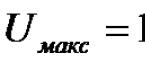
Здравствуйте! Я Александр Макаров, и вы можете меня знать по фреймворку «Yii» — я один из его разработчиков. У меня также есть full-time работа — и это уже не стартап — Stay.com, который занимается путешествиями.
Сегодня я буду рассказывать про горизонтальное масштабирование, но в очень-очень общих словах.
Что такое масштабирование, вообще? Это возможность увеличить производительность проекта за минимальное время путем добавления ресурсов.
Обычно масштабирование подразумевает не переписывание кода, а либо добавление серверов, либо наращивание ресурсов существующего. По этому типу выделяют вертикальное и горизонтальное масштабирование.
Вертикальное — это когда добавляют больше оперативки, дисков и т.д. на уже существующий сервер, а горизонтальное — это когда ставят больше серверов в дата-центры, и сервера там уже как-то взаимодействуют.
Самый классный вопрос, который задают, — а зачем оно надо, если у меня все и на одном сервере прекрасно работает? На самом-то деле, надо проверить, что будет. Т.е., сейчас оно работает, но что будет потом? Есть две замечательные утилиты — ab и siege, которые как бы нагоняют тучу пользователей конкурента, которые начинают долбить сервер, пытаются запросить странички, послать какие-то запросы. Вы должны указать, что им делать, а утилиты формируют такие вот отчеты:

Главные два параметра: n — количество запросов, которые надо сделать, с — количество одновременных запросов. Таким образом они проверяют конкурентность.
На выходе получаем RPS, т.е. количество запросов в секунду, которое способен обработать сервер, из чего станет понятно, сколько пользователей он может выдержать. Все, конечно, зависит от проекта, бывает по-разному, но обычно это требует внимания.
Есть еще один параметр — Responce time — время ответа, за которое в среднем сервер отдал страничку. Оно бывает разное, но известно, что около 300 мс — это норма, а что выше — уже не очень хорошо, потому что эти 300 мс отрабатывает сервер, к этому прибавляются еще 300-600 мс, которые отрабатывает клиент, т.е. пока все загрузится — стили, картинки и остальное — тоже проходит время.
Бывает, что на самом деле пока и не надо заботиться о масштабировании — идем на сервер, обновляем PHP, получаем 40% прироста производительности и все круто. Далее настраиваем Opcache, тюним его. Opcache, кстати, тюнится так же, как и APC, скриптом, который можно найти в репозитории у Расмуса Лердорфа и который показывает хиты и мисы, где хиты — это сколько раз PHP пошел в кэш, а мисы — сколько раз он пошел в файловую систему доставать файлики. Если прогнать весь сайт, либо запустить туда какой-то краулер по ссылкам, либо вручную потыкать, то у нас будет статистика по этим хитам и мисам. Если хитов 100%, а мисов — 0%, значит, все нормально, а если есть мисы, то надо выделить больше памяти, чтобы весь наш код влез в Opcache. Это частая ошибка, которую допускают — вроде Opcache есть, но что-то не работает…
Еще часто начинают масштабировать, но не смотрят, вообще, из-за чего все работает медленно. Чаще всего лезем в базу, смотрим — индексов нет, ставим индексы — все сразу залетало, еще на 2 года хватит, красота!
Ну, еще надо включить кэш, заменить apache на nginx и php-fpm, чтобы сэкономить память. Будет все классно.
Все перечисленное достаточно просто и дает вам время. Время на то, что когда-то этого станет мало, и к этому уже сейчас надо готовиться.
Как, вообще, понять, в чем проблема? Либо у вас уже настал highload, а это не обязательно какое-то бешеное число запросов и т.д., это, когда у вас проект не справляется с нагрузкой, и тривиальными способами это уже не решается. Надо расти либо вширь, либо вверх. Надо что-то делать и, скорее всего, на это мало времени, что-то надо придумывать.
Первое правило — никогда ничего нельзя делать вслепую, т.е. нам нужен отличный мониторинг. Сначала мы выигрываем время на какой-то очевидной оптимизации типа включения кэша или кэширования Главной и т.п. Потом настраиваем мониторинг, он нам показывает, чего не хватает. И все это повторяется многократно – останавливать мониторинг и доработку никогда нельзя.
Что может показать мониторинг? Мы можем упереться в диск, т.е. в файловую систему, в память, в процессор, в сеть… И может быть такое, что, вроде бы, все более-менее, но какие-то ошибки валятся. Все это разрешается по-разному. Можно проблему, допустим, с диском решить добавлением нового диска в тот же сервер, а можно поставить второй сервер, который будет заниматься только файлами.
На что нужно обращать внимание прямо сейчас при мониторинге? Это:
- доступность, т.е. жив сервер, вообще, или нет;
- нехватка ресурсов диска, процессора и т.д.;
- ошибки.
Как это все мониторить?
Вот список замечательных инструментов, которые позволяют мониторить ресурсы и показывать результаты в очень удобном виде:
Первые 4 инструмента можно поставить на сервер, они мощные, классные. А ServerDensity хостится у кого-то, т.е. мы за нее платим деньги, и она может собирать с серверов все данные и отображать их для анализа.
Для мониторинга ошибок есть два хороших сервиса:
Обычно мы мониторим ошибки так — либо пишем все в лог и потом смотрим его, либо дополнительно к этому начинаем email"ы или смс-ки слать разработчикам. Это все нормально, но как только у нас набегает туча народа на сервис, и есть там какая-то ошибка, она начинает повторяться очень большое количество раз, начинает бешено спамить email либо он, вообще, переполняется, или же у разработчика полностью теряется внимание и он начинает письма игнорировать. Вышеуказанные сервисы берут и ошибки одного и того же типа собирают в одну большую пачку, плюс они считают, сколько раз ошибки произошли за последнее время и в приоритетах автоматом поднимают все это дело.
Sentry можно поставить к себе на сервер, есть исходник, а Rollbar — нет, но Rollbar лучше, потому что он берет деньги за количество ошибок, т.е. стимулирует их исправлять.
Про нотификации повторю, что спамить не стоит, теряется внимание.
Что, вообще, надо анализировать?

RPS и Responce time — если у нас начинает время ответа падать, то надо что-то делать.
Количество процессов, потоков и размеры очередей — если это все начинает плодиться, забиваться и т.д., то что-то здесь опять не так, надо анализировать более детально и как-то менять инфраструктуру.
Также стоит смотреть на бизнес-анализ. Google Analytics для сайтовых типов отлично подходит, а mixpanel — для логирования ивентов, он работает на десктопных приложениях, на мобильных, на веб. Можно и на основе каких-то своих данных писать, но я бы советовал готовые сервисы. Смысл в том, что наш мониторинг может показывать, что сервис жив, что все работает, что общий Responce time нормальный, но когда мы, допустим, регистрацию в mixpanel"е начинаем трекать, он показывает, что их как-то маловато. В этом случае надо смотреть, насколько быстро отрабатывают определенные ивенты, страницы, и в чем состоят проблемы. Проект всегда должен быть «обвешан» анализом, чтобы всегда знать, что происходит, а не работать вслепую.
Нагрузка, вообще, возникает или запланировано, или нет, может возникать постепенно, может не постепенно:

Как бороться с нагрузкой? Решает все бизнес, и важна только цена вопроса. Важно:
- чтобы сервис работал,
- чтобы это было не сильно дорого, не разорило компанию.
Остальное не очень важно.

