| Представление о базах данных
Уроки 35 - 37
Представление о базах данных
Изучив эту тему, вы узнаете:
Почему понятие «предметная область» играет важную роль при создании баз данных;
- зачем надо заниматься структурированием данных;
- почему таблица является предпочтительной формой представления данных;
- каковы основные понятия базы данных.
Роль информационной системы
В течение многих поколений люди использовали разнообразные способы сохранения и передачи информации. Вначале информация передавалась от поколения к поколению в виде преданий и устных рассказов. Возникновение и развитие книгопечатания позволило передавать и хранить информацию посредством книг. Открытия в области электричества привели к появлению телеграфа, телефона, радио, телевидения, позволяющих оперативно передавать и накапливать информацию.
Развитие прогресса привело к резкому росту потока информации и вопрос сохранения и переработки ее становился все острее и острее. Возникла парадоксальная ситуация: растет информационный голод, обусловленный не недостатком информации, а ее избытком. Все труднее отыскать в информационном изобилии интересующую конкретного пользователя информацию.
С появлением вычислительной техники значительно упростился процесс хранения, а главное - обработки информации. Развитие вычислительной техники на базе микропроцессоров приводит к совершенствованию компьютеров и программного обеспечения. Появляются программы, способные обработать большие потоки информации. С помощью таких программ создаются информационные системы.
Целью любой информационной системы является обработка данных об объектах реального мира и предоставление нужной человеку информации о них. Если мы рассмотрим совокупность некоторых объектов, то можно выделить объекты, которые обладают одинаковыми свойствами. Такие объекты можно объединить в отдельные классы (рыбы, мебель, ученики и т. д.). Внутри выделенного класса объекты можно упорядочивать по определенным признакам, например по алфавиту, или осуществлять выборку по некоторым общим признакам, например по цвету или материалу.
Выборка (группировка) по определенным признакам значительно облегчает поиск и отбор нужной информации.
Например, вы хотите приобрести деревянный компьютерный стол из ореха. Для этого вам необходима информация о том, где продаются такие столы. Получить ее можно различными способами, например:
♦ обойти все мебельные магазины города и найти нужный вам стол;
♦ изучить каталоги по мебели и прайс-листы мебельных магазинов;
♦ обратиться в информационную систему с необходимым запросом.
Очевидно, что первый способ может привести к положительному результату, но для этого понадобится много сил и времени.
Второй способ более оптимистический, так как в этом случае не надо никуда ходить, а достаточно воспользоваться телефоном и обзвонить магазины, торгующие подобной мебелью. Последний способ предполагает обращение в информационную систему, где в разделе Мебель нужно выбрать - Столы, среди столов выбрать Компьютерные, затем - Деревянные, далее рассмотреть Столы из ореха и автоматически соединиться по телефону с соответствующим магазином и отправиться по указанному адресу за покупкой. В нашей ситуации наиболее рациональным, наверное, является третий способ.
Как же организована подобная информационная система и каким образом можно организовать хранение и представление информации в ней?
Информационная система, прежде всего, должна работать с данными конкретной предметной области, для которой должно существовать описание в виде информационной модели. Предметной областью может быть сфера человеческой деятельности: предприятие, школа, поликлиника и пр. Это может быть также область человеческих знаний: биология, география и пр.
Предметную область образует совокупность объектов, которые находятся между собой в определенных отношениях и связях.
Если в качестве примера рассмотреть предметную область Школа, то в этой области можно выделить следующие классы объектов: ученики, учителя, обслуживающий персонал, учебные предметы, помещения и т. д. Между этими объектами существуют определенные отношения и связи.
