэймворками. В некоторых случаях, PUT и DELETE запросы отправляются посредством отправки POST, в содержании которого указано действие, которое нужно совершить с ресурсом: создать, обновить или удалить.
Также HTTP поддерживает и другие методы:
HEAD : аналогичен GET. Разница в том, что при данном виде запроса не передаётся сообщение. Сервер получает только заголовки. Используется, к примеру, для того чтобы определить, был ли изменён ресурс.
TRACE : во время передачи запрос проходит через множество точек доступа и прокси серверов, каждый из которых вносит свою информацию: IP, DNS. С помощью данного метода, можно увидеть всю промежуточную информацию.
OPTIONS : используется для определения возможностей сервера, его параметров и конфигурации для конкретного ресурса.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант - это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted : запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content : в теле ответа нет сообщения.
- 205 Reset Content : указание серверу о сбросе представления документа.
- 206 Partial Content : ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently : ресурс теперь можно найти по другому URL адресу.
- 303 See Other : ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified : сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности - Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request : вопрос был сформирован неверно.
- 401 Unauthorized : для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden : сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed : неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict : сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented : сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable : это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.

Давайте посмотрим на структуру передаваемого сообщения через HTTP:
Message =
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
General-header = Cache-Control | Connection | Date | Pragma | Trailer | Transfer-Encoding | Upgrade | Via | Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache - это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.
Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
Entity-header = Allow | Content-Encoding | Content-Language | Content-Length | Content-Location | Content-MD5 | Content-Range | Content-Type | Expires | Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
Формат запроса
Запрос выглядит примерно так:
Request-Line = Method SP URI SP HTTP-Version CRLF Method = "OPTIONS" | "HEAD" | "GET" | "POST" | "PUT" | "DELETE" | "TRACE"
SP - это разделитель между токенами. Версия HTTP указывается в HTTP-Version. Реальный запрос выглядит так:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Список возможных заголовков запроса:
Request-header = Accept | Accept-Charset | Accept-Encoding | Accept-Language | Authorization | Expect | From | Host | If-Match | If-Modified-Since | If-None-Match | If-Range | If-Unmodified-Since | Max-Forwards | Proxy-Authorization | Range | Referer | TE | User-Agent
В заголовке Accept определяется поддерживаемые mime типы, язык, кодировку символов. Заголовки From, Host, Referer и User-Agent содержат информацию о клиенте. Префиксы If- предназначены для создания условий. Если условие не прошло, то возникнет ошибка 304 Not Modified.
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
HTTP/1.1 200 OK
Заголовки ответа могут быть следующими:
Response-header = Accept-Ranges | Age | ETag | Location | Proxy-Authenticate | Retry-After | Server | Vary | WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Инструменты для определения HTTP трафика
Существует множество инструментов для мониторинга HTTP трафика. Вот несколько из них:
Наиболее часто используемый - это Chrome Developers Tools:

Если говорить об отладчике, можно воспользоваться Fiddler :

Для отслеживания HTTP трафика вам потребуется curl, tcpdump и tshark.
Библиотеки для работы с HTTP - jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте .
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({ url: "http://www.articles.com/latest", type: "GET", beforeSend: function (jqXHR) { jqXHR.setRequestHeader("Accepts-Language", "en-US,en"); } });
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({ statusCode: { 404: function() { alert("page not found"); } } });
Итог
Вот такой вот он, тур по основам протокола HTTP. Во второй части будет ещё больше интересных фактов и примеров.
Для World Wide Web. Такие протоколы представляют собой структурированный текст, который использует логические связи (гиперссылки) между узлами, содержащими определенные данные. Таким образом, это способ обмена или передачи гипертекста.
HTTP-протокол работает как функция запрос-ответ в клиентско-серверной модели вычислений. Так, веб-браузер выступает в роли клиента, а хостинг сайта является сервером. Клиент отправляет сообщение запроса HTTP на сервер, предоставляющий определенные ресурсы (например, HTML-файлы и другие материалы), а затем возвращает ответное сообщение. Ответ содержит информацию о запросе, и также может содержать запрошенное содержимое в теле сообщения.
Браузер является основным примером агента пользователя (клиента). Другие типы пользовательских агентов включают в себя программное обеспечение, используемое для индексации поисковыми провайдерами, мобильные приложения и другие ресурсы, которые используют или отображают веб-контент.
HTTP-протокол предназначен для обеспечения промежуточных элементов сети для повышения или обеспечения связи между клиентами и серверами. Сайты с большим трафиком часто извлекают для себя выгоду из кэша веб-серверов, которые отображают контент от имени вышестоящих ресурсов, уменьшая время загрузки. Кэш веб-браузеров при этом позволяет пользователю уменьшить сетевой трафик. Прокси-сервера, которые использует HTTP-протокол в локальной сети, могут обеспечить связь для клиентов, не допускающих глобальную маршрутизацию адреса, путем ретрансляции сообщений с внешних серверов.

Сессия HTTP представляет собой последовательный процесс из запросов и ответов. Клиент инициирует запрос путем создания TCP-подключения к определенному порту на сервере, а последний прослушивает этот порт и ждет сообщение с запросом. При его получении сервер посылает в ответное сообщение. Тело этого сообщения, как правило, представляет собой запрошенный ресурс, хотя может быть отображено и сообщение об ошибке или другая информация.
Если рассматривать назначение протокола HTTP, следует отметить, что он определяет методы с целью указать нужное действие, выполняемое по выявленным ресурсам. При этом вид отображаемой информации (ранее существовавшие данные или генерируемые динамически) зависит от реализации сервера. Часто такой ресурс соответствует файлу или сценарию, расположенному на хостинге.
Некоторые методы, которые использует протокол передачи гипертекста HTTP, предназначены только для поиска информации и при этом не должны изменять состояние сервера. Другими словами, они не оказывают серьезного воздействия, за исключением относительно безвредных эффектов - кэширования или увеличения статистики посещений.

С другой стороны, HTTP-протокол может применять и такие методы, которые предназначены для действий, способных оказать влияние либо на сервер, либо на другие внешние ресурсы - активизировать финансовые операции или выполнить передачу электронной почты. Изредка такие способы используются веб-роботами или некоторыми сайтами и могут делать запросы вне зависимости от основной задачи.