Если дешевле попрофайлить, оптимизировать, записать в кэш, поправить какие-то конфиги, то это и надо делать, не задумываясь пока о масштабировании и о том, чтобы докупать «железо» и т.д. Но бывает, что «железо» становится дешевле, чем работа программиста, особенно, если программисты очень подкованные. В этом случае уже начинается масштабирование.

На рисунке синяя штука — это Интернет, из которого идут запросы. Ставится балансировщик, единственная задача которого — распределить запросы на отдельные фронтенды-сервера, принять от них ответы и отдать клиенту. Смысл тут в том, что 3 сервера могут обработать (в идеале) в 3 раза больше запросов, исключая какие-то накладные расходы на сеть и на саму работу балансировщика.
Что это нам дает? Указанную выше возможность обработать больше запросов, а еще надежность. Если в традиционной схеме валится nginx или приложение, или в диск уперлись и т.п., то все встало. Здесь же, если у нас один фронтенд отвалился, то ничего страшного, балансировщик, скорее всего, это поймет и отправит запросы на оставшиеся 2 сервера. Может, будет чуть помедленнее, но это не страшно.
Вообще, PHP — штука отличная для масштабирования, потому что он следует принципу Share nothing по умолчанию. Это означает, что если мы возьмем, допустим, Java для веба, то там приложение запускается, читает весь код, записывает по максимуму данных в память программы, все там крутится, работает, на request уходит очень мало времени, очень мало дополнительных ресурсов. Однако есть засада — т.к. приложение написано так, что оно должно на одном инстансе работать, кэшироваться, читать из своей же памяти, то ничего хорошего у нас при масштабировании не получится. А в PHP по умолчанию ничего общего нет, и это хорошо. Все, что мы хотим сделать общим, мы это помещаем в memcaсhed, а memcaсhed можно читать с нескольких серверов, поэтому все замечательно. Т.е. достигается слабая связанность для слоя серверов приложений. Это прекрасно.
Чем, вообще, балансировать нагрузку?
Чаще всего это делали Squid"ом или HAProxy, но это раньше. Сейчас же автор nginx взял и партировал из nginx+ балансировщик в nginx, так что теперь он может делать все то, что раньше делали Squid"ом или HAProxy. Если оно начинает не выдерживать, можно поставить какой-нибудь крутой дорогой аппаратный балансировщик.
Проблемы, которые решает балансировщик — это как выбрать сервер и как хранить сессии? Вторая проблема — чисто PHP"шная, а сервер может выбираться либо по очереди из списка, либо по географии каких-то IP"шников, либо по какой-то статистике (nginx поддерживает least-connected, т.е. к какому серверу меньше коннектов, на него он и будет перекидывать). Можем написать для балансировщика какой-то код, который будет выбирать, как ему работать.

Что, если мы упремся в балансировщик?
Есть такая штука как DNS Round robin — это замечательный трюк, который позволяет нам не тратиться на аппаратный балансировщик. Что мы делаем? Берем DNS-сервер (обычно DNS-сервера у себя никто не хостит, это дорого, несильно надежно, если он выйдет из строя, то ничего хорошего не получится, все пользуются какими-то компаниями), в А-записи прописываем не один сервер, а несколько. Это будут А-записи разных балансировщиков. Когда браузер туда идет (гарантий, на самом деле, нет, но все современные браузеры так действуют), он выбирает по очереди какой-нибудь IP-адрес из А-записей и попадает либо на один балансировщик, либо на второй. Нагрузка, конечно, может размазываться не равномерно, но, по крайней мере, она размазывается, и балансировщик может выдержать немного больше.
Что делать с сессиями?
Сессии у нас по умолчанию в файлах. Это не дело, потому что каждый из серверов-фронтендов у нас будет держать сессии в своей файловой системе, а пользователь может попадать то на один, то на второй, то на третий, т.е. сессии он будет каждый раз терять.
Возникает очевидное желание сделать общую файловую систему, подключить NFS. Но делать так не надо — она до жути медленная.
Можно записать в БД, но тоже не стоит, т.к. БД не оптимальна для этой работы, но если у вас нет другого выхода, то, в принципе, сойдет.
Можно писать в memcached, но очень-очень осторожно, потому что memcached — это, все-таки, кэш и он имеет свойство вытираться, как только у него мало ресурсов, или некуда писать новые ключи — тогда он начинает терять старые без предупреждения, сессии начинают теряться. За этим надо либо следить, либо выбрать тот же Redis.
Redis — нормальное решение. Смысл в том, что Redis у нас на отдельном сервере, и все наши фронтенды ломятся туда и начинают с Redis"а свои сессии считывать. Но Redis однопоточный и рано или поздно можем хорошенько упереться. Тогда делают sticky-сессии. Ставится тот же nginx и сообщается ему, что нужно сделать сессии так, чтобы юзер, когда он пришел на сервер и ему выдалась сессионная coockies, чтобы он впоследствии попадал только на этот сервер. Чаще всего это делают по IP-хэшу. Получается, что если Redis на каждом инстансе, соответственно, сессии там свои, и пропускная способность чтения-записи будет гораздо лучше.
Как насчет coockies? Можно писать в coockies, никаких хранилищ не будет, все хорошо, но, во-первых, у нас все еще куда-то надо девать данные о сессии, а если мы начнем писать в coockies, она может разрастись и не влезть в хранилище, а, во-вторых, можно хранить в coockies только ID, и нам все равно придется обращаться к БД за какими-то сессионными данными. В принципе, это нормально, решает проблему.
Есть классная штука — прокси для memcached и Redis:

Они, вроде как, поддерживают распараллеливание из коробки, но делается это, я не сказал бы, что очень оптимально. А вот эта штука — twemproxy — она работает примерно как nginx с PHP, т.е. как только ответ получен, он сразу отправляет данные и в фоне закрывает соединение, получается быстрее, меньше ресурсов потребляет. Очень хорошая штука.

Очень часто возникает такая ошибка «велосипедирования», когда начинают писать, типа «мне сессии не нужны! я сейчас сделаю замечательный токен, который будет туда-сюда передаваться»… Но, если подумать, то это опять же сессия.
В PHP есть такой механизм как session handler, т.е. мы можем поставить свой handler и писать в coockies, в БД, в Redis — куда угодно, и все это будет работать со стандартными session start и т.д.