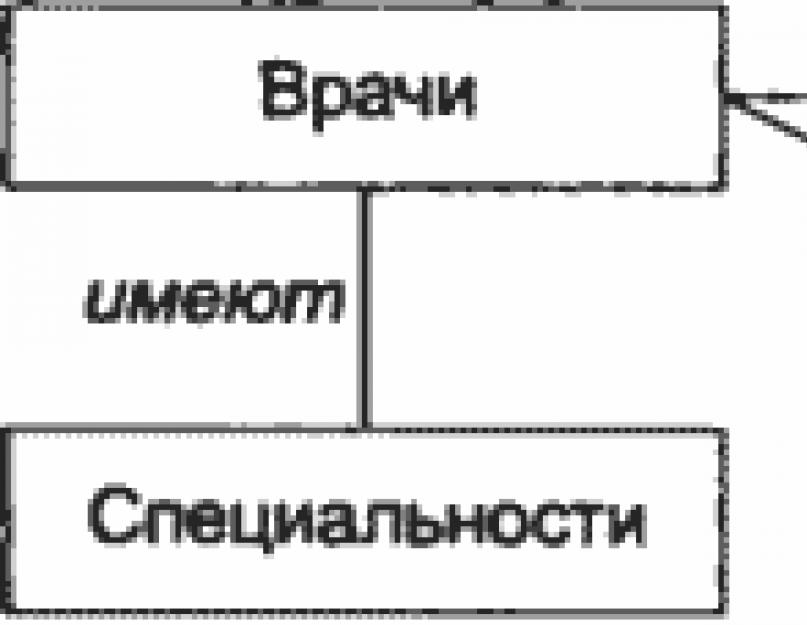
Рассмотрим другой пример. В предметной области Поликлиника можно выделить следующие классы объектов: врачи, пациенты, диагнозы, специальности врачей и пр. Связи между объектами выделенной предметной области отображены на рис. 4.1.

Рис. 4.1. Пример взаимосвязи классов объектов предметной области Поликлиника
Обратимся к другому примеру. Все мы любим песни, и у каждого есть свои любимые песни и исполнители. Было бы желательно иметь возможность обращаться к информационной системе, которая позволяла бы осуществлять хранение, поиск и отбор ваших любимых песен. Очевидно, что подобная информационная система должна иметь в своем составе программы, ориентированные на работу с классами объектов Песня и Исполнитель.
Возникает вопрос: как следует представить информацию об этих объектах?
Можно было бы привести такое описание: песня «Spice up your life» в исполнении группы из Англии «Spice Girls», написанная в стиле «Hip-hop» в 1997 году, или, например, песня 1996 года российской группы «Иванушки International» под названием «Тучи» в стиле «Рор».
В этом описании совместно фиксируются название некоторого параметра и его значение, например: песня (название параметра) «Тучи» (значение параметра). При этом значения параметра - это данные, а название параметра - это смысловая характеристика этих данных. Описать любой класс объектов можно с помощью информационной модели. Для этого необходимо определить, какими параметрами должны характеризоваться объекты данного класса. Например, такими параметрами могут быть: наименование песни, исполнитель, стиль, дата создания, страна. Перечень этих параметров должен определяться поставленной целью, то есть указывать, в чем заключается ваш интерес к песне и ее исполнителю.
Представить такую информацию можно разными способами, например в виде списка:
1. «Spice up your life», «Spice Girls», Hip-hop, 1997, Англия;
2. «Тучи», «Иванушки International», Pop, 1996, Россия;
3. «Моряк», «Агата Кристи», Rock, 1997, Россия.
Работать с информацией, записанной в подобном виде, весьма трудно. Во-первых
, здесь указаны только данные и не описан смысл этих данных. Не каждый может понять, что означают эти данные. Во-вторых
, даже если смысл данных понятен, чтобы найти нужную песню в длинном списке, надо внимательно просмотреть каждую строку, пока не доберемся до нужной. Сделать какие-либо выборки, например отобрать песни с одинаковым стилем, еще сложнее.
Другим очень распространенным и естественным способом представления данных является таблица. Мы уже не раз обращались к такой форме представления данных. Информацию по каждой песне можно представить в виде таблицы (см. табл. 4.1).
Рассмотрим структуру созданной нами таблицы. Вся таблица представляет класс объектов Песня. Каждый столбец в таблице отражает данные по одному признаку. Первая строка содержит заголовки столбцов, соответствующие названиям параметров. Первая строка таблицы соответствует информационной модели объекта Песня.
Таблица 4.1. Сведения о песнях

Таким образом, мы перешли к структурированной форме представления данных, в которой данные и их смысловая интерпретация отделены друг от друга и представлены в некоторой форме. Этот процесс получил название «структурирование данных».
Структурирование данных - это процесс, приводящий к определенной форме записи данных об объектах одного класса.
