Порыскав на досуге по тырнету, удивился, что специальных статей-руководств по оптимизации SQL-запросов нет. Перелистав различную информацию и книги, я постараюсь дать некоторое руководство к действию, которое поможет научиться писать правильные запросы.
- Оптимизация таблиц
. Необходима, когда было произведено много изменений в таблице: либо удалена большая часть данных, либо много изменений со строками переменной длины - text, varchar, blob. Дело в том, что удалённые записи продолжают поддерживаться в индексном файле, и при последующей вставке новых записей используются позиции старых записей. Чтобы дефрагментировать файл с данными, используюется команда OPTIMIZE.
OPTIMIZE TABLE `table1`, `table2`…
Не стоит забывать, что во время выполнения оптимизации, доступ к таблице блокируется.
- Не забывайте про временные таблицы типа HEAP . Несмотря на то, что таблица имеет ограничения, в ней удобно хранить промежуточные данные, особенно когда требуется сделать ещё одну выборку из таблицы без повторного обращения. Дело в том, что эта таблица хранится в памяти и поэтому доступ к ней очень быстрый.
- Поиск по шаблону . Зависит от размера поля и если уменьшить размер с 400 байтов до 300, то время поиска сократиться на 25%.
Перестройка данных в таблице . После частых изменений в таблице, данная команда может повысить производительность работы с данными. Она перестраивает их в таблице и сортирует по определённому полю.
ALTER TABLE `table1` ORDER BY `id`
Тип данных . Лучше не индексировать поля, имеющие строковый тип, особенно поля типа TEXT. Для таблиц, данные которых часто изменяются, желательно избегать использования полей типа VARCHAR и BLOB, так как данный тип создаёт динамическую длину строки, тем самым увеличивая время доступа к данным. При этом советуют использовать поле VARCHAR вместо TEXT, так как с ним работа происходит быстрее.
NOT NULL и поле по умолчанию . Лучше всего помечать поля как NOT NULL, так как они немного экономят место и исключают лишние проверки. При этом стоит задавать значение полей по умолчанию и новые данные вставлять только в том случае, если они от него отличаются. Это ускорит добавление данных и снизит время на анализ таблиц. И стоит помнить, что типы полей BLOB и TEXT не могут содержать значения по умолчанию.
Постоянное соединение с сервером БД . Позволяет избежать потерь времени на повторное соединение. Однако стоит помнить, что у сервера может быть ограничение на количество соединений, и в том случае, если посещаемость сайта очень высокая, то постоянное соединение может сыграть злую шутку.
Разделение данных.
Длинные не ключевые поля советуют выделить в отдельную таблицу в том случае, если по исходной таблице происходит постоянная выборка данных и которая часто изменяется. Данный метод позволит сократить размер изменяемой части таблицы, что приведёт к сокращению поиска информации.
Особенно это актуально в тех случаях, когда часть информации в таблице предназначена только для чтения, а другая часть - не только для чтения, но и для модификации (не забываем, что при записи информации блокируется вся таблица). Яркий пример - счётчик посещений.
Есть таблица (имя first) с полями id, content, shows. Первое ключевое с auto_increment, второе - текстовое, а третье числовое - считает количество показов. Каждый раз загружая страницу, к последнему полю прибавляется +1. Отделим последнее поле во вторую таблицу. Итак, первая таблица (first) будет с полями id, content, а вторая (second) с полями shows и first_id. Первое поле понятно, второе думаю тоже - отсыл к ключевому полю id из первой таблицы.
Теперь постоянные обновления будут происходить во второй таблице. При этом изменять количество посещений лучше не программно, а через запрос:
А выборка будет происходить усложнённым запросом, но одним, двух не нужно:
SELECT first.id, first.content, second.first_id, second.shows FROM second INNER JOIN first ON (first.id = second.first_id)
Стоит помнить, что всё это не актуально для сайтов с малой посещаемостью и малым количеством информации.