Сессии надо закрывать вот этим замечательным методом.
Как только мы из сессии все прочитали, мы не собираемся туда писать, ее надо закрыть, потому что сессия частенько блокируется. Она, вообще-то, должна блокироваться, потому что без блокировок будут проблемы с конкурентностью. На файлах это видно сразу, на других хранилищах блокировщики бывают не на весь файл сразу, и с этим немного проще.
Что делать с файлами?
С ними можно справляться двумя способами:
- какое-то специализированное решение, которое дает абстракцию, и мы работаем с файлами как с файловой системой. Это что-то вроде NFS, но NFS не надо.
- «шардирование» средствами PHP.
Специализированные решения из того, что действительно работает, — это GlusterFS. Это то, что можно поставить себе. Оно работает, оно быстрое, дает тот же интерфейс, что NFS, только работает с нормальной терпимой скоростью.
И Amazon S3 — это, если вы в облаке Amazon"а, — тоже хорошая файловая система.
Если вы реализуете со стороны PHP, есть замечательная библиотека Flysystem, покрытая отличными тестами, ее можно использовать для работы со всякими файловыми системами, что очень удобно. Если вы сразу напишете всю работу с файлами с этой библиотекой, то потом перенести с локальной файловой системы на Amazon S3 или др. будет просто — в конфиге строчку переписать.
Как это работает? Пользователь из браузера загружает файл, тот может попадать либо на фронтенд и оттуда расползаться по файловым серверам, либо на каждом файловом сервере делается скрипт для аплоада и файл заливается сразу в файловую систему. Ну и, параллельно в базу пишется, какой файл на каком сервере лежит, и мы читать его можем непосредственно оттуда.
Лучше всего раздавать файлы nginx"ом или Varnish"ем, но лучше все делать nginx"ом, т.к. мы все его любим и используем — он справится, он хороший.

Что у нас происходит с базой данных?
Если у вас все уперлось в код PHP, мы делаем кучу фронтендов и все еще обращаемся к одной БД — она справится достаточно долгое время. Если нагрузка не страшная, то БД живет хорошо. Например, мы делали JOIN"ы по 160 млн. строк в таблице, и все было замечательно, все бегало хорошо, но там, правда, оперативки надо больше выделить на буферы, на кэш…
Что делать с БД, если мы уперлись в нее? Есть такие техники как репликация. Обычно делается репликация мастер-слэйв, есть репликация мастер-мастер. Можно делать репликацию вручную, можно делать шардирование и можно делать партицирование.
Что такое мастер-слэйв?

Выбирается один сервер главным и куча серверов — второстепенными. На главный пишется, а читать мы можем с мастера, а можем и со слэйвов (на картинке красные стрелочки — это то, что мы пишем, зеленые — то, что мы читаем). В типичном проекте у нас операций чтения гораздо больше, чем операций записи. Бывают нетипичные проекты.
В случае типичного проекта большое количество слэйвов позволяет разгрузить как мастер, так и, вообще, увеличить скорость чтения.
Также это дает отказоустойчивость — если упал один из слэйвов, то делать ничего не надо. Если упал мастер, мы можем достаточно быстро сделать один из слэйвов мастером. Правда, это обычно не делается автоматически, это внештатная ситуация, но возможность есть.
Ну, и бэкапы. Бэкапы базы все делают по-разному, иногда это делается MySQL-дампом, при этом он фризит весь проект намертво, что не очень хорошо. Но если делать бэкап с какого-нибудь слэйва, предварительно остановив его, то пользователь ничего не заметит. Это прекрасно.
Кроме этого, на слэйвах можно делать тяжелые вычисления, чтобы не затронуть основную базу, основной проект.
Есть такая штука как read/write split.Делается 2 пула серверов — мастер, слэйв, соединение по требованию, и логика выбора соединения варьируется. Смысл в том, что если мы будем всегда читать со слэйвов, а писать всегда в мастер, то будет небольшая засада:

т.е. репликация выполняется не немедленно, и нет гарантий, что она выполнилась, когда мы делаем какой-либо запрос.
Есть два типа выборок:
- для чтения или для вывода;
- для записи, т.е., когда мы что-то выбрали и потом это что-то надо изменить и записать обратно.
Если выборка для записи, то мы можем либо всегда читать с мастера и писать на мастер, либо мы можем выполнить «SHOW SLAVE STATUS» и посмотреть там Seconds_Behind_Master (для PostgreSQL тоже супер-запрос есть на картинке) — он покажет нам число. Если это 0 (нуль), значит, все у нас уже реплицировалось, можно смело читать со слэйва. Если число больше нуля, то надо смотреть значение — либо нам стоит подождать немного и тогда прочитать со слэйва, либо сразу читать с мастера. Если у нас NULL, значит еще не реплицировали, что-то застряло, и надо смотреть логи.
Причины подобного лага — это либо медленная сеть, либо не справляется реплика, либо слишком много слэйвов (больше 20 на 1 мастер). Если медленная сеть, то понятно, ее надо как-то ускорять, собирать в единые дата-центры и т.д. Если не справляется реплика, значит надо добавить реплик. Если же слишком много слэйвов, то надо уже придумывать что-то интересное, скорее всего, делать какую-то иерархию.
Что такое мастер-мастер?

Это ситуация, когда стоит несколько серверов, и везде и пишется, и читается. Плюс в том, что оно может быть быстрее, оно отказоустойчивое. В принципе, все то же, что и у слэйвов, но логика, вообще, простая — мы просто выбираем рандомное соединение и с ним работаем. Минусы: лаг репликации выше, есть шанс получить какие-то неконсистентные данные, и, если произошла какая-нибудь поломка, то она начинает раскидываться по всем мастерам, и никому уже неизвестно, какой мастер нормальный, какой поломался… Это все дело начинает реплицироваться по кругу, т.е. очень неслабо забивает сеть. Вообще, если пришлось делать мастер-мастер, надо 100 раз подумать. Скорее всего, можно обойтись мастер-слэйвом.
Можно делать репликацию всегда руками, т.е. организовать пару соединений и писать сразу в 2, в 3, либо что-то делать в фоне.
Что такое шардирование?
Фактически это размазывание данных по нескольким серверам. Шардировать можно отдельные таблицы. Берем, допустим, таблицу фото, таблицу юзеров и др., растаскиваем их на отдельные сервера. Если таблицы были большие, то все становится меньше, памяти ест меньше, все хорошо, только нельзя JOIN"ить и приходится делать запросы типа WHERE IN, т.е. сначала выбираем кучу ID"шников, потом все эти ID"шники подставляем запросу, но уже к другому коннекту, к другому серверу.
Можно шардировать часть одних и тех же данных, т.е., например, мы берем и делаем несколько БД с юзерами.

