В настоящее время каждый человек может наблюдать стремительный рост объема цифровой информации. А так как большая часть этой информации является важной, возникает необходимость ее сохранения на цифровых носителях для последующего использования. В данной ситуации могут применяться такие современные технологии, как базы данных. Они обеспечивают надежное хранение любой цифровой информации, а доступ к данным может быть осуществлен в любой точке земного шара. Одной из рассматриваемых технологий является система управления базами данных MySQL.
СУБД MySQL - что это?
MySQL является одной из самых востребованных и часто используемых технологий хранения информации. Ее функциональные возможности превосходят по многим показателям существующие СУБД. В частности, одной из главных особенностей является возможность использовать вложенные запросы MySQL.
Поэтому многие проекты, где важно время быстродействия и необходимо обеспечить хранение информации, а также осуществлять сложные выборки данных, разрабатываются на базе СУБД MySQL. Большую часть таких разработок составляют интернет-сайты. При этом MySQL активно внедряется при реализации как небольших (блоги, сайт-визитки и т. п.), так и достаточно крупных задач (интернет-магазины, и т. д.). В обоих случаях для отображения информации на странице сайта применяется MySQL-запрос. В запросе разработчики стараются максимально использовать имеющиеся возможности, которые предоставляет система управления базами данных.
Как должно быть организовано хранение данных
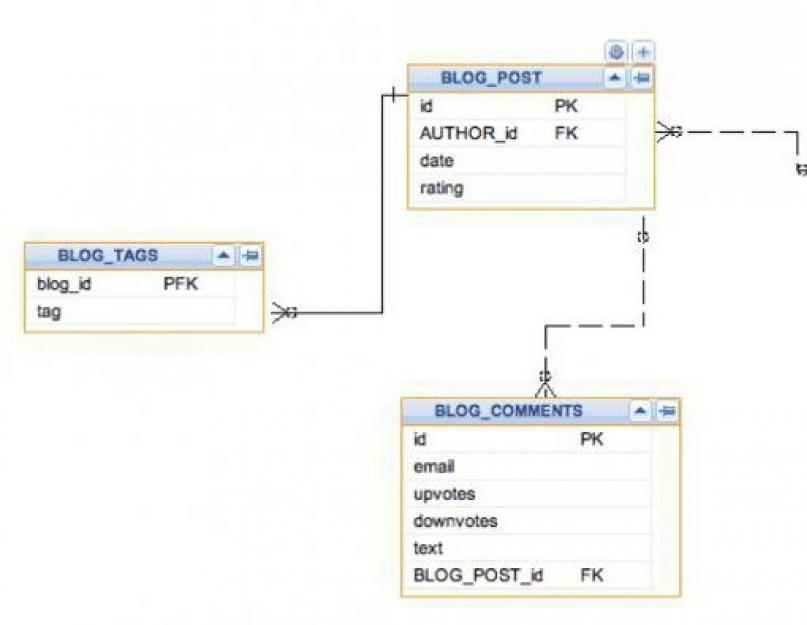
Для удобного хранения и последующей обработки данные обязательно упорядочиваются. Структура данных позволяет определить, каким образом будут выглядеть таблицы, использующиеся для хранения информации. Таблицы базы данных представляют собой набор полей (столбцов), отвечающих за каждое определенное свойство объекта данных.

Например, если составляется таблица сотрудников определенной компании, то ее самая простая структура будет иметь следующий вид. За каждым сотрудником закреплен уникальный номер, который, как правило, используется в качестве первичного ключа к таблице. Затем в таблицу заносятся персональные данные сотрудника. Это может быть что угодно: Ф. И. О., номер отдела, за которым он закреплен, телефон, адрес и прочее. Согласно требованиям нормализации (6 нормальных форм баз данных), а также для того, чтобы MySQL-запросы выстраивались структурированно, поля таблицы должны быть атомарными, то есть не иметь перечислений или списков. Поэтому, как правило, в таблице существуют отдельные поля для фамилии, имени и т. д.