Имена полей , по которым происходит связывание, к примеру, двух таблиц, желательно, чтобы имели одинаковое название. Тогда одновременное получение информации из разных таблиц через один запрос будет происходить быстрее. Например, из предыдущего пункта желательно, чтобы во второй таблице поле имело имя не first_id, а просто id, аналогично первой таблице. Однако при одинаковом имени становится внешне не очень наглядно что, куда и как. Поэтому совет на любителя.
Требовать меньше данных . При возможности избегать запросов типа:
SELECT * FROM `table1`
Запрос не эффективен, так как скорее всего возвращает больше данных, чем необходимо для работы. Вариантом лучше будет конструкция:
SELECT id, name FROM table1 ORDER BY id LIMIT 25
Тут же сделаю добавление о желательности использования LIMIT. Данная команда ограничивает количество строк, возвращаемых запросом. То есть запрос становится "легче" и производительнее.
Если стоит LIMIT 10, то после получения десяти строк запрос прерывается.
Если в запросе применяется сортировка ORDER BY, то она происходит не по всей таблице, а только по выборке.
Если использовать LIMIT совместно с DISTINCT, то запрос прервётся после того, как будет найдено указанное количество уникальных строк.
Если использовать LIMIT 0, то возвращено будет пустое значение (иногда нужно для определения типа поля или просто проверки работы запроса).
Ограничить использование DISTINCT
. Эта команда исключает повторяющиеся строки в результате. Команда требует повышенного времени обработки. Лучше всего комбинировать с LIMIT.
Есть маленькая хитрость. Если необходимо просмотреть две таблицы на тему соответствия, то приведённая команда остановится сразу же, как только будет найдено первое соответствие.
Ограничить использование SELECT для постоянно изменяющихся таблиц .
После написания программы и появления «живых» данных выясняется, что реакция программы на тестовые наборы, порой сильно отличается от работы с реальными данными. Программисты обычно мало внимания уделяют формированию тестовых наборов данных, что является серьезной ошибкой. Ставка делается на то, что используются современные «крутые» СУБД, которые сами себя настраивают. К сожалению это не совсем так, и работе с базой данных следует уделять пристальное внимание. В идеале, за обработку бизнес логики должны отвечать специалисты. Но и рядовым программистам полезно иметь навыки и знания по архитектуре СУБД и написанию SQL запросов.
Нередки случаи, когда используются генераторы скриптов и программного кода для доступа к данным. Авторы программ надеются на то, что современные технологические новинки сами выполнят за вас всю работу. В результате нередки случаи, когда несколько месяцев спустя после внедрения программы, пользователи начинают жаловаться, что программа «еле шевелится». Начинается всеобщая паника с привлечением дорогостоящих специалистов, которые смогут найти “бутылочное горлышко” тормозящее программу и спасти проект.
Практика показывает что, анализируя и перестраивая SQL запросы можно снизить время их выполнения в десятки, а иногда и в сотни раз. После разработки нескольких проектов, у программистов вырабатываются навыки написания более «быстрых» запросов. Но все равно полезно выполнять периодический анализ затрат ресурсов сервера при работе вашего творения. И хотя по большому счету анализ использования ресурсов сервера это работа администратора базы данных, иметь навыки по оптимизации программ никому не помешает. Тем более что это не так сложно, как кажется на первый взгляд.
Существует ряд программ позволяющих автоматизировать и упростить эту задачу. Данный материал ориентирован на работу с сервером Oracle , но и для других баз данных есть аналогичные средства анализа и оптимизации «тюнинга». Первым нашим помощником станет программа мониторинга работы сервера Oracle с названием « Spotlight on Oracle » фирмы Quest software (http://www.quest.com). Это очень мощный инструмент, предназначенный для контроля функционирования вашего сервера. Данная программа выполнена в необычной цветовой палитре, что резко выделяет ее от других продуктов. После запуска данной программы необходимо создать учетную запись пользователя для чего потребуется учетная запись SYS или запись с системными привилегиями DBA. Помощник создания новой учетной записи вызывается из меню “ File > User Wizard ”.