Можно достаточно просто выбрать сервер — остаток от деления на количество серверов. Альтернатива — завести карту, т.е. для каждой записи держать в каком-нибудь Redis"е или т.п. ключ значения, т.е. где какая запись лежит.
Есть вариант проще:

Сложнее — это когда не удается сгруппировать данные. Надо знать ID данных, чтобы их достать. Никаких JOIN, ORDER и т.д. Фактически мы сводим наш MySQL или PostgreSQL к key-valuе хранилищу, потому что мы с ними ничего делать не можем.
Обычные задачи становятся необычными:
- Выбрать TOP 10.
- Постраничная разбивка.
- Выбрать с наименьшей стоимостью.
- Выбрать посты юзера X.
Если мы зашардировали так, что все разлетелось по всем серверам, это уже начинает решаться очень нетривиально. В этой ситуации возникает вопрос — а зачем нам, вообще SQL? Не писать ли нам в Redis сразу? А правильно ли мы выбрали хранилище?
Из коробки шардинг поддерживается такими штуками как:
- memcache;
- Redis;
- Cassandra (но она, говорят, с какого-то момента не справляется и начинает падать).
Как быть со статистикой?
Часто статистику любят считать с основного сервера — с единственного сервера БД. Это прекрасно, но запросы в статистике обычно жуткие, многостраничные и т.д., поэтому считать статистику по основным данным — это большая ошибка. Для статистики в большинстве случаев realtime не нужен, так что мы можем настроить мастер-слэйв репликацию и на слэйве эту статистику уже посчитать. Или мы можем взять что-нибудь готовое — Mixpanel, Google Analytics или подобное.

Это основная идея, которая помогает раскидывать все по разным серверам и масштабировать. Во-первых, от этого сразу виден профит — даже если у вас один сервер и вы начинаете в фоне что-то выполнять, юзер получает ответ гораздо быстрее, но и впоследствии размазывать нагрузку, т.е. мы можем перетащить всю эту обработку на другой сервер, можно обрабатывать даже не на PHP. Например, в Stay.com картинки ресайзятся на Go.
Можно сразу взять Gearman. Это готовая штука для обработки в фоне. Есть под PHP библиотеки, драйвера… А можно использовать очереди, т.е. ActiveMQ, RabbitMQ, но очереди пересылают только сообщения, сами обработчики они не вызывают, не выполняют, и тогда придется что-то придумывать.
Общий смысл всегда один — есть основное ПО, которое помещает в очереди какие-то данные (обычно это «что сделать?» и данные для этого), и какой-то сервис – он либо достает, либо ему прилетают (если очередь умеет активно себя вести) эти данные, он все обрабатывает в фоне.
Перейдем к архитектуре.
Самое главное при масштабировании — это в проекте сделать как можно меньше связанности. Чем меньше связанности, тем проще менять одно решение на другое, тем проще вынести часть на другой сервер.
Связанность бывает в коде. SOLID, GRASP — это принципы, которые позволяют избежать связанности именно в коде. Но связанность в коде на разнос по серверам, конечно, влияет, но не настолько, насколько связанность доменного слоя с нашим окружением. Если мы в контроллере пишем много-много кода, получается, что в другом месте мы это использовать, скорее всего, не сможем. Нам непросто будет все это переносить из веб-контроллера в консоль и, соответственно, сложнее переносить на другие сервера и там обрабатывать по-другому.

Service-oriented architecture.
Есть 2 подхода разбиения систем на части:
- когда бьют на технические части, т.е., например, есть очередь, вынесли сервис очередей, есть обработка изображений, вынесли и этот сервис и т.д.
Это хорошо, но когда эти очереди, изображения и т.п. взаимодействуют в рамках двух доменных областей… Например, в проекте есть область Sales и область Customer — это разные области, с ними работают разные пользователи, но и у тех, и у тех есть разные очереди. Когда все начинает сваливаться в кучу, проект превращается в месиво;
- правильное решение — бить на отдельные логические части, т.е. если в областях Sales и Customer используется модель user, то мы создаем 2 модели user. Они могут читать одни и те же данные, но представляют они их немного по-разному. Если разбить систему таким образом, то все гораздо лучше воспринимается и намного проще все это раскидать.
Еще важно то, что части всегда должны взаимодействовать через интерфейсы. Так, в нашем примере, если Sales с чем-то взаимодействует, то он не пишет в БД, не использует общую модель, а с другими областями «разговаривает» через определенный контракт.
Что с доменным слоем?
Доменный слой разбивается на какие-то сервисы и т.п. — это важно для разработки приложения, но для масштабирования его проектирование не очень-то и важно. В доменном слое сверхважно отделить его от среды, контекста, в котором он выполняется, т.е. от контроллера, консольного окружения и т.д., чтобы все модели можно было использовать в любом контексте.
Есть 2 книги про доменный слой, которые всем советую:
- «Domain-Driven Design: Tackling Complexity in the Heart of Software» от Eric Evans,
- «Implementing Domain-Driven Design, Implementing Domain-Driven Design».
- про BoundedContext — http://martinfowler.com/bliki/BoundedContext.html (то, о чем было выше — если у вас две области вроде как пересекаются, но они
разные, то стоит некоторые сущности продублировать, такие как модель user); - про DDD в общем — — ссылка еще на одну книгу.
В архитектуре, опять же, стоит придерживаться принципа share nothing, т.е. если вы хотите что-то сделать общим, делайте это всегда сознательно. Логику предпочтительно закидывать на сторону приложения, но и в этом стоит знать меру. Никогда не стоит, допустим, делать хранимые процедуры в СУБД, потому что масштабировать это очень тяжело. Если это перенести на сторону приложения, то становится проще — сделаем несколько серверов и все будет выполняться там.
Не стоит недооценивать браузерную оптимизацию. Как я уже говорил, из тех 300-600 мс, которые запросы выполняются на сервере, к ним прибавляется 300-600 мс, которые тратятся на клиенте. Клиенту все равно, сервер ли у нас быстрый, или это сайт так быстро отработал, поэтому советую использовать Google PageSpeed и т.д.
Как обычно, абстракция и дробление совсем не бесплатны. Если мы раздробим сервис на много микросервисов, то мы больше не сможем работать с новичками и придется много-много платить нашей команде, которая будет во всем этом рыться, все слои перебирать, кроме этого сервис может начать медленнее работать. Если в компилируемых языках это не страшно, то в PHP, по крайней мере, до версии 7, это не очень…
Никогда не действуйте вслепую, всегда мониторьте, анализируйте. Вслепую практически все решения по умолчанию неправильные. Думайте! Не верьте, что существует «серебряная пуля», всегда проверяйте.
Еще немного ссылок полезных:

Контакты
Этот доклад - расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем за 2015 год.
Старьё! - скажите вы.
- Вечные ценности! - ответим мы.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем - это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость - мы начали подготовку весеннего фестиваля "Российские интернет-технологии ", в который входит восемь конференций, включая HighLoad++ Junior .
Модель доверенная подсистема (или доверенный сервер)
В некоторых ситуациях может потребоваться более одного доверенного удостоверения, например, при наличии двух групп пользователей, одна из которых должна быть авторизована на осуществление операций чтения/записи, а другая – только операций чтения. Использование множества доверенных удостоверений сервиса обеспечивает возможность более детального контроля доступа к ресурсам и аудита без особого влияния на масштабируемость. На рис. 14 показана модель с применением множества доверенных удостоверений сервиса.
Модель с применением множества доверенных удостоверений сервиса
Вертикальное и горизонтальное масштабирование
Подход к реализации масштабирования является критически важным аспектом проектирования. Независимо от того, планируется ли выполнять горизонтальное
масштабирование решения с помощью кластера с балансировкой нагрузки или секционированной базы данных, дизайн должен обеспечивать поддержку выбранной опции. Существует два основных типа масштабирования: вертикальное (большой блок) и
горизонтальное (больше блоков).
При вертикальном масштабировании поддержка повышенной нагрузки обеспечивается через введение в существующие серверы дополнительного оборудования, такого как процессоры, оперативная память и сетевые интерфейсные платы (network interface cards, NIC). Такой простой вариант не добавляет затрат на обслуживание и поддержку, но может быть экономически выгодным лишь до определенного момента. Однако всегда сохраняется вероятность сбоя, что является риском. Кроме того, введение дополнительного оборудования в существующие серверы обеспечивает желаемые результаты не бесконечно, и получение последних 10% расчетной производительности путем наращивания мощностей одного компьютера может быть очень дорогим удовольствием.
Эффективного вертикального масштабирования приложения можно добиться лишь при условии соответствующего вертикального масштабирования базовой инфраструктуры, среды выполнения и архитектуры компьютера. Продумайте, какие ресурсы ограничивают производительность приложения. Например, если это связано с нехваткой памяти или низкой пропускной способностью сети, добавление процессоров ничего не даст.
При горизонтальном масштабировании добавляется больше серверов и используются решения с балансировкой нагрузки и кластеризацией. Кроме возможности обработки большей нагрузки, горизонтальное масштабирование смягчает последствия сбоев оборудования. Если один из серверов выходит из строя, другие серверы кластера берут на себя его нагрузку. Например, уровень представления и бизнес-уровень приложения могут размещаться на нескольких Веб-серверах с балансировкой нагрузки, образующих Веб-ферму. Или можно физически отделить бизнес-логику приложения и использовать для нее отдельный средний уровень с балансировкой нагрузки, но при этом размещать уровень представления на внешнем уровне с балансировкой нагрузки. Если приложение имеет ограничения по вводу/выводу и должно поддерживать очень большую базу данных, ее можно распределить по нескольким серверам баз данных. Как правило, способность приложения масштабироваться горизонтально больше зависит от его архитектуры, чем от базовой инфраструктуры.
Вопросы вертикального масштабирования
Вертикальное масштабирование через повышение мощности процессора и увеличение объема памяти может быть экономически эффективным решением. Также при таком подходе не возникает необходимости в дополнительных затратах на управление, как с горизонтальным масштабированием в связи с применением Веб-ферм и кластеризации. Прежде всего, следует рассмотреть варианты вертикального масштабирования и провести тестирование производительности, чтобы убедиться в том, что вертикальное масштабирование решения соответствует заданному критерию масштабирования и обеспечивает приемлемый уровень производительности для требуемого числа одновременно работающих пользователей. Необходимо выработать план масштабирования для системы, который будет отражать перспективы ее роста.
Проектирование с поддержкой горизонтального масштабирования
Если вертикальное масштабирование решения не обеспечивает требуемой масштабирумости из-за достижения предельных показателей для процессора, подсистемы ввода/вывода или памяти, необходимо выполнять горизонтальное масштабирование и вводить дополнительные серверы. Для обеспечения эффективного горизонтального масштабирования приложения при проектировании пользуйтесь следующими практиками:
Узкие места идентификации и горизонтального масштабирования. Часто узким местом являются совместно используемые плохо масштабируемые в вертикальном направлении ресурсы. Например, имеется единственный экземпляр SQL Server, с которым работают множество серверов приложений. В этом случае разделение данных таким образом, чтобы они могли обслуживаться несколькими экземплярами SQL Server, обеспечит возможность горизонтального масштабирования решения. Если существует вероятность того, что узким местом станет сервер базы данных, предусмотрите секционирование данных при проектировании, это избавит от многих проблем в будущем.
Слабо связанный и многослойный дизайн. Слабо связанный многослойный дизайн с четкими интерфейсами, которые могут использоваться удаленно, проще масштабировать горизонтально, чем дизайн, использующий тесно связанные слои с детализированными интерфейсами. Многослойный дизайн будет иметь естественные точки разделения, что делает его идеальным для горизонтального масштабирования в границах уровней. Главное, правильно определить границы. Например, бизнес-логику проще перенести в ферму серверов приложений среднего уровня с балансировкой нагрузки.
Компромиссы и последствия их принятия
Следует учесть аспекты масштабируемости, которые могут быть разными для разных слоев, уровней или типов данных. Выявление необходимых компромиссов позволит увидеть, в каких аспектах имеется гибкость, а в каких нет. В некоторых случаях вертикальное масштабирование с последующим горизонтальным масштабированием с применением Веб-серверов или серверов приложений не является наилучшим подходом. Например, можно установить 8- процессорный сервер, но из соображений экономии, скорее всего, вместо одного большого сервера будут использоваться несколько меньших серверов.
С другой стороны, в определенных ситуациях, в зависимости от роли данных и их использования, вертикальное масштабирование с последующим горизонтальным масштабированием может быть оптимальным подходом для серверов баз данных. Однако возможности балансировки нагрузки и обработки отказов не бесконечны, и количество серверов, которые могут быть охвачены этими процессами, ограничено. Также влияние оказывают и другие аспекты, такие как секционирование базы данных. Кроме технических вопросов и вопросов производительности, нельзя забывать об эксплуатации и управлении и об общей стоимости всей системы.
Как правило, выполняется оптимизация цены и производительности в рамках, налагаемых всеми остальными ограничениями. Например, использование четырех 2-процессорных Веб-
серверов/серверов приложений может быть более оптимальным вариантом с точки зрения цены и производительности по сравнению с использованием двух 4-процессорных серверов. Однако должны быть учтены и другие ограничения, такие как какое максимальное число серверов, которые можно разместить в конкретной инфраструктуре балансировки нагрузки, а также энергопотребление или предоставляемая площадь в дата-центре.
Для реализации ферм серверов и для размещения сервисов могут использоваться виртуализированные серверы. Такой подход поможет найти оптимальное соотношение производительности и стоимости, обеспечивая при этом максимальное использование ресурсов и рентабельность инвестиций.
Компоненты без сохранения состояния
Применение компонентов без сохранения состояния (не сохраняющие промежуточного состояния компоненты, которые могут быть реализованы в клиентской части Веб-приложения) означает возможность создания дизайна с лучшими возможностями, как для горизонтального, так и для вертикального масштабирования. Для сознания дизайна без сохранения состояния придется пойти на многие компромиссы, но обеспечиваемые им преимущества с точки зрения масштабируемости, как правило, перевешивают все возможные недостатки.
Секционирование данных и базы данных
Если приложение работает с очень большой базой данных и есть опасения, что операции ввода/вывода станут узким местом системы, заранее предусмотрите секционирование базы данных. Секционирование базы данных на более поздних этапах проектирования обычно требует полной переработки дизайна базы данных и, соответственно, масштабных изменений всего кода приложения. Секционирование обеспечивает несколько преимуществ, включая возможность направления всех запросов к одной секции (таким образом, использование ресурсов ограничивается только одной частью данных) и возможность задействовать множество секций (таким образом, достигаются лучшие возможности одновременной работы и исключительная производительности за счет извлечения данных с множества дисков).