Иванович | Администрац. | Директор | |||||
Петрович | Администрац. | Зам. директора | |||||
Григорий | Григорьевич | Начальник | |||||
Сергеевич | Продавец-консульт. |
Выше представлен тривиальный пример структуры таблицы базы данных. Однако она ещё не до конца отвечает основным требованиям нормализации. В реальных системах создается дополнительная таблица отделов. Поэтому приведенная таблица вместо слов в колонке «Отдел» должна содержать номера отделов.
Каким образом происходит выборка данных
Для получения данных из таблиц в СУБД используется специальная команда MySQL - запрос Select . Для того чтобы сервер правильно отреагировал на обращение, запрос должен быть корректно сформирован. Структура запроса формируется следующим образом. Любое обращение к серверу БД начинается с ключевого слова select . Именно с негостроятся все вMySQL запросы. Примеры могут иметь различную сложность, но принцип построения очень похож.
Затем необходимо указать, с каких полей требуется выбрать интересующую информацию. Перечисление полей происходит через запятую после предложения select . После того как все необходимые поля были перечислены, в запросе указывается объект таблицы, из которого будет происходить выборка, при помощи предложения from и указания имени таблицы.
Для ограничения выборки в MySQL-запросы добавляются специальные операторы, предусмотренные СУБД. Для выборки неповторяющихся (уникальных) данных используется предложение distinct , а для задания условий - оператор where . В качестве примера, применимого к вышеуказанной таблице, можно рассмотреть запрос, требующий информацию о Ф.И.О. сотрудников, работающих в отделе «Продажи». Структура запроса примет вид, как в таблице ниже.

Понятие вложенного запроса
Но главная особенность СУБД, как было указано выше, возможность обрабатывать вложенные запросы MySQL. Как он должен выглядеть? Из названия логически понятно, что , сформированный в определенной иерархии из двух или более запросов. В теории по изучению особенностей СУБД сказано, что MySQL не накладывает ограничений на количество MySQL-запросов, которые могут быть вложены в главный запрос. Однако можно поэкспериментировать на практике и убедиться, что уже после второго десятка вложенных запросов время отклика серьезно увеличится. В любом случае на практике не встречаются задачи, требующие использовать чрезвычайно сложный MySQL-запрос. В запросе может потребоваться максимально до 3-5 вложенных иерархий.

Построение вложенных запросов
При анализе прочитанной информации возникает ряд вопросов о том, где могут быть использованы вложенные запросы и нельзя ли решить задачу разбиением их на простые без усложнения структуры. На практике вложенные запросы используются для решения сложных задач. К такому типу задач относятся ситуации, когда заранее неизвестно условие, по которому будет происходить ограничение дальнейшей выборки значений. Решить такие задачи невозможно, если просто использовать обычный MySQL-запрос. В запросе, состоящем из иерархий, будет происходить поиск ограничений, которые могут меняться с течением времени или заранее не могут быть известны.
Если рассматривать таблицу, приведенную выше, то в качестве сложной задачи можно привести следующий пример. Допустим, нам необходимо узнать основную информацию о сотрудниках, находящихся в подчинении Гришина Григория Григорьевича, который является При формировании запроса нам неизвестен его идентификационный номер. Поэтому изначально нам необходимо его узнать. Для этого используется простой запрос, который позволит найти решение главного условия и дополнит основной MySQL-запрос. В запросе наглядно представлено, что подзапрос получает идентификационный номер сотрудника, который в дальнейшем определяет ограничение главного запроса:

В данном случае предложение any используется для того, чтобы исключить возникновение ошибок, если сотрудников с такими инициалами окажется несколько.
Итоги
Подводя итог, необходимо отметить, что существует ещё много других дополнительных возможностей, которые значительно облегчают построение запросов, так как СУБД MySQL - мощное средство с богатым арсеналом инструментов для хранения и обработки данных.
Как оптимизировать MySQL запросы?
Для обычного, не особо посещаемого сайта, нет большой разницы, оптимизированы MySQL запросы к базе или нет. А вот для рабочих серверов под большой нагрузкой разница между правильным и неправильным SQL является огромной, и во время выполнения они могут значительно влиять на поведение и надежность сервисов. В этой статье я рассмотрю, как писать быстрые запросы и факторы, делающие их медленными.