После создания учетной записи пользователя и соединением с сервером Oracle нам представляется визуальная картинка, которая отображает компоненты и процессы работы сервера. Если один, или несколько компонентов сервера работает не оптимально или с перегрузкой, то его цвет изменяется от зеленого до красного, в зависимости от степени перегрузки. Возможен мониторинг сразу нескольких серверов, список которых отображается в левой панели и так же меняет цвет. Иконка в панели задач также меняет цвет синхронно с программой, что позволяет оперативно реагировать при “свернутом” в приложении. Пример мониторинга показан на рисунке 1.
Очень полезной особенностью данной программы является система авто-рекомендаций решения проблем. Достаточно кликнуть мышкой по красному участку изображения, чтобы получить развернутое описание проблемы и возможные методы ее устранения. Если же все нормально, то благодаря данной программе можно подстроить параметры запуска сервера для уменьшения используемых им системных ресурсов. Например, по рисунку 1 можно сделать вывод, что размер табличного пространства файла базы данных можно смело уменьшить в два раза, и желательно выделить дополнительную память под “ Shared Pool ”.
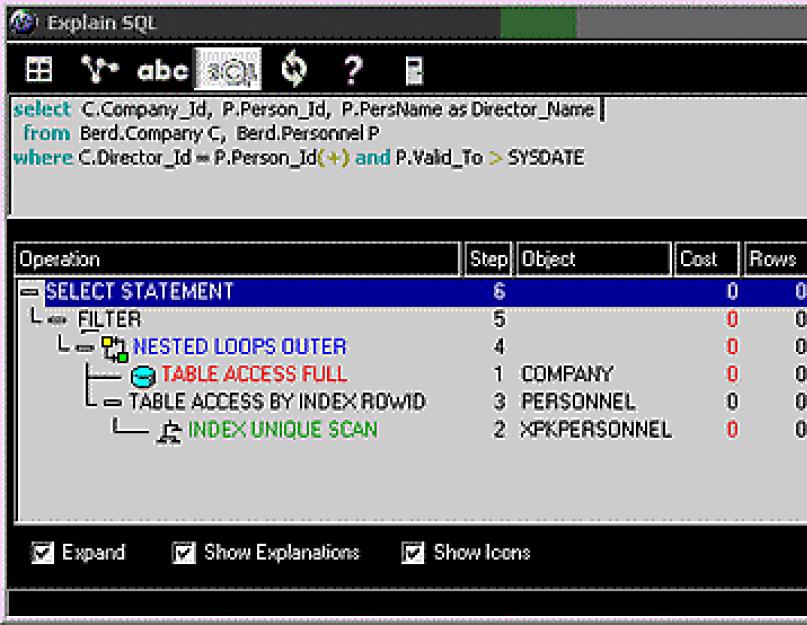
Но это все проблемы администратора базы данных. Разработчиков же больше волнует, как работают их творения и сколько ресурсов «кушают» запросы к базе данных. Для этого вызываем пункт меню “ Navigator > Top Sessions ”. После заполнения параметров фильтра отбора данных нам будет показан список текущих запросов к серверу базы данных. Предварительно отсортировав запросы по требованиям к ресурсам, можно выделить самые “прожорливые”. В этом же окне можно посмотреть план выполнения запроса, пример которого показан на рисунке 2. Причем план запросов можно представить в виде графа, дерева или словесного описания. Здесь так же используется цветовая маркировка проблемных участков.

После выявления проблемных SQL запросов настал черед их оптимизации. Для автоматизации этого процесса воспользуемся программой SQL Expert фирмы LECCO (http://www.leccotech.com). Вызываем окно SQL редактора и добавляем в него скрипт запроса. Здесь так же можно посмотреть план выполнения запроса. Но нас больше всего интересует функция меню “SQL-> Optimize ”, которая генерирует список альтернативных вариантов построения заданного SQL скрипта. А функция “SQL-> Butch Run ” позволяет проанализировать время выполнения всех запросов на “живых” данных и вывести результирующую таблицу, которую можно отсортировать по требуемому параметру. Выбрав наиболее оптимальный запрос, его можно сравнить с оригиналом и принять решение о возможности дальнейшего его использования в своем приложении. Пример работы по оптимизации запроса показан на рисунке 3.

