Рассказывать про DML я буду по своей последовательности выработанной на личном опыте. По ходу, так же постараюсь рассказать про «скользкие» места, на которые стоит акцентировать внимание, эти «скользкие» места, схожи во многих диалектах языка SQL.
Т.к. учебник посвящается широкому кругу читателей (не только программистам), то и объяснение, порой будет соответствующее, т.е. долгое и нудное. Это мое видение материала, которое в основном получено на практике в результате профессиональной деятельности.
Основная цель данного учебника, шаг за шагом, выработать полное понимание сути языка SQL и научить правильно применять его конструкции. Профессионалам в этой области, может тоже будет интересно пролистать данный материал, может и они смогут вынести для себя что-то новое, а может просто, будет полезно почитать в целях освежить память. Надеюсь, что всем будет интересно.
Т.к. DML в диалекте БД MS SQL очень сильно связан с синтаксисом конструкции SELECT, то я начну рассказывать о DML именно с нее. На мой взгляд конструкция SELECT является самой главной конструкцией языка DML, т.к. за счет нее или ее частей осуществляется выборка необходимых данных из БД.
Язык DML содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
В данной части, мы рассмотрим, только базовый синтаксис команды SELECT, который выглядит следующим образом:
SELECT список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
Тема оператора SELECT очень обширная, поэтому в данной части я и остановлюсь только на его базовых конструкциях. Я считаю, что, не зная хорошо базы, нельзя приступать к изучению более сложных конструкций, т.к. дальше все будет крутиться вокруг этой базовой конструкции (подзапросы, объединения и т.д.).
Также в рамках этой части, я еще расскажу о предложении TOP. Это предложение я намерено не указал в базовом синтаксисе, т.к. оно реализуется по-разному в разных диалектах языка SQL.
Если язык DDL больше статичен, т.е. при помощи него создаются жесткие структуры (таблицы, связи и т.п.), то язык DML носит динамический характер, здесь правильные результаты вы можете получить разными путями.
Обучение так же будет продолжаться в режиме Step by Step, т.е. при чтении нужно сразу же своими руками пытаться выполнить пример. После делаете анализ полученного результата и пытаетесь понять его интуитивно. Если что-то остается непонятным, например, значение какой-нибудь функции, то обращайтесь за помощью в интернет.
Примеры будут показываться на БД Test, которая была создана при помощи DDL+DML в первой части.
Для тех, кто не создавал БД в первой части (т.к. не всех может интересовать язык DDL), может воспользоваться следующим скриптом:
Скрипт создания БД Test
Создание БД
CREATE DATABASE Test
GO
-- сделать БД Test текущей
USE Test
GO
-- создаем таблицы справочники
CREATE TABLE Positions(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL)
CREATE TABLE Departments(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL)
GO
-- заполняем таблицы справочники данными
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(1,N"Бухгалтер"),
(2,N"Директор"),
(3,N"Программист"),
(4,N"Старший программист")
SET IDENTITY_INSERT Positions OFF
GO
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name)VALUES
(1,N"Администрация"),
(2,N"Бухгалтерия"),
(3,N"ИТ")
SET IDENTITY_INSERT Departments OFF
GO
-- создаем таблицу с сотрудниками
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name))
GO
-- заполняем ее данными
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219","[email protected]",2,1,NULL),
(1001,N"Петров П.П.","19831203","[email protected]",3,3,1003),
(1002,N"Сидоров С.С.","19760607","[email protected]",1,2,1000),
(1003,N"Андреев А.А.","19820417","[email protected]",4,3,1000)
Все, теперь мы готовы приступить к изучению языка DML.
SELECT – оператор выборки данных
Первым делом, для активного редактора запроса, сделаем текущей БД Test, выбрав ее в выпадающем списке или же командой «USE Test».Начнем с самой элементарной формы SELECT:
SELECT *
FROM Employees
В данном запросе мы просим вернуть все столбцы (на это указывает «*») из таблицы Employees – можно прочесть это как «ВЫБЕРИ все_поля ИЗ таблицы_сотрудники». В случае наличия кластерного индекса, возвращенные данные, скорее всего будут отсортированы по нему, в данном случае по колонке ID (но это не суть важно, т.к. в большинстве случаев сортировку мы будем указывать в явном виде сами при помощи ORDER BY …):
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 | NULL |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 | 1000 |
Вообще стоит сказать, что в диалекте MS SQL самая простая форма запроса SELECT может не содержать блока FROM, в этом случае вы можете использовать ее, для получения каких-то значений:
SELECT
5550/100*15,
SYSDATETIME(), -- получение системной даты БД
SIN(0)+COS(0)
| (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
Обратите внимание, что выражение (5550/100*15) дало результат 825, хотя если мы посчитаем на калькуляторе получится значение (832.5). Результат 825 получился по той причине, что в нашем выражении все числа целые, поэтому и результат целое число, т.е. (5550/100) дает нам 55, а не (55.5).
Запомните следующее, что в MS SQL работает следующая логика:
- Целое / Целое = Целое (т.е. в данном случае происходит целочисленное деление)
- Вещественное / Целое = Вещественное
- Целое / Вещественное = Вещественное
SELECT
123/10, -- 12
123./10, -- 12.3
123/10. -- 12.3
Здесь (123.) = (123.0), просто в данном случае 0 можно отбросить и оставить только точку.
При других арифметических операциях действует та же самая логика, просто в случае деления этот нюанс более актуален.
Поэтому обращайте внимание на тип данных числовых столбцов. В том случае если он целый, а результат вам нужно получить вещественный, то используйте преобразование, либо просто ставьте точку после числа указанного в виде константы (123.).
Для преобразования полей можно использовать функцию CAST или CONVERT. Для примера воспользуемся полем ID, оно у нас типа int:
SELECT
ID,
ID/100, -- здесь произойдет целочисленное деление
CAST(ID AS float)/100, -- используем функцию CAST для преобразования в тип float
CONVERT(float,ID)/100, -- используем функцию CONVERT для преобразования в тип float
ID/100. -- используем преобразование за счет указания что знаменатель вещественное число
FROM Employees
| ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
На заметку. В БД ORACLE синтаксис без блока FROM недопустим, там для этой цели используется системная таблица DUAL, которая содержит одну строку:SELECT 5550/100*15, -- а в ORACLE результат будет равен 832.5 sysdate, sin(0)+cos(0) FROM DUAL
Примечание. Имя таблицы во многих РБД может предваряться именем схемы:SELECT * FROM dbo.Employees -- dbo – имя схемы
Схема – это логическая единица БД, которая имеет свое наименование и позволяет сгруппировать внутри себя объекты БД такие как таблицы, представления и т.д.
Определение схемы в разных БД может отличатся, где-то схема непосредственно связанна с пользователем БД, т.е. в данном случае можно сказать, что схема и пользователь – это синонимы и все создаваемые в схеме объекты по сути являются объектами данного пользователя. В MS SQL схема – это независимая логическая единица, которая может быть создана сама по себе (см. CREATE SCHEMA).
По умолчанию в базе MS SQL создается одна схема с именем dbo (Database Owner) и все создаваемые объекты по умолчанию создаются именно в данной схеме. Соответственно, если мы в запросе указываем просто имя таблицы, то она будет искаться в схеме dbo текущей БД. Если мы хотим создать объект в конкретной схеме, мы должны будем так же предварить имя объекта именем схемы, например, «CREATE TABLE имя_схемы.имя_таблицы(…)».
В случае MS SQL имя схемы может еще предваряться именем БД, в которой находится данная схема:
SELECT * FROM Test.dbo.Employees -- имя_базы.имя_схемы.таблица
Такое уточнение бывает полезным, например, если:Схема – очень удобное средство, которое полезно использовать при разработке архитектуры БД, а особенно крупных БД.
- в одном запросе мы обращаемся к объектам расположенных в разных схемах или базах данных
- требуется сделать перенос данных из одной схемы или БД в другую
- находясь в одной БД, требуется запросить данные из другой БД
- и т.п.
Так же не забываем, что в тексте запроса мы можем использовать как однострочные «-- …», так и многострочные «/* … */» комментарии. Если запрос большой и сложный, то комментарии могут очень помочь, вам или кому-то другому, через некоторое время, вспомнить или разобраться в его структуре.
Если столбцов в таблице очень много, а особенно, если в таблице еще очень много строк, плюс к тому если мы делаем запросы к БД по сети, то предпочтительней будет выборка с непосредственным перечислением необходимых вам полей через запятую:
SELECT ID,Name FROM Employees
Т.е. здесь мы говорим, что нам из таблицы нужно вернуть только поля ID и Name. Результат будет следующим (кстати оптимизатор здесь решил воспользоваться индексом, созданным по полю Name):
| ID | Name |
|---|---|
| 1003 | Андреев А.А. |
| 1000 | Иванов И.И. |
| 1001 | Петров П.П. |
| 1002 | Сидоров С.С. |
На заметку. Порой бывает полезным посмотреть на то как осуществляется выборка данных, например, чтобы выяснить какие индексы используются. Это можно сделать если нажать кнопку «Display Estimated Execution Plan – Показать расчетный план» или установить «Include Actual Execution Plan – Включить в результат актуальный план выполнения запроса» (в данном случае мы сможем увидеть уже реальный план, соответственно, только после выполнения запроса):Анализ плана выполнения очень полезен при оптимизации запроса, он позволяет выяснить каких индексов не хватает или же какие индексы вообще не используются и их можно удалить.
Если вы только начали осваивать DML, то сейчас для вас это не так важно, просто возьмите на заметку и можете спокойно забыть об этом (может это вам никогда и не пригодится) – наша первоначальная цель изучить основы языка DML и научится правильно применять их, а оптимизация это уже отдельное искусство. Порой важнее, чтобы на руках просто был правильно написанный запрос, который возвращает правильные результат с предметной точки зрения, а его оптимизацией уже занимаются отдельные люди. Для начала вам нужно научиться просто правильно писать запросы, используя любые средства для достижения цели. Главная цель которую вы сейчас должны достичь – чтобы ваш запрос возвращал правильные результаты.
Задание псевдонимов для таблиц
При перечислении колонок их можно предварять именем таблицы, находящейся в блоке FROM:SELECT Employees.ID,Employees.Name FROM Employees
Но такой синтаксис обычно использовать неудобно, т.к. имя таблицы может быть длинным. Для этих целей обычно задаются и применяются более короткие имена – псевдонимы (alias):
SELECT emp.ID,emp.Name
FROM Employees AS emp
или
SELECT emp.ID,emp.Name FROM Employees emp -- ключевое слово AS можно отпустить (я предпочитаю такой вариант)
Здесь emp – псевдоним для таблицы Employees, который можно будет использоваться в контексте данного оператора SELECT. Т.е. можно сказать, что в контексте этого оператора SELECT мы задаем таблице новое имя.
Конечно, в данном случае результаты запросов будут точно такими же как и для «SELECT ID,Name FROM Employees». Для чего это нужно будет понятно дальше (даже не в этой части), пока просто запоминаем, что имя колонки можно предварять (уточнять) либо непосредственно именем таблицы, либо при помощи псевдонима. Здесь можно использовать одно из двух, т.е. если вы задали псевдоним, то и пользоваться нужно будет им, а использовать имя таблицы уже нельзя.
На заметку. В ORACLE допустим только вариант задания псевдонима таблицы без ключевого слова AS.
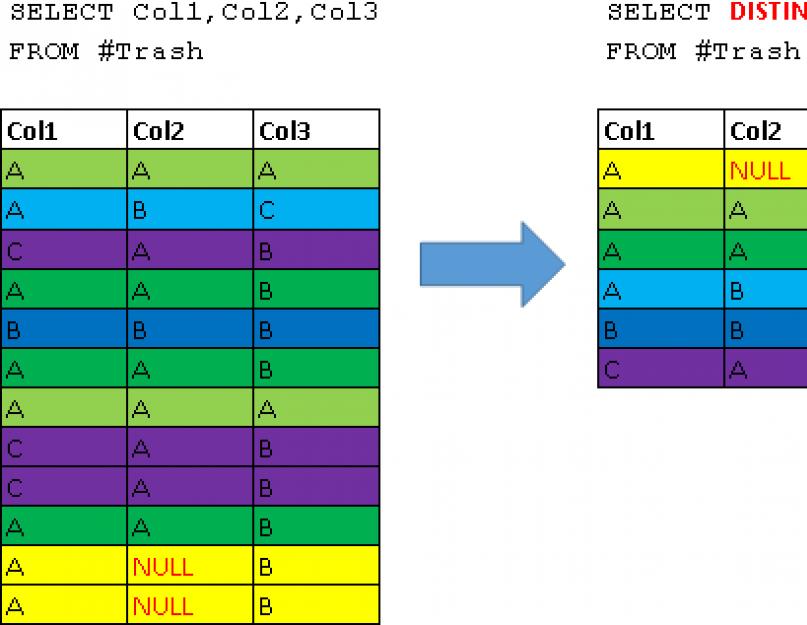
DISTINCT – отброс строк дубликатов
Ключевое слово DISTINCT используется для того чтобы отбросить из результата запроса строки дубликаты. Грубо говоря представьте, что сначала выполняется запрос без опции DISTINCT, а затем из результата выбрасываются все дубликаты. Продемонстрируем это для большей наглядности на примере:Создадим для демонстрации временную таблицу CREATE TABLE #Trash(ID int NOT NULL PRIMARY KEY, Col1 varchar(10), Col2 varchar(10), Col3 varchar(10)) -- наполним данную таблицу всяким мусором INSERT #Trash(ID,Col1,Col2,Col3)VALUES (1,"A","A","A"), (2,"A","B","C"), (3,"C","A","B"), (4,"A","A","B"), (5,"B","B","B"), (6,"A","A","B"), (7,"A","A","A"), (8,"C","A","B"), (9,"C","A","B"), (10,"A","A","B"), (11,"A",NULL,"B"), (12,"A",NULL,"B") -- посмотрим что возвращает запрос без опции DISTINCT SELECT Col1,Col2,Col3 FROM #Trash -- посмотрим что возвращает запрос с опцией DISTINCT SELECT DISTINCT Col1,Col2,Col3 FROM #Trash -- удалим временную таблицу DROP TABLE #Trash
Наглядно это будет выглядеть следующим образом (все дубликаты помечены одним цветом):

Теперь давайте рассмотрим где это можно применить, на более практичном примере – вернем из таблицы Employees только уникальные идентификаторы отделов (т.е. узнаем ID отделов в которых числятся сотрудники):
SELECT DISTINCT DepartmentID
FROM Employees
Здесь мы получили 4 строчки, т.к. повторяющихся комбинаций (DepartmentID, PositionID) в нашей таблице нет.