Однако в некоторых ситуациях наличие множества секций может иметь негативные последствия. Например, некоторые операции эффективнее выполнять с данными, сконцентрированными на одном накопителе.
Принимаемые в сценариях развертывания решения о секционировании хранилища данных во многом определяются типом данных. Рассмотрим значимые факторы:
Статические справочные данные только для чтения. Для этого типа данных в целях улучшения производительности и масштабируемости можно без особого труда поддерживать множество копий на разных накопителях, размещаемых в соответствующих местоположениях. Это имеет минимальное влияние на дизайн и обычно определяется соображениями оптимизации. Сведение нескольких логически отдельных и независимых баз данных на один сервер базы данных, даже если это позволяет объем дискового пространства, может быть неудачным решением, и размещение копий ближе к потребителям данных может оказаться в равной степени приемлемым подходом. Однако нельзя забывать, что любое
тиражирование требует применения механизмов обеспечения синхронизации системы.
Динамические (часто изменяющиеся) легко секционируемые данные. Это данные, относящиеся к конкретному пользователю или сеансу, такие как корзина в системе электронной коммерции, где данные пользователя А никак не связаны с данными пользователя В. Управлять такими данными немного сложнее, чем статическими данными только для чтения, но их довольно легко оптимизировать и распределять, поскольку они могут быть секционированы. Нет никаких зависимостей между группами вплоть до отдельных пользователей. Важная особенность эти данных в том, что здесь не выполняется запрос по всем секциям: запрашивается содержимое корзины пользователя А, но не все корзины, включающие определенный товар. Обратите внимание, если последующие запросы могут поступать на другой Веб-сервер или сервер приложений, все эти серверы должны иметь возможность доступа к соответствующей секции.
Основные данные . Это основной случай применения вертикального масштабирования с последующим горизонтальным масштабированием. Как правило, тиражировать данные этого типа нежелательно из-за сложности их синхронизации. Классическое решение для таких данных – вертикальное масштабирование до предельных возможностей (в идеале, сохранение единственного логического экземпляра с соответствующей кластеризацией) и применение секционирования и распределения, только если горизонтальное масштабирование является единственным допустимым вариантом. Прогресс и достижения в технологиях баз данных, такие как распределенные секционированные представления, намного упростили секционирование, тем не менее, оно должно применяться лишь в случае крайней необходимости. Слишком большой размер базы данных редко является определяющим фактором при принятии решения, намного чаще основную роль играют другие соображения, такие как кому принадлежат данные, географическое распределение пользователей, близость к потребителю и доступность.
Данные с отложенной синхронизацией. Некоторые используемые в приложениях данные не требуют немедленной синхронизации или синхронизации вообще. Отличный пример – такие данные онлайн-магазинов, как «С товаром Х часто покупают Y и Z». Эти данные извлекаются из основных данных, но не требуют обновления в режиме реального времени. Проектирование стратегий, обеспечивающих перевод данных из основных в секционируемые (динамические) и затем в статические, является ключевым фактором в построении высокомасштабируемых приложений.
Более подробно схемы перемещения и тиражирования данных рассматриваются в статье «Data Movement Patterns » (Шаблоны передачи данных) по адресу http://msdn.microsoft.com/en-us/library/ms998449.aspx .
Систем, программных комплексов , систем баз данных , маршрутизаторов , сетей и т. п., если для них требуется возможность работать под большой нагрузкой. Система называется масштабируемой , если она способна увеличивать производительность пропорционально дополнительным ресурсам. Масштабируемость можно оценить через отношение прироста производительности системы к приросту используемых ресурсов. Чем ближе это отношение к единице, тем лучше. Также под масштабируемостью понимается возможность наращивания дополнительных ресурсов без структурных изменений центрального узла системы.
В системе с плохой масштабируемостью добавление ресурсов приводит лишь к незначительному повышению производительности, а с некоторого «порогового» момента добавление ресурсов не даёт никакого полезного эффекта.
Вертикальное масштабирование
Увеличение производительности каждого компонента системы c целью повышения общей производительности.
Горизонтальное масштабирование
Разбиение системы на более мелкие структурные компоненты и разнесение их по отдельным физическим машинам (или их группам) и/или увеличение количества серверов параллельно выполняющих одну и ту же функцию.
Примечания
См. также
Ссылки
Wikimedia Foundation . 2010 .
Смотреть что такое "Масштабируемость" в других словарях:
масштабируемость - расширяемость Характеристика приложения, которое исполняется на разных платформах и варьируется в размерах (например, на PC под Windows и на рабочей станции Sun под Unix). Для аппаратных средств предсказуемый рост системных характеристик при… …
масштабируемость - 3.1.43 масштабируемость (scalability): Способность обеспечивать функциональные возможности вверх и вниз по упорядоченному ряду прикладных платформ, отличающихся по быстродействию и ресурсам. Источник … Словарь-справочник терминов нормативно-технической документации
Способность программного обеспечения корректно работать на малых и на больших системах с производительностью, которая увеличивается пропорционально вычислительной мощности системы. По английски: Scalability См. также: Открытые системы Программное … Финансовый словарь
масштабируемость системы (в SCADA) - масштабируемость системы [Интент] Масштабируемость системы. Это означает, что разработанный проект можно опробовать на одном компьютере или маленькой сети и затем расширять систему (в соответствии с программой развития, бюджетом и т. д.) без… … Справочник технического переводчика
масштабируемость (в информационных технологиях) - Способность ИТ услуги, процесса, конфигурационной единицы и т.п., выполнять свою ранее согласованную функцию, в случае изменения рабочей нагрузки или охвата. [Словарь терминов ITIL версия 1.0, 29 июля 2011 г.] EN scalability The ability of an IT… … Справочник технического переводчика
масштабируемость (приложения) - масштабируемость расширяемость Характеристика приложения, которое исполняется на разных платформах и варьируется в размерах (например, на PC под Windows и на рабочей станции Sun под Unix). Для аппаратных средств предсказуемый рост системных… … Справочник технического переводчика
масштабируемость (сети и системы связи) - Критерий экономически эффективной системы автоматизации подстанции, учитывающий различные функциональные характеристики, различные интеллектуальные электронные устройства, размер подстанции и диапазоны напряжений подстанции. [ГОСТ Р 54325 2011… … Справочник технического переводчика
масштабируемость в широких пределах - — [Л.Г.Суменко. Англо русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.] Тематики информационные технологии в целом EN terabyte scalability … Справочник технического переводчика
горизонтальная масштабируемость - Наращивание мощности системы добавлением узлов в кластер. Тематики информационные технологии в целом EN horizontal scalability … Справочник технического переводчика
SCALABILITY - масштабируемость - один из основных принципов построения открытых систем, гарантирует сохранение инвестиций в информацию и ПО при переходе на более мощную аппаратную платформу … Словарь электронного бизнеса
Книги
- Microsoft SharePoint 2010. Полное руководство , Майкл Ноэл, Колин Спенс. В книге рассматриваются все новые возможности SharePoint - от новых компонентов социальных сетей до усовершенствованного поиска - которые помогают максимально задействовать как SharePoint…
) Здравствуйте! Я Александр Макаров, и вы можете меня знать по фреймворку «Yii» — я один из его разработчиков. У меня также есть full-time работа — и это уже не стартап — Stay.com, который занимается путешествиями.
Сегодня я буду рассказывать про горизонтальное масштабирование, но в очень-очень общих словах.
Что такое масштабирование, вообще? Это возможность увеличить производительность проекта за минимальное время путем добавления ресурсов.
Обычно масштабирование подразумевает не переписывание кода, а либо добавление серверов, либо наращивание ресурсов существующего. По этому типу выделяют вертикальное и горизонтальное масштабирование.
Вертикальное — это когда добавляют больше оперативки, дисков и т.д. на уже существующий сервер, а горизонтальное — это когда ставят больше серверов в дата-центры, и сервера там уже как-то взаимодействуют.
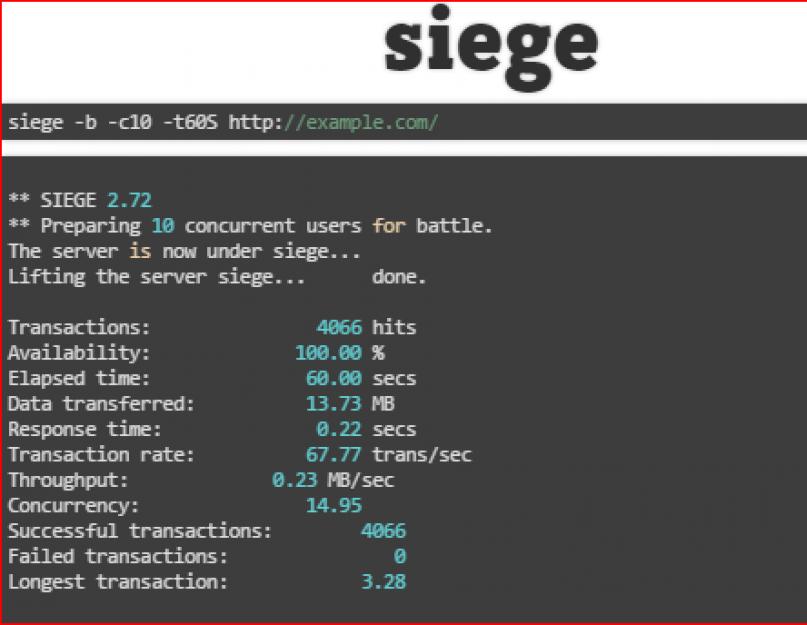
Самый классный вопрос, который задают, — а зачем оно надо, если у меня все и на одном сервере прекрасно работает? На самом-то деле, надо проверить, что будет. Т.е., сейчас оно работает, но что будет потом? Есть две замечательные утилиты — ab и siege, которые как бы нагоняют тучу пользователей конкурента, которые начинают долбить сервер, пытаются запросить странички, послать какие-то запросы. Вы должны указать, что им делать, а утилиты формируют такие вот отчеты:

Главные два параметра: n — количество запросов, которые надо сделать, с — количество одновременных запросов. Таким образом они проверяют конкурентность.
На выходе получаем RPS, т.е. количество запросов в секунду, которое способен обработать сервер, из чего станет понятно, сколько пользователей он может выдержать. Все, конечно, зависит от проекта, бывает по-разному, но обычно это требует внимания.
Есть еще один параметр — Response time — время ответа, за которое в среднем сервер отдал страничку. Оно бывает разное, но известно, что около 300 мс — это норма, а что выше — уже не очень хорошо, потому что эти 300 мс отрабатывает сервер, к этому прибавляются еще 300-600 мс, которые отрабатывает клиент, т.е. пока все загрузится — стили, картинки и остальное — тоже проходит время.
Бывает, что на самом деле пока и не надо заботиться о масштабировании — идем на сервер, обновляем PHP, получаем 40% прироста производительности и все круто. Далее настраиваем Opcache, тюним его. Opcache, кстати, тюнится так же, как и APC, скриптом, который можно найти в репозитории у Расмуса Лердорфа и который показывает хиты и мисы, где хиты — это сколько раз PHP пошел в кэш, а мисы — сколько раз он пошел в файловую систему доставать файлики. Если прогнать весь сайт, либо запустить туда какой-то краулер по ссылкам, либо вручную потыкать, то у нас будет статистика по этим хитам и мисам. Если хитов 100%, а мисов — 0%, значит, все нормально, а если есть мисы, то надо выделить больше памяти, чтобы весь наш код влез в Opcache. Это частая ошибка, которую допускают — вроде Opcache есть, но что-то не работает…
Еще часто начинают масштабировать, но не смотрят, вообще, из-за чего все работает медленно. Чаще всего лезем в базу, смотрим — индексов нет, ставим индексы — все сразу залетало, еще на 2 года хватит, красота!
Ну, еще надо включить кэш, заменить apache на nginx и php-fpm, чтобы сэкономить память. Будет все классно.
Все перечисленное достаточно просто и дает вам время. Время на то, что когда-то этого станет мало, и к этому уже сейчас надо готовиться.
Как, вообще, понять, в чем проблема? Либо у вас уже настал highload, а это не обязательно какое-то бешеное число запросов и т.д., это, когда у вас проект не справляется с нагрузкой, и тривиальными способами это уже не решается. Надо расти либо вширь, либо вверх. Надо что-то делать и, скорее всего, на это мало времени, что-то надо придумывать.
Первое правило — никогда ничего нельзя делать вслепую, т.е. нам нужен отличный мониторинг. Сначала мы выигрываем время на какой-то очевидной оптимизации типа включения кэша или кэширования Главной и т.п. Потом настраиваем мониторинг, он нам показывает, чего не хватает. И все это повторяется многократно – останавливать мониторинг и доработку никогда нельзя.
Что может показать мониторинг? Мы можем упереться в диск, т.е. в файловую систему, в память, в процессор, в сеть… И может быть такое, что, вроде бы, все более-менее, но какие-то ошибки валятся. Все это разрешается по-разному. Можно проблему, допустим, с диском решить добавлением нового диска в тот же сервер, а можно поставить второй сервер, который будет заниматься только файлами.
На что нужно обращать внимание прямо сейчас при мониторинге? Это:
- доступность, т.е. жив сервер, вообще, или нет;
- нехватка ресурсов диска, процессора и т.д.;
- ошибки.
Вот список замечательных инструментов, которые позволяют мониторить ресурсы и показывать результаты в очень удобном виде:
Этот доклад - расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем за 2015 год.Старьё! - скажите вы.
- Вечные ценности! - ответим мы.highload junior Добавить метки
Итак вы сделали сайт. Всегда интересно и волнительно наблюдать как счетчик посещений медленно, но верно ползет вверх, с каждым днем показывая все лучшие результаты. Но однажды, когда вы этого не ждете, кто-то запостит ссылку на ваш ресурс на каком-нибудь Reddit или Hacker News (или на Хабре - прим. пер.), и ваш сервер ляжет.
Вместо того, что бы получить новых постоянных пользователей, вы останетесь с пустой страницей. В этот момент, ничего не поможет вам восстановить работоспособность сервера, и трафик будет утерян навсегда. Как же избежать таких проблем? В этой статье мы поговорим об оптимизации и масштабировании
.
Немного про оптимизацию
Основные советы всем известны: обновитесь до последней версии PHP (в 5.5 теперь встроен OpCache), разберитесь с индексами в базе данных, кэшируйте статику (редко изменяемые страницы, такие как “О нас”, “FAQ” и т.д.).
Также стоит упомянуть об одном особом аспекте оптимизации - обслуживании статического контента не-Apache сервером, таким как, например, Nginx, Настройте Nginx на обработку всего статического контента (*.jpg, *.png, *.mp4, *.html…), а файлы требующие серверной обработки пусть отсылает тяжелому Apache. Это называется reverse proxy .
Масштабирование
Есть два типа масштабирования - вертикальное и горизонтальное.
В моем понимании, сайт является масштабируемым, если он может справляться с трафиком, без изменений в программном обеспечении.
Вертикальное масштабирование.
Представьте себе сервер, обслуживающий веб-приложение. У него 4ГБ RAM, i5 процессор и 1ТБ HDD. Он отлично выполняет свои функции, но, что бы лучше справляться с более высоким трафиком, вы решаете увеличить RAM до 16ГБ, поставить процессор i7, и раскошелиться на SSD диск. Теперь сервер гораздо мощнее, и справляется с высокими нагрузками. Это и есть вертикальное масштабирование.
Горизонтальное масштабирование.
Горизонтальное масштабирование - создание кластера из связанных между собой (часто не очень мощных) серверов, которые вместе обслуживают сайт. В этом случае, используется балансировщик нагрузки (aka load balancer ) - машина или программа, основная функция которой - определить на какой сервер послать запрос. Сервера в кластере делят между собой обслуживание приложения, ничего друг о друге не зная, таким образом значительно увеличивая пропускную способность и отказоустойчивость вашего сайта.
Есть два типа балансировщиков - аппаратные и программные. Программный - устанавливается на обычный сервер и принимает весь трафик, передавая его соответствующим обработчикам. Таким балансировщиком может быть, например, Nginx. В разделе “Оптимизация” он перехватывал все запросы на статические файлы, и обслуживал эти запросы сам, не обременяя Apache. Другое популярное ПО для реализации балансировки нагрузки - Squid . Лично я всегда использую именно его, т.к. он предоставляет отличный дружественный интерфейс, для контроля за самыми глубокими аспектами балансировки.
Аппаратный балансировщик - выделенная машина, единственная цель которой - распределять нагрузку. Обычно на этой машине, никакого ПО, кроме разработанного производителем, больше не стоит. Почитать про аппаратные балансировщики нагрузки можно .
Обратите внимание, что эти два метода не являются взаимоисключающими. Вы можете вертикально масштабировать любую машину (aka Ноду
) в вашей системе.
В этой статье мы обсуждаем горизонтальное масштабирование, т.к. оно дешевле и эффективнее, хотя и сложнее в реализации.
Постоянное соединение
При масштабировании PHP приложений, возникает несколько непростых проблем. Одна из них - работа с данными сессии пользователя. Ведь если вы залогинились на сайте, а следующий ваш запрос балансировщик отправил на другую машину, то новая машина не будет знать, что вы уже залогинены. В этом случае, вы можете использовать постоянное соединение. Это значит, что балансировщик запоминает на какую ноду отправил запрос пользователя в прошлый раз, и отправляет следующий запрос туда же. Однако, получается, что балансировщик слишком перегружен функциями, кроме обработки сотни тысяч запросов, ему еще и приходится помнить как именно он их обработал, в результате чего, сам балансировщик становится узким местом в системе.
Обмен локальными данными.
Разделить данные сессии пользователей между всеми нодами кластера - кажется неплохой идеей. И несмотря на то, что этот подход требует некоторых изменений в архитектуре вашего приложения, оно того стоит - разгружается балансировщик, и весь кластер становится более отказоустойчивым. Смерть одного из серверов совершенно не отражается на работе всей системы.
Как мы знаем, данные сессии хранятся в суперглобальном массиве $_SESSION
, который пишет и берет данные с файла на диске. Если этот диск находится на одном сервере, очевидно, что другие сервера не имеют к нему доступа. Как же нам сделать его доступным на нескольких машинах?
Во первых, обратите внимание, что обработчик сессий в PHP можно переопределить
. Вы можете реализовать свой собственный класс для работы с сессиями .
Использование БД для хранения сессий
Используя собственный обработчик сессий, мы можем хранить их в БД. База данных может быть на отдельном сервере (или даже кластере). Обычно этот метод отлично работает, но при действительно большом трафике, БД становится узким местом (а при потере БД мы полностью теряем работоспособность), ибо ей приходится обслуживать все сервера, каждый из которых пытается записать или прочитать данные сессии.
Распределенная файловая система
Возможно вы думаете о том, что неплохо бы было настроить сетевую файловую систему, куда все сервера смогли бы писать данные сессии. Не делайте этого! Это очень медленный подход, приводящий к порче, а то и потере данных. Если же, по какой-то причине, вы все-таки решили использовать этот метод, рекомендую вам GlusterFS
Memcached
Вы также можете использовать memcached для хранения данных сессий в RAM. Однако это не безопасно, ибо данные в memcached перезаписываются, если заканчивается свободное место. Вы, наверное, задаетесь вопросом, разве RAM не разделен по машинам? Как он применяется на весь кластер? Memcached имеет возможность объединять доступную на разных машинах RAM в один пул .