Таким образом, используя предложенную методику, можно не затрагивая код основной программы порой существенно повысить производительность приложений и спасти проект. При этом, вы получите неоценимый опыт для написания высокопроизводительных запросов. Анализируя предложенные программой варианты SQL скриптов, со временем вырабатывается привычка писать сразу «оптимально», что так же повышает ваш имидж как хорошего специалиста.
Теперь настало время произвести оптимизацию самих условных операторов SQL. Большинство запросов используют директиву SQL WHERE, поэтому, оптимизируя условия, можно добиться значительной производительности запросов. При этом почему-то лишь небольшая часть приложений для БД используют оптимизацию условий.
AND
Очевидно, что в серии из нескольких операторов AND условия должны располагаться в порядке возрастания вероятности истинности данного условия. Это делается для того, чтобы при проверке условий БД не проверяла остальную часть условия. Эти рекомендации не относится к БД Oracle, где условия начинают проверяться с конца. Соответственно, их порядок должен быть обратным - по убыванию вероятности истинности.
OR
Ситуация с данным оператором прямо противоположна ситуации с AND. Условия должны располагаться в порядке убывания вероятности истинности. Фирма Microsoft настойчиво рекомендует использовать данный метод при построении запросов, хотя многие даже не знают об этом или, по крайней мере, не обращают на него внимание. Но опять-таки это не относится к БД Oracle, где условия должны располагаться по возрастанию вероятности истинности.
Еще одним условием для оптимизации можно считать тот факт, что если одинаковые колонки располагаются рядом, запрос выполняется быстрее. Например, запрос ".. WHERE column1 = 1 OR column2 = 3 OR column1 = 2" будет выполняться медленней, чем запрос "WHERE column1 = 1 OR column1 = 2 OR column2 = 3" . Даже если вероятность истинности условия column2 = 3 выше, чем column1 = 2.
Еще в школе мне рассказывали про распределительный закон. Он гласит, что A AND (B OR C) - то же самое, что и (A AND B) OR (A AND C ). Опытным путем было установлено, что запрос вида "...WHERE column1 = 1 AND (column2 = "A" OR column2 = "B")" выполняется несколько быстрее, чем "...WHERE (column1 = 1 AND column2 = "A") OR (column1 = 1 AND column2 = "B")" . Некоторые БД сами умеют оптимизировать запросы такого типа, но лучше перестраховаться.
NOT
Эту операцию всегда следует приводить к более "читабельному" виду (в разумных пределах, конечно). Так, запрос "...WHERE NOT (column1 > 5)" преобразуется в "...WHERE column1 <= 5" . Более сложные условия можно преобразовать используя правило де Моргана, которое ты тоже должен был изучить в школе. Согласно этому правилу NOT(A AND B) = (NOT A) OR (NOT B) и NOT(A OR B) = (NOT A) AND (NOT B) . Например, условие "...WHERE NOT (column1 > 5 OR column2 = 7)" преобразуется в более простую форму: ...WHERE column1 <= 5 AND column2 <> 7 .
IN
Многие наивно полагают, что запрос "... WHERE column1 = 5 OR column1 = 6" равносилен запросу "...WHERE column1 IN (5, 6)" . На самом деле это не так. Операция IN работает гораздо быстрее, чем серия OR. Поэтому всегда следует заменять OR на IN, где это возможно, несмотря на то, что некоторые БД сами производят эту оптимизацию. Там, где используется серия последовательных чисел, IN следует поменять на BETWEEN. Например, "...WHERE column1 IN (1, 3, 4, 5)" оптимизируется к виду: …WHERE column1 BETWEEN 1 AND 5 AND column1 <> 2 . И этот запрос действительно быстрее.
LIKE
Эту операцию следует использовать только при крайней необходимости, потому что лучше и быстрее использовать поиск, основанный на full-text индексах. К сожалению, я вынужден направить тебя за информацией о поиске на просторы всемирной паутины.