Ненадолго вернемся к DDL
Так как данных для демонстрационных примеров начинает не хватать, а рассказать хочется более обширно и понятно, то давайте чуть расширим нашу таблицу Employess. К тому же немного вспомним DDL, как говорится «повторение – мать учения», и плюс снова немного забежим вперед и применим оператор UPDATE:Создаем новые колонки ALTER TABLE Employees ADD LastName nvarchar(30), -- фамилия FirstName nvarchar(30), -- имя MiddleName nvarchar(30), -- отчество Salary float, -- и конечно же ЗП в каких-то УЕ BonusPercent float -- процент для вычисления бонуса от оклада GO -- наполняем их данными (некоторые данные намерено пропущены) UPDATE Employees SET LastName=N"Иванов",FirstName=N"Иван",MiddleName=N"Иванович", Salary=5000,BonusPercent= 50 WHERE ID=1000 -- Иванов И.И. UPDATE Employees SET LastName=N"Петров",FirstName=N"Петр",MiddleName=N"Петрович", Salary=1500,BonusPercent= 15 WHERE ID=1001 -- Петров П.П. UPDATE Employees SET LastName=N"Сидоров",FirstName=N"Сидор",MiddleName=NULL, Salary=2500,BonusPercent=NULL WHERE ID=1002 -- Сидоров С.С. UPDATE Employees SET LastName=N"Андреев",FirstName=N"Андрей",MiddleName=NULL, Salary=2000,BonusPercent= 30 WHERE ID=1003 -- Андреев А.А.
Убедимся, что данные обновились успешно:
SELECT *
FROM Employees
| ID | Name | … | LastName | FirstName | MiddleName | Salary | BonusPercent |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | Иванов | Иван | Иванович | 5000 | 50 | |
| 1001 | Петров П.П. | Петров | Петр | Петрович | 1500 | 15 | |
| 1002 | Сидоров С.С. | Сидоров | Сидор | NULL | 2500 | NULL | |
| 1003 | Андреев А.А. | Андреев | Андрей | NULL | 2000 | 30 |
Задание псевдонимов для столбцов запроса
Думаю, здесь будет проще показать, чем написать:SELECT
-- даем имя вычисляемому столбцу
LastName+" "+FirstName+" "+MiddleName AS ФИО,
-- использование двойных кавычек, т.к. используется пробел
HireDate AS "Дата приема",
-- использование квадратных скобок, т.к. используется пробел
Birthday AS [Дата рождения],
-- слово AS не обязательно
Salary ZP
FROM Employees
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
Как видим заданные нами псевдонимы столбцов, отразились в заголовке результирующей таблицы. Собственно, это и есть основное предназначение псевдонимов столбцов.
Обратите внимание, т.к. у последних 2-х сотрудников не указано отчество (NULL значение), то результат выражения «LastName+" "+FirstName+" "+MiddleName» так же вернул нам NULL.
Для соединения (сложения, конкатенации) строк в MS SQL используется символ «+».
Запомним, что все выражения в которых участвует NULL (например, деление на NULL, сложение с NULL) будут возвращать NULL.
На заметку.
В случае ORACLE для объединения строк используется оператор «||» и конкатенация будет выглядеть как «LastName||" "||FirstName||" "||MiddleName». Для ORACLE стоит отметить, что у него для строковых типов есть исключение, для них NULL и пустая строка "" это одно и тоже, поэтому в ORACLE такое выражение вернет для последних 2-х сотрудников «Сидоров Сидор » и «Андреев Андрей ». На момент версии ORACLE 12c, насколько я знаю, опции которая изменяет такое поведение нет (если не прав, прошу поправить меня). Здесь мне сложно судить хорошо это или плохо, т.к. в одних случаях удобнее поведение NULL-строки как в MS SQL, а в других как в ORACLE.В ORACLE тоже допустимы все перечисленные выше псевдонимы столбцов, кроме […].
Для того чтобы не городить конструкцию с использованием функции ISNULL, в MS SQL мы можем применить функцию CONCAT. Рассмотрим и сравним 3 варианта:
SELECT
LastName+" "+FirstName+" "+MiddleName FullName1,
-- 2 варианта для замены NULL пустыми строками "" (получаем поведение как и в ORACLE)
ISNULL(LastName,"")+" "+ISNULL(FirstName,"")+" "+ISNULL(MiddleName,"") FullName2,
CONCAT(LastName," ",FirstName," ",MiddleName) FullName3
FROM Employees
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
В MS SQL псевдонимы еще можно задавать при помощи знака равенства:
SELECT "Дата приема"=HireDate, -- помимо "…" и […] можно использовать "…" [Дата рождения]=Birthday, ZP=Salary FROM Employees
Использовать для задания псевдонима ключевое слово AS или же знак равенства, наверное, больше дело вкуса. Но при разборе чужих запросов, данные знания могут пригодиться.
Напоследок скажу, что для псевдонимов имена лучше задавать, используя только символы латиницы и цифры, избегая применения "…", "…" и […], то есть использовать те же правила, что мы использовали при наименовании таблиц. Дальше, в примерах я буду использовать только такие наименования и никаких "…", "…" и […].
Основные арифметические операторы SQL
Приоритет выполнения арифметических операторов такой же, как и в математике. Если необходимо, то порядок применения операторов можно изменить используя круглые скобки - (a+b)*(x/(y-z)).
И еще раз повторюсь, что любая операция с NULL дает NULL, например: 10+NULL, NULL*15/3, 100/NULL – все это даст в результате NULL. Т.е. говоря просто неопределенное значение не может дать определенный результат. Учитывайте это при составлении запроса и при необходимости делайте обработку NULL значений функциями ISNULL, COALESCE:
SELECT
ID,Name,
Salary/100*BonusPercent AS Result1, -- без обработки NULL значений
Salary/100*ISNULL(BonusPercent,0) AS Result2, -- используем функцию ISNULL
Salary/100*COALESCE(BonusPercent,0) AS Result3 -- используем функцию COALESCE
FROM Employees
Немного расскажу о функции COALESCE:
COALESCE (expr1, expr2, ..., exprn) - Возвращает первое не NULL значение из списка значений.
SELECT COALESCE(f1, f1*f2, f2*f3) val -- в данном случае вернется третье значение FROM (SELECT null f1, 2 f2, 3 f3) q
В основном, я сосредоточусь на рассказе конструкций языка DML и по большей части не буду рассказывать о функциях, которые будут встречаться в примерах. Если вам непонятно, что делает та или иная функция поищите ее описание в интернет, можете даже поискать информацию сразу по группе функций, например, задав в поиске Google «MS SQL строковые функции», «MS SQL математические функции» или же «MS SQL функции обработки NULL». Информации по функциям очень много, и вы ее сможете без труда найти. Для примера, в библиотеке MSDN, можно узнать больше о функции COALESCE:
Вырезка из MSDN Сравнение COALESCE и CASEВыражение COALESCE - синтаксический ярлык для выражения CASE. Это означает, что код COALESCE(expression1,...n) переписывается оптимизатором запросов как следующее выражение CASE:
CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
Для примера рассмотрим, как можно воспользоваться остатком от деления (%). Данный оператор очень полезен, когда требуется разбить записи на группы. Например, вытащим всех сотрудников, у которых четные табельные номера (ID), т.е. те ID, которые делятся на 2:
SELECT ID,Name
FROM Employees
WHERE ID%2=0 -- остаток от деления на 2 равен 0
ORDER BY – сортировка результата запроса
Предложение ORDER BY используется для сортировки результата запроса.SELECT
LastName,
FirstName,
Salary
FROM Employees
ORDER BY LastName,FirstName -- упорядочить результат по 2-м столбцам – по Фамилии, и после по Имени
Для заметки. Для сортировки по возрастанию есть ключевое слово ASC, но так как сортировка по возрастанию применяется по умолчанию, то про эту опцию можно забыть (я не помню случая, чтобы я когда-то использовал эту опцию).
Стоит отметить, что в предложении ORDER BY можно использовать и поля, которые не перечислены в предложении SELECT (кроме случая, когда используется DISTINCT, об этом случае я расскажу ниже). Для примера забегу немного вперед используя опцию TOP и покажу, как например, можно отобрать 3-х сотрудников у которых самая высокая ЗП, с учетом что саму ЗП в целях конфиденциальности я показывать не должен:
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY Salary DESC -- сортируем результат по убыванию Заработной Платы
| ID | LastName | FirstName |
|---|---|---|
| 1000 | Иванов | Иван |
| 1002 | Сидоров | Сидор |
Конечно здесь есть случай, что у нескольких сотрудников может быть одинаковая ЗП и тут сложно сказать каких именно трех сотрудников вернет данный запрос, это уже нужно решать с постановщиком задачи. Допустим, после обсуждения с постановщиком данной задачи, вы согласовали и решили использовать следующий вариант – сделать дополнительную сортировку по полю даты рождения (т.е. молодым у нас дорога), а если и дата рождения у нескольких сотрудников может совпасть (ведь такое тоже не исключено), то можно сделать третью сортировку по убыванию значений ID (в последнюю очередь под выборку попадут те, у кого ID окажется максимальным – например, те кто был принят последним, допустим табельные номера у нас выдаются последовательно):
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата ID,LastName,FirstName FROM Employees ORDER BY Salary DESC, -- 1. сортируем результат по убыванию Заработной Платы Birthday, -- 2. потом по Дате рождения ID DESC -- 3. и для полной однозначности результата добавляем сортировку по ID
Т.е. вы должны стараться чтобы результат запроса был предсказуемым, чтобы вы могли в случае разбора полетов объяснить почему в «черный список» попали именно эти люди, т.е. все было выбрано честно, по утверждённым правилам.
Сортировать можно так же используя разные выражения в предложении ORDER BY:
SELECT LastName,FirstName FROM Employees ORDER BY CONCAT(LastName," ",FirstName) -- используем выражение
Так же в ORDER BY можно использовать псевдонимы заданные для колонок:
SELECT CONCAT(LastName," ",FirstName) fi FROM Employees ORDER BY fi -- используем псевдоним
Стоит отметить что в случае использования предложения DISTINCT, в предложении ORDER BY могут использоваться только колонки, перечисленные в блоке SELECT. Т.е. после применения операции DISTINCT мы получаем новый набор данных, с новым набором колонок. По этой причине, следующий пример не отработает:
SELECT DISTINCT LastName,FirstName,Salary FROM Employees ORDER BY ID -- ID отсутствует в итоговом наборе, который мы получили при помощи DISTINCT
Т.е. предложение ORDER BY применяется уже к итоговому набору, перед выдачей результата пользователю.
Примечание 1. Так же в предложении ORDER BY можно использовать номера столбцов, перечисленных в SELECT:SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- упорядочить в порядке 3 DESC, -- 1. убывания Заработной Платы 1, -- 2. по Фамилии 2 -- 3. по Имени
Для начинающих выглядит удобно и заманчиво, но лучше забыть и никогда не использовать такой вариант сортировки.
Если в данном случае (когда поля явно перечислены), такой вариант еще допустим, то для случая с использованием «*» такой вариант лучше никогда не применять. Почему – потому что, если кто-то, например, поменяет в таблице порядок столбцов, или удалит столбцы (и это нормальная ситуация), ваш запрос может так же работать, но уже неправильно, т.к. сортировка уже может идти по другим столбцам, и это коварно тем что данная ошибка может обнаружиться очень нескоро.
В случае, если бы столбы были явно перечислены, то в вышеуказанной ситуации, запрос либо бы продолжал работать, но также правильно (т.к. все явно определено), либо бы он просто выдал ошибку, что данного столбца не существует.
Так что можете смело забыть, о сортировке по номерам столбцов.
Примечание 2.
В MS SQL при сортировке по возрастанию NULL значения будут отображаться первыми.SELECT BonusPercent FROM Employees ORDER BY BonusPercent
Соответственно при использовании DESC они будут в конце
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC
Если необходимо поменять логику сортировки NULL значений, то используйте выражения, например:
SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)
В ORACLE для этой цели предусмотрены 2 опции NULLS FIRST и NULLS LAST (применяется по умолчанию). Например:
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LAST
Обращайте на это внимание при переходе на ту или иную БД.
TOP – возврат указанного числа записей
Вырезка из MSDN. TOP – ограничивает число строк, возвращаемых в результирующем наборе запроса до заданного числа или процентного значения. Если предложение TOP используется совместно с предложением ORDER BY, то результирующий набор ограничен первыми N строками отсортированного результата. В противном случае возвращаются первые N строк в неопределенном порядке.
Обычно данное выражение используется с предложением ORDER BY и мы уже смотрели примеры, когда нужно было вернуть N-первых строк из результирующего набора.
Без ORDER BY обычно данное предложение применяется, когда нужно просто посмотреть на неизвестную нам таблицу, в которой может быть очень много записей, в этом случае мы можем, для примера, попросить вернуть нам только первые 10 строк, но для наглядности мы скажем только 2:
SELECT TOP 2 * FROM Employees
Так же можно указать слово PERCENT, для того чтобы вернулось соответствуй процент строк из результирующего набора:
SELECT TOP 25 PERCENT * FROM Employees
На моей практике чаше применяется именно выборка по количеству строк.