Почему MySQL?
Сегодня идет много разговоров о Dig Data и других новых технологиях. NoSQL и облачные решения это супер, но много популярного софта (такого как WordPress, phpBB, Drupal) до сих пор работает на MySQL. Миграция на новейшие решения может вылиться не только в изменении конфигурации на серверах. К тому же, эффективность MySQL до сих пор на уровне, особенно версия Percona.
Не делайте распространенную ошибку, выбрасывая все больше и больше железа на решение проблемы медленных запросов и высокой нагрузки серверов - лучше обратиться к истокам проблем. Увеличение мощности процессоров и жестких дисков и добавление оперативной памяти это также определенный вид оптимизации, однако, это не то, о чем мы будем говорить в данной статье. Также, оптимизируя сайт и решая проблему железом, нагрузка будет расти только в геометрической прогрессии. Поэтому это лишь краткосрочное решение.
Хорошее понимание SQL это важнейший инструмент для веб-разработчика, именно он позволит эффективно оптимизировать и использовать реляционные базы данных. В этой статье мы сфокусируемся на популярной открытой базе данных, часто используется в связке с PHP, и это MySQL.
Для кого эта статья?
Для веб-разработчиков, архитекторов и разработчиков баз данных и системных администраторов, хорошо знакомых с MySQL. Если раньше вы не использовали MySQL, эта статья может не принести вам пользы, но я все равно буду стараться быть как можно более информативным и полезным даже для новичков в MySQL.
Сначала бэкап
Я рекомендую делать следующие шаги на базе MySQL, с которой вы работаете, однако не забудьте сделать резервную копию. Если у вас нет базы данных, с которой вы можете работать, я буду предоставлять примеры для создания собственной базы данных, где это будет уместно.
Делать бэкапы MySQL просто, используя утилиту mysqldump:
$ mysqldump myTab > myTab-backup.sql Вы можете узнать больше о mysqldump .
Что делает запрос медленным?
Вот общий список факторов, влияющих на скорость выполнения запросов и нагрузки сервера:
- индексы таблиц;
- условие WHERE(и использования внутренних функций MySQL, например, таких как IF или DATE);
- сортировка по ORDER BY;
- частое повторение одинаковых запросов;
- тип механизма хранения данных (InnoDB, MyISAM, Memory, Blackhole);
- не использование версии Percona;
- конфигурации сервера (my.cnf / my.ini);
- большие выдачи данных (более 1000 строк);
- нестойкое соединение;
- распределенная или кластерная конфигурация;
- слабое проектирование таблиц.
Что такое индексы?
Индексы используются в MySQL для поиска строк с указанными значениями колонок, например, с командой WHERE. Без индексов, MySQL должна, начиная с первой строки, прочитать всю таблицу в поисках релевантных значений. Чем больше таблица, тем больше затрат.
Если таблица имеет индексы на колонках, которые будут использованы в запросе, MySQL быстро найдет расположения необходимой информации без просмотра всей таблицы. Это гораздо быстрее, чем последовательный поиск в каждой строке.
Нестойкое соединение?
Когда ваше приложение подключается к базе данных и настроено устойчивое соединение, оно будет использоваться каждый раз без надобности каждый раз открывать новое соединение. Это оптимальное решение для рабочей среды.
Уменьшаем частое повторение одинаковых запросов
Наиболее быстрый и эффективный способ, который я нашел для этого - это создание хранилища запросов и результатов их выполнения с помощью Memcached или Redis. С Memcache вы можете легко положить в кэш результат выполнения вашего запроса, например, следующим образом:
connect("localhost",11211); $cacheResult = $cache->get("key-name"); if($cacheResult){ //не нуждаемся в запросе $result = $cacheResult; } else { //запускаем ваш запрос $mysqli = mysqli("p:localhost","username","password","table"); //добавляйте p: для договременного хранения $sql = "SELECT * FROM posts LEFT JOIN userInfo using (UID) WHERE posts.post_type = "post" || posts.post_type = "article" ORDER BY column LIMIT 50"; $result = $mysqli->query($sql); $memc->set("key-name", $result->fetch_array(), MEMCACHE_COMPRESSED,86400); } //Пароль $cacheResult в шаблон $template->assign("posts", $cacheResult); ?> Теперь тяжелый запрос, использующий LEFT JOIN, будет выполняться только раз за каждые 86 400 секунд (то есть раз в сутки), что значительно уменьшит нагрузку MySQL сервера, оставив ресурсы для других соединений.