CASE
Сама эта функция может использоваться для повышения скорости работы запроса, когда в нем есть более одного вызова медленной функции в условии. Например, чтобы избежать повторного вызова slow_function() в запросе "...WHERE slow_function(column1) = 3 OR slow_function(column1) = 5" , нужно использовать CASE:
... WHERE 1 = CASE slow_function(column1)
WHEN 3 THEN 1
WHEN 5 THEN 1
Оптимизация неэффективного SQL, несомненно, важнейшее средство повышения производительности в арсенале аналитика по производительности Oracle. Если вызов базы данных порождает более десятка вызовов LIO для каждой строки, возвращаемой из каждой таблицы фразы FROM соответствующей команды SQL, то, скорее всего, производительность такой команды можно повысить. Например, операция соединения трех таблиц, возвращающая две строки, вероятно, должна требовать не более 60 вызовов LIO.
Любая относительная оценка при определенных условиях может оказаться неверной. Одним из таких условий является формирование результата запроса как итога агрегирования. Например, запрос, возвращающий сумму (одну строку) для таблицы из миллиона строк, вполне законно может требовать выполнения более десяти вызовов LIO.
Приложения, выполняющие код SQL, порождающий множество вызовов LIO, создает серьезные препятствия для масштабируемости систем с большим количеством пользователей. Лишние вызовы LIO не только отнимают мощность процессора, но и могут вызвать большое количество событий latch free для защелок cache buffers chains . Получение и освобождение защелок само по себе может привести к избыточному потреблению мощности процессора, особенно в конфигурациях, где аналитики увеличили значение, заданное для _SPIN_COUNT по умолчанию (обычно не стоит этого делать).
В настоящее время есть ряд полезных ресурсов по оптимизации SQL: .1 Участники разнообразных списков рассылки, например Oracle-L (http://www.cybcon.com/~jkstill), также делают замечательное дело, помогая друг другу писать эффективный код. Все эти ресурсы содержат хорошие советы о том, как писать эффективный SQL, применяя методы, часть из которых перечислена ниже:
Диагностика выполнения команд SQL посредством таких инструментов, как tkprof, EXPLAIN PLAN, и отладочных событий 10032, 10033,10046,10079,10104 и 10241.
Диагностика поведения оптимизатора запросов Oracle при помощи отладочного события, подобного 10053.
Работа с текстом SQL, направленная на использование более эффективных планов выполнения.
Выбор эффективной стратегии индексирования с тем, чтобы обеспечить сокращение объема данных для запросов без создания дополнительной нагрузки в операциях INSERT, UPDATE, MERGE и DELETE.
Применение хранимых планов выполнения с целью заставить оптимизатор запросов Oracle использовать выбранный вами план.
Создание приемлемой статистики для таблиц, индексов и базы данных с тем, чтобы наилучшим образом информировать оптимизатор запросов Oracle о ваших данных.
Разработка таких физических моделей данных, которые облегчают хранение и выборку в контексте приложения.
Разработка логических моделей данных, облегчающих хранение и выборку в контексте приложения.
Оптимизация разбора
Избыточный разбор - это верный путь к невозможности обеспечить масштабируемость приложения для работы с большим количеством пользователей . Студенты обычно приходят к нам, считая, что полные разборы (hard parses) значительно замедляют обработку транзакций, а вот в частичном разборе (soft parse) нет ничего страшного. Более того, иногда люди считают, что полного разбора можно избежать, а частичного - нет. Оба мнения верны лишь наполовину. Полные разборы действительно так ужасны, как о них думают, и их можно избежать, используя в коде SQL переменные связывания вместо литералов. Однако частичный разбор столь же ужасен, и часто без него тоже можно обойтись.
Многие авторы употребляют словосочетание «частичный разбор» (soft parse) как синоним для «вызова разбора» (parse call). Мне больше нравится термин «вызов разбора», т. к. он обращает наше внимание на приложение, внутри которого в действительности может быть предпринято спасительное действие. Если же говорить о «частичном разборе», то внимание акцентируется на базе данных, которая не является местом решения нашей проблемы. И вот почему. Каждый раз, когда серверный процесс Oracle получает вызов разбора от приложения, этому процессу необходимо использовать процессор сервера базы данных. Если будет обнаружен подходящий для этого запроса разделяемый курсор в кэше курсоров сеанса или библиотечном кэше Oracle, то вызов разбора никогда не приведет к полному разбору, и окажется, что затраты на разбор совсем не так велики, как могли бы быть. Однако отсутствие разбора обходится еще дешевле, чем частичный разбор. Наилучшую масштабируемость для большого количества пользователей имеют приложения, в которых разбор происходит как можно реже. Следует по возможности избавиться от всех ненужных вызовов разбора.