Так же с TOP можно использовать опцию WITH TIES, которая поможет вернуть все строки в случае неоднозначной сортировки, т.е. это предложение вернет все строки, которые равны по составу строкам, которые попадают в выборку TOP N, в итоге строк может быть выбрано больше чем N. Давайте для демонстрации добавим еще одного «Программиста» с окладом 1500:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1004,N"Николаев Н.Н.","[email protected]",3,3,1003,1500)
И введем еще одного сотрудника без указания должности и отдела с окладом 2000:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1005,N"Александров А.А.","[email protected]",NULL,NULL,1000,2000)
Теперь давайте выберем при помощи опции WITH TIES всех сотрудников, у которых оклад совпадает с окладами 3-х сотрудников, с самым маленьким окладом (надеюсь дальше будет понятно, к чему я клоню):
SELECT TOP 3 WITH TIES ID,Name,Salary FROM Employees ORDER BY Salary
Здесь хоть и указано TOP 3, но запрос вернул 4 записи, т.к. значение Salary которое вернуло TOP 3 (1500 и 2000) оказалось у 4-х сотрудников. Наглядно это работает примерно следующим образом:

На заметку.
В разных БД TOP реализуется разными способами, в MySQL для этого есть предложение LIMIT, в котором дополнительно можно задать начальное смещение.В ORACLE 12c, тоже ввели свой аналог совмещающий функциональность TOP и LIMIT – ищите по словам «ORACLE OFFSET FETCH». До версии 12c для этой цели обычно использовался псевдостолбец ROWNUM.
А что же будет если применить одновременно предложения DISTINCT и TOP? На такие вопросы легко ответить, проводя эксперименты. В общем, не бойтесь и не ленитесь экспериментировать, т.к. большая часть познается именно на практике. Порядок слов в операторе SELECT следующий, первым идет DISTINCT, а после него идет TOP, т.е. если рассуждать логически и читать слева-направо, то первым применится отброс дубликатов, а потом уже по этому набору будет сделан TOP. Что-ж проверим и убедимся, что так и есть:
SELECT DISTINCT TOP 2
Salary
FROM Employees
ORDER BY Salary
| Salary |
|---|
| 1500 |
| 2000 |
Т.е. в результате мы получили 2 самые маленькие зарплаты из всех. Конечно может быть случай что ЗП для каких-то сотрудников может быть не указанной (NULL), т.к. схема нам это позволяет. Поэтому в зависимости от задачи принимаем решение либо обработать NULL значения в предложении ORDER BY, либо просто отбросить все записи, у которых Salary равна NULL, а для этого переходим к изучению предложения WHERE.
WHERE – условие выборки строк
Данное предложение служит для фильтрации записей по заданному условию. Например, выберем всех сотрудников работающих в «ИТ» отделе (его ID=3):SELECT ID,LastName,FirstName,Salary
FROM Employees
WHERE DepartmentID=3 -- ИТ
ORDER BY LastName,FirstName
| ID | LastName | FirstName | Salary |
|---|---|---|---|
| 1004 | NULL | NULL | 1500 |
| 1003 | Андреев | Андрей | 2000 |
| 1001 | Петров | Петр | 1500 |
Предложение WHERE пишется до команды ORDER BY.
Порядок применения команд к исходному набору Employees следующий:
- WHERE – если указано, то первым делом из всего набора Employees идет отбор только удовлетворяющих условию записей
- DISTINCT – если указано, то отбрасываются все дубликаты
- ORDER BY – если указано, то делается сортировка результата
- TOP – если указано, то из отсортированного результата возвращается только указанное число записей
Рассмотрим для наглядности пример:
SELECT DISTINCT TOP 1 Salary FROM Employees WHERE DepartmentID=3 ORDER BY Salary
Наглядно это будет выглядеть следующим образом:

Стоит отметить, что проверка на NULL делается не знаком равенства, а при помощи операторов IS NULL и IS NOT NULL. Просто запомните, что на NULL при помощи оператора «=» (знак равенства) сравнивать нельзя, т.к. результат выражения будет так же равен NULL.
Например, выберем всех сотрудников, у которых не указан отдел (т.е. DepartmentID IS NULL):
SELECT ID,Name
FROM Employees
WHERE DepartmentID IS NULL
Теперь для примера посчитаем бонус для всех сотрудников у которых указано значение BonusPercent (т.е. BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent IS NOT NULL
Да, кстати, если подумать, то значение BonusPercent может равняться нулю (0), а так же значение может быть внесено со знаком минус, ведь мы не накладывали на данное поле никаких ограничений.
Хорошо, рассказав о проблеме, нам пока сказали считать, что если (BonusPercent<=0 или BonusPercent IS NULL), то это означает что у сотрудника так же нет бонуса. Для начала, как нам сказали, так и сделаем, реализуем это при помощи логического оператора OR и NOT:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL)
Т.е. здесь мы начали изучать булевы операторы. Выражение в скобках «(BonusPercent<=0 OR BonusPercent IS NULL)» проверяет на то что у сотрудника нет бонуса, а NOT инвертирует это значение, т.е. говорит «верни всех сотрудников которые не сотрудники у которых нет бонуса».
Так же данное выражение можно переписать и сразу сказав сразу «верни всех сотрудников, у которых есть бонус» выразив это выражением (BonusPercent>0 и BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent>0 AND BonusPercent IS NOT NULL
Также в блоке WHERE можно делать проверку разного рода выражений с применением арифметических операторов и функций. Например, аналогичную проверку можно сделать, использовав выражение с функцией ISNULL:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE ISNULL(BonusPercent,0)>0
Булевы операторы и простые операторы сравнения
Да, без математики здесь не обойтись, поэтому сделаем небольшой экскурс по булевым и простым операторам сравнения.Булевых операторов в языке SQL всего 3 – AND, OR и NOT:
Для каждого булева оператора можно привести таблицы истинности где дополнительно показано какой будет результат, когда условия могут быть равны NULL:

Есть следующие простые операторы сравнения, которые используются для формирования условий:
Плюс имеются 2 оператора для проверки значения/выражения на NULL:
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Приоритет: 1) Все операторы сравнения; 2) NOT; 3) AND; 4) OR.
При построении сложных логических выражений используются круглые скобки:
((условие1 AND условие2) OR NOT(условие3 AND условие4 AND условие5)) OR (…)
Так же при помощи использования круглых скобок, можно изменить стандартную последовательность вычислений.
Здесь я постарался дать представление о булевой алгебре в достаточном для работы объеме. Как видите, чтобы писать условия посложнее без логики уже не обойтись, но ее здесь немного (AND, OR и NOT) и придумывали ее люди, так что все достаточно логично.
Идем к завершению второй части
Как видите даже про базовый синтаксис оператора SELECT можно говорить очень долго, но, чтобы остаться в рамках статьи, напоследок я покажу дополнительные логических операторы – BETWEEN, IN и LIKE.BETWEEN – проверка на вхождение в диапазон
Проверяемое_значение BETWEEN начальное_ значение AND конечное_ значение
В роли значений могут выступать выражения.
Разберем на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
Собственно, BETWEEN это упрощенная запись вида:
SELECT ID,Name,Salary FROM Employees WHERE Salary>=2000 AND Salary<=3000 -- все у кого ЗП в диапозоне 2000-3000
Перед словом BETWEEN может использоваться слово NOT, которое будет осуществлять проверку значения на не вхождение в указанный диапазон:
SELECT ID,Name,Salary FROM Employees WHERE Salary NOT BETWEEN 2000 AND 3000 -- аналогично выражению NOT(Salary>=2000 AND Salary<=3000)
Соответственно, в случае использования BETWEEN, IN, LIKE вы можете так же объединять их с другими условиями при помощи AND и OR:
SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000 AND DepartmentID=3 -- учитывать сотрудников только отдела 3
IN – проверка на вхождение в перечень значений
Этот оператор имеет следующий вид:Проверяемое_значение IN (значение1, значение2, …)
Думаю, проще показать на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID IN(3,4) -- у кого должность равна 3 или 4
Т.е. по сути это аналогично следующему выражению:
SELECT ID,Name,Salary FROM Employees WHERE PositionID=3 OR PositionID=4 -- у кого должность равна 3 или 4
В случае NOT это будет аналогично (получим всех кроме тех, кто из отдела 3 и 4):
SELECT ID,Name,Salary FROM Employees WHERE PositionID NOT IN(3,4) -- аналогично выражению NOT(PositionID=3 OR PositionID=4)
Так же запрос с NOT IN можно выразить и через AND:
SELECT ID,Name,Salary FROM Employees WHERE PositionID<>3 AND PositionID<>4 -- равносильно PositionID NOT IN(3,4)
Учтите, что искать NULL значения при помощи конструкции IN не получится, т.к. проверка NULL=NULL вернет так же NULL, а не True:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2,NULL) -- NULL записи не войдут в результат
В этом случае разбивайте проверку на несколько условий:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2) -- 1 или 2 OR DepartmentID IS NULL -- или NULL
Или же можно написать что-то вроде:
SELECT ID,Name,DepartmentID FROM Employees WHERE ISNULL(DepartmentID,-1) IN(1,2,-1) -- если вы уверены, что в нет и не будет департамента с ID=-1
Думаю, первый вариант, в данном случае будет более правильным и надежным. Ну ладно, это всего лишь пример, для демонстрации того какие еще конструкции можно строить.
Так же стоит упомянуть еще более коварную ошибку, связанную с NULL, которую можно допустить при использовании конструкции NOT IN. Для примера, давайте попробуем выбрать всех сотрудников, кроме тех, у которых отдел равен 1 или у которых отдел вообще не указан, т.е. равен NULL. В качестве решения напрашивается вариант:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1,NULL)
Но выполнив запрос, мы не получим ни одной строки, хотя мы ожидали увидеть следующее:
Опять же шутку здесь сыграло NULL указанное в списке значений.
Разберем почему в данном случае возникла логическая ошибка. Разложим запрос при помощи AND:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID<>1 AND DepartmentID<>NULL -- проблема из-за этой проверки на NULL - это условие всегда вернет NULL
Правое условие (DepartmentID<>NULL) нам всегда здесь даст неопределенность, т.е. NULL. Теперь вспомним таблицу истинности для оператора AND, где (TRUE AND NULL) дает NULL. Т.е. при выполнении левого условия (DepartmentID<>1) из-за неопределенного правого условия в результате мы получим неопределенное значение всего выражения (DepartmentID<>1 AND DepartmentID<>NULL), поэтому строка не войдет в результат.
Переписать условие правильно можно следующим образом:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1) -- или в данном случае просто DepartmentID<>1 AND DepartmentID IS NOT NULL -- и отдельно проверяем на NOT NULL
IN еще можно использовать с подзапросами, но к такой форме мы вернемся, уже в последующих частях данного учебника.
LIKE – проверка строки по шаблону
Про данный оператор я расскажу только в самом простом виде, который является стандартом и поддерживается большинством диалектов языка SQL. Даже в таком виде при помощи него можно решить много задач, которые требуют выполнить проверку по содержимому строки.Этот оператор имеет следующий вид:
Проверяемая_строка LIKE строка_шаблон
В «строке_шаблон» могут применятся следующие специальные символы:
- Знак подчеркивания «_» - говорит, что на его месте может стоять любой единичный символ
- Знак процента «%» - говорит, что на его месте может стоять сколько угодно символов, в том числе и ни одного
SELECT ID,Name FROM Employees WHERE Name LIKE "Пет%" -- у кого имя начинается с букв "Пет" SELECT ID,LastName FROM Employees WHERE LastName LIKE "%ов" -- у кого фамилия оканчивается на "ов" SELECT ID,LastName FROM Employees WHERE LastName LIKE "%ре%" -- у кого фамилия содержит сочетание "ре"
Рассмотрим примеры с символом «_»:
SELECT ID,LastName FROM Employees WHERE LastName LIKE "_етров" -- у кого фамилия состоит из любого первого символа и последующих букв "етров" SELECT ID,LastName FROM Employees WHERE LastName LIKE "____ов" -- у кого фамилия состоит из четырех любых символов и последующих букв "ов"
При помощи ESCAPE можно задать отменяющий символ, который отменяет проверяющее действие специальных символов «_» и «%». Данное предложение используется, когда в строке нужно непосредственно проверить наличие знака процента или знака подчеркивания.
Для демонстрации ESCAPE давайте занесем в одну запись мусор:
UPDATE Employees SET FirstName="Это_мусор, содержащий %" WHERE ID=1005
И посмотрим, что вернут следующие запросы:
SELECT * FROM Employees WHERE FirstName LIKE "%!%%" ESCAPE "!" -- строка содержит знак "%" SELECT * FROM Employees WHERE FirstName LIKE "%!_%" ESCAPE "!" -- строка содержит знак "_"
В случае, если требуется проверить строку на полное совпадение, то вместо LIKE лучше использовать просто знак «=»:
SELECT * FROM Employees WHERE FirstName="Петр"
На заметку.
В MS SQL в шаблоне оператора LIKE так же можно задать поиск по регулярным выражениям, почитайте о нем в интернете, в том случае, если вам станет недостаточно стандартных возможностей данного оператора.В ORACLE для поиска по регулярным выражениям применяется функция REGEXP_LIKE.
Немного о строках
В случае проверки строки на наличие Unicode символов, нужно будет ставить перед кавычками символ N, т.е. N"…". Но так как у нас в таблице все символьные поля в формате Unicode (тип nvarchar), то для этих полей можно всегда использовать такой формат. Пример:SELECT ID,Name FROM Employees WHERE Name LIKE N"Пет%" SELECT ID,LastName FROM Employees WHERE LastName=N"Петров"
Если делать правильно, при сравнении с полем типа varchar (ASCII) нужно стараться использовать проверки с использованием "…", а при сравнении поля с типом nvarchar (Unicode) нужно стараться использовать проверки с использованием N"…". Это делается для того, чтобы избежать в процессе выполнения запроса неявных преобразований типов. То же самое правило используем при вставке (INSERT) значений в поле или их обновлении (UPDATE).
При сравнении строк стоит учесть момент, что в зависимости от настройки БД (collation), сравнение строк может быть, как регистро-независимым (когда "Петров"="ПЕТРОВ"), так и регистро-зависимым (когда "Петров"<>"ПЕТРОВ").