Чем больше у вас машин, тем больше вы можете отвести в этот пул памяти. Вам не обязательно объединять всю память машин в пул, но вы можете, и вы можете пожертвовать в пул произвольное количество памяти с каждой машины. Так что, есть возможность оставить бо льшую часть памяти для обычного использования, и выделить кусок для кэша, что позволит кэшировать не только сессии, но другую подходящую информацию. Memcached - отличное и широко распространенное решение .
Для использования этого подхода, нужно немного подредактировать php.ini
Session.save_handler = memcache session.save_path = "tcp://path.to.memcached.server:port"
Redis кластер
Redis - NoSQL хранилище данных. Хранит базу в оперативной памяти. В отличие от memcached поддерживает постоянное хранение данных, и более сложные типы данных. Redis не поддерживает кластеризацию , так что использовать его для горизонтального масштабирования несколько затруднительно, однако, это временно, и уже вышла альфа версия кластерного решения .
Другие решения
Итого
Как видите, горизонтальное масштабирование PHP приложений не такое уж простое дело. Существует много трудностей, большинство решений не взаимозаменяемые, так что приходится выбирать одно, и придерживаться его до конца, ведь когда трафик зашкаливает - уже нет возможности плавно перейти на что-то другое.
Надеюсь этот небольшой гайд поможет вам выбрать подход к масштабированию для вашего проекта.
Во второй части статьи мы поговорим о масштабировании базы данных .