Примечание: Допишите p: в начале аргумента хоста MySQLi для создания постоянного соединения.
Распределенная или кластерная конфигурация
Когда данных становится все больше, и скорость вашего сервиса идет под уклон, паника может овладеть вами. Быстрым решением может стать распределения ресурсов (sharding). Однако я не рекомендую делать это, если вы не обладаете хорошим опытом, поскольку распределение по своей сути делает структуры данных сложнейшими.
Слабое проектирование таблиц
Создание схем баз данных не является сложной работой, если следовать таким золотым правилам, как работа с ограничениями и знание того, что будет эффективным. Например, хранение изображений в ячейках типа BLOB очень смущает - лучше храните путь к файлу в ячейке VARCHAR, это является гораздо лучшим решением.
Обеспечение правильного проектирования для нужного использования является первостепенным в создании вашего приложения. Храните различные данные в различных таблицах (например, категории и статьи) и убедитесь, что отношения к другу (many to one) и один ко многим (one to many) могут быть легко связаны с идентификаторами (ID). Использование FOREIGN KEY в MySQL идеально подходит для хранения каскадных данных в таблицах.
При создании таблицы помните следующее:
- Создавайте эффективные таблицы для решения ваших задач, а не заполняйте таблицы лишними данными и связями.
- Не ожидайте от MySQL выполнения вашей бизнес логики или програмности - данные должны быть готовы к вставке строки вашей скриптовым языком. Например, если вам нужно отсортировать список в случайном порядке, сделайте это в массиве PHP, не используя ORDER BY из арсенала MySQL.
- Используйте индексные типы UNIQUE для уникальных наборов данных и применяйте ON DUPLICATE KEY UPDATE, чтобы хранить дату обновленной, например, для того, чтобы знать, когда строка была в последний раз изменена.
- Используйте тип данных INT для сохранения целых чисел. Если вы не укажете размер типа данных, MySQL сделает это за вас.
Для эффективной оптимизации мы должны применять три подхода к вашему приложению:
- Анализ (логирование медленных запросов, изучение системы, анализ запросов и проектирование базы данных)
- Требования к исполнению (сколько пользователей)
- Ограничения технологий (скорость железа, неправильное использование MySQL)
Колонки, вы видите, сохраняют важную информацию о запросе. Колонки, на которые вы должны обратить наибольшее внимание это possible_keys и Extra.
Колонка possible_keys покажет индексы, в которые MySQL имел доступ, чтобы выполнить запрос. Иногда нужно назначить индексы, чтобы запрос выполнялся быстрее. Колонка Extra покажет, были ли использованы дополнительные WHEREили ORDER BY. Наиболее важно обратить внимание, есть ли Using Filesort в выводе.
Что делает Using Filesort, указано в справке MySQL:
MySQL должен выполнить дополнительный проход, чтобы понять, как вернуть строки в отсортированном виде. Это сортировка происходит проходом по всем строкам в соответствии с типом объединения и сохраняет ключ к сортировке и указатель на строку для всех строк, совпадающих с условным выражением WHERE. Ключи сортируются и строки возвращаются в нужном порядке.Лишний проход замедлит ваше приложение, этого нужно избегать, чего бы это ни стоило. Другой критический результат Extra, который мы должны избегать - это Using temporary. Он говорит о том, что MySQL пришлось создать временную таблицу для выполнения запроса. Очевидно, это ужасное использования MySQL. В таком случае результат запроса должен быть сохранен в Redis или Memcache и не выполняться пользователями лишний раз.
Чтобы избежать проблемы с Using Filesort мы должны увериться, что MySQL использует INDEX. Сейчас указано несколько ключей в possible_keys, из которых можно выбирать, но MySQL может выбрать только один индекс для финального запроса. Также индексы могут быть составлены из нескольких колонок, также вы можете ввести подсказки (хинты) для оптимизатора MySQL, указывая на индексы, что вы создали.