В случае регистро-зависимой настройки, если требуется сделать поиск без учета регистра, то можно, например, сделать предварительное преобразование правого и левого выражения в один регистр – верхний или нижний:
SELECT ID,Name FROM Employees WHERE UPPER(Name) LIKE UPPER(N"Пет%") -- или LOWER(Name) LIKE LOWER(N"Пет%") SELECT ID,LastName FROM Employees WHERE UPPER(LastName)=UPPER(N"Петров") -- или LOWER(LastName)=LOWER(N"Петров")
Немного о датах
При проверке на дату, вы можете использовать, как и со строками одинарные кавычки "…".Вне зависимости от региональных настроек в MS SQL можно использовать следующий синтаксис дат "YYYYMMDD" (год, месяц, день слитно без пробелов). Такой формат даты MS SQL поймет всегда:
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN "19800101" AND "19891231" -- сотрудники 80-х годов ORDER BY Birthday
В некоторых случаях, дату удобнее задавать при помощи функции DATEFROMPARTS:
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31) ORDER BY Birthday
Так же есть аналогичная функция DATETIMEFROMPARTS, которая служит для задания Даты и Времени (для типа datetime).
Еще вы можете использовать функцию CONVERT, если требуется преобразовать строку в значение типа date или datetime:
SELECT CONVERT(date,"12.03.2015",104), CONVERT(datetime,"2014-11-30 17:20:15",120)
Значения 104 и 120, указывают какой формат даты используется в строке. Описание всех допустимых форматов вы можете найти в библиотеке MSDN задав в поиске «MS SQL CONVERT».
Функций для работы с датами в MS SQL очень много, ищите «ms sql функции для работы с датами».
Примечание. Во всех диалектах языка SQL свой набор функций по работе с датами и применяется свой подход по работе с ними.
Немного о числах и их преобразованиях
Информация этого раздела наверно больше будет полезна ИТ-специалистам. Если вы таковым не являетесь, а ваша цель просто научится писать запросы для получения из БД необходимой вам информации, то такие тонкости вам возможно и не понадобятся, но в любом случае можете бегло пройтись по тексту и взять что-то на заметку, т.к. если вы взялись за изучение SQL, то вы уже приобщаетесь к ИТ.В отличие от функции преобразования CAST, в функции CONVERT можно задать третий параметр, который отвечает за стиль преобразования (формат). Для разных типов данных может использоваться свой набор стилей, которые могут повлиять на возвращаемый результат. Использование стилей мы уже затрагивали при рассмотрении преобразования строки функцией CONVERT в типы date и datetime.
Подробней про функции CAST, CONVERT и стили можно почитать в MSDN – «Функции CAST и CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Для упрощения примеров здесь будут использованы инструкции языка Transact-SQL – DECLARE и SET.
Конечно, в случае преобразования целого числа в вещественное (которое я привел вначале данного урока, в целях демонстрации разницы между целочисленным и вещественным делением), знание нюансов преобразования не так критично, т.к. там мы делали преобразование целого числа в вещественное (диапазон которого намного больше диапазона целых):
DECLARE @min_int int SET @min_int=-2147483648 DECLARE @max_int int SET @max_int=2147483647 SELECT -- (-2147483648) @min_int,CAST(@min_int AS float),CONVERT(float,@min_int), -- 2147483647 @max_int,CAST(@max_int AS float),CONVERT(float,@max_int), -- numeric(16,6) @min_int/1., -- (-2147483648.000000) @max_int/1. -- 2147483647.000000
Возможно не стоило указывать способ неявного преобразования, получаемого делением на (1.), т.к. желательно стараться делать явные преобразования, для большего контроля типа получаемого результата. Хотя, в случае, если мы хотим получить результат типа numeric, с указанным количеством цифр после запятой, то мы можем в MS SQL применить трюк с умножением целого значения на (1., 1.0, 1.00 и т.д):
DECLARE @int int SET @int=123 SELECT @int*1., -- numeric(12, 0) - 0 знаков после запятой @int*1.0, -- numeric(13, 1) - 1 знак @int*1.00, -- numeric(14, 2) - 2 знака -- хотя порой лучше сделать явное преобразование CAST(@int AS numeric(20, 0)), -- 123 CAST(@int AS numeric(20, 1)), -- 123.0 CAST(@int AS numeric(20, 2)) -- 123.00
В некоторых случаях детали преобразования могут быть действительно важны, т.к. они влияют на правильность полученного результата, например, в случае, когда делается преобразование числового значения в строку (varchar). Рассмотрим примеры по преобразованию значений типа money и float в varchar:
Поведение при преобразовании money в varchar DECLARE @money money SET @money = 1025.123456789 -- произойдет неявное преобразование в 1025.1235, т.к. тип money хранит только 4 цифры после запятой SELECT @money, -- 1025.1235 -- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0) CAST(@money as varchar(20)), -- 1025.12 CONVERT(varchar(20), @money), -- 1025.12 CONVERT(varchar(20), @money, 0), -- 1025.12 (стиль 0 - без разделителя тысячных и 2 цифры после запятой (формат по умолчанию)) CONVERT(varchar(20), @money, 1), -- 1,025.12 (стиль 1 - используется разделитель тысячных и 2 цифры после запятой) CONVERT(varchar(20), @money, 2) -- 1025.1235 (стиль 2 - без разделителя и 4 цифры после запятой)
Поведение при преобразовании float в varchar DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 SELECT @float1, -- 1025.123456789 @float2, -- 1231025.12345679 -- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0) -- стиль 0 - Не более 6 разрядов. По необходимости используется экспоненциальное представление чисел -- при преобразовании в varchar здесь творятся действительно страшные вещи CAST(@float1 as varchar(20)), -- 1025.12 CONVERT(varchar(20), @float1), -- 1025.12 CONVERT(varchar(20), @float1, 0), -- 1025.12 CAST(@float2 as varchar(20)), -- 1.23103e+006 CONVERT(varchar(20), @float2), -- 1.23103e+006 CONVERT(varchar(20), @float2, 0), -- 1.23103e+006 -- стиль 1 - Всегда 8 разрядов. Всегда используется экспоненциальное представление чисел. -- этот стиль для float тоже не очень точен CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003 CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006 -- стиль 2 - Всегда 16 разрядов. Всегда используется экспоненциальное представление чисел. -- здесь с точностью уже получше CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK
Как видно из примера, плавающие типы float, real в некоторых случаях действительно могут создать большую погрешность, особенно при перегонке в строку и обратно (такое может быть при разного рода интеграциях, когда данные, например, передаются в текстовых файлах из одной системы в другую).
Если нужно явно контролировать точность до определенного знака, более 4-х, то для хранения данных, порой лучше использовать тип decimal/numeric. Если хватает 4-х знаков, то можно использовать и тип money – он примерно соотвествует numeric(20,4).
Decimal и numeric DECLARE @money money SET @money = 1025.123456789 -- 1025.1235 DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789 SELECT CAST(@numeric as varchar(20)), -- 1025.12345679 CONVERT(varchar(20), @numeric), -- 1025.12345679 CAST(@money as numeric(28,9)), -- 1025.123500000 CAST(@float1 as numeric(28,9)), -- 1025.123456789 CAST(@float2 as numeric(28,9)) -- 1231025.123456789
Примечание.
С версии MS SQL 2008, можно использовать вместо конструкции:ms sql server Добавить метки
Последнее обновление: 24.06.2017
SQL Server является одной из наиболее популярных систем управления базами данных (СУБД) в мире. Данная СУБД подходит для самых различных проектов: от небольших приложений до больших высоконагруженных проектов.
SQL Server был создан компанией Microsoft. Первая версия вышла в 1987 году. А текущей версией является версия 16, которая вышла в 2016 году и которая будет использоваться в текущем руководстве.
SQL Server долгое время был исключительно системой управления базами данных для Windows, однако начиная с версии 16 эта система доступна и на Linux.
SQL Server характеризуется такими особенностями как:
Производительность. SQL Server работает очень быстро.
Надежность и безопасность. SQL Server предоставляет шифрование данных.
Простота. С данной СУБД относительно легко работать и вести администрирование.
Центральным аспектом в MS SQL Server, как и в любой СУБД, является база данных. База данных представляет хранилище данных, организованных определенным способом. Нередко физически база данных представляет файл на жестком диске, хотя такое соответствие необязательно. Для хранения и администрирования баз данных применяются системы управления базами данных (database management system) или СУБД (DBMS). И как раз MS SQL Server является одной из такой СУБД.
Для организации баз данных MS SQL Server использует реляционную модель. Эта модель баз данных была разработана еще в 1970 году Эдгаром Коддом. А на сегодняшний день она фактически является стандартом для организации баз данных.
Реляционная модель предполагает хранение данных в виде таблиц, каждая из которых состоит из строк и столбцов. Каждая строка хранит отдельный объект, а в столбцах размещаются атрибуты этого объекта.
Для идентификации каждой строки в рамках таблицы применяется первичный ключ (primary key). В качестве первичного ключа может выступать один или несколько столбцов. Используя первичный ключ, мы можем ссылаться на определенную строку в таблице. Соответственно две строки не могут иметь один и тот же первичный ключ.
Через ключи одна таблица может быть связана с другой, то есть между двумя таблицами могут быть организованы связи. А сама таблица может быть представлена в виде отношения ("relation").
Для взаимодействия с базой данных применяется язык SQL (Structured Query Language). Клиент (например, внешняя программа) отправляет запрос на языке SQL посредством специального API. СУБД должным образом интерпретирует и выполняет запрос, а затем посылает клиенту результат выполнения.
Изначально язык SQL был разработан в компании IBM для системы баз данных, которая называлась System/R. При этом сам язык назывался SEQUEL (Structured English Query Language). Хотя в итоге ни база данных, ни сам язык не были впоследствии официально опубликованы, по традиции сам термин SQL нередко произносят как "сиквел".
В 1979 году компания Relational Software Inc. разработала первую систему управления баз данных, которая называлась Oracle и которая использовала язык SQL. В связи с успехом данного продукта компания была переименована в Oracle.
Впоследствии стали появляться другие системы баз данных, которые использовали SQL. В итоге в 1989 году Американский Национальный Институт Стандартов (ANSI) кодифицировал язык и опубликовал его первый стандарт. После этого стандарт периодически обновлялся и дополнялся. Последнее его обновление состоялось в 2011 году. Но несмотря на наличие стандарта нередко производители СУБД используют свои собственные реализации языка SQL, которые немного отличаются друг от друга.
Выделяются две разновидности языка SQL: PL-SQL и T-SQL. PL-SQL используется в таких СУБД как Oracle и MySQL. T-SQL (Transact-SQL) применяется в SQL Server. Собственно поэтому в рамках текущего руководства будет рассматриваться именно T-SQL.
В зависимости от задачи, которую выполняет команда T-SQL, он может принадлежать к одному из следующих типов:
CREATE : создает объекты базы данных (саму базу даных, таблицы, индексы и т.д.)
ALTER : изменяет объекты базы данных
DROP : удаляет объекты базы данных
TRUNCATE : удаляет все данные из таблиц
SELECT : извлекает данные из БД
UPDATE : обновляет данные
INSERT : добавляет новые данные
DELETE : удаляет данные
GRANT : предоставляет права для доступа к данным
REVOKE : отзывает права на доступ к данным
DDL (Data Definition Language / Язык определения данных). К этому типу относятся различные команды, которые создают базу данных, таблицы, индексы, хранимые процедуры и т.д. В общем определяют данные.
В частности, к этому типу мы можем отнести следующие команды:
DML (Data Manipulation Language / Язык манипуляции данными). К этому типу относят команды на выбору данных, их обновление, добавление, удаление - в общем все те команды, с помощью которыми мы можем управлять данными.
К этому типу относятся следующие команды:
DCL (Data Control Language / Язык управления доступа к данным). К этому типу относят команды, которые управляют правами по доступу к данным. В частности, это следующие команды:
Синтакс SQL
Этот раздел описывает основные различия в синтаксе языка SQL, используемого СУБД Firebird и MS SQL.
СУБД Firebird и MS SQL могут ссылаться на объекты базы данных (таблицы, поля и т.д.) по их именам напрямую, если имена объектов не содержат пробелы и другие недопустимые в прямой ссылке символы (например, нелатинские буквы). Для использования пробелов и других символов СУБД MS SQL использует квадратные скобки, [ и ] , а СУБД Firebird использует двойные кавычки, " . Еще одно различие - возможность использования в СУБД MS SQL схемы для ссылки на объект: база_данных.владелец_объекта.объект . СУБД Firebird не допускает такой нотации.
Внимание
СУБД MS SQL использует регистро-зависимые имена объектов, если при установке Вы выбрали использование различения регистра символов; в противном случае, имена объектов регистро-независимы. Весело? Не очень...
Подсказка
СУБД MS SQL способна работать с идентификаторами, имена которых заключены в двойные кавычки, но по умолчанию эта возможность доступна только при доступе через OLE DB и ODBC, но не при доступе через DB-Library. По этой причине такую практику работы следует избегать.
СУБД MS SQL 7 и выше поддерживает обновляемые соединения (joins) (обновление, удаление, вставка). СУБД Firebird не распознает такой синтакс.
Типы даных, конечно, различаются. Хотя обе СУБД имеют общее подмножество наиболее часто используемых типов. Этот вопрос редко вызывает проблемы при переносе базы данных.
Различаются встроенные функции. Большинство из встроенных функций СУБД MS SQL можно заменить в СУБД Firebird использованием функций, определяемых пользователем (UDFs).
Различаются форматы указания строковых констант для дат. СУБД Firebird принимает строки различных форматов, вне зависимости от используемой платформы. СУБД MS SQL, в свою очередь, использует совмещение серверо-независимых, серверо-платформенных форматов и формата настройки клиентского соединения. Дополнительно, методы доступа СУБД MS SQL обычно вводят один или два уровня, в которых строковая константа может быть преобразована в дату тем или иным образом.