Для обеспечения масштабируемости лучше всего, чтобы приложения осуществляли минимально возможное количество вызовов базы данных. Именно в этом направлении развивается Oracle Call Interface (OCI). Например, в версии 8 OCI предприняты меры для снижения количества пересылок между клиентом и сервером (http://otn.oracle.com/tech/oci/htdocs/Developing_apps.html). Версия 9.2 OCI идет еще дальше, делая так, что многие вызовы базы данных приложения вообще не достигают базы дан ных (http://otn.oracle.com/tech/oci/htdocs/oci9ir2_new_features).
В системах с высокой конкурентностью и неоправданно многочисленными вызовами разбора большое количество событий CPU service зачастую коррелирует с большим количеством событий ожидания latch free для библиотечного кэша, разделяемого пула и других защелок. Само по себе получение и освобождение защелок может привести к избыточному потреблению мощности процессора, особенно в конфигурациях, где аналитики увеличили значение, заданное для SPINCOUNT по умолчанию (опять-таки, обычно не стоит этого делать). Более того, избыточные вызовы разбора могут привести к ненужным задержкам SQL*Net message from client, способным добавить до нескольких секунд лишнего време ни отклика на каждую секунду реальной работы, выполняемой в базе данных. Наконец, вызовы разбора для длинных фрагментов SQL создают ненужные задержки SQL*Net more data from client, которые также могут внести существенный вклад в увеличение времени отклика.
Если ухудшение производительности вызвано большим количеством вызовов разбора, то можно воспользоваться следующими способами снижения нагрузки:
Старайтесь обходиться без строковых литералов в инструкциях WHERE. Заменяйте их переменными связывания (заполнителями), особенно когда строковый литерал имеет высокую кардинальность (т. е. строка может иметь множество значений). Использование строковых литералов вместо переменных связывания приводит к затратам процессорного времени (CPU service), а также вызывает в системах с высокой конкурентностью ненужные события ожидания освобождения защелок для библиотечного кэша, разделяемого пула и объектов кэша строк.
Пример 11.2. Разбор внутри цикла серьезно препятствует масштабируемости
Отключите те функции интерфейсного драйвера, которые приводят к увеличению количества вызовов разбора по отношению к их числу в исходном коде приложения. Например, Perl DBI содержит атрибут уровня prepare под названием ora_check_sql. Его значение по умолчанию равно 1, что означает два вызова разбора для каждого вызова функции Perl prepare. Первый вызов разбора выполняется с тем, чтобы помочь SQL-разработчику приложения быстрее отладить свой исходный код за счет предоставления более подробной диагностической информации для неудачных вызовов разбора. Од нако в промышленных системах такую функцию следует отключить, т. к. она приводит к излишним вызовам разбора.
Поделюсь опытом, который получил за несколько лет оптимизации sql запросов. Большая часть советов касается субд ORACLE.
Если кому статья покажется слишком очевидной, то считайте это заметкой чисто для себя, чтобы не забыть.
1. Ни каких подзапросов, только JOIN
Как я уже писал ранее , если выборка 1 к 1 или надо что-то просуммировать, то ни каких подзапросов, только join.
Стоит заметить, что в большинстве случаев оптимизатор сможет развернуть подзапрос в join, но это может случиться не всегда.
2. Выбор IN или EXISTS ?
На самом деле это сложный выбор и правильное решение можно получить только опытным путем.
Я дам только несколько советов:
* Если в основной выборке много строк, а в подзапросе мало, то ваш выбор IN
. Т.к. в этом случае запрос в in выполнится один раз и сразу ограничит большую основную таблицу.
* Если в подзапросе сложный запрос, а в основной выборке относительно мало строк, то ваш выбор EXISTS
. В этом случае сложный запрос выполнится не так часто.
* Если и там и там сложно, то это повод изменить логику на джойны.
3. Не забывайте про индексы
Совет для совсем новичков: вешайте индексы на столбцы по которым джойните таблицы.
4. По возможности не используйте OR.
Проведите тесты, возможно UNION выглядит не так элегантно, за то запрос может выполнится значительно быстрей. Причина в том, что в случае OR индексы почти не используются в join.
5. По возможности не используйте WITH
в oracle.
Значительно облегчает жизнь, если запрос в with необходимо использовать несколько раз (с хинтом materialize) в основной выборке или если число строк в подзапросе не значительно.
Во всех других случаях необходимо использовать прямые подзапросы в from или взаранее подготовленную таблицу с нужными индексами и данными из WITH.
Причина плохой работы WITH в том, что при его джойне не используются ни какие индексы и если данных в нем много, то все встанет. Вторая причина в том, что оптимизатору сложно определить сколько данных нам вернет with и оптимизатор не может построить правильный план запроса.
В большинстве случаев WITH без +materialize все равно будет развернут в основной запрос.
6. Не делайте километровых запросов
Часто в web обратная проблема - это много мелких запросов в цикле и их советуют объединить в один большой. Но тут есть свои ограничения, если у вас запрос множество раз обернутый в from, то внутреннюю(ие) части надо вынести в отдельную выборку, заполнить временную таблицу, навесить индексы, а потом использовать ее в основной выборке. Скорость работы будет значительно выше (в первую очередь из-за сложности построения оптимального плана на большом числе сочетаний таблиц)
7. Используйте KEEP взамен корреляционных подзапросов.
В ORACLE есть очень полезные аналитические функции , которые упростят ваши запросы. Один из них - это KEEP.
KEEP позволит сделать вам сортировку или группировку основной выборки без дополнительно запроса.
Пример: отобрать контрагента для номенклатуры, который раньше остальных был к ней подвязан. У одной номенклатуры может быть несколько поставщиков.
SELECT n.ID, MIN(c.ID) KEEP (DENSE_RANK FIRST ORDER BY c.date ASC) as cnt_id
FROM nmcl n, cnt c
WHERE n.cnt_id = c.id
GROUP BY n.ID
При обычном бы подходе пришлось бы делать корреляционный подзапрос для каждой номенклатуры с выбором минимальной даты.
Но не злоупотребляйте большим числом аналитических функций, особенно если они имеют разные сортировки. Каждая разная сортировка - это новое сканирование окна.
8. Гуляние по выборке вверх-вниз
Менее популярная функция, но не менее полезная. Позволяет смещать текущую строку выборки на N элементов вверх или вниз. Бывает полезно, если необходимо сравнить показатели рядом стоящих строк.
Следующий пример отбирает продажи департаментов отсортированных по дате. К основной выборке добавляются столбцы со следующим и предыдущим значением выручки. Второй параметр - это на сколько строк сместиться, третьи - параметр по-умолчанию, если данные соседа не нашлись.
SELECT deptno, empno, sal,
LEAD(sal, 1, 0) OVER (PARTITION BY dept ORDER BY date) NEXT_LOWER_SAL,
LAG(sal, 1, 0) OVER (PARTITION BY dept ORDER BY date) PREV_HIGHER_SAL
FROM emp;
ORDER BY deptno, date DESC;
При обычном подходе бы пришлось это делать через логику приложения.
9. Direct Path Read
Установка этой настройки (настройкой или параллельным запросом) - чтение данных напрямую в PGA, минуя буферный кэш. Что укоряет последующие этапы запроса, т.к. не используется UNDO и защелки совместного доступа.
10. Direct IO
Использование прямой записи/чтения с диска без использования буфера файловой системы (файловая система конкретно для СУБД).
* В случае чтения преимущество в использовании буферного кэша БД, замен кэша ФС (кэш бд лучше заточен на работу с sql)
* В случае записи, прямая запись гарантирует, что данные не потеряются в буфере ФС в случае выключения электричества (для redolog всегда использует fsync, в не зависимости от типа ФС)