Рассмотрев свойства объекта и создав информационную модель в виде таблицы, мы получаем более наглядную и удобную форму записи информации. Теперь можно продумать, какие действия можно совершать над этим объектом. Более удобно стало описывать любую песню, так как определены характеризующие ее параметры и не надо отвлекаться на другие свойства объекта. Значительно облегчился поиск и отбор информации. Например, чтобы найти и отобрать песни одного исполнителя, мы просматриваем только столбец Исполнитель.
Основные понятия базы данных
Основу любой информационной системы составляет база данных, в которой хранятся сведения о большом количестве экземпляров взаимосвязанных классов объектов. Под базой данных понимают совокупность специальным образом организованных данных, которые хранятся на каком-либо материальном носителе. Обращаем ваше внимание на то, что это не набор каких-то разрозненных данных. Данные обязательно должны быть структурированы и связаны между собой так, чтобы человек мог составить представление о каком-либо объекте, явлении или процессе.
База данных - это поименованная совокупность структурированных данных некоторой предметной области.
Основными понятиями базы данных являются поле и запись .
Поле - это простейший объект базы данных, предназначенный для хранения значений одного параметра описываемого реального объекта.

Поле характеризуется именем и типом данных. В рассмотренной выше базе данных полями являются Название песни, Исполнитель, Стиль, Год, Страна. Поля в базе данных могут иметь различный тип данных: текстовый, числовой, дата, время, денежный и пр. В табл. 4.1, где представлены сведения о песнях, названия полей указаны в первой строке, а значения каждого поля - в соответствующем столбце.
База данных содержит сведения о многих параметрах объектов предметной области. Поэтому важно, в какой последовательности будут располагаться (записываться) эти параметры. Например, сведения об ученике логично представить в виде записи, где порядок расположения параметров будет следующий: Фамилия, Имя, Отчество, Дата рождения, Улица, Дом, Квартира. Для сравнения рассмотрим неудачный порядок расположения тех же параметров: Невский пр., Тихонов, 07.12.1989, д. 15, Виктор, кв. 48, Николаевич.
Таким образом, важным этапом создания базы данных является разработка структуры записи.
Структура записи - это совокупность логически связанных полей, характеризующих параметры реального объекта.
Запись - это совокупность значений параметров конкретного объекта.
Если информация об объекте представлена в форме таблицы, то первая строка таблицы всегда содержит названия параметров, то есть определяет структуру записи. Все остальные строки - это записи.
Контрольные вопросы и задания
1. Какова роль информационной системы при работе с информацией?
2. В чем состоит цель создания информационной системы?
3. Что такое предметная область?
4. Приведите примеры, когда возникает необходимость отбора нужной информации? Как вы это делаете? Важно ли при этом понятие «предметная область»?
5. Приведите примеры разных предметных областей и выделите в них объекты, информация о которых вас будет интересовать. Какими параметрами должны характеризоваться объекты данного класса?
6. Что такое структурирование данных?
7. Что такое база данных?
8. Что такое поле?
9. Что такое структура записи?
10. Что такое запись?
11. Представьте параметры объектов конкретной предметной области в виде таблицы. Укажите в таблице поля, записи, структуру записи.
Структурирование данных. Не вызывает сомнения, что при хранении большого количества данных неизбежно могут возникнуть проблемы с извлечением из этого множества только тех из них, которые необходимы для решения конкретной задачи.
Само собой разумеется, что сделать это проще, если данные упорядочены. В подтверждение этого рассмотрим пример данных, содержащих некоторые сведения о студентах (рис. 2.1).
Личное дело № 16493, Сергеев Петр Михайлович, дата рождения 1 января 1976 г.; ГУд Na 16593, Петрова Анна Владимировна, дата рожд. 15 марта 1975 г.; Na личн.дела 16693, д.р. 14.04.76, Анохин Андрей Борисович.
Рис. 2.1. Неструктурированные данные
Легко убедиться, что найти необходимые данные при такой организации их хранения непросто. Гораздо проще сделать это, если эти же данные упорядочить, например поместить каждый из элементов данных в отдельную ячейку таблицы так, как это показано на рис. 2.2.
Рис. 2.2. Структурированные данные
Введение соглашений (правил) о способах представления данных называется их структурированием. Очевидно, что вариантов таких соглашений может быть сколь угодно много. Способ представления данных определяет их структуру, т. е. их взаиморасположение и связь . Наиболее распространенными являются три основных типа структур данных - иерархическая, сетевая и реляционная.