В СУБД MS SQL можно определять бОльшее количество переменных окружения, чем в СУБД Firebird , но наиболее общие можно найти и в СУБД Firebird (извлечение идентификатора и имени пользователя). Единственная важная переменная, которая отсутствует в СУБД Firebird , - это переменная, возвращающая количество строк последней операции (с версии 1.5 СУБД Firebird такая переменная введена - прим. перев.).
Важное различие было в том, что СУБД Firebird 1.0 не поддерживала оператор CASE СУБД MS SQL. Иногда можно было заменить его функциональность использованием хранимой процедуры. Начиная с версии 1.5, СУБД Firebird поддерживает использование оператора CASE .
Небольшое различие между СУБД еще и в том, что СУБД MS SQL не использует разделителей для операторов, что может служить источником трудно обнаруживаемых ошибок при переходе, особенно при использовании множества скобок. СУБД Firebird в скриптах требует завершать каждый оператор точкой с запятой (если не определен другой разделитель - прим. перев.), поэтому ошибки легче обнаружить.
Обе СУБД MS SQL и Firebird поддерживают комментарии, заключенные между разделителями /* и */ . СУБД MS SQL также поддерживает синтакс «два дефиса » -- для однострочного комментария. Некоторые утилиты для СУБД Firebird также поддерживают такой синтакс.
WHILE
Оператор WHILE существует в обоих СУБД Firebird и MS SQL, но с некоторыми различиями. Не существует операторов BREAK или CONTINUE , но их можно эмулировать при помощи дополнительных конструкций. Так же есть небольшое различие в используемом синтаксисе: СУБД Firebird требует наличия ключевого слова DO после условия цикла. Сравните следующие эквивалентные части кода.
/* Синтакс Firebird. */ WHILE (i < 3) DO BEGIN i = i + 1; j = j * 2; END /* Синтакс MS SQL. */ WHILE (i < 3) BEGIN SET @i = @i + 1 SET @j = @j * 2 END
RETURN
Оператор RETURN в СУБД MS SQL возвращает значение целочисленной переменной и прекращает выполнение. В СУБД Firebird существует оператор EXIT , который передает управление на заключительный END хранимой процедуры. Однако здесь нет скрытой возвращаемой переменной, поэтому, если Вам необходимо вернуть некоторое значение (что опционально в СУБД MS SQL), Вы должны явно объявить возвращаемую переменную в процедуре.
WAITFOR
Оператор WAITFOR в СУБД MS SQL приостанавливает выполнение на некоторое время или до наступления указанного времени. Что-то подобное можно осуществить при помощи функций, определяемых пользователем (UDFs), в СУБД Firebird . Но в обоих СУБД использование такого оператора следует исключить, поскольку взаимодействие с клиентом полностью приостанавливается (в СУБД Firebird это может привести и к приостановке обслуживания всех соединений, а не только соединения, вызвавшего аналог указанного оператора - прим. перев.).
Стандартные операторы
Стандартными операторами, имеющимися в обоих СУБД, являются SELECT , INSERT , UPDATE и DELETE . СУБД Firebird и MS SQL поддерживают их, но в СУБД MS SQL есть несколько нестандартных расширений этих операторов, о которых необходимо рассказать на случай их использования.
В СУБД Firebird оператор SELECT не позволяет использовать ключевое слово INTO для создания новой таблицы «на лету ». Вместо этого, ключевое слово INTO используется для связи результата запроса с переменной.
/* Синтаксис MS SQL для присваивания значения поля переменной. */ SELECT @my_state = state FROM authors WHERE auth_name = "John" /* Синтаксис Firebird. */ SELECT state INTO:state /* --> обратите внимание на ":" перед именем переменной */ FROM authors WHERE auth_name = "John"
В СУБД MS SQL 7 и выше в операторе SELECT можно указвать спецификатор TOP для органичения возвращаемого набора данных. Эта функция в настоящий момент находится в стадии разработки для СУБД Firebird . (Спецификаторы FIRST и SKIP в СУБД Firebird введены, начиная с версии 1.5. - прим. перев.)
Обе СУБД MS SQL и Firebird поддерживают обычный синтаксис оператора INSERT и оператора INSERT..SELECT .
Обе СУБД MS SQL и Firebird поддерживают обычный синтаксис оператора UPDATE . СУБД MS SQL также поддерживает синтаксис оператора UPDATE , в котором выполняется соединение (join) и производится обновление одной из таблиц соединения. Можно думать об этом как об условии WHERE на стероидах. Если такая функция очень нужна, то ее можно реализовать в СУБД Firebird с использованием представлений (views).
Обе СУБД MS SQL и Firebird поддерживают обычный синтаксис оператора DELETE . СУБД MS SQL также поддерживает оператор TRUNCATE TABLE , который более эффективен (но и опаснее), чем оператор DELETE . (СУБД MS SQL также поддерживает синтаксис оператора DELETE , в котором выполняется соединение. - прим. перев.)
/* Синтаксис MS SQL для удаления всех записей my_table. */ TRUNCATE TABLE my_table /* ...или... */ DELETE FROM my_table /* Синтаксис Firebird. */ DELETE FROM my_table
Использование транзакций
В СУБД Firebird в DSQL (dynamic SQL) транзакции «напрямую » не используются. Именованные транзакции в этом случае недоступны совсем. (Операторы DSQL выполняются в контексте транзакций, запущенных и контролируемых клиентским приложением.- прим. перев.) Синтаксис обоих СУБД поддерживает ключевое слово WORK для совместимости.
В большинстве случаев проблем с транзакциями не должно возникать: явное управление транзакциями «на месте » в СУБД MS SQL используется обычно из-за отсутствия поддержки управлением через исключения (exceptions).
Подсказка
В СУБД MS SQL есть глобальная переменная XACT_ABORT , которая управляет откатом транзакции при возникновении ошибки времени выполнения (run-time error). В противном случае Вам необходимо проверять значение переменной @@ERROR после выполнения каждого оператора.
В общем, большинство проблем, связанных с уровнями изоляции транзакций в СУБД MS SQL, пропадают при переходе на СУБД Firebird . Соперничество между «читателями » и «писателями » минимально за счет использования многоверсионной архитектуры (multigeneration architecture, MGA).
В СУБД MS SQL курсоры используются, в основном, для перемещения по результатам запросов, чтобы выполнить с этими результатами некоторые действия. Кроме синтаксиса, нет большой разницы для выполнения одной и той же задачи. Хотя существуют опции для перемещения вперед и назад, на практике используются, по большей части, однонаправленные курсоры.
/* Синтакс MS SQL. */ DECLARE my_cursor CURSOR FOR SELECT au_lname FROM authors ORDER BY au_lname DECLARE @au_lname varchar(40) OPEN my_cursor FETCH NEXT FROM my_cursor INTO @au_lname WHILE @@FETCH_STATUS = 0 BEGIN /* Сделать что-то интересное с @au_lname. */ FETCH NEXT FROM my_cursor END CLOSE my_cursor DEALLOCATE my_cursor /* Синтакс Firebird. */ DECLARE VARIABLE au_lname VARCHAR(40); ... FOR SELECT au_lname FROM authors ORDER BY au_lname INTO:au_lname DO BEGIN /* Сделать что-то интересное с au_lname. */ END
Заметьте, что СУБД MS SQL может размещать курсоры в переменных, и передавать эти переменные как параметры; это невозможно в СУБД Firebird .
В первой части мы уже немного затронули язык DML, применяя почти весь набор его команд, за исключением команды MERGE.Рассказывать про DML я буду по своей последовательности выработанной на личном опыте. По ходу, так же постараюсь рассказать про «скользкие» места, на которые стоит акцентировать внимание, эти «скользкие» места, схожи во многих диалектах языка SQL.
Т.к. учебник посвящается широкому кругу читателей (не только программистам), то и объяснение, порой будет соответствующее, т.е. долгое и нудное. Это мое видение материала, которое в основном получено на практике в результате профессиональной деятельности.
Основная цель данного учебника, шаг за шагом, выработать полное понимание сути языка SQL и научить правильно применять его конструкции. Профессионалам в этой области, может тоже будет интересно пролистать данный материал, может и они смогут вынести для себя что-то новое, а может просто, будет полезно почитать в целях освежить память. Надеюсь, что всем будет интересно.
Т.к. DML в диалекте БД MS SQL очень сильно связан с синтаксисом конструкции SELECT, то я начну рассказывать о DML именно с нее. На мой взгляд конструкция SELECT является самой главной конструкцией языка DML, т.к. за счет нее или ее частей осуществляется выборка необходимых данных из БД.
Язык DML содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
В данной части, мы рассмотрим, только базовый синтаксис команды SELECT, который выглядит следующим образом:
SELECT список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
Тема оператора SELECT очень обширная, поэтому в данной части я и остановлюсь только на его базовых конструкциях. Я считаю, что, не зная хорошо базы, нельзя приступать к изучению более сложных конструкций, т.к. дальше все будет крутиться вокруг этой базовой конструкции (подзапросы, объединения и т.д.).
Также в рамках этой части, я еще расскажу о предложении TOP. Это предложение я намерено не указал в базовом синтаксисе, т.к. оно реализуется по-разному в разных диалектах языка SQL.
Если язык DDL больше статичен, т.е. при помощи него создаются жесткие структуры (таблицы, связи и т.п.), то язык DML носит динамический характер, здесь правильные результаты вы можете получить разными путями.
Обучение так же будет продолжаться в режиме Step by Step, т.е. при чтении нужно сразу же своими руками пытаться выполнить пример. После делаете анализ полученного результата и пытаетесь понять его интуитивно. Если что-то остается непонятным, например, значение какой-нибудь функции, то обращайтесь за помощью в интернет.
Примеры будут показываться на БД Test, которая была создана при помощи DDL+DML в первой части.
Для тех, кто не создавал БД в первой части (т.к. не всех может интересовать язык DDL), может воспользоваться следующим скриптом:
Скрипт создания БД Test
Создание БД
CREATE DATABASE Test
GO
-- сделать БД Test текущей
USE Test
GO
-- создаем таблицы справочники
CREATE TABLE Positions(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL)
CREATE TABLE Departments(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL)
GO
-- заполняем таблицы справочники данными
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name)VALUES
(1,N"Бухгалтер"),
(2,N"Директор"),
(3,N"Программист"),
(4,N"Старший программист")
SET IDENTITY_INSERT Positions OFF
GO
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name)VALUES
(1,N"Администрация"),
(2,N"Бухгалтерия"),
(3,N"ИТ")
SET IDENTITY_INSERT Departments OFF
GO
-- создаем таблицу с сотрудниками
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name))
GO
-- заполняем ее данными
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219","[email protected]",2,1,NULL),
(1001,N"Петров П.П.","19831203","[email protected]",3,3,1003),
(1002,N"Сидоров С.С.","19760607","[email protected]",1,2,1000),
(1003,N"Андреев А.А.","19820417","[email protected]",4,3,1000)
Все, теперь мы готовы приступить к изучению языка DML.
SELECT – оператор выборки данных
Первым делом, для активного редактора запроса, сделаем текущей БД Test, выбрав ее в выпадающем списке или же командой «USE Test».Начнем с самой элементарной формы SELECT:
SELECT *
FROM Employees
В данном запросе мы просим вернуть все столбцы (на это указывает «*») из таблицы Employees – можно прочесть это как «ВЫБЕРИ все_поля ИЗ таблицы_сотрудники». В случае наличия кластерного индекса, возвращенные данные, скорее всего будут отсортированы по нему, в данном случае по колонке ID (но это не суть важно, т.к. в большинстве случаев сортировку мы будем указывать в явном виде сами при помощи ORDER BY …):
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 | NULL |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 | 1000 |
Вообще стоит сказать, что в диалекте MS SQL самая простая форма запроса SELECT может не содержать блока FROM, в этом случае вы можете использовать ее, для получения каких-то значений:
SELECT
5550/100*15,
SYSDATETIME(), -- получение системной даты БД
SIN(0)+COS(0)
| (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
Обратите внимание, что выражение (5550/100*15) дало результат 825, хотя если мы посчитаем на калькуляторе получится значение (832.5). Результат 825 получился по той причине, что в нашем выражении все числа целые, поэтому и результат целое число, т.е. (5550/100) дает нам 55, а не (55.5).
Запомните следующее, что в MS SQL работает следующая логика:
- Целое / Целое = Целое (т.е. в данном случае происходит целочисленное деление)
- Вещественное / Целое = Вещественное
- Целое / Вещественное = Вещественное
SELECT
123/10, -- 12
123./10, -- 12.3
123/10. -- 12.3
Здесь (123.) = (123.0), просто в данном случае 0 можно отбросить и оставить только точку.
При других арифметических операциях действует та же самая логика, просто в случае деления этот нюанс более актуален.
Поэтому обращайте внимание на тип данных числовых столбцов. В том случае если он целый, а результат вам нужно получить вещественный, то используйте преобразование, либо просто ставьте точку после числа указанного в виде константы (123.).
Для преобразования полей можно использовать функцию CAST или CONVERT. Для примера воспользуемся полем ID, оно у нас типа int:
SELECT
ID,
ID/100, -- здесь произойдет целочисленное деление
CAST(ID AS float)/100, -- используем функцию CAST для преобразования в тип float
CONVERT(float,ID)/100, -- используем функцию CONVERT для преобразования в тип float
ID/100. -- используем преобразование за счет указания что знаменатель вещественное число
FROM Employees
| ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
На заметку. В БД ORACLE синтаксис без блока FROM недопустим, там для этой цели используется системная таблица DUAL, которая содержит одну строку:SELECT 5550/100*15, -- а в ORACLE результат будет равен 832.5 sysdate, sin(0)+cos(0) FROM DUAL
Примечание. Имя таблицы во многих РБД может предваряться именем схемы:SELECT * FROM dbo.Employees -- dbo – имя схемы
Схема – это логическая единица БД, которая имеет свое наименование и позволяет сгруппировать внутри себя объекты БД такие как таблицы, представления и т.д.