Хинтинг индексов
Оптимизатор MySQL будет использовать статистику, основанную на запросах таблиц, чтобы выбрать лучший индекс для выполнения запроса. Он действует достаточно просто, основываясь на встроенной статистической логике, поэтому имея несколько вариантов, не всегда делает правильный выбор без помощи хинтинга. Чтобы убедиться, что был использован правильный (или неправильный) ключ, воспользуйтесь ключевым словам FORCE INDEX, USE INDEX и IGNORE INDEX в вашем запросе. Вы можете прочитать больше о хинтинге индексов в справке MySQL .
Чтобы вывести ключи таблицы, используйте команду SHOW INDEX. Вы можете задать несколько хинтов для использования оптимизатором.
В дополнение к EXPLAIN существует ключевое слово DESCRIBE. Вместе с DESCRIBE можно просматривать информацию из таблицы следующим образом:

Добавляем индекс
Для добавления индексов в MySQL надо использовать синтаксис CREATE INDEX. Есть несколько видов индексов. FULLTEXT Применяется для полнотекстового поиска, а UNIQUE - для хранения уникальных данных.
Чтобы добавить индекс в вашу таблицу, используйте следующий синтаксис:
Mysql> CREATE INDEX idx_bookname ON `books` (bookname(10)); Это создаст индекс на таблице books, которая будет использовать первые 10 букв из колонки, которая хранит названия книг и имеет тип varchar. В этом случае, любой поиск с запросом WHERE на название книги с совпадением до 10 символов будет давать такой же результат, как и просмотр всей таблицы от начала до конца.
Композитные индексы
Индексы имеют большое влияние на скорость выполнения запросов. Только назначения главного уникального ключа недостаточно - композитные ключи являются реальной областью применения в настройке MySQL, что иногда требует некоторых A/B проверок с использованием EXPLAIN.
Например, если нам нужно ссылаться на две колонки в условии выражения WHERE, композитный ключ будет идеальным решением.
Mysql> CREATE INDEX idx_composite ON users (username, active); Как только мы создали ключ на основе колонки username, в котором хранится имя пользователя и колонки active типа ENUM, определяющий, активен ли его аккаунт. Теперь все оптимизировано для запроса, который будет использовать WHERE для поиска валидного имени пользователя с активным аккаунтом (active = 1).
Насколько быстра ваша MySQL?
Включим профилирование, чтобы подробнее рассмотреть MySQL запросы. Это можно сделать, выполнив команду set profiling=1, после чего для просмотра результата надо выполнить show profiles.
Если вы используете PDO, выполните следующий код:
$db->query("set profiling=1"); $db->query("select headline, body, tags from posts"); $rs = $db->query("show profiles"); $db->query("set profiling=0"); // отключить профилирование после выполнения запроса $records = $rs->fetchAll(PDO::FETCH_ASSOC); // получить результаты профилирования $errmsg = $rs->errorInfo(); //Отлавливаем некоторые ошибки здесь То же самое можно сделать с помощью mysqli:
$db = new mysqli($host,$username,$password,$dbname); $db->query("set profiling=1"); $db->query("select headline, body, tags from posts"); if ($result = $db->query("SHOW profiles", MYSQLI_USE_RESULT)) { while ($row = $result->fetch_row()) { var_dump($row); } $result->close(); } if ($result = $db->query("show profile for query 1", MYSQLI_USE_RESULT)) { while ($row = $result->fetch_row()) { var_dump($row); } $result->close(); } $db->query("set profiling=0"); Это вернет вам профилированные данные, содержащие время выполнения запроса во втором элементе ассоциативного массива.
Array(3) { => string(1) "1" => string(10) "0.00024300" => string(17) "select headline, body, tags from posts" } Этот запрос выполнялся 0.00024300 секунд. Это довольно быстро, поэтому не будем беспокоиться. Но когда числа становятся большими, мы должны смотреть глубже. Перейдите к вашему приложению, чтобы потренироваться на рабочем примере. Проверьте константу DEBUG в конфигурации вашей базы данных, а затем начните изучать систему, включив вывод результатов профилирования с помощью функций var_dump или print_r. Так вы сможете переходить со страницы на страницу в вашем приложении, получив удобное профилирование системы.