Иерархическая структура данных. Иерархический тип структуры предполагает расположение частей или элементов целого в порядке от высшего к низшему. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рис. 2.3. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Такой узел называется порожденным. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (порожденные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рис. 2.3, для записи С4 путь проходит через записи А и ВЗ. В такой структуре связь имеет характер подчинения и направлена от исходного (родительского) узла к зависимому (порожденному).
Рис. 2.3. Графическое изображение иерархической структуры БД
Таким образом, иерархическая структура данных, отличается тем, что адрес каждого элемента данных однозначно определяется путем доступа, ведущим от вершины структуры к данному элементу. Это обусловливает сложность записи адреса элемента данных.
Поиск данных в такой структуре осуществляется путем последовательного просмотра ветвей дерева. Такой процесс может быть достаточно длительным и трудоемким, что, несомненно, является недостатком такого структурирования. На практике задачу поиска можно упростить, если создать вспомогательную таблицу, связывающую элементы иерархической структуры с идентификаторами, облегчающими перемещение по ветвям дерева. Так, например, учебник представляет собой иерархическую структуру, уровнями которой являются разделы, главы и параграфы. Оглавление позволяет связать эти элементы структуры с номерами страниц, что позволяет читателю быстрее найти нужный фрагмент текста.
Несомненным достоинством иерархической структуры является простота ее обновления. Действительно, для этого достаточно ввести новую вершину на любом уровне. Свойства такой структуры обеспечили возможность ее применения для организации хранения данных во внешней памяти компьютера.
Пример иерархической структуры данных, описывающих гипотетический вуз, приведен на рис. 2.4. Предполагается, что данные об отдельных студентах располагаются на нижнем, шестом уровне. Применение иерархической структуры для рассматриваемого примера целесообразно потому, что каждый студент

Рис. 2.4. Пример иерархической структуры данных
учится в определенной (только одной) группе, которая относится к определенному (только одному) вузу. Для учета формы обучения (дневная, очно-заочная, заочная) можно ввести еще один уровень иерархии.
Сетевая структура данных. Если в древовидной структуре порожденные узлы имеют связи более чем с одним исходным, то такая структура называется сетевой. Другими словами, в сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом (рис.

Рис. 2.5. Графическое изображение сетевой структуры
Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о дорожной сети какого-либо региона (рис. 2.6). Такая структура сложнее, чем иерархи-

Рис. 2.6. Пример сетевой структуры базы данных
ческая. Следовательно, в ней труднее организовать поиск нужных данных. Реальным примером использования такой структуры на практике является структура глобальной информационной сети, которая получила название WWW (World Wide Web), или «всемирная паутина». Именно сложность поиска информации в этой структуре вызвали появление специальных средств поиска, таких, как «поисковые машины» и «каталоги».
Реляционная структура данных. Реляционные (от англ. relation - отношение) структуры данных отличаются простотой, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. В этом случае данные организуются в виде двухмерных таблиц. Каждая реляционная таблица представляет собой двухмерный массив и обладает следующими свойствами:
В ячейку таблицы помещается только один элемент данных;
Все столбцы в таблице однородные, т. е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т. д.) и длину;
Каждый столбец имеет уникальное имя;
Одинаковые строки в таблице отсутствуют;
Порядок следования строк и столбцов может быть произвольным.
Примером реляционной таблицы может служить информация о студентах, обучающихся в вузе, представленная в табл. 2.8.
Таблица 2.8. Пример реляционной таблицы
Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект. Строки таблицы представляют собой запись. Так, таблица «Студенты», представленная в нашем примере, содержит сведения обо всех студентах, а каждая ее строка - набор значений атрибутов конкретного студента. Значения конкретного атрибута выбираются из столбцов, в каждом из которых содержится множество всех возможных значений атрибута объекта. Имя столбца должно быть уникальным в таблице. Столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. Любая таблица содержит, по крайней мере, один столбец. В отличие от столбцов строки не имеют имен. Порядок следования строк в таблице не определен, а количество логически не ограничено. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует «первой» и «последней».
Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом. В таблице «Студенты» первичным ключом служит столбец «№ личного дела». В таблице не должно быть строк, имеющих одно и то же значение первичного ключа. Если таблица удовлетворяет этому требованию, она называется отношением. Следовательно, отношение представляет собой сгруппированные в таблицу логически связанные данные, описывающие информационный объект.
Доступ к элементам данных в реляционной структуре осуществляется по адресу ячейки. Достоинством табличной структуры является простота адресации, а недостатком - сложность обновления. Последнее обстоятельство обусловлено тем, что при необходимости включения в такую структуру новых строк или столбцов изменяются адреса всех элементов данных, расположенных после заново включенных.
Экзамен Информатика
Информация как ресурс. Способы хранения и обработки информации.
Информация от лат. «Information» означает разъяснение, осведомление, изложение.
В широком смысле информация –
это общенаучное понятие, включающее в себя обмен сведениями между людьми, обмен сигналами между живой и неживой природой, людьми и устройствами.
Информация –
это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, кот-е уменьшают имеющуюся о них степень неопределенности, неполноты знаний.
Информатика рассматривает информацию как концептуально связанные между собой сведения, данные, понятия, изменяющие наши представления о явлении или объекте окружающего мира.
Информационные ресурсы –
это отдельные документы и отдельные массивы документов, документы и массивы документов в информационных системах (библиотеках, архивах, фондах, банках).
Чтобы информация могла использоваться, причем многократно, необходимо ее хранить.
Хранение информации –
это способ распространения информации в пространстве и времени. Способ хранения информации зависит от ее носителя (книга - библиотека, картина - музей, фотография - альбом). ЭВМ предназначена для компактного хранения информации с возможностью быстрого доступа к ней.
Обработка информации
– это преобразование информации из одного вида в другой.
Обработка информации – сам процесс перехода от исходных данных к результату и есть процесс обработки. Объект или субъект, осуществляющий обработку - исполнитель обработки.
1-ый тип обработки:
обработка, связанная с получением новой информации, нового содержания знаний.
2-ой тип обработки:
обработка, связанная с изменением формы, но не изменяющая содержания (например,
перевод текста с одного языка на другой).
Важный вид обработки - кодирование
– преобразование информации в символьную форму,
удобную для ее хранения, передачи, обработки. Другой вид обработки информации – структурирование данных (внесение определенного порядка в хранилище информации, классификация, каталогизация данных).
Ещё один вид обработки информации – поиск в некотором хранилище информации нужных данных, удовлетворяющих определенным условиям поиска (запросу).
Понятие структурированных данных. Определение и назначение базы данных.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро извлекать выборку с произвольным сочетанием признаком. Сделать это возможно, только если данные структурированы.
Структурирование - это введение соглашений о способах представления данных.
Структурированные данные - это упорядоченные данные.
Неструктурированные данные – это данные, записанные, например, в текстовом файле: Личное дело № 1 Сидоров Олег Иванович, дата рожд. 14.11.92, Личное дело № 2 Петрова Анна Викторовна, дата рожд. 15.03.91.
Чтобы автоматизировать поиск и систематизировать эти данные, необходимо выработать определенные соглашения о способах предоставления данных, т.е. дату рожд. нужно записывать одинаково для каждого студента, она должна иметь одинаковую длину и опред. место среди остальной информации. Эти же замечания справедливы и для остальных данных (№ личного дела, Ф., И., О.) После проведения несложной структуризации с информацией, она будет выглядеть так:
Пример структурированных данных: № Ф. И. О. Дата рожд.
1 Сидоров Олег Иванович 14.11.92
Элементы структурированных данных:
1) А – поле (столбец) – это элементарная неделимая единица организации информации
2) Б – запись (строка) – это совокупность логически связанных полей
3) В – таблица (файл) – это совокупность экземпляров записей одной структуры.
База данных – это организованная на машинном носителе совокупность взаимосвязанных структурированных данных, содержащая сведения о различных сущностях некоторой предметной области (объектах, процессах, событиях, явлениях).
В широком смысле слова база данных – это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области.
Под предметной областью понимается часть реального мира, подлежащая изучению для организации управления, автоматизации, например, предприятии, ВУЗ и т.д.
Назначение базы данных:
1)Контроль за избыточностью данных. Как уже говорилось, традиционные файловые системы неэкономно расходуют внешнюю память, сохраняя одни и те же данные в нескольких файлах. При использовании базы данных, наоборот, предпринимается попытка исключить избыточность данных за счет интеграции файлов, чтобы избежать хранения нескольких копий одного и того же элемента информации.
2)Непротиворечивость данных. Устранение избыточности данных или контроль над ней позволяет сократить риск возникновения противоречивых состояний. Если элемент данных хранится в базе только в одном экземпляре, то для изменения его значения потребуется выполнить только одну операцию обновления, причем новое значение станет доступным сразу всем пользователям базы данных. А если этот элемент данных с ведома системы хранится в базе данных в нескольких экземплярах, то такая система сможет следить за тем, чтобы копии не противоречили друг другу.
3)Совместное использование данных. Файлы обычно принадлежат отдельным лицам или целым отделам, которые используют их в своей работе. В то же время база данных принадлежит всей организации в целом и может совместно использоваться всеми зарегистрированными пользователями. При такой организации работы большее количество пользователей может работать с большим объемом данных. Более того, при этом можно создавать новые приложения на основе уже существующей в базе данных информации и добавлять в нее только те данные, которые в настоящий момент еще не хранятся в ней, а не определять заново требования ко всем данным, необходимым новому приложению.
4)Поддержка целостности данных. Целостность базы данных означает корректность и непротиворечивость хранимых в ней данных. Целостность обычно описывается с помощью ограничений, т.е. правил поддержки непротиворечивости, которые не должны нарушаться в базе данных. Ограничения можно применять к элементам данных внутри одной записи или к связям между записями. Например, ограничение целостности может гласить, что зарплата сотрудника не должна превышать 40 000 рублей в год или же что в записи с данными о сотруднике номер отделения, в котором он работает, должен соответствовать реально существующему отделению компании.
5)Повышенная безопасность. Безопасность базы данных заключается в защите базы данных от несанкционированного доступа со стороны пользователей. Без привлечения соответствующих мер безопасности интегрированные данные становятся более уязвимыми, чем данные в файловой системе. Однако интеграция позволяет определить требуемую систему безопасности базы данных, а СУБД привести ее в действие. Система обеспечения безопасности может быть выражена в форме учетных имен и паролей для идентификации пользователей, которые зарегистрированы в этой базе данных. Доступ к данным со стороны зарегистрированного пользователя может быть ограничен только некоторыми операциями (извлечением, вставкой, обновлением и удалением).
Какие виды структур данных бывают?(можете указать название структуры в определенном языке программирования) Хочется узнать их предназначение, сильные и слабые стороны. Так же интересует классификация, верно ли в вики написано? Список структур данных Развернутый ответ пока каждой структуре не нужен, просто кратко, для примера рассказать в чем преимущество этой структуры перед остальными(например самое быстрое время доступа к элементу, способность динамически менять объем памяти и т.д.) Может на всё сразу не стоит отвечать, вдруг объем ответа будет значительным, хотя бы по одной из структур которую хорошо знаете можете отписаться, а я буду добавлять в основной пост информацию. Очень удобно будет иметь перед глазами такой список, сразу по нему сверился и выбрал нужное.
1. Линейные структуры данных – это структуры данных, в которых переход от одного элемента данных к другому не зависит от каких-либо логических условий, т.е. в линейных структурах используются лишь безусловные связи элементов.
1.1 Список Может всё то же самое, что и массив, но позволяет добавлять элементы в любое место, удалять элементы из любого места и получать текущее количество элементов.
1.2 Ассоциативный массив
1.3 Хеш-таблица - это обычный массив с необычной адресацией, задаваемой хеш-функцией. Лучший выбор, если не нужна сортировка информации, а только быстрый доступ к ней. Тратится дополнительная память.
преимущества:
- Важное свойство хеш-таблиц состоит в том, что, при некоторых разумных допущениях, все три операции (поиск, вставка, удаление элементов) в среднем выполняются за время O(1), время для наихудшего случая - O(n).
недостатки:
- Итерация не в порядке возрастания ключей
- Необходимость «перехеширования» при увеличении числа хранимых объектов (?)
- нельзя реализовать быстро работающие дополнительные операции MIN, MAX и алгоритм обхода всех хранимых пар в порядке возрастания или убывания ключей (?)
- не поддерживает упорядоченности, и не сохраняет порядок следования элементов (?)
- возможность коллизий
общий вид описания структур:
Основное предназначение, описание
Поддерживаемые операции
Преимущества
Недостатки
Готовая реализация в языке программирования (название функции или класса)
условные обозначения
(?) - под сомнением, поправьте пожалуйста если вдруг неправильно написано или наоборот утвердите чтобы исключить неоднозначность.
редактирование продолжается..
Банк данных представляет собой форму организации хранения и доступа к информации и является системой специальным образом организованных данных, программных, технических, языковых, организационно-методических средств, которые предназначены для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
Банк данных должен соответствовать следующим требованиям:
- * удовлетворять информационные потребности внешних пользователей, обеспечивать возможность хранения и изменения больших объемов различной информации;
- * соответствовать заданному уровню достоверности хранимой информации и ее непротиворечивости;
- * производить доступ к данным только пользователям, обладающим соответствующими полномочиями;
- * осуществлять возможность поиска информации по любой группе признаков;
- * удовлетворять необходимым требованиям по производительности при обработке запросов;
- * иметь возможность реорганизации и расширения при изменении границ программного обеспечения;
- * обеспечивать пользователям выдачу информации в различной форме;
- * гарантировать простоту и удобство обращения внешних пользователей за информацией;
- * осуществлять возможность одновременного обслуживания большого числа внешних пользователей.
Банк данных состоит из двух основных компонент: базы данных и системы управления базой данных.
Ядром банка данных служит база данных, которая представляет собой совокупность взаимосвязанных, хранящихся вместе данных при наличии минимальной избыточности, допускающей их использование оптимальным образом для одного или нескольких приложений. При этом данные запоминаются так, чтобы они были независимы от использующих их программ; для добавления новых или преобразования существующих данных, а также для поиска данных в базе данных используется общий управляемый способ.
К организации баз данных предъявляются следующие требования:
- 1) легкое, быстрое и дешевое осуществление разработки приложений базы данных;
- 2) возможность многократного применения данных;
- 3) сохранение затрат умственного труда, выражающееся в существовании программы и логических структур данных, которые не переделываются при внесении изменений в базу данных;
- 4) простота;
- 5) легкость использования;
- 6) гибкость использования;
- 7) большая скорость обработки незапланированных запросов на данные;
- 8) простота внесения изменений;
- 9) небольшие затраты; низкая стоимость хранения и использования данных и минимизация затрат на внесение изменений;
- 10) малая избыточность данных;
- 11) производительность;
- 12) достоверность данных и соответствие одному уровню обновления; нужно применять контроль за достоверностью данных; система предотвращает наличие различных версий одних и тех же элементов данных, доступных пользователям, на различных стадиях обновления;
- 13) секретность; несанкционированный доступ к данным невозможен; ограничение доступа к одинаковым данным для различного вида их использования может осуществляться разными способами;
- 14) защита от искажения и уничтожения; данные необходимо защищать от сбоев;
- 15) готовность; пользователь быстро получает данные всегда, когда это ему необходимо.
В процессе создания и функционирования банка данных участвуют пользователи разных категорий, при этом основной категорией являются конечные пользователи, т. е. те, для нужд которых и создается банк данных.
По типу хранимой информации БД делятся на
- · документальные,
- · фактографические и
- · лексикографические.
Среди документальных баз различают библиографические, реферативные и полнотекстовые.
К лексикографическим базам данных относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.).
В системах фактографического типа в БД хранится информация об интересующих пользователя объектах предметной области в виде «фактов» (например, биографические данные о сотрудниках, данные о выпуске продукции производителями и т.п.); в ответ на запрос пользователя выдается требуемая информация об интересующем его объекте (объектах) или сообщение о том, что искомая информация отсутствует в БД.
В документальных БД единицей хранения является какой-либо документ (например, текст закона или статьи), и пользователю в ответ на его запрос выдается либо ссылка на документ, либо сам документ, в котором он может найти интересующую его информацию.
БД документального типа могут быть организованы по- разному: без хранения и с хранением самого исходного документа на машинных носителях. К системам первого типа можно отнести библиографические и реферативные БД, а также БД- указатели, отсылающие к источнику информации. Системы, в которых предусмотрено хранение полного текста документа, называются полнотекстовыми.
В системах документального типа целью поиска может быть не только какая-то информация, хранящаяся в документах, но и сами документы. Так, возможны запросы типа «сколько документов было создано за определенный период времени» и т. п. Часто в критерий поиска в качестве признаков включаются «дата принятия документа», «кем принят» и другие «выходные данные» документов.
Специфической разновидностью баз данных являются базы данных форм документов. Они обладают некоторыми чертами документальных систем (ищется документ, а не информация о конкретном объекте, форма документа имеет название, по которому обычно и осуществляется его поиск), и специфическими особенностями (документ ищется не с целью извлечь из него информацию, а с целью использовать его в качестве шаблона).
В последние годы активно развивается объектно- ориентированный подход к созданию информационных систем. Объектные базы данных организованы как объекты и ссылки к объектам. Объект представляет собой данные и правила, по которым осуществляются операции с этими данными. Объект включает метод, который является частью определения объекта и запоминается вместе с объектом. В объектных базах данных данные запоминаются как объекты, классифицированные по типам классов и организованные в иерархическое семейство классов. Класс - коллекция объектов с одинаковыми свойствами. Объекты принадлежат классу. Классы организованы в иерархии.
По характеру организации хранения данных и обращения к ним различают
- · локальные (персональные),
- · общие (интегрированные, централизованные) и
- · распределенные базы данных
Персональная база данных - это база данных, предназначенная для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД.
Интегрированные и распределенные БД предполагают возможность одновременного обращения нескольких пользователей к одной и той же информации (многопользовательский, параллельный режим доступа). Это привносит специфические проблемы при их проектировании и в процессе эксплуатации БнД. Распределенные БД, кроме того, имеют характерные особенности, связанные с тем, что физически разные части БД могут быть расположены на разных ЭВМ, а логически, с точки зрения пользователя, они должны представлять собой единое целое.
БД классифицируются по объему. Особое место здесь занимают так называемые очень большие базы данных. Это вызвано тем, что для больших баз данных по-иному ставятся вопросы обеспечения эффективности хранения информации и обеспечения ее обработки.
По характеру организации данных БД могут быть разделены на
- · неструктурированные,
- · частично структурированные и
- · структурированные.
Этот классификационный признак относится к информации, представленной в символьном виде. К неструктурированным БД могут быть отнесены базы, организованные в виде семантических сетей. Частично структурированными можно считать базы данных в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры БД. Только после этого базы данных такого типа могут быть заполнены данными.
Структурированные БД, в свою очередь, по типу используемой модели делятся на
- · иерархические,
- · сетевые,
- · реляционные,
- · смешанные и
- · мультимодельные.
Классификация по типу модели распространяется не только на базы данных, но и на СУБД.
Иерархические, сетевые, реляционные
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рисунке.
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется древовидная структура, в узлах которой стоят объекты с типом данных «узел». Объект «узел» схож с типами данных «структура» языков программирования С и «запись» языка Pascal. В них допускается вложенность типов, каждый из которых находится на некотором уровне. Тип «узел» является составным. Он включает в себя ссылки на подобъекты («поддеревья»), каждый из которых, и свою очередь, является типом «узел» с другими вложенными объектами. Каждое «дерево» состоит из одного «корневого» объекта (узла) и упорядоченного набора (возможно, пустого) подчиненных узлов. Каждый из элементарных узлов, включенных в «дерево», несет в себе простую или составную информацию, заключенную в прикрепленном к нему объекте. Простой «узел» несет в сете объект из одного типа, например числового, а составной объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример «дерева» как совокупности узлов показан на рисунке.
Корневым называется узел, который имеет подчиненные узлы и сам не является подузлом. Подчиненный узел (подузел) является потомком по отношению к узлу, который выступает для него в роли предка (родителя). Потомки одного и того же узла являются близнецами по отношению друг к другу В целом «дерево» представляет собой иерархически организованный набор типов «узел». Иерархическая БД представляет собой упорядоченную совокупность деревьев, содержащих экземпляры типа «узел» (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных.
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рисунке. Смысл связей здесь обозначены надписями на соединяющих типы записей линиях. В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т.д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
Реляционная модель данных предложена сотрудником фирмы IВМ Удгаром Коддом и основывается на понятии отношение (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам -- атрибуты отношения.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.