Определение схемы в разных БД может отличатся, где-то схема непосредственно связанна с пользователем БД, т.е. в данном случае можно сказать, что схема и пользователь – это синонимы и все создаваемые в схеме объекты по сути являются объектами данного пользователя. В MS SQL схема – это независимая логическая единица, которая может быть создана сама по себе (см. CREATE SCHEMA).
По умолчанию в базе MS SQL создается одна схема с именем dbo (Database Owner) и все создаваемые объекты по умолчанию создаются именно в данной схеме. Соответственно, если мы в запросе указываем просто имя таблицы, то она будет искаться в схеме dbo текущей БД. Если мы хотим создать объект в конкретной схеме, мы должны будем так же предварить имя объекта именем схемы, например, «CREATE TABLE имя_схемы.имя_таблицы(…)».
В случае MS SQL имя схемы может еще предваряться именем БД, в которой находится данная схема:
SELECT * FROM Test.dbo.Employees -- имя_базы.имя_схемы.таблица
Такое уточнение бывает полезным, например, если:Схема – очень удобное средство, которое полезно использовать при разработке архитектуры БД, а особенно крупных БД.
- в одном запросе мы обращаемся к объектам расположенных в разных схемах или базах данных
- требуется сделать перенос данных из одной схемы или БД в другую
- находясь в одной БД, требуется запросить данные из другой БД
- и т.п.
Так же не забываем, что в тексте запроса мы можем использовать как однострочные «-- …», так и многострочные «/* … */» комментарии. Если запрос большой и сложный, то комментарии могут очень помочь, вам или кому-то другому, через некоторое время, вспомнить или разобраться в его структуре.
Если столбцов в таблице очень много, а особенно, если в таблице еще очень много строк, плюс к тому если мы делаем запросы к БД по сети, то предпочтительней будет выборка с непосредственным перечислением необходимых вам полей через запятую:
SELECT ID,Name FROM Employees
Т.е. здесь мы говорим, что нам из таблицы нужно вернуть только поля ID и Name. Результат будет следующим (кстати оптимизатор здесь решил воспользоваться индексом, созданным по полю Name):
| ID | Name |
|---|---|
| 1003 | Андреев А.А. |
| 1000 | Иванов И.И. |
| 1001 | Петров П.П. |
| 1002 | Сидоров С.С. |
На заметку. Порой бывает полезным посмотреть на то как осуществляется выборка данных, например, чтобы выяснить какие индексы используются. Это можно сделать если нажать кнопку «Display Estimated Execution Plan – Показать расчетный план» или установить «Include Actual Execution Plan – Включить в результат актуальный план выполнения запроса» (в данном случае мы сможем увидеть уже реальный план, соответственно, только после выполнения запроса):Анализ плана выполнения очень полезен при оптимизации запроса, он позволяет выяснить каких индексов не хватает или же какие индексы вообще не используются и их можно удалить.
Если вы только начали осваивать DML, то сейчас для вас это не так важно, просто возьмите на заметку и можете спокойно забыть об этом (может это вам никогда и не пригодится) – наша первоначальная цель изучить основы языка DML и научится правильно применять их, а оптимизация это уже отдельное искусство. Порой важнее, чтобы на руках просто был правильно написанный запрос, который возвращает правильные результат с предметной точки зрения, а его оптимизацией уже занимаются отдельные люди. Для начала вам нужно научиться просто правильно писать запросы, используя любые средства для достижения цели. Главная цель которую вы сейчас должны достичь – чтобы ваш запрос возвращал правильные результаты.
Задание псевдонимов для таблиц
При перечислении колонок их можно предварять именем таблицы, находящейся в блоке FROM:SELECT Employees.ID,Employees.Name FROM Employees
Но такой синтаксис обычно использовать неудобно, т.к. имя таблицы может быть длинным. Для этих целей обычно задаются и применяются более короткие имена – псевдонимы (alias):
SELECT emp.ID,emp.Name
FROM Employees AS emp
или
SELECT emp.ID,emp.Name FROM Employees emp -- ключевое слово AS можно отпустить (я предпочитаю такой вариант)
Здесь emp – псевдоним для таблицы Employees, который можно будет использоваться в контексте данного оператора SELECT. Т.е. можно сказать, что в контексте этого оператора SELECT мы задаем таблице новое имя.
Конечно, в данном случае результаты запросов будут точно такими же как и для «SELECT ID,Name FROM Employees». Для чего это нужно будет понятно дальше (даже не в этой части), пока просто запоминаем, что имя колонки можно предварять (уточнять) либо непосредственно именем таблицы, либо при помощи псевдонима. Здесь можно использовать одно из двух, т.е. если вы задали псевдоним, то и пользоваться нужно будет им, а использовать имя таблицы уже нельзя.
На заметку. В ORACLE допустим только вариант задания псевдонима таблицы без ключевого слова AS.
DISTINCT – отброс строк дубликатов
Ключевое слово DISTINCT используется для того чтобы отбросить из результата запроса строки дубликаты. Грубо говоря представьте, что сначала выполняется запрос без опции DISTINCT, а затем из результата выбрасываются все дубликаты. Продемонстрируем это для большей наглядности на примере:Создадим для демонстрации временную таблицу CREATE TABLE #Trash(ID int NOT NULL PRIMARY KEY, Col1 varchar(10), Col2 varchar(10), Col3 varchar(10)) -- наполним данную таблицу всяким мусором INSERT #Trash(ID,Col1,Col2,Col3)VALUES (1,"A","A","A"), (2,"A","B","C"), (3,"C","A","B"), (4,"A","A","B"), (5,"B","B","B"), (6,"A","A","B"), (7,"A","A","A"), (8,"C","A","B"), (9,"C","A","B"), (10,"A","A","B"), (11,"A",NULL,"B"), (12,"A",NULL,"B") -- посмотрим что возвращает запрос без опции DISTINCT SELECT Col1,Col2,Col3 FROM #Trash -- посмотрим что возвращает запрос с опцией DISTINCT SELECT DISTINCT Col1,Col2,Col3 FROM #Trash -- удалим временную таблицу DROP TABLE #Trash
Наглядно это будет выглядеть следующим образом (все дубликаты помечены одним цветом):
Теперь давайте рассмотрим где это можно применить, на более практичном примере – вернем из таблицы Employees только уникальные идентификаторы отделов (т.е. узнаем ID отделов в которых числятся сотрудники):
SELECT DISTINCT DepartmentID
FROM Employees
Здесь мы получили 4 строчки, т.к. повторяющихся комбинаций (DepartmentID, PositionID) в нашей таблице нет.
Ненадолго вернемся к DDL
Так как данных для демонстрационных примеров начинает не хватать, а рассказать хочется более обширно и понятно, то давайте чуть расширим нашу таблицу Employess. К тому же немного вспомним DDL, как говорится «повторение – мать учения», и плюс снова немного забежим вперед и применим оператор UPDATE:Создаем новые колонки ALTER TABLE Employees ADD LastName nvarchar(30), -- фамилия FirstName nvarchar(30), -- имя MiddleName nvarchar(30), -- отчество Salary float, -- и конечно же ЗП в каких-то УЕ BonusPercent float -- процент для вычисления бонуса от оклада GO -- наполняем их данными (некоторые данные намерено пропущены) UPDATE Employees SET LastName=N"Иванов",FirstName=N"Иван",MiddleName=N"Иванович", Salary=5000,BonusPercent= 50 WHERE ID=1000 -- Иванов И.И. UPDATE Employees SET LastName=N"Петров",FirstName=N"Петр",MiddleName=N"Петрович", Salary=1500,BonusPercent= 15 WHERE ID=1001 -- Петров П.П. UPDATE Employees SET LastName=N"Сидоров",FirstName=N"Сидор",MiddleName=NULL, Salary=2500,BonusPercent=NULL WHERE ID=1002 -- Сидоров С.С. UPDATE Employees SET LastName=N"Андреев",FirstName=N"Андрей",MiddleName=NULL, Salary=2000,BonusPercent= 30 WHERE ID=1003 -- Андреев А.А.
Убедимся, что данные обновились успешно:
SELECT *
FROM Employees
| ID | Name | … | LastName | FirstName | MiddleName | Salary | BonusPercent |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | Иванов | Иван | Иванович | 5000 | 50 | |
| 1001 | Петров П.П. | Петров | Петр | Петрович | 1500 | 15 | |
| 1002 | Сидоров С.С. | Сидоров | Сидор | NULL | 2500 | NULL | |
| 1003 | Андреев А.А. | Андреев | Андрей | NULL | 2000 | 30 |
Задание псевдонимов для столбцов запроса
Думаю, здесь будет проще показать, чем написать:SELECT
-- даем имя вычисляемому столбцу
LastName+" "+FirstName+" "+MiddleName AS ФИО,
-- использование двойных кавычек, т.к. используется пробел
HireDate AS "Дата приема",
-- использование квадратных скобок, т.к. используется пробел
Birthday AS [Дата рождения],
-- слово AS не обязательно
Salary ZP
FROM Employees
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
Как видим заданные нами псевдонимы столбцов, отразились в заголовке результирующей таблицы. Собственно, это и есть основное предназначение псевдонимов столбцов.
Обратите внимание, т.к. у последних 2-х сотрудников не указано отчество (NULL значение), то результат выражения «LastName+" "+FirstName+" "+MiddleName» так же вернул нам NULL.
Для соединения (сложения, конкатенации) строк в MS SQL используется символ «+».
Запомним, что все выражения в которых участвует NULL (например, деление на NULL, сложение с NULL) будут возвращать NULL.
На заметку.
В случае ORACLE для объединения строк используется оператор «||» и конкатенация будет выглядеть как «LastName||" "||FirstName||" "||MiddleName». Для ORACLE стоит отметить, что у него для строковых типов есть исключение, для них NULL и пустая строка "" это одно и тоже, поэтому в ORACLE такое выражение вернет для последних 2-х сотрудников «Сидоров Сидор » и «Андреев Андрей ». На момент версии ORACLE 12c, насколько я знаю, опции которая изменяет такое поведение нет (если не прав, прошу поправить меня). Здесь мне сложно судить хорошо это или плохо, т.к. в одних случаях удобнее поведение NULL-строки как в MS SQL, а в других как в ORACLE.В ORACLE тоже допустимы все перечисленные выше псевдонимы столбцов, кроме […].
Для того чтобы не городить конструкцию с использованием функции ISNULL, в MS SQL мы можем применить функцию CONCAT. Рассмотрим и сравним 3 варианта:
SELECT
LastName+" "+FirstName+" "+MiddleName FullName1,
-- 2 варианта для замены NULL пустыми строками "" (получаем поведение как и в ORACLE)
ISNULL(LastName,"")+" "+ISNULL(FirstName,"")+" "+ISNULL(MiddleName,"") FullName2,
CONCAT(LastName," ",FirstName," ",MiddleName) FullName3
FROM Employees
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
В MS SQL псевдонимы еще можно задавать при помощи знака равенства:
SELECT "Дата приема"=HireDate, -- помимо "…" и […] можно использовать "…" [Дата рождения]=Birthday, ZP=Salary FROM Employees
Использовать для задания псевдонима ключевое слово AS или же знак равенства, наверное, больше дело вкуса. Но при разборе чужих запросов, данные знания могут пригодиться.
Напоследок скажу, что для псевдонимов имена лучше задавать, используя только символы латиницы и цифры, избегая применения "…", "…" и […], то есть использовать те же правила, что мы использовали при наименовании таблиц. Дальше, в примерах я буду использовать только такие наименования и никаких "…", "…" и […].
Основные арифметические операторы SQL
Приоритет выполнения арифметических операторов такой же, как и в математике. Если необходимо, то порядок применения операторов можно изменить используя круглые скобки - (a+b)*(x/(y-z)).
И еще раз повторюсь, что любая операция с NULL дает NULL, например: 10+NULL, NULL*15/3, 100/NULL – все это даст в результате NULL. Т.е. говоря просто неопределенное значение не может дать определенный результат. Учитывайте это при составлении запроса и при необходимости делайте обработку NULL значений функциями ISNULL, COALESCE:
SELECT
ID,Name,
Salary/100*BonusPercent AS Result1, -- без обработки NULL значений
Salary/100*ISNULL(BonusPercent,0) AS Result2, -- используем функцию ISNULL
Salary/100*COALESCE(BonusPercent,0) AS Result3 -- используем функцию COALESCE
FROM Employees
Немного расскажу о функции COALESCE:
COALESCE (expr1, expr2, ..., exprn) - Возвращает первое не NULL значение из списка значений.
SELECT COALESCE(f1, f1*f2, f2*f3) val -- в данном случае вернется третье значение FROM (SELECT null f1, 2 f2, 3 f3) q
В основном, я сосредоточусь на рассказе конструкций языка DML и по большей части не буду рассказывать о функциях, которые будут встречаться в примерах. Если вам непонятно, что делает та или иная функция поищите ее описание в интернет, можете даже поискать информацию сразу по группе функций, например, задав в поиске Google «MS SQL строковые функции», «MS SQL математические функции» или же «MS SQL функции обработки NULL». Информации по функциям очень много, и вы ее сможете без труда найти. Для примера, в библиотеке MSDN, можно узнать больше о функции COALESCE:
Вырезка из MSDN Сравнение COALESCE и CASEВыражение COALESCE - синтаксический ярлык для выражения CASE. Это означает, что код COALESCE(expression1,...n) переписывается оптимизатором запросов как следующее выражение CASE:
CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
Для примера рассмотрим, как можно воспользоваться остатком от деления (%). Данный оператор очень полезен, когда требуется разбить записи на группы. Например, вытащим всех сотрудников, у которых четные табельные номера (ID), т.е. те ID, которые делятся на 2:
SELECT ID,Name
FROM Employees
WHERE ID%2=0 -- остаток от деления на 2 равен 0
ORDER BY – сортировка результата запроса
Предложение ORDER BY используется для сортировки результата запроса.SELECT
LastName,
FirstName,
Salary
FROM Employees
ORDER BY LastName,FirstName -- упорядочить результат по 2-м столбцам – по Фамилии, и после по Имени
Для заметки. Для сортировки по возрастанию есть ключевое слово ASC, но так как сортировка по возрастанию применяется по умолчанию, то про эту опцию можно забыть (я не помню случая, чтобы я когда-то использовал эту опцию).