Полный аудит работы базы вашего сайта
Чтобы сделать полный аудит ваших запросов, включите логирование. Некоторые разработчики сайтов переживают по поводу того, что логирование сильно влияет на выполнение и дополнительно замедляет запросы. Однако, практика показывает, что разница незначительна.
Чтобы включить логирование в MySQL 5.1.6 используйте глобальную переменную log_slow_queries, также вы можете отметить файл для логирования с помощью переменной slow_query_log_file. Это можно сделать, выполнив следующий запрос:
Set global log_slow_queries = 1; set global slow_query_log_file = /dev/slow_query.log; Также это можно указать в файлах конфигурации /etc/my.cnf или my.ini вашего сервера.
После внесения изменений не забудьте перезагрузить MySQL сервер необходимой командой, например service mysql restart, если вы используете Linux.
В версиях MySQL после 5.6.1 переменная log_slow_queries обозначена как устаревшая и вместо нее используется slow_query_log. Также для более удобного дебаггинга можно включить вывод в таблице, задав переменной log_output значение TABLE, однако эта функция доступна только с MySQL 5.6.1.
Log_output = TABLE; log_queries_not_using_indexes = 1; long_query_time = 1; Переменная long_query_time определяет количество секунд, после которых выполнение запроса считается медленным. Значение это 10, а минимум это 0. Также можно указать миллисекунды, используя дробь; сейчас я указал одну секунду. И теперь каждый запрос, который будет выполняться дольше 1 секунды, записывается в логи в таблице.
Логирование будет вестись в таблицах mysql.slow_log и mysql.general_log вашей MySQL базы данных. Чтобы выключить логирование, измените log_output на NONE.
Логирование на рабочем сервере
На рабочем сервере, который обслуживает клиентов, лучше применять логирование только на короткий период и для мониторинга нагрузки, чтобы не создавать лишней нагрузки. Если ваш сервис перегружен и необходимо безотлагательное вмешательство, попробуйте выделить проблему, выполнив SHOW PROCESSLIST, или обратитесь к таблице information_schema.PROCESSLIST, выполнив SELECT * FROM information_schema.PROCESSLIST;.
Логирование всех запросов на рабочем сервере может дать вам много информации и стать хорошим средством для исследовательских целей при проверке проекта, однако логи за большие периоды не дадут вам много полезной информации по сравнению с логами за период до 48 часов (старайтесь отслеживать пиковые нагрузки, чтобы иметь шанс лучше исследовать выполнение запросов).
Примечание: если у вас сайт, переживающей волны трафика и временами почти без него, как, например, спортивный сайт в не сезон, тогда используйте эту информацию для построения и изучения логирования.
Логирование множества запросов
Важно знать не только о запросах, которые выполняются дольше секунду, также необходимо иметь в виду запросы, выполняемые сотни раз. Даже если запросы выполняются быстро, в нагруженной системе они могут оттянуть все ресурсы на себя.
Вот почему всегда нужно быть настороже после внесения изменений в живом проекте - это наиболее критическое время для работы любой базы данных.
Горячий и холодный кэш
Количество запросов и нагрузка сервера имеет сильное влияние на исполнение, также может повлиять на время выполнения запросов. При разработке вы должны взять за правило, что выполнение каждого запроса должно быть не более доли миллисекунды (0.0xx или быстрее) на свободном сервере.
Применение Memcache имеет сильный эффект на нагрузку серверов, освободит ресурсы, которые выполняют запросы. Убедитесь, что вы используете Memcached эффективно и протестовали ваше приложение с горячим кэшем (подгруженными данным) и с холодным кэшем.
Чтобы избежать запуска на рабочем сервере с пустым кэшем, хорошей идеей будет скрипт, который соберет весь необходимый кэш перед запуском сервера, чтобы большой наплыв клиентов не снизил время загрузки системы.