Стоит отметить, что в предложении ORDER BY можно использовать и поля, которые не перечислены в предложении SELECT (кроме случая, когда используется DISTINCT, об этом случае я расскажу ниже). Для примера забегу немного вперед используя опцию TOP и покажу, как например, можно отобрать 3-х сотрудников у которых самая высокая ЗП, с учетом что саму ЗП в целях конфиденциальности я показывать не должен:
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата
ID,LastName,FirstName
FROM Employees
ORDER BY Salary DESC -- сортируем результат по убыванию Заработной Платы
| ID | LastName | FirstName |
|---|---|---|
| 1000 | Иванов | Иван |
| 1002 | Сидоров | Сидор |
Конечно здесь есть случай, что у нескольких сотрудников может быть одинаковая ЗП и тут сложно сказать каких именно трех сотрудников вернет данный запрос, это уже нужно решать с постановщиком задачи. Допустим, после обсуждения с постановщиком данной задачи, вы согласовали и решили использовать следующий вариант – сделать дополнительную сортировку по полю даты рождения (т.е. молодым у нас дорога), а если и дата рождения у нескольких сотрудников может совпасть (ведь такое тоже не исключено), то можно сделать третью сортировку по убыванию значений ID (в последнюю очередь под выборку попадут те, у кого ID окажется максимальным – например, те кто был принят последним, допустим табельные номера у нас выдаются последовательно):
SELECT TOP 3 -- вернуть только 3 первые записи из всего результата ID,LastName,FirstName FROM Employees ORDER BY Salary DESC, -- 1. сортируем результат по убыванию Заработной Платы Birthday, -- 2. потом по Дате рождения ID DESC -- 3. и для полной однозначности результата добавляем сортировку по ID
Т.е. вы должны стараться чтобы результат запроса был предсказуемым, чтобы вы могли в случае разбора полетов объяснить почему в «черный список» попали именно эти люди, т.е. все было выбрано честно, по утверждённым правилам.
Сортировать можно так же используя разные выражения в предложении ORDER BY:
SELECT LastName,FirstName FROM Employees ORDER BY CONCAT(LastName," ",FirstName) -- используем выражение
Так же в ORDER BY можно использовать псевдонимы заданные для колонок:
SELECT CONCAT(LastName," ",FirstName) fi FROM Employees ORDER BY fi -- используем псевдоним
Стоит отметить что в случае использования предложения DISTINCT, в предложении ORDER BY могут использоваться только колонки, перечисленные в блоке SELECT. Т.е. после применения операции DISTINCT мы получаем новый набор данных, с новым набором колонок. По этой причине, следующий пример не отработает:
SELECT DISTINCT LastName,FirstName,Salary FROM Employees ORDER BY ID -- ID отсутствует в итоговом наборе, который мы получили при помощи DISTINCT
Т.е. предложение ORDER BY применяется уже к итоговому набору, перед выдачей результата пользователю.
Примечание 1. Так же в предложении ORDER BY можно использовать номера столбцов, перечисленных в SELECT:SELECT LastName,FirstName,Salary FROM Employees ORDER BY -- упорядочить в порядке 3 DESC, -- 1. убывания Заработной Платы 1, -- 2. по Фамилии 2 -- 3. по Имени
Для начинающих выглядит удобно и заманчиво, но лучше забыть и никогда не использовать такой вариант сортировки.
Если в данном случае (когда поля явно перечислены), такой вариант еще допустим, то для случая с использованием «*» такой вариант лучше никогда не применять. Почему – потому что, если кто-то, например, поменяет в таблице порядок столбцов, или удалит столбцы (и это нормальная ситуация), ваш запрос может так же работать, но уже неправильно, т.к. сортировка уже может идти по другим столбцам, и это коварно тем что данная ошибка может обнаружиться очень нескоро.
В случае, если бы столбы были явно перечислены, то в вышеуказанной ситуации, запрос либо бы продолжал работать, но также правильно (т.к. все явно определено), либо бы он просто выдал ошибку, что данного столбца не существует.
Так что можете смело забыть, о сортировке по номерам столбцов.
Примечание 2.
В MS SQL при сортировке по возрастанию NULL значения будут отображаться первыми.SELECT BonusPercent FROM Employees ORDER BY BonusPercent
Соответственно при использовании DESC они будут в конце
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC
Если необходимо поменять логику сортировки NULL значений, то используйте выражения, например:
SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)
В ORACLE для этой цели предусмотрены 2 опции NULLS FIRST и NULLS LAST (применяется по умолчанию). Например:
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LAST
Обращайте на это внимание при переходе на ту или иную БД.
TOP – возврат указанного числа записей
Вырезка из MSDN. TOP – ограничивает число строк, возвращаемых в результирующем наборе запроса до заданного числа или процентного значения. Если предложение TOP используется совместно с предложением ORDER BY, то результирующий набор ограничен первыми N строками отсортированного результата. В противном случае возвращаются первые N строк в неопределенном порядке.
Обычно данное выражение используется с предложением ORDER BY и мы уже смотрели примеры, когда нужно было вернуть N-первых строк из результирующего набора.
Без ORDER BY обычно данное предложение применяется, когда нужно просто посмотреть на неизвестную нам таблицу, в которой может быть очень много записей, в этом случае мы можем, для примера, попросить вернуть нам только первые 10 строк, но для наглядности мы скажем только 2:
SELECT TOP 2 * FROM Employees
Так же можно указать слово PERCENT, для того чтобы вернулось соответствуй процент строк из результирующего набора:
SELECT TOP 25 PERCENT * FROM Employees
На моей практике чаше применяется именно выборка по количеству строк.
Так же с TOP можно использовать опцию WITH TIES, которая поможет вернуть все строки в случае неоднозначной сортировки, т.е. это предложение вернет все строки, которые равны по составу строкам, которые попадают в выборку TOP N, в итоге строк может быть выбрано больше чем N. Давайте для демонстрации добавим еще одного «Программиста» с окладом 1500:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1004,N"Николаев Н.Н.","[email protected]",3,3,1003,1500)
И введем еще одного сотрудника без указания должности и отдела с окладом 2000:
INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1005,N"Александров А.А.","[email protected]",NULL,NULL,1000,2000)
Теперь давайте выберем при помощи опции WITH TIES всех сотрудников, у которых оклад совпадает с окладами 3-х сотрудников, с самым маленьким окладом (надеюсь дальше будет понятно, к чему я клоню):
SELECT TOP 3 WITH TIES ID,Name,Salary FROM Employees ORDER BY Salary
Здесь хоть и указано TOP 3, но запрос вернул 4 записи, т.к. значение Salary которое вернуло TOP 3 (1500 и 2000) оказалось у 4-х сотрудников. Наглядно это работает примерно следующим образом:
На заметку.
В разных БД TOP реализуется разными способами, в MySQL для этого есть предложение LIMIT, в котором дополнительно можно задать начальное смещение.В ORACLE 12c, тоже ввели свой аналог совмещающий функциональность TOP и LIMIT – ищите по словам «ORACLE OFFSET FETCH». До версии 12c для этой цели обычно использовался псевдостолбец ROWNUM.
А что же будет если применить одновременно предложения DISTINCT и TOP? На такие вопросы легко ответить, проводя эксперименты. В общем, не бойтесь и не ленитесь экспериментировать, т.к. большая часть познается именно на практике. Порядок слов в операторе SELECT следующий, первым идет DISTINCT, а после него идет TOP, т.е. если рассуждать логически и читать слева-направо, то первым применится отброс дубликатов, а потом уже по этому набору будет сделан TOP. Что-ж проверим и убедимся, что так и есть:
SELECT DISTINCT TOP 2
Salary
FROM Employees
ORDER BY Salary
| Salary |
|---|
| 1500 |
| 2000 |
Т.е. в результате мы получили 2 самые маленькие зарплаты из всех. Конечно может быть случай что ЗП для каких-то сотрудников может быть не указанной (NULL), т.к. схема нам это позволяет. Поэтому в зависимости от задачи принимаем решение либо обработать NULL значения в предложении ORDER BY, либо просто отбросить все записи, у которых Salary равна NULL, а для этого переходим к изучению предложения WHERE.
WHERE – условие выборки строк
Данное предложение служит для фильтрации записей по заданному условию. Например, выберем всех сотрудников работающих в «ИТ» отделе (его ID=3):SELECT ID,LastName,FirstName,Salary
FROM Employees
WHERE DepartmentID=3 -- ИТ
ORDER BY LastName,FirstName
| ID | LastName | FirstName | Salary |
|---|---|---|---|
| 1004 | NULL | NULL | 1500 |
| 1003 | Андреев | Андрей | 2000 |
| 1001 | Петров | Петр | 1500 |
Предложение WHERE пишется до команды ORDER BY.
Порядок применения команд к исходному набору Employees следующий:
- WHERE – если указано, то первым делом из всего набора Employees идет отбор только удовлетворяющих условию записей
- DISTINCT – если указано, то отбрасываются все дубликаты
- ORDER BY – если указано, то делается сортировка результата
- TOP – если указано, то из отсортированного результата возвращается только указанное число записей
Рассмотрим для наглядности пример:
SELECT DISTINCT TOP 1 Salary FROM Employees WHERE DepartmentID=3 ORDER BY Salary
Наглядно это будет выглядеть следующим образом:
Стоит отметить, что проверка на NULL делается не знаком равенства, а при помощи операторов IS NULL и IS NOT NULL. Просто запомните, что на NULL при помощи оператора «=» (знак равенства) сравнивать нельзя, т.к. результат выражения будет так же равен NULL.
Например, выберем всех сотрудников, у которых не указан отдел (т.е. DepartmentID IS NULL):
SELECT ID,Name
FROM Employees
WHERE DepartmentID IS NULL
Теперь для примера посчитаем бонус для всех сотрудников у которых указано значение BonusPercent (т.е. BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent IS NOT NULL
Да, кстати, если подумать, то значение BonusPercent может равняться нулю (0), а так же значение может быть внесено со знаком минус, ведь мы не накладывали на данное поле никаких ограничений.
Хорошо, рассказав о проблеме, нам пока сказали считать, что если (BonusPercent<=0 или BonusPercent IS NULL), то это означает что у сотрудника так же нет бонуса. Для начала, как нам сказали, так и сделаем, реализуем это при помощи логического оператора OR и NOT:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL)
Т.е. здесь мы начали изучать булевы операторы. Выражение в скобках «(BonusPercent<=0 OR BonusPercent IS NULL)» проверяет на то что у сотрудника нет бонуса, а NOT инвертирует это значение, т.е. говорит «верни всех сотрудников которые не сотрудники у которых нет бонуса».
Так же данное выражение можно переписать и сразу сказав сразу «верни всех сотрудников, у которых есть бонус» выразив это выражением (BonusPercent>0 и BonusPercent IS NOT NULL):
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent>0 AND BonusPercent IS NOT NULL
Также в блоке WHERE можно делать проверку разного рода выражений с применением арифметических операторов и функций. Например, аналогичную проверку можно сделать, использовав выражение с функцией ISNULL:
SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE ISNULL(BonusPercent,0)>0
Булевы операторы и простые операторы сравнения
Да, без математики здесь не обойтись, поэтому сделаем небольшой экскурс по булевым и простым операторам сравнения.Булевых операторов в языке SQL всего 3 – AND, OR и NOT:
Для каждого булева оператора можно привести таблицы истинности где дополнительно показано какой будет результат, когда условия могут быть равны NULL:
Есть следующие простые операторы сравнения, которые используются для формирования условий:
Плюс имеются 2 оператора для проверки значения/выражения на NULL:
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Приоритет: 1) Все операторы сравнения; 2) NOT; 3) AND; 4) OR.
При построении сложных логических выражений используются круглые скобки:
((условие1 AND условие2) OR NOT(условие3 AND условие4 AND условие5)) OR (…)
Так же при помощи использования круглых скобок, можно изменить стандартную последовательность вычислений.
Здесь я постарался дать представление о булевой алгебре в достаточном для работы объеме. Как видите, чтобы писать условия посложнее без логики уже не обойтись, но ее здесь немного (AND, OR и NOT) и придумывали ее люди, так что все достаточно логично.
Идем к завершению второй части
Как видите даже про базовый синтаксис оператора SELECT можно говорить очень долго, но, чтобы остаться в рамках статьи, напоследок я покажу дополнительные логических операторы – BETWEEN, IN и LIKE.BETWEEN – проверка на вхождение в диапазон
Проверяемое_значение BETWEEN начальное_ значение AND конечное_ значение
В роли значений могут выступать выражения.
Разберем на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000
Собственно, BETWEEN это упрощенная запись вида:
SELECT ID,Name,Salary FROM Employees WHERE Salary>=2000 AND Salary<=3000 -- все у кого ЗП в диапозоне 2000-3000
Перед словом BETWEEN может использоваться слово NOT, которое будет осуществлять проверку значения на не вхождение в указанный диапазон:
SELECT ID,Name,Salary FROM Employees WHERE Salary NOT BETWEEN 2000 AND 3000 -- аналогично выражению NOT(Salary>=2000 AND Salary<=3000)
Соответственно, в случае использования BETWEEN, IN, LIKE вы можете так же объединять их с другими условиями при помощи AND и OR:
SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000 -- у кого ЗП в диапазоне 2000-3000 AND DepartmentID=3 -- учитывать сотрудников только отдела 3
IN – проверка на вхождение в перечень значений
Этот оператор имеет следующий вид:Проверяемое_значение IN (значение1, значение2, …)
Думаю, проще показать на примере:
SELECT ID,Name,Salary
FROM Employees
WHERE PositionID IN(3,4) -- у кого должность равна 3 или 4
Т.е. по сути это аналогично следующему выражению:
SELECT ID,Name,Salary FROM Employees WHERE PositionID=3 OR PositionID=4 -- у кого должность равна 3 или 4
В случае NOT это будет аналогично (получим всех кроме тех, кто из отдела 3 и 4):
SELECT ID,Name,Salary FROM Employees WHERE PositionID NOT IN(3,4) -- аналогично выражению NOT(PositionID=3 OR PositionID=4)
Так же запрос с NOT IN можно выразить и через AND:
SELECT ID,Name,Salary FROM Employees WHERE PositionID<>3 AND PositionID<>4 -- равносильно PositionID NOT IN(3,4)
Учтите, что искать NULL значения при помощи конструкции IN не получится, т.к. проверка NULL=NULL вернет так же NULL, а не True:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2,NULL) -- NULL записи не войдут в результат
В этом случае разбивайте проверку на несколько условий:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2) -- 1 или 2 OR DepartmentID IS NULL -- или NULL
Или же можно написать что-то вроде:
SELECT ID,Name,DepartmentID FROM Employees WHERE ISNULL(DepartmentID,-1) IN(1,2,-1) -- если вы уверены, что в нет и не будет департамента с ID=-1
Думаю, первый вариант, в данном случае будет более правильным и надежным. Ну ладно, это всего лишь пример, для демонстрации того какие еще конструкции можно строить.
Так же стоит упомянуть еще более коварную ошибку, связанную с NULL, которую можно допустить при использовании конструкции NOT IN. Для примера, давайте попробуем выбрать всех сотрудников, кроме тех, у которых отдел равен 1 или у которых отдел вообще не указан, т.е. равен NULL. В качестве решения напрашивается вариант:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1,NULL)
Но выполнив запрос, мы не получим ни одной строки, хотя мы ожидали увидеть следующее:
Опять же шутку здесь сыграло NULL указанное в списке значений.
Разберем почему в данном случае возникла логическая ошибка. Разложим запрос при помощи AND:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID<>1 AND DepartmentID<>NULL -- проблема из-за этой проверки на NULL - это условие всегда вернет NULL
Правое условие (DepartmentID<>NULL) нам всегда здесь даст неопределенность, т.е. NULL. Теперь вспомним таблицу истинности для оператора AND, где (TRUE AND NULL) дает NULL. Т.е. при выполнении левого условия (DepartmentID<>1) из-за неопределенного правого условия в результате мы получим неопределенное значение всего выражения (DepartmentID<>1 AND DepartmentID<>NULL), поэтому строка не войдет в результат.
Переписать условие правильно можно следующим образом:
SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1) -- или в данном случае просто DepartmentID<>1 AND DepartmentID IS NOT NULL -- и отдельно проверяем на NOT NULL
IN еще можно использовать с подзапросами, но к такой форме мы вернемся, уже в последующих частях данного учебника.
LIKE – проверка строки по шаблону
Про данный оператор я расскажу только в самом простом виде, который является стандартом и поддерживается большинством диалектов языка SQL. Даже в таком виде при помощи него можно решить много задач, которые требуют выполнить проверку по содержимому строки.Этот оператор имеет следующий вид:
Проверяемая_строка LIKE строка_шаблон
В «строке_шаблон» могут применятся следующие специальные символы:
- Знак подчеркивания «_» - говорит, что на его месте может стоять любой единичный символ
- Знак процента «%» - говорит, что на его месте может стоять сколько угодно символов, в том числе и ни одного
SELECT ID,Name FROM Employees WHERE Name LIKE "Пет%" -- у кого имя начинается с букв "Пет" SELECT ID,LastName FROM Employees WHERE LastName LIKE "%ов" -- у кого фамилия оканчивается на "ов" SELECT ID,LastName FROM Employees WHERE LastName LIKE "%ре%" -- у кого фамилия содержит сочетание "ре"
Рассмотрим примеры с символом «_»:
SELECT ID,LastName FROM Employees WHERE LastName LIKE "_етров" -- у кого фамилия состоит из любого первого символа и последующих букв "етров" SELECT ID,LastName FROM Employees WHERE LastName LIKE "____ов" -- у кого фамилия состоит из четырех любых символов и последующих букв "ов"
При помощи ESCAPE можно задать отменяющий символ, который отменяет проверяющее действие специальных символов «_» и «%». Данное предложение используется, когда в строке нужно непосредственно проверить наличие знака процента или знака подчеркивания.
Для демонстрации ESCAPE давайте занесем в одну запись мусор:
UPDATE Employees SET FirstName="Это_мусор, содержащий %" WHERE ID=1005
И посмотрим, что вернут следующие запросы:
SELECT * FROM Employees WHERE FirstName LIKE "%!%%" ESCAPE "!" -- строка содержит знак "%" SELECT * FROM Employees WHERE FirstName LIKE "%!_%" ESCAPE "!" -- строка содержит знак "_"
В случае, если требуется проверить строку на полное совпадение, то вместо LIKE лучше использовать просто знак «=»:
SELECT * FROM Employees WHERE FirstName="Петр"
На заметку.
В MS SQL в шаблоне оператора LIKE так же можно задать поиск по регулярным выражениям, почитайте о нем в интернете, в том случае, если вам станет недостаточно стандартных возможностей данного оператора.В ORACLE для поиска по регулярным выражениям применяется функция REGEXP_LIKE.
Немного о строках
В случае проверки строки на наличие Unicode символов, нужно будет ставить перед кавычками символ N, т.е. N"…". Но так как у нас в таблице все символьные поля в формате Unicode (тип nvarchar), то для этих полей можно всегда использовать такой формат. Пример:SELECT ID,Name FROM Employees WHERE Name LIKE N"Пет%" SELECT ID,LastName FROM Employees WHERE LastName=N"Петров"
Если делать правильно, при сравнении с полем типа varchar (ASCII) нужно стараться использовать проверки с использованием "…", а при сравнении поля с типом nvarchar (Unicode) нужно стараться использовать проверки с использованием N"…". Это делается для того, чтобы избежать в процессе выполнения запроса неявных преобразований типов. То же самое правило используем при вставке (INSERT) значений в поле или их обновлении (UPDATE).
При сравнении строк стоит учесть момент, что в зависимости от настройки БД (collation), сравнение строк может быть, как регистро-независимым (когда "Петров"="ПЕТРОВ"), так и регистро-зависимым (когда "Петров"<>"ПЕТРОВ").
В случае регистро-зависимой настройки, если требуется сделать поиск без учета регистра, то можно, например, сделать предварительное преобразование правого и левого выражения в один регистр – верхний или нижний:
SELECT ID,Name FROM Employees WHERE UPPER(Name) LIKE UPPER(N"Пет%") -- или LOWER(Name) LIKE LOWER(N"Пет%") SELECT ID,LastName FROM Employees WHERE UPPER(LastName)=UPPER(N"Петров") -- или LOWER(LastName)=LOWER(N"Петров")
Немного о датах
При проверке на дату, вы можете использовать, как и со строками одинарные кавычки "…".Вне зависимости от региональных настроек в MS SQL можно использовать следующий синтаксис дат "YYYYMMDD" (год, месяц, день слитно без пробелов). Такой формат даты MS SQL поймет всегда:
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN "19800101" AND "19891231" -- сотрудники 80-х годов ORDER BY Birthday
В некоторых случаях, дату удобнее задавать при помощи функции DATEFROMPARTS:
SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31) ORDER BY Birthday
Так же есть аналогичная функция DATETIMEFROMPARTS, которая служит для задания Даты и Времени (для типа datetime).
Еще вы можете использовать функцию CONVERT, если требуется преобразовать строку в значение типа date или datetime:
SELECT CONVERT(date,"12.03.2015",104), CONVERT(datetime,"2014-11-30 17:20:15",120)
Значения 104 и 120, указывают какой формат даты используется в строке. Описание всех допустимых форматов вы можете найти в библиотеке MSDN задав в поиске «MS SQL CONVERT».
Функций для работы с датами в MS SQL очень много, ищите «ms sql функции для работы с датами».
Примечание. Во всех диалектах языка SQL свой набор функций по работе с датами и применяется свой подход по работе с ними.
Немного о числах и их преобразованиях
Информация этого раздела наверно больше будет полезна ИТ-специалистам. Если вы таковым не являетесь, а ваша цель просто научится писать запросы для получения из БД необходимой вам информации, то такие тонкости вам возможно и не понадобятся, но в любом случае можете бегло пройтись по тексту и взять что-то на заметку, т.к. если вы взялись за изучение SQL, то вы уже приобщаетесь к ИТ.В отличие от функции преобразования CAST, в функции CONVERT можно задать третий параметр, который отвечает за стиль преобразования (формат). Для разных типов данных может использоваться свой набор стилей, которые могут повлиять на возвращаемый результат. Использование стилей мы уже затрагивали при рассмотрении преобразования строки функцией CONVERT в типы date и datetime.
Подробней про функции CAST, CONVERT и стили можно почитать в MSDN – «Функции CAST и CONVERT (Transact-SQL)»: msdn.microsoft.com/ru-ru/library/ms187928.aspx
Для упрощения примеров здесь будут использованы инструкции языка Transact-SQL – DECLARE и SET.
Конечно, в случае преобразования целого числа в вещественное (которое я привел вначале данного урока, в целях демонстрации разницы между целочисленным и вещественным делением), знание нюансов преобразования не так критично, т.к. там мы делали преобразование целого числа в вещественное (диапазон которого намного больше диапазона целых):
DECLARE @min_int int SET @min_int=-2147483648 DECLARE @max_int int SET @max_int=2147483647 SELECT -- (-2147483648) @min_int,CAST(@min_int AS float),CONVERT(float,@min_int), -- 2147483647 @max_int,CAST(@max_int AS float),CONVERT(float,@max_int), -- numeric(16,6) @min_int/1., -- (-2147483648.000000) @max_int/1. -- 2147483647.000000
Возможно не стоило указывать способ неявного преобразования, получаемого делением на (1.), т.к. желательно стараться делать явные преобразования, для большего контроля типа получаемого результата. Хотя, в случае, если мы хотим получить результат типа numeric, с указанным количеством цифр после запятой, то мы можем в MS SQL применить трюк с умножением целого значения на (1., 1.0, 1.00 и т.д):
DECLARE @int int SET @int=123 SELECT @int*1., -- numeric(12, 0) - 0 знаков после запятой @int*1.0, -- numeric(13, 1) - 1 знак @int*1.00, -- numeric(14, 2) - 2 знака -- хотя порой лучше сделать явное преобразование CAST(@int AS numeric(20, 0)), -- 123 CAST(@int AS numeric(20, 1)), -- 123.0 CAST(@int AS numeric(20, 2)) -- 123.00
В некоторых случаях детали преобразования могут быть действительно важны, т.к. они влияют на правильность полученного результата, например, в случае, когда делается преобразование числового значения в строку (varchar). Рассмотрим примеры по преобразованию значений типа money и float в varchar:
Поведение при преобразовании money в varchar DECLARE @money money SET @money = 1025.123456789 -- произойдет неявное преобразование в 1025.1235, т.к. тип money хранит только 4 цифры после запятой SELECT @money, -- 1025.1235 -- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0) CAST(@money as varchar(20)), -- 1025.12 CONVERT(varchar(20), @money), -- 1025.12 CONVERT(varchar(20), @money, 0), -- 1025.12 (стиль 0 - без разделителя тысячных и 2 цифры после запятой (формат по умолчанию)) CONVERT(varchar(20), @money, 1), -- 1,025.12 (стиль 1 - используется разделитель тысячных и 2 цифры после запятой) CONVERT(varchar(20), @money, 2) -- 1025.1235 (стиль 2 - без разделителя и 4 цифры после запятой)
Поведение при преобразовании float в varchar DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 SELECT @float1, -- 1025.123456789 @float2, -- 1231025.12345679 -- по умолчанию CAST и CONVERT ведут себя одинаково (т.е. грубо говоря применяется стиль 0) -- стиль 0 - Не более 6 разрядов. По необходимости используется экспоненциальное представление чисел -- при преобразовании в varchar здесь творятся действительно страшные вещи CAST(@float1 as varchar(20)), -- 1025.12 CONVERT(varchar(20), @float1), -- 1025.12 CONVERT(varchar(20), @float1, 0), -- 1025.12 CAST(@float2 as varchar(20)), -- 1.23103e+006 CONVERT(varchar(20), @float2), -- 1.23103e+006 CONVERT(varchar(20), @float2, 0), -- 1.23103e+006 -- стиль 1 - Всегда 8 разрядов. Всегда используется экспоненциальное представление чисел. -- этот стиль для float тоже не очень точен CONVERT(varchar(20), @float1, 1), -- 1.0251235e+003 CONVERT(varchar(20), @float2, 1), -- 1.2310251e+006 -- стиль 2 - Всегда 16 разрядов. Всегда используется экспоненциальное представление чисел. -- здесь с точностью уже получше CONVERT(varchar(30), @float1, 2), -- 1.025123456789000e+003 - OK CONVERT(varchar(30), @float2, 2) -- 1.231025123456789e+006 - OK
Как видно из примера, плавающие типы float, real в некоторых случаях действительно могут создать большую погрешность, особенно при перегонке в строку и обратно (такое может быть при разного рода интеграциях, когда данные, например, передаются в текстовых файлах из одной системы в другую).
Если нужно явно контролировать точность до определенного знака, более 4-х, то для хранения данных, порой лучше использовать тип decimal/numeric. Если хватает 4-х знаков, то можно использовать и тип money – он примерно соотвествует numeric(20,4).
Decimal и numeric DECLARE @money money SET @money = 1025.123456789 -- 1025.1235 DECLARE @float1 float SET @float1 = 1025.123456789 DECLARE @float2 float SET @float2 = 1231025.123456789 DECLARE @numeric numeric(28,9) SET @numeric = 1025.123456789 SELECT CAST(@numeric as varchar(20)), -- 1025.12345679 CONVERT(varchar(20), @numeric), -- 1025.12345679 CAST(@money as numeric(28,9)), -- 1025.123500000 CAST(@float1 as numeric(28,9)), -- 1025.123456789 CAST(@float2 as numeric(28,9)) -- 1231025.123456789
Примечание.
С версии MS SQL 2008, можно использовать вместо конструкции: Добавить метки