Исправление медленных запросов
Теперь, когда логирование настроено, вы могли найти несколько медленных запросов на вашем сайте. Давайте исправим их! Для примера я покажу несколько распространенных проблем, вы можете встретить и логику их исправления.
Если вы пока не нашли медленного запроса, проверьте настройки long_query_time, если вы пользуетесь этим методом логирования. Иначе, проверив все ваши запросы профилирования (set profiling=1), составьте список запросов, отнимают больше времени, чем доля миллисекунд (0.000x секунд) и начнем из них.
Распространенные проблемы
Вот шесть самых распространенных проблем, которые я находил, оптимизируя MySQL запросы:
ORDER BY и filesort
Предотвращение filesort иногда невозможно из-за выражения ORDER BY. Для оптимизации сохраните результат в Memcache, или выполните сортировку в логике вашего приложения.
Использование ORDER BY вместе с WHERE и LEFT JOIN
ORDER BY очень замедляет выполнение запросов. Если это возможно, старайтесь не использовать ORDER BY. Если же вам необходима сортировка, то используйте сортировку по индексам.
Применение ORDER BY по временным колонками
Просто не делайте этого. Если вам нужно объединить результаты, сделайте это в логике вашего приложения; не используйте фильтрацию или сортировку во временной таблице запроса MySQL. Это требует много ресурсов.
Игнорирование индекса FULLTEXT
Использование LIKE это самый лучший способ сделать полнотекстовый поиск медленным.
Беспричинный выбор большого количества строк
Забыв о LIMIT в вашем запросе можно сильно увеличить время выполнения выборки из базы данных в зависимости от размера таблиц.
Чрезмерное использование JOIN вместо создания композитных таблиц или представления
Когда в одном запросе вы пользуетесь больше чем тремя-четырьмя операторами LEFT JOIN, спросите себя: все ли здесь верно? Продолжайте, если у вас есть на то веская причина, например - запрос используется не часто для вывода в панели администратора, или результат вывода может быть сохранен в кэше. Если же вам нужно выполнять запрос с большим количеством операций объединения таблиц, тогда лучше задуматься о создании композитных таблиц из необходимых столбиков или использовать представления.
Итак
Мы обсудили основы оптимизации и инструменты, необходимые для работы. Мы изучили систему, применяя профилирования и оператор EXPLAIN, чтобы увидеть, что происходит с базой данных, и понять, как можно улучшить структуру.
Также мы посмотрели на несколько примеров и классических ловушек, в которые вы можете попасть, используя MySQL. Используя хинтинг индексов, мы можем увериться в том, что MySQL выберет необходимые индексы, особенно при нескольких выборках в одной таблице. Чтобы продолжить изучение темы, я советую вам посмотреть в сторону Percona project.

Синтаксис:
* где fields1
— поля для выборки через запятую, также можно указать все поля знаком *; table
— имя таблицы, из которой вытаскиваем данные; conditions
— условия выборки; fields2
— поле или поля через запятую, по которым выполнить сортировку; count
— количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
Простые примеры использования select
1. Обычная выборка данных:
> SELECT * FROM users
2. Выборка данных с объединением двух таблиц (JOIN):
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights . Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
а) известна точка начала и определенный временной интервал:
* будут выбраны данные за последний час (поле date ).
б) известны дата начала и дата окончания:
25.10.2017 и 25.11.2017 .
в) известны даты начала и окончания + время:
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд .
г) вытаскиваем данные за определенные месяц и год:
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
4. Выборка максимального, минимального и среднего значения:
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки:
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT):
* из таблицы users извлекаются данные по полю id , все они помещаются в одну строку, значения разделяются запятыми .
2. Группировка данных по двум и более полям:
> SELECT * FROM users GROUP BY CONCAT(title, "::", birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth . Перед группировкой мы делаем объединение полей в одну строку с разделителем :: .
3. Объединение результатов из двух таблиц (UNION):
> (SELECT id, fio, address, "Пользователи" as type FROM users)
UNION
(SELECT id, fio, address, "Покупатели" as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers .
4. Выборка средних значений, сгруппированных за каждый час:
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H") as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